Command Palette
Search for a command to run...
关于 PEFT 的扩展:迈向万亿参数的百万级个性化模型
关于 PEFT 的扩展:迈向万亿参数的百万级个性化模型
摘要
参数高效微调(PEFT)通常被视为全量微调的廉价替代方案。我们研究其更广泛的作用:将小型可训练适配器作为强大共享基础模型之上的持久化局部状态。在此框架下,基础模型提供共享能力,而适配器则承载实例特定的行为,如偏好、技能、工具使用习惯以及类记忆更新。我们围绕三个扩展轴组织该问题:Scale Up,即更强的共享先验使小型局部更新更具效用;Scale Down,即我们研究适配器在保持可靠性的前提下可缩减至何种规模;以及 Scale Out,即大量持久化的适配实例共存。MinT 提供了一个基础设施范例,用于管理适配器的身份、版本修订、来源追溯、评估及服务驻留。综合结果表明,PEFT 可作为持久化个人模型的紧凑底层基础,而不仅仅是全量微调的预算替代方案。
一句话总结
将小型可训练适配器框架化为强大共享基础模型上的持久局部状态,本研究解决了三个耦合扩展问题,以支持通过大先验 LoRA 强化学习、δ-mem 设计和 MinT 基础设施实现数百万个万亿参数个人模型,证明参数高效微调保持了交互间的连续性并实现了基于多样性的聚合。
核心贡献
- 这项工作将参数高效微调重新框架化为共享基础模型上的持久局部状态,并定义了三个耦合扩展问题以指导适应研究。该框架通过大先验 LoRA 强化学习考察 Scale Up,通过面向内存的适配器设计考察 Scale Down,并使用基于多样性的聚合考察 Scale Out。
- MinT 作为一个具体的基础设施示例被提出,支持大型适配器群体的适配器身份、策略修订和服务驻留。该系统使机制能够支持强大基础模型服务于数百万个持久的个人助手。
- 来自万亿参数 LoRA 强化学习研究的实验表明,使用 LoRA 适配的更大基础模型比使用全参数强化学习训练的较小模型实现了更大的头寸归一化收益。这些结果表明,当学习预算固定时,先验强度比可训练表面大小更重要。
引言
当前的前沿模型缺乏维持持久个人状态的能力,尽管推理和工具使用取得了进展。先前工作将参数高效微调主要视为节省成本的措施,并依赖外部检索进行记忆,这无法高效捕捉习得的行为习惯。作者将适配器重新框架化为强大共享基础模型之上的紧凑自适应状态单元,以实现持久的个人实例。他们引入了一个三轴框架,解决基础模型强度、适配器稳定性和群体扩展问题。该团队在万亿参数混合专家模型上展示了万亿规模的 LoRA 强化学习,并表明多样化的适配器群体通过聚合实现集体智能。
方法
所提出的持久个人模型架构依赖于三个协调的扩展轴:Scale Up、Scale Down 和 Scale Out。作者利用生物学类比来说明模型扩展如何镜像人类发展。
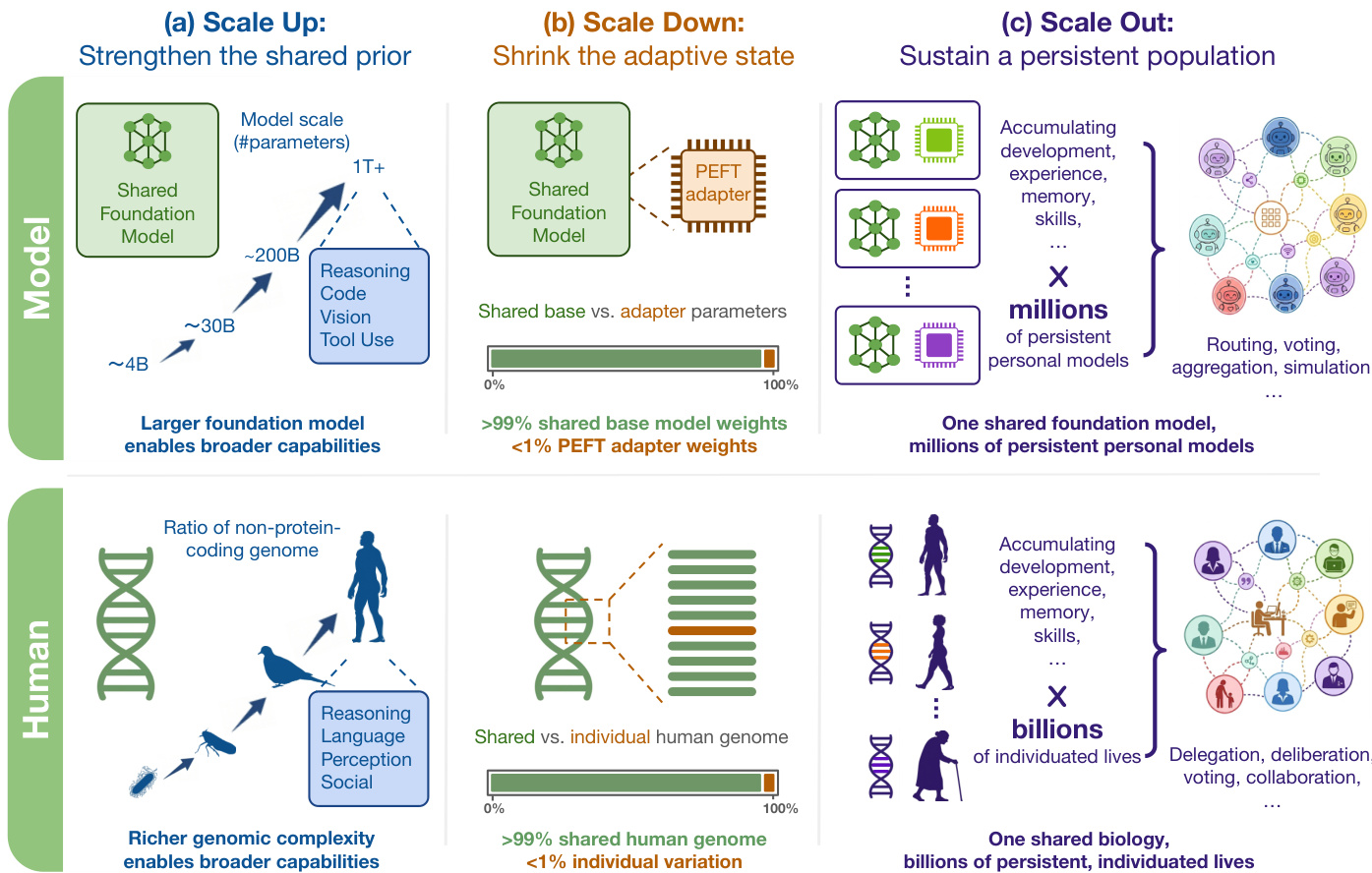
该框架将共享基础模型与个体自适应状态分离。Scale Up 使用万亿规模参数加强共享先验。Scale Down 缩小自适应状态以确保效率和稳定性。Scale Out 维持这些模型的持久群体。这些轴的细分突出了从个体适应到群体规模个性化的转变。
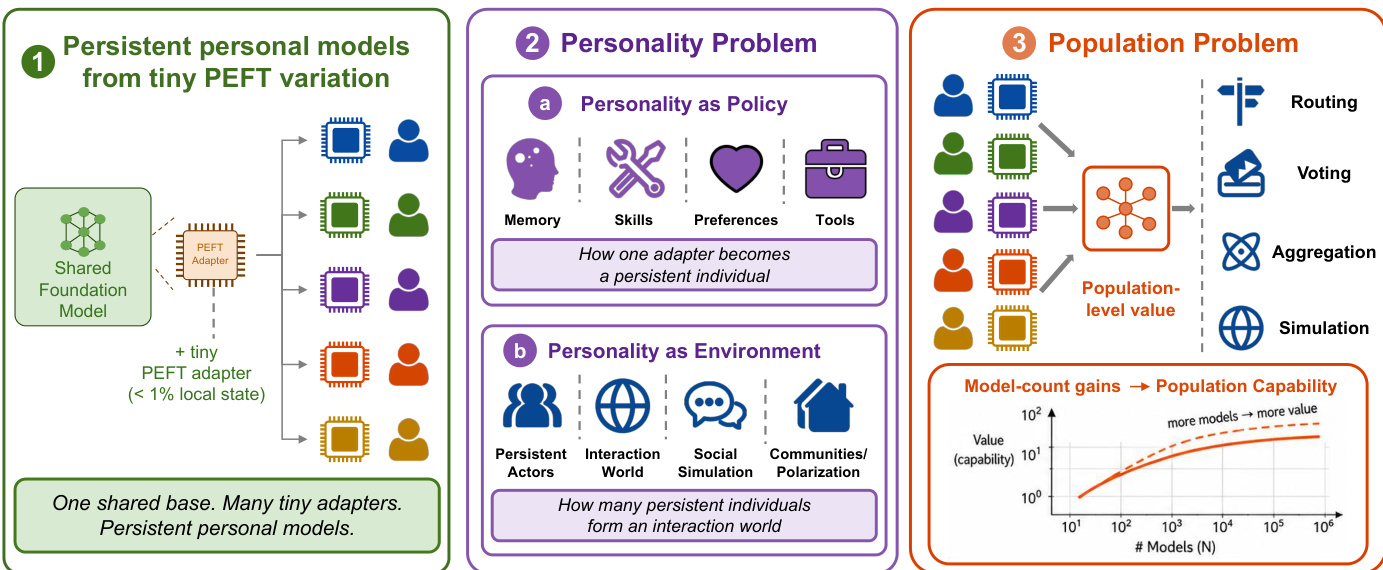
为实现 Scale Down,系统采用了超越静态低秩适应的高级适配器设计。一个关键模块是 δ-mem 状态化适配器,它维护紧凑的在线关联记忆状态。
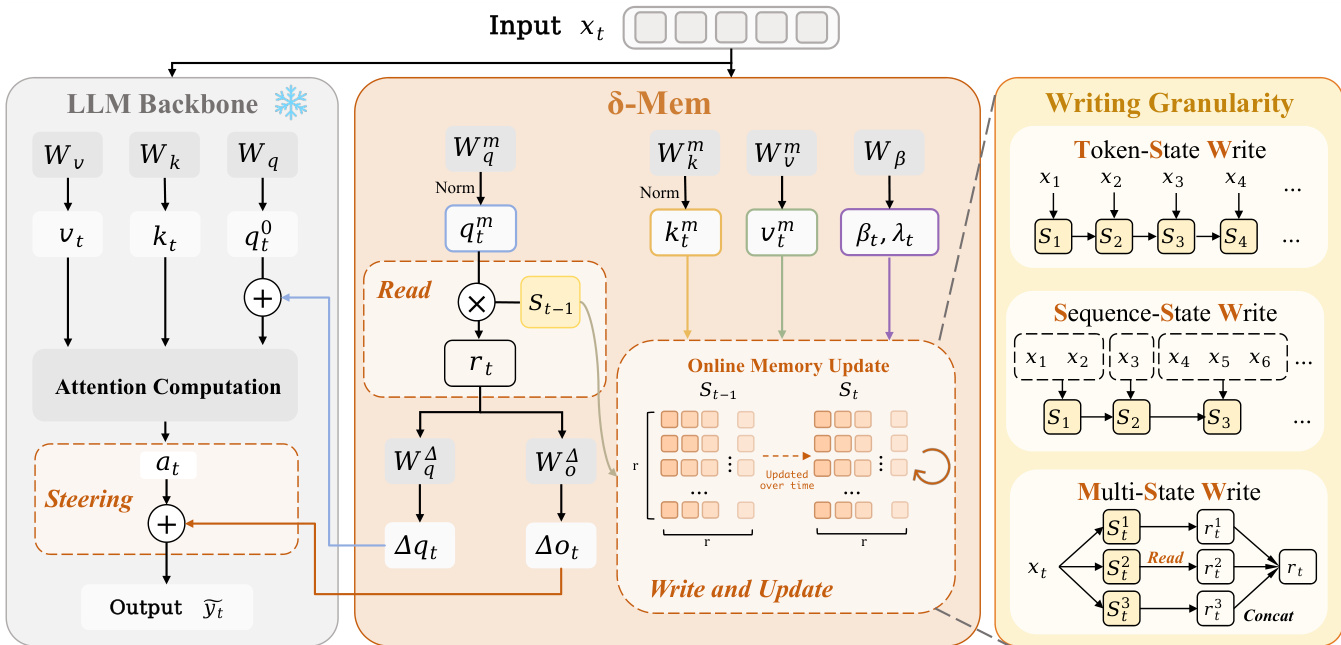
该架构用低维状态 St 增强冻结的骨干网络。该模块从先前的记忆中读取,生成修正,并使用 delta 规则更新写入更新信息。这使得适配器能够在不显著增加参数计数的情况下累积交互历史。
训练过程利用上下文蒸馏将上下文时间的改进转化为持久的参数更新。该方法分三个不同的步骤运行。
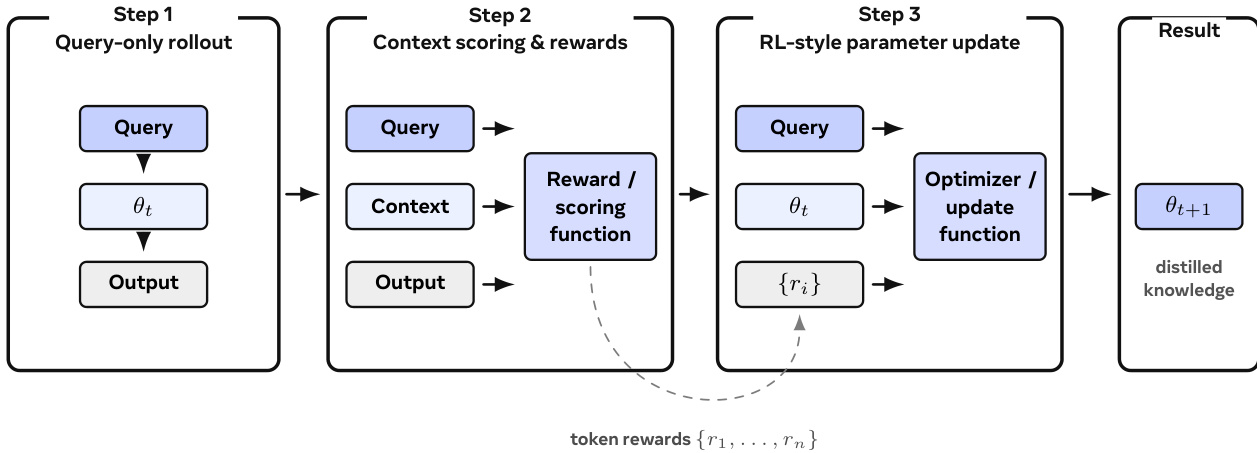
首先,模型执行仅查询的 rollout。其次,更强的系统使用检索到的证据或工具对输出进行评分。第三,RL 风格的更新根据此信号调整参数。这确保模型学习表现得更好,而无需在推理期间需要特权上下文。
管理该群体需要像 MinT 这样强大的系统层。基础设施分离训练和 rollout 工作者以处理不同的计算配置文件。
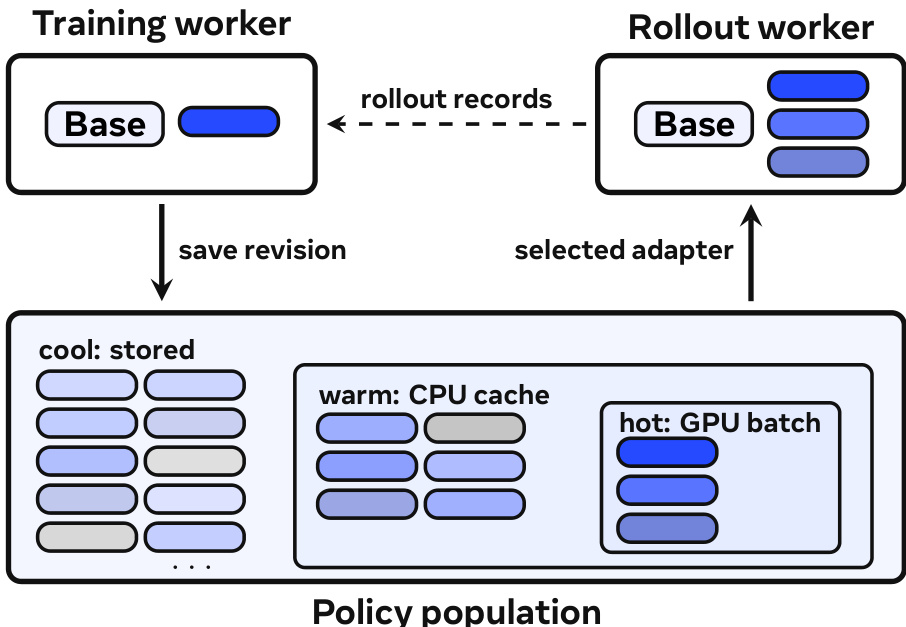
策略群体被组织为热、温、冷存储层以优化驻留。此设计支持个人模型的生命周期,其中训练更新适配器状态,导出保存用于服务的固定修订版。
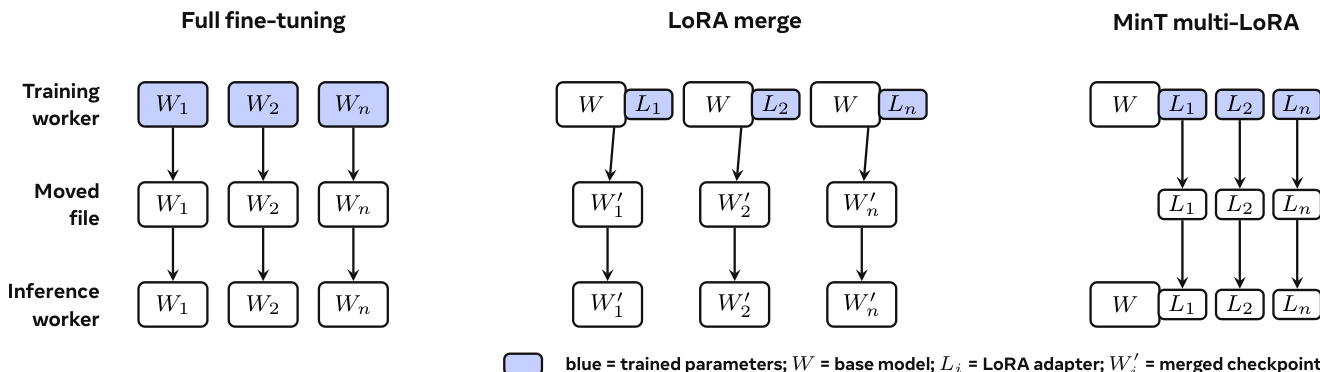
最后,系统证明群体能力随模型数量增长。扩展定律表明,适配模型之间的多样性成为集体性能的来源。
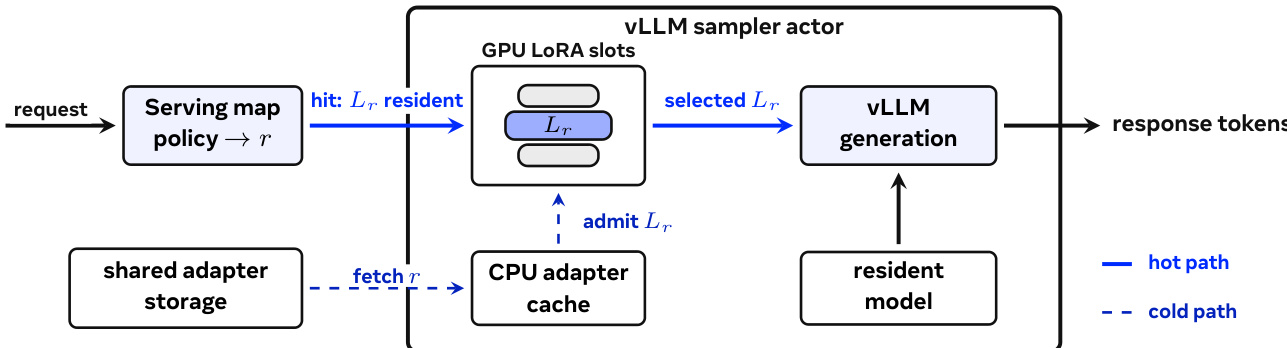
实验
评估秩缩减、初始化和超参数转移的实验表明,低秩适配器保留高潜力,但需要特定的优化策略以确保跨种子的可靠性。在 agent 模拟和集体智能任务中,每用户适配器比共享基础模型更好地维持行为多样性和性能,防止异构群体崩溃为统一策略。最后,基础设施测试表明,扩展到数百万实例需要将策略寻址与活动驻留分离,以有效管理服务成本和延迟。
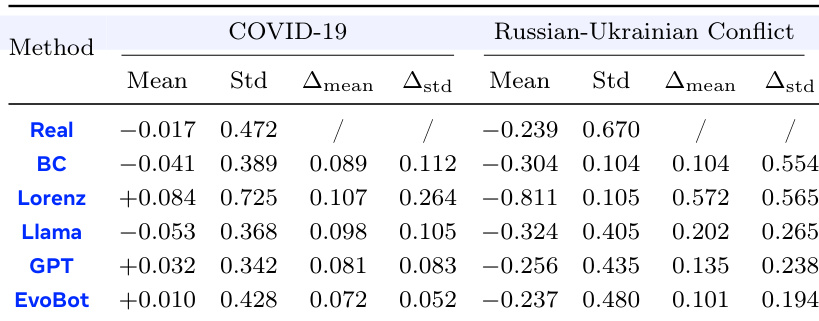
该实验评估了不同方法在 COVID-19 大流行和俄乌冲突期间模拟现实社会动态的能力。EvoBot 表现出与现实数据的优越统计对齐,显示与 Lorenz、Llama、GPT 和行为克隆等基线相比,均值和标准差的偏差显著降低。EvoBot 在大流行和冲突数据集上都实现了与现实世界统计的最接近匹配。Lorenz 方法表现出与真实数据最高的分歧,特别是在俄乌冲突场景中。标准 LLM 和行为克隆表现出中等性能,但无法匹配 EvoBot 方法的保真度。
该实验在具有不同群体规模的社会模拟环境中比较了每用户 LoRA 适配器与共享基础模型。数据表明,LoRA 配置始终产生更高的活动量和用户立场的更大多样性。此外,与共享基础控制相比,LoRA 群体表现出更有效的社区结构,同质性降低。LoRA agents 在所有测试的群体规模下比共享基础模型生成显著更多的评论和原始帖子。LoRA 条件下的立场分散度明显更高,支持和怀疑用户的标准差达到基础模型值的约两倍。LoRA 群体形成更有效的交互社区,同时表现出比基础条件更低的社区内侧向同质性。
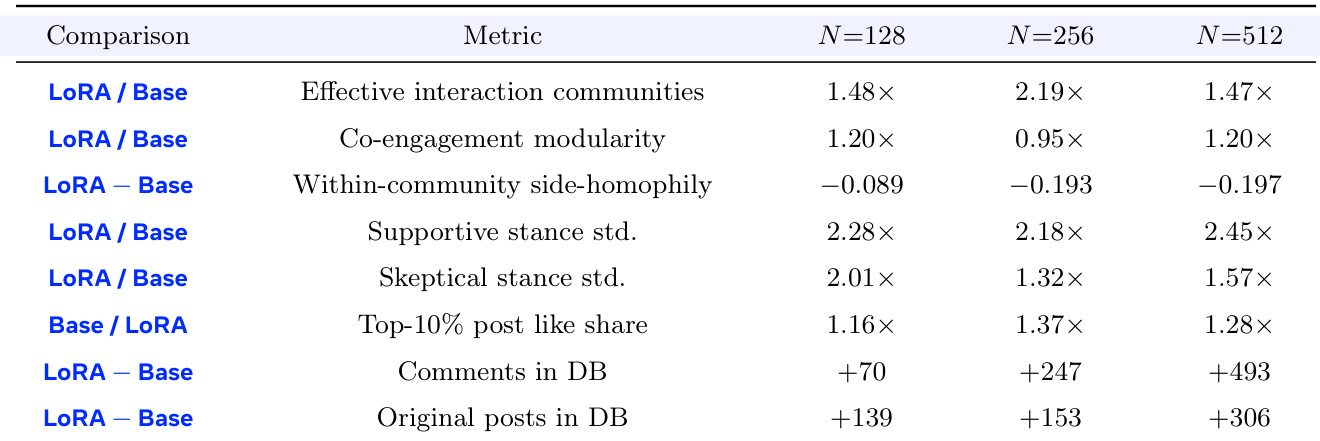
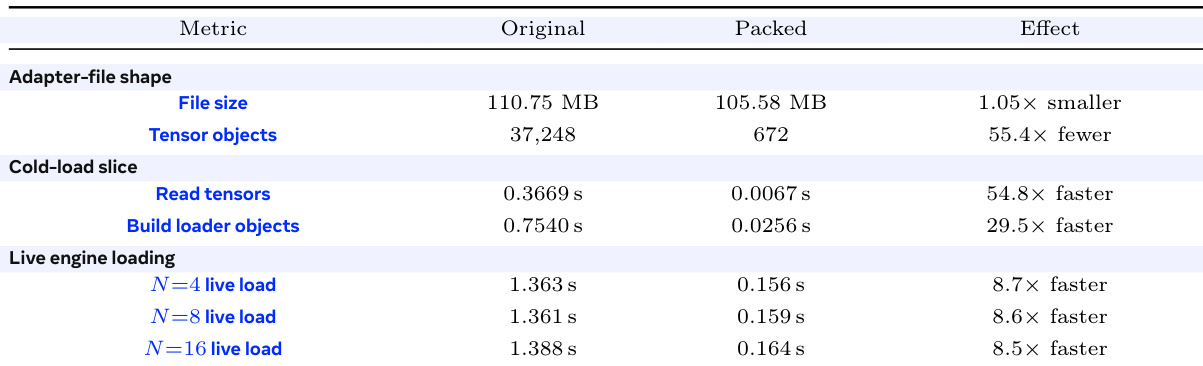
作者评估了打包适配器格式以优化大规模部署中的服务效率,重点关注减少冷加载开销。结果表明,虽然文件大小保持相似,但打包格式大幅减少了张量对象的数量,导致加载和初始化过程显著加速。打包将张量对象的数量减少了 50 多倍,同时保持相似的文件大小。冷加载操作,如读取张量和构建加载器对象,变得快约 30 到 55 倍。不同批量大小下的实时引擎加载时间提高了约 8.5 倍。
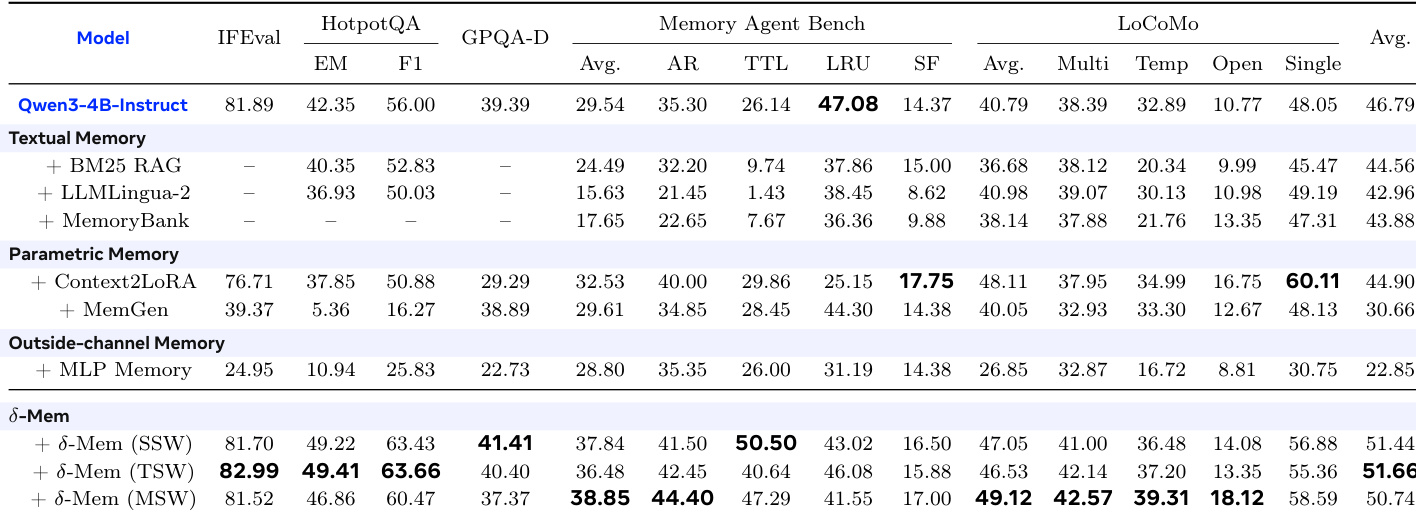
该实验在基础模型上评估各种记忆机制,比较文本检索、参数更新和外部通道方法与提出的 delta-Mem 变体。结果表明,虽然传统记忆增强通常相对于基础模型降低性能,但 delta-Mem 配置始终优于基线和其他记忆策略。不同的 delta-Mem 变体在推理、记忆和指令遵循任务中表现出稳健的改进。delta-Mem 变体始终优于基础模型和其他记忆方法,实现优越的整体性能。文本记忆和外部通道记忆方法在评估的基准测试中通常表现不如基础模型。特定的 delta-Mem 配置显示出独特的优势,不同的变体在特定类别中领先,如长上下文记忆或推理准确性。
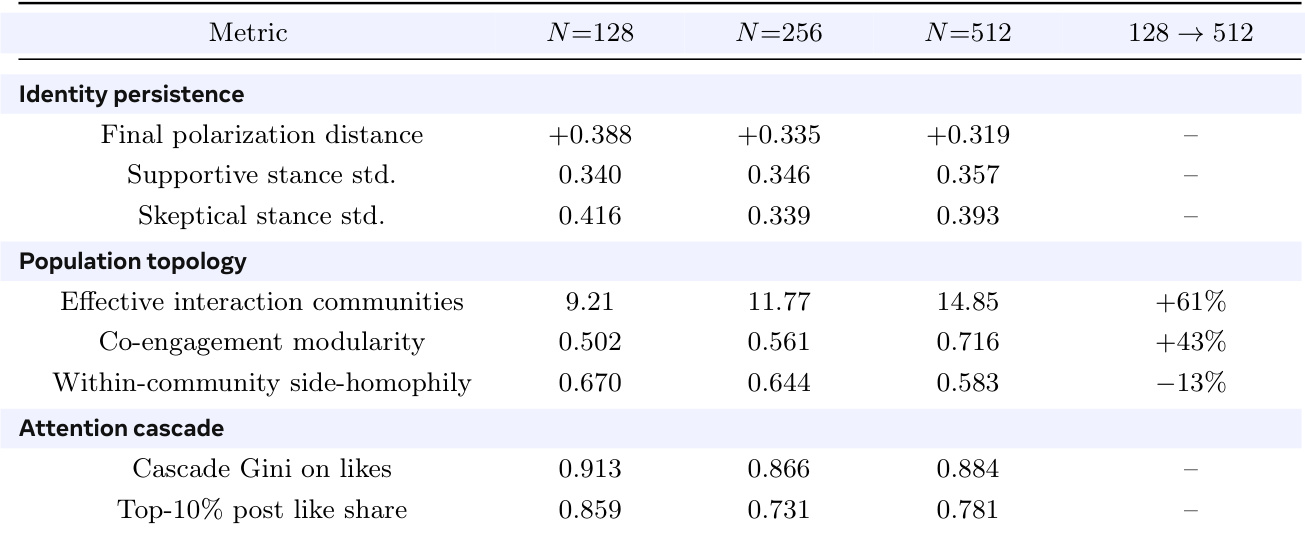
作者使用每用户 LoRA 适配器评估模拟社会环境的结构扩展,随着群体规模增加。结果表明,更大的群体形成更独特的交互社区,具有更高的模块化和降低的组内同质性。身份指标如立场标准差在群体规模之间保持一致,表明个体行为多样性在扩展过程中得以保留。随着群体规模增长,有效的交互社区和共同参与模块化大幅增加。社区内侧向同质性随群体规模增大而减少,促进更多样化的跨群体交互。支持和怀疑用户的立场标准差在不同的群体规模下保持稳定。
实验验证了 EvoBot 在模拟现实社会动态方面优于基线方法的能力,涵盖大流行和冲突数据集,同时表明每用户 LoRA 适配器比共享基础模型生成更多样化的活动和有效的社区结构。效率评估确认打包适配器格式显著减少加载开销,记忆机制测试显示 delta-Mem 变体在推理和指令任务中始终优于传统增强策略。此外,结构扩展分析显示,增加群体规模促进独特的交互社区并减少同质性,同时不损害个体行为多样性。