Command Palette
Search for a command to run...
LEAP:利用智能体框架为大型语言模型在形式化数学领域的赋能增效
LEAP:利用智能体框架为大型语言模型在形式化数学领域的赋能增效
摘要
大型语言模型(LLM)在非形式化数学推理方面表现出强大能力,但在生成如 Lean 等正式语言中的机械可验证证明时仍面临挑战。我们提出了 LEAP(LLM-in-Lean Environment Agentic Prover,即“Lean 环境中基于大模型的智能体证明器”),这是一个智能体框架,使通用基础模型在自动形式化定理证明领域达到了最先进水平。LEAP 利用了基础模型的非形式化推理、指令遵循和迭代自我完善等能力。通过将复杂问题分解为更小的单元,该系统通过与 Lean 编译器的持续交互,桥接了形式化证明构建与非形式化蓝图之间的关系。为了在日益饱和的基准测试之外提供更为严谨的评估,我们引入了 Lean-IMO-Bench,这是一个以 Lean 形式化的国际数学奥林匹克(IMO)风格问题基准测试。该基准测试的题目陈述简短,但证明过程具有高度的非例行性和多步骤特征,涵盖了广泛难度级别。实验结果表明,在最新的 2025 年波拉克数学竞赛(Putnam Competition,面向北美本科生年度数学竞赛)中,LEAP 成功解决了全部 12 道题目,性能与前沿形式化数学模型的最新突破持平。在 Lean-IMO-Bench 上,LEAP 将通用 LLM 的一次性形式化求解率从不足 10% 提升至 70%,显著超越了由一枚金牌水平的 IMO 专用系统所创下的 48% 基准成绩。此外,我们还展示了 LEAP 在研究层面的实用性,其能够自主形式化复杂证明,例如针对开放组合挑战问题的证明,包括对 Knuth 的偶数阶 Cayley 图哈密顿分解中一个关键子问题的已验证证明。
一句话总结
LEAP(LLM-in-Lean Environment Agentic Prover)通过通过与 Lean 编译器的持续交互,将形式化证明构建与非正式蓝图相结合,使通用基础模型在自动化形式化定理证明中实现最先进性能,解决了 2025 年普特南竞赛中的全部 12 道题目,并将 Lean-IMO-Bench 上的一次性形式化解决率从低于 10% 提升至 70%,同时自主为开放组合挑战构建复杂证明,包括对 Knuth 偶阶 Cayley 图哈密顿分解中一个关键子问题的已验证证明。
核心贡献
- 本文介绍了 LEAP,一个 agent 框架,使通用基础模型在自动化形式化定理证明中实现最先进性能。该方法将复杂问题分解为更小的单元,并通过与 Lean 编译器的持续交互,将形式化证明构建与非正式蓝图相结合。
- 为了在饱和基准之外提供严格评估,该工作提出了 Lean-IMO-Bench,这是一组在 Lean 中形式化的 IMO 风格问题,具有高度非常规和多步证明。该数据集针对需要跨广泛难度级别的结构复杂解决方案的基本陈述。
- 实验结果表明,LEAP 解决了 2025 年普特南竞赛中的全部 12 道问题,并将 Lean-IMO-Bench 上的一次性形式化解决率从低于 10% 提高到 70%。这些发现表明,对于通用 LLM 而言,与证明环境的结构化迭代交互比单纯的形式语言理解更为关键。
引言
大型语言模型擅长非形式化数学推理,但在生成 Lean 等正式语言中可机械验证的证明方面存在困难。这一限制至关重要,因为自然语言解决方案通常包含难以验证的幻觉,而正式语言提供具有保证准确性的自动验证。现有方法通常依赖于在正式语料库上微调的专用模型,或通用模型仅处理非形式化推理的混合系统。为解决这一问题,作者引入了 LEAP,一个 agent 框架,使通用基础模型无需专用微调即可在自动化形式化定理证明中实现领先性能。LEAP 将复杂问题分解为更小的单元,并利用编译器反馈迭代优化证明,以弥合非正式蓝图与形式化构建之间的差距。此外,团队发布了 Lean-IMO-Bench,以评估在饱和基准之外具有挑战性的多步问题上的进展。
数据集
- 数据集组成与来源: 作者介绍了 LEAN-IMO-BENCH,这是一个精心策划的 60 个问题集合,基于 Luong 等人 (2025) 的 IMO-ProofBench 套件。
- 子集详情: 基准测试平均分为 Basic 集和 Advanced 集,各 30 个问题。Basic 集涵盖从 pre-IMO 到 IMO-Medium 的难度,包括 8 个代数、8 个组合、8 个数论和 6 个几何问题。Advanced 集包含新颖问题,难度高达 IMO-Hard,包括 8 个代数、8 个组合、6 个数论和 8 个几何问题。
- 论文中的使用: 团队主要利用此数据进行形式化定理证明任务以评估模型性能,指出自然语言推理不能保证形式化代码生成的成功。
- 处理与验证: Lean 专家手动形式化并验证了每个问题陈述以确保高准确性。相应的 Lean 解决方案保持简洁,以避免复杂现代数学理论带来的开销,同时依赖基础数学背景。
方法
作者介绍了 LEAP,一个用于自动化定理证明的 agent 框架,利用分层分解和规划来弥合通用 LLM 与形式化验证之间的差距。LEAP 不是单次合成完整证明,而是增量起草蓝图,将 Lean 目标分解为支持的引理,并将不断演变的证明计划维护为 AND-OR DAG。
整体工作流程如下图所示。
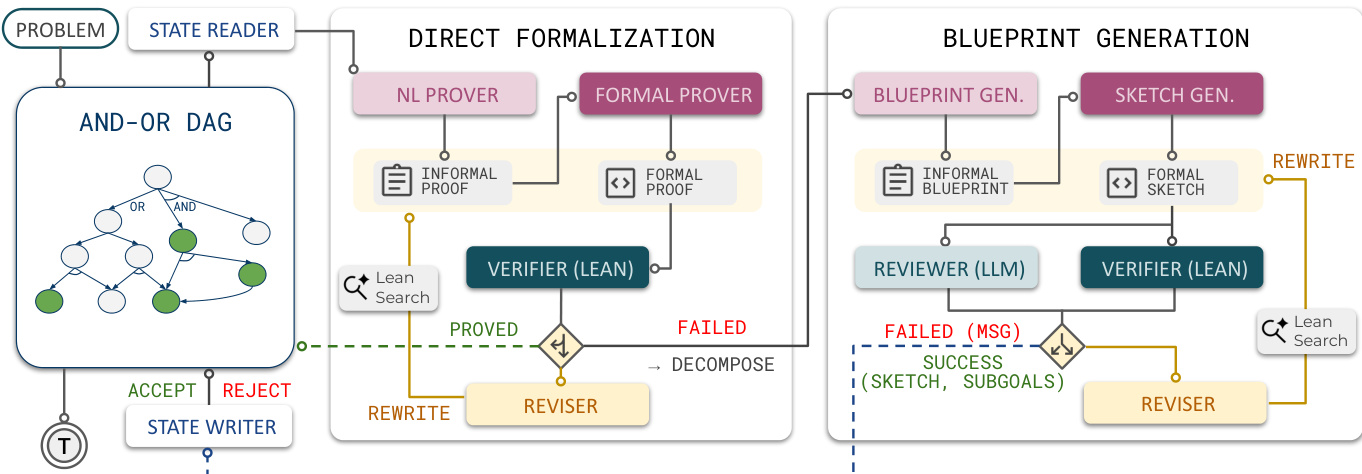
给定一个输入定理,系统将 Lean 语句注册为根目标,表示为 AND-OR DAG 中的 OR 节点。State Reader 检索当前目标的语句、依赖项和相关引理。LEAP 首先尝试直接证明策略。这涉及 NL Prover 生成非正式论证,Formal Prover 将其转换为 Lean 代码。Verifier 根据 Lean 编译器检查候选项。如果证明失败,Reviser 利用反馈尝试重写。
如果直接证明失败,系统转向称为 Blueprint Generation 的分解策略。agent 起草一个非正式蓝图,提出中间引理,然后将此计划转换为 Lean 证明草图。关键在于,草图在仅假设所提议引理为真的情况下证明当前目标:主定理主体无 sorry,而 sorry 占位符仅允许在新的提议引理语句中。此草图由 Verifier (Lean) 和 Reviewer (LLM) 验证。Reviewer 评估子目标是否相关并使问题更容易,充当搜索过滤器以防止 agent 扩展弱蓝图。
当草图被接受时,它作为 AND 节点添加,提议的引理作为子 OR 节点添加。这确保一旦所有子子目标被证明,父目标也被证明。State Writer 随后检查更新是否保持无环性,然后将其提交到 DAG。然后 agent 递归处理新创建的子目标。
证明计划的依赖结构如下 DAG 示例所示。
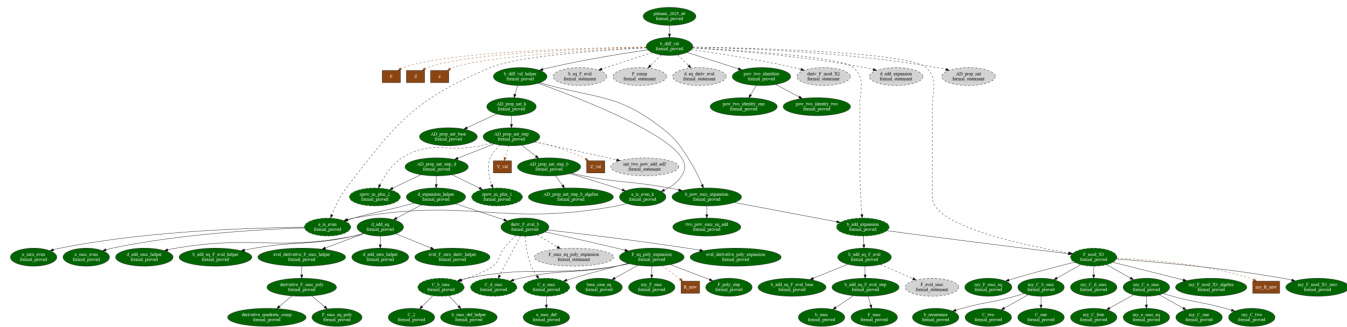
此结构支持两个主要优势。首先,单调细化允许搜索专注于扩展后代而无需重新构建已建立的依赖顺序。其次,引理记忆化将中间引理语句存储为共享节点,允许在出现相同子问题时在不同分支中重用。这也支持预期引理规划,其中提议当前草图未立即需要的辅助引理以支持后续证明步骤。
该方法依赖于三个紧密耦合的设计选择。通过 DAG 的分层记忆化保存进度并在分支间重用引理。交错的非形式化 - 形式化规划将自然语言策略与可执行的 Lean 代码连接起来,确保每次形式化尝试都配对非正式理由。最后,验证引导的证明搜索使用编译器反馈和基于 LLM 的审查来接受、修订、分解或放弃候选分支,有效地引导搜索通过形式化证明空间。
实验
评估在 Putnam 2025 和 Lean-IMO-Bench 数据集上针对多个基线评估 LEAP 框架,以验证其形式化证明能力。结果表明,LEAP 通过解决复杂的搜索瓶颈并在其他方法失败的挑战性基准上实现完全成功,显著优于专用和通用模型。消融研究进一步证明,系统的基于 DAG 的内存和 LLM 引导的审查机制对于减少冗余推导和修剪无生产力的证明分支至关重要,而针对开放组合问题的案例研究证实了该框架自主合成复杂数学任务严格证明的能力。
该研究比较了专用自动化定理证明器和通用基础模型之间的一次性和迭代形式化性能。当允许迭代修订步骤时,通用模型表现出显著改进,而专用模型从反馈循环中未显示任何益处。这突显了通用推理能力在处理迭代证明生成所需的复杂上下文中的重要性。通用基础模型在一次性和迭代评估设置中均优于专用证明器。迭代修订步骤为通用模型带来显著性能提升,而专用模型未能从反馈循环中受益。这些发现表明,解释编译器错误和保持上下文是通用模型优于专用证明器的能力。

作者将完整 DAG 架构与朴素树变体进行比较,以评估全局引理共享对形式化证明生成的影响。结果表明,Full DAG 配置始终优于基线,特别是在高级代数和数论任务中实现了完美的解决率。这表明维护全局证明内存显著增强了系统处理复杂数学推理的能力。Full DAG 配置在代数和数论方面在两个难度层级上均实现了完美性能,而树基线在高级数论方面遇到困难。整体性能显示 Full DAG 设置有显著改进,特别是在 Advanced 集,其中树基线表现显著更差。虽然几何仍然是最具挑战性的类别,但 Full DAG 配置设法解决了一些朴素树基线完全失败的问题。

数据展示了 Gemini 模型在 Lean-IMO-Bench 上的基线性能,涵盖三个评估任务:自然语言证明、形式化定理证明和形式化证明翻译。虽然自然语言证明生成取得中等成功,但模型在生成或翻译形式化 Lean 证明方面存在显著困难。性能从 Basic 集到 Advanced 集持续下降,突显了当前基础模型在没有专用 agent 框架的情况下处理复杂形式化验证的困难。自然语言证明生成优于形式化定理证明和证明翻译任务。所有评估任务在 Advanced 集上的性能相比 Basic 集显著下降。即使进行大量采样尝试,形式化任务的平均成功率仍然非常低。

该表格比较了 LEAP 框架与 Putnam 2025 基准上各种基线方法的问题解决能力。虽然直接形式化基线未能解决任何问题,但所提出的 LEAP 框架在整个数据集中实现了完美的解决率。此性能显著优于其他系统,包括解决了大部分但非全部问题的专用 Aristotle 模型。像 Gemini-3.1-pro 和 Goedel-Prover-V2-32B 这样的直接形式化基线未能解决任何基准问题。LEAP 框架成功解决了基准中的所有问题,实现了高于所有其他比较方法的更高成功率。像 Aristotle 和 Hilbert 这样的专用系统显示出部分成功,但未能达到 LEAP 实现的完全覆盖。

对 Lean-IMO-Bench 的评估将所提出的 LEAP 框架与直接形式化和 agent 基线在 Basic 和 Advanced 难度层级上进行了比较。结果表明,虽然基线方法在复杂性和特定领域(如几何)增加时存在显著困难,但 LEAP 表现出卓越鲁棒性和泛化能力。所提出的方法实现了最高的整体性能,并在代数和数论中无论难度如何均保持完美的解决率。LEAP 在基准测试中实现了最高的整体解决率,在两个难度层级上均优于专用和通用基线。基线模型在 Advanced 集上表现出显著的性能下降,而 LEAP 保持强一致性,包括代数和数论中的完美分数。几何被证明对所有方法都是一个困难类别,整体性能保持可忽略不计。
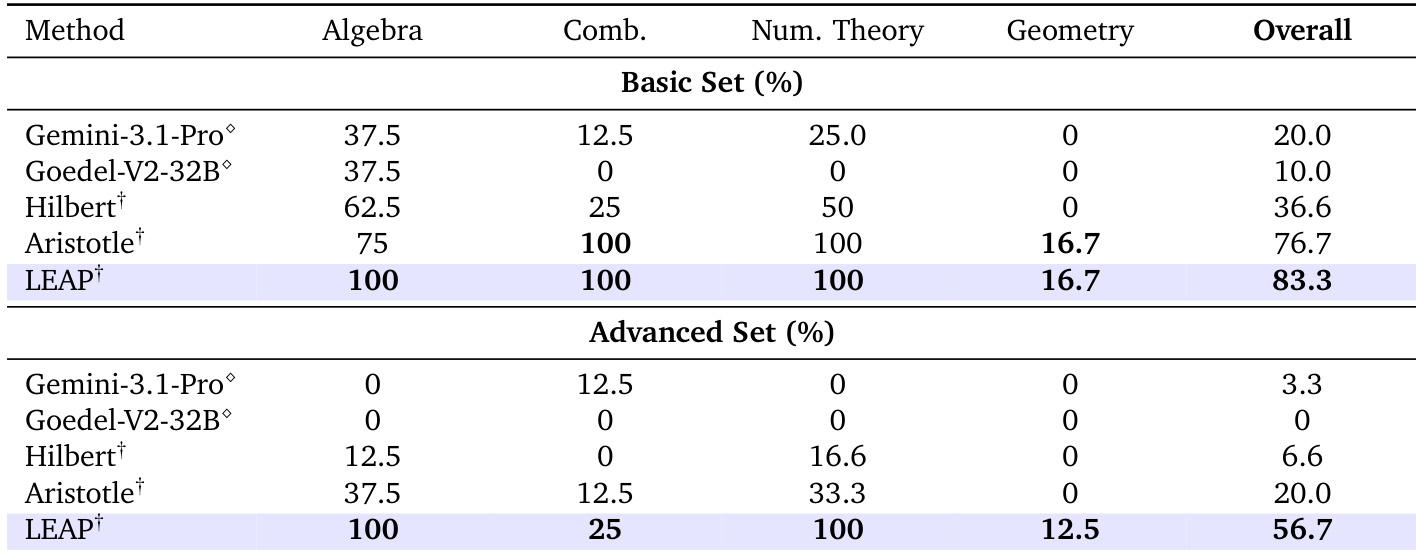
比较评估表明,通用基础模型从迭代修订步骤中显著受益,并在处理复杂推理上下文方面优于专用证明器。架构分析揭示,与朴素树基线相比,具有全局引理共享的 Full DAG 配置显著增强了高级代数和数论任务的性能。虽然标准模型在困难基准上难以进行形式化证明生成,但所提出的 LEAP 框架通过跨多个评估集实现完美解决率展示了卓越鲁棒性。