Command Palette
Search for a command to run...
K-BrowseComp:基于韩国语境的 Web 浏览 Agent 基准测试
K-BrowseComp:基于韩国语境的 Web 浏览 Agent 基准测试
摘要
前沿模型评估正从基础能力(例如指令遵循与推理)向组合式、agent相关的评估转变,但韩国agent基准测试依然稀缺。我们提出K-BrowseComp,这是一个基于韩国语境的网页浏览agent基准测试,共包含400道题目。其中包含300道题目的K-BrowseComp-Verified子集由韩语母语者手动构建并验证。在该子集上,包括GPT-5.5、DeepSeek-V4-Pro和GLM-5.1在内的前沿大语言模型得分仅为30.00--45.67%,相较于BrowseComp出现显著下降;而通过韩国专有AI基础模型计划发布的韩国大语言模型得分仅为0.00--10.33%。我们进一步构建了一个包含100道题目的合成划分,采用困难少样本示例与针对失败模式的生成方法,以利用解决网页浏览问题与构建网页浏览问题之间的不对称性。在对抗性过滤的合成诊断划分上,表现最强的模型得分仅为26.00%,我们将该划分单独作为针对性压力测试进行报告。我们已公开释放相关数据与代码。
一句话总结
本文提出 K-BROWSECOMP,这是一个面向韩国语境的网页浏览 Agent 基准测试,包含一个 300 道题目的手动验证子集和一个 100 道题目的 SYNTHETIC 划分。该划分通过高难度少样本示例与针对失败模式的生成方法构建。实验表明,包括 GPT-5.5、DeepSeek-V4-Pro 和 GLM-5.1 在内的前沿模型在验证集上的准确率仅为 30.00%–45.67%,在合成划分上的准确率为 26.00%,而韩国本土模型的得分介于 0.00% 至 10.33% 之间。
核心贡献
- 本研究提出 K-BROWSECOMP,这是一个基于韩国语境的 400 项任务网页浏览 Agent 基准测试,融合了本地搜索惯例、文化特定线索以及多网站导航需求。
- 开发了一套合成任务生成流水线,通过人工验证的题目识别反复出现的失败模式,并利用高难度少样本示例算法化地构建对抗性、针对失败模式的浏览问题。
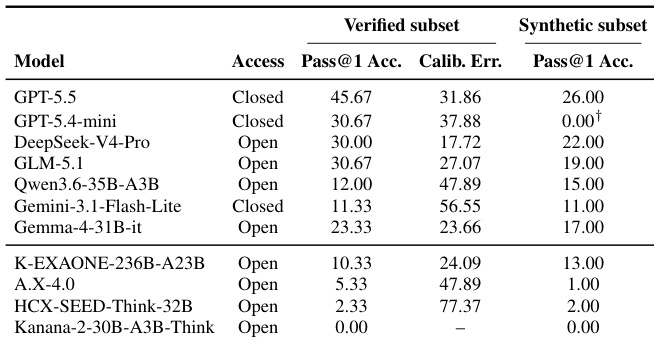
- 在 300 道题目的验证子集上的评估表明,前沿模型的准确率为 30.00% 至 45.67%,韩国本土模型的准确率为 0.00% 至 10.33%。在对抗性过滤的合成诊断划分上的性能进一步将最强模型的准确率限制在 26.00%。
引言
随着前沿模型向组合式 Agent 评估方向转变,韩国 AI 社区缺乏衡量浏览能力的标准化工具,这一空白威胁到本地 AI 主权并限制了跨语言泛化研究。此前的评估框架仍局限于静态语言任务,或依赖以英语为中心的网页基准测试,忽视了韩国搜索惯例、本地实体与文化语境。为弥补这一差距,作者提出 K-BROWSECOMP,这是一个扎根于本土文化的基准测试,用于检验模型在多个网站间检索与综合区域特定信息的有效性。作者利用一套新颖的合成生成流水线,将人工验证的失败模式与少样本示例相结合,以生成具有挑战性且可验证的任务,从而为开发针对韩国语境的浏览 Agent 建立稳健的诊断平台。
数据集
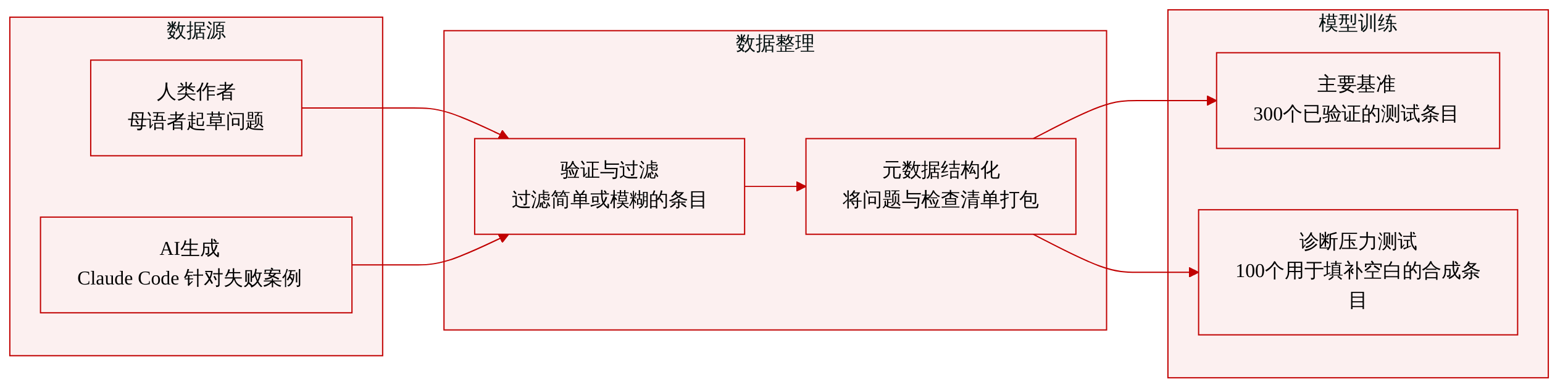
-
数据集构成与来源
- 作者提出 K-BROWSECOMP,这是一个包含 400 个条目的基准测试,旨在评估韩国网页浏览 Agent 在查找难以获取的公开信息方面的表现。所有条目均基于韩国语境,并严格来源于公开可访问的纯文本网页。该数据集明确排除私有、付费、需登录或非文本来源(如 PDF 和图像)。
-
子集详情
- K-BROWSECOMP-VERIFIED(300 个条目): 由韩语母语者手动构建,并经研究团队严格验证。编写者遵循严格指南,要求包含至少四步的多跳或并行分支推理,答案需具备唯一性与时间稳定性,且通过直接搜索难以发现但定位后易于验证。该子集在多跳(53.3%)与并行分支(46.7%)格式上均匀分布,其中娱乐与媒体类别占比最大(36.3%)。
- SYNTHETIC(100 个条目): 使用 AI Agent(Claude Code)生成,旨在针对验证集中识别出的特定模型失败模式创建对抗性问题。生成流水线利用种子页面与九类失败模式分类法,通过草稿、测试与修订循环优化草案。每个候选题目需通过三项连续筛选:可搜索性(防止直接暴露答案)、结构完整性(确保答案可从来源中唯一提取)以及对抗难度(要求仅具备基础搜索能力的模型失败)。该划分保留了推理格式的平衡,但将类别分布向科学、IT 与学术领域(33.0%)倾斜,并采用更长的提示词。
-
数据使用与处理
- 作者仅将该数据集用于评估,而非模型训练。不存在训练集划分或混合比例。验证子集作为衡量前沿模型与韩国本土大语言模型性能的主要基准,合成划分则作为针对性的诊断压力测试单独报告。作者通过分析模型轨迹来定位失败发生的位置,重点关注状态维护、约束跟踪与来源指针保留,而非简单的检索错误。
-
元数据构建与处理细节
- 所有条目均以结构化 JSON 格式提交与存储,包含问题陈述、标准答案、预期推理轨迹、来源 URL、韩国特定关键词及推理依据。作者实施了一套检查清单系统以验证中间推理步骤并确认证据路径。基于基础模型的错误,作者手动构建了轨迹级失败分类法(F1 至 F8),以指导合成生成与事后分析。针对划分诊断,作者使用多语言句子转换器对所有问题进行向量化嵌入,并训练分类器以测量问题长度、类别与推理格式分布的变化。由于该基准测试完全依赖文本证据与推理轨迹,因此未应用任何视觉裁剪操作。
方法
作者利用一套多阶段推理框架,旨在解决需要整合多源信息与约束条件的复杂多跳问题。模型的运行围绕一系列搜索与验证步骤构建,每个阶段均涉及检索候选实体或证据,并应用逻辑约束以优化解决方案。该过程的核心在于基于轨迹的方法,模型在所需状态的指导下生成一系列搜索查询,该状态明确了正确答案的必要条件。框架区分了代表理想解决路径的“标准轨迹”与反映模型实际执行(通常存在缺陷)动作序列的“模型轨迹”。
模型首先分析问题以识别所需状态,该状态封装了最终答案必须满足的逻辑条件。随后利用该状态引导一系列搜索查询,每项查询旨在检索相关信息或缩小候选集范围。模型可并行执行多个搜索分支,分别针对问题的不同方面。例如,在要求识别特定 K-pop 组合的问题中,模型可能先搜索前十二名参赛者,随后验证其国籍与专辑发行日期。然而,由于约束应用错误或过早锁定候选项,模型轨迹常偏离最优路径。如图所示,模型可能在所有上游约束得到验证前便锁定一个看似合理的候选项,导致最终答案虽具备局部证据支持,却无法满足完整的要求集合。
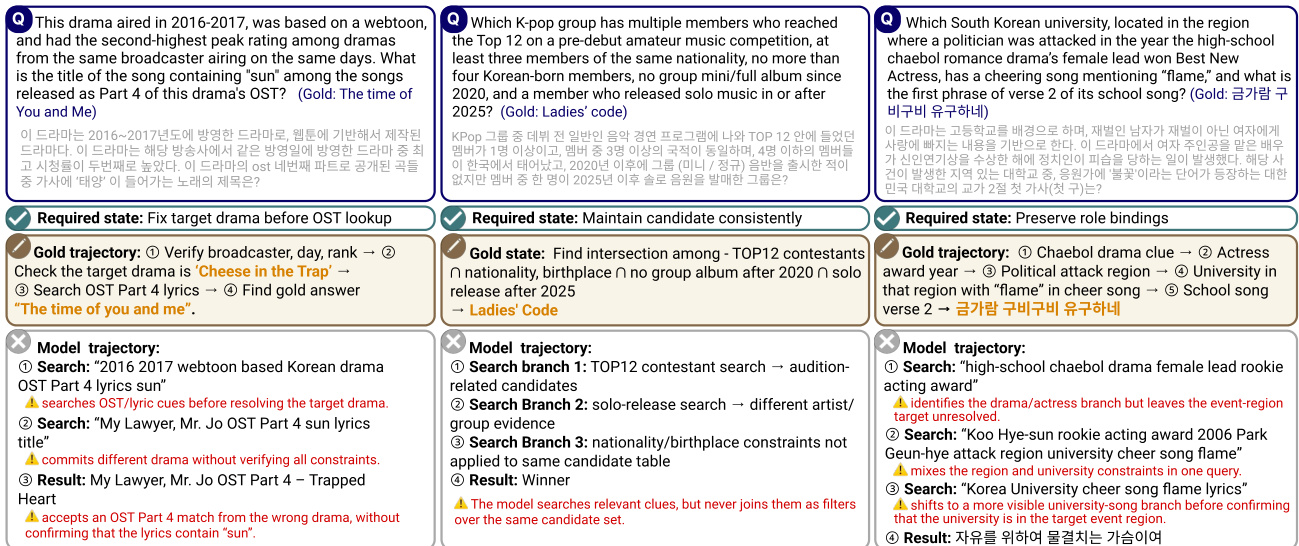
模型的搜索过程受信息处理顺序的显著影响。当模型基于部分证据锁定候选项时,框架易发生故障。例如,若模型在确认正确公司与品牌前便搜索获奖产品,可能被引导至一条合理但错误的路径,从而得出一组局部有效但不符合完整约束链的答案。该行为属于关键失败模式,即模型轨迹受最显著或最易获取的证据驱动,而非对所有必要条件进行系统性验证。模型轨迹通常由一系列搜索步骤构成,每一步均可能引入错误,如过滤不当、候选集合并失败或中间结果计算错误,最终导致答案错误。
实验
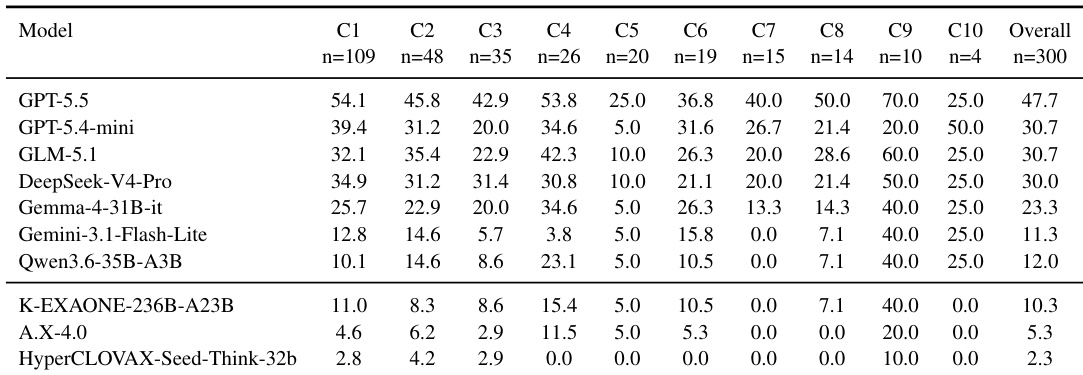
评估采用一套受限的深度研究 Agent,在 K-BROWSECOMP 基准测试及诊断性合成划分上对专有模型与开源权重模型(含韩国专用变体)进行测试。定性轨迹分析表明,性能瓶颈主要源于检索后失败,例如约束跟踪不佳、过早锁定候选项以及答案最终化不稳定,而非搜索投入不足。尽管简单领域的查询相对可控,但复杂的多步推理始终暴露出各类模型家族在长程状态维护方面的弱点。实验最终表明,当前大语言模型难以维持连贯的浏览轨迹,且韩国本土架构在真实网页搜索环境中相较于全球同类模型并未展现出明显优势。
作者在韩国网页浏览基准测试上评估了一系列专有与开源权重模型,结果显示即使表现优异的模型准确率也较低,尤其在诊断性合成划分上更为明显。各领域的性能差异显著,娱乐与体育类题目难度低于科学、IT 与教育类题目,且韩国开源权重模型表现不及全球同类模型。分析表明,大量失败发生在证据检索之后,通常源于在多步操作中未能维持约束、候选项与角色绑定的稳定性。即使领先模型在基准测试上的整体表现依然偏低,且在诊断性合成划分上准确率大幅下降。娱乐与体育类别难度较低,科学、IT 与教育类别难度较高,反映出网页浏览任务存在领域特异性挑战。许多错误出现在检索阶段之后,模型未能跨步骤维持一致的候选项、约束与角色状态。
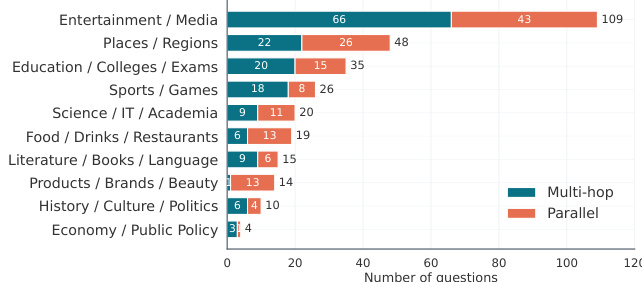
作者在韩国网页浏览基准测试上评估了一系列专有与开源权重模型,考察其在多个类别与失败模式下的表现。结果表明,尽管顶尖模型在特定领域能达到较高准确率,但多数模型在复杂多步推理与证据整合方面仍面临困难,韩国语境下的挑战尤为突出。表现优异的模型在某些类别上准确率较高,但在不同领域间存在显著差异。许多模型在检索到相关信息后,仍无法在多次搜索步骤中维持一致的证据与约束。韩国开源权重模型表现不及全球同类模型,表明尽管经过专项训练,其在长程推理与状态维护方面仍面临挑战。
作者在一项网页浏览基准测试上评估了一组专有与开源权重模型,重点关注性能表现与搜索投入模式。结果显示,模型在多次步骤中往往难以维持一致的状态,即使已检索到相关证据。错误尝试中更高的搜索使用率表明,失败主要源于推理与最终化阶段的缺陷,而非检索不足。韩国开源权重模型表现不及全球同类模型,在状态维护与答案稳定方面存在问题。模型常在检索到相关证据后发生错误,问题出在跨步骤丢失约束与候选项的追踪。错误尝试的搜索调用次数通常多于正确尝试,表明失败发生在推理与最终化阶段而非检索阶段。韩国开源权重模型相较于全球模型存在显著性能差距,在维持轨迹状态与生成结构完整的答案方面存在缺陷。
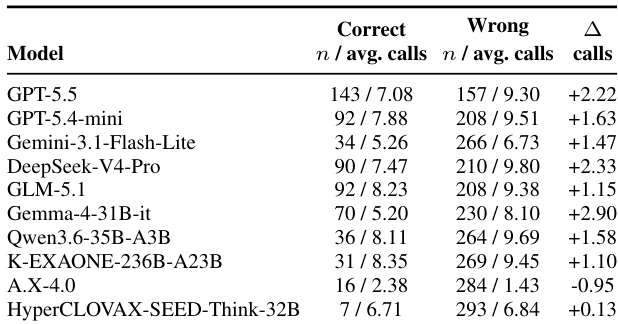
作者在韩国网页浏览基准测试上评估了一系列闭源与开源权重模型,结果显示专有模型表现显著优于开源模型,尤其在验证子集中更为明显。所有模型在合成划分上的性能均处于低位,表明在维持一致的证据整合与答案最终化方面仍存在持续挑战。韩国开源权重模型尽管经过专项训练,在轨迹级推理方面仍表现出明显短板,失败多发生在相关证据检索之后。专有模型在验证子集上的准确率大幅高于开源模型,表现最佳的模型 pass@1 指标超过 45%。所有模型在合成划分上的性能均显著下降,反映出维持一致推理与证据整合的难度。韩国开源权重模型不及全球同类模型,失败常因检索后的约束跟踪与答案最终化问题所致。
实验在韩国网页浏览基准测试上评估了专有与开源权重模型,以验证其在不同领域的多步推理、证据整合与状态维护能力。定性分析表明,性能因主题差异显著,娱乐与体育类题目难度低于技术领域,而大多数错误发生在检索到相关证据之后,主要受限于约束跟踪困难与一致推理状态维持失败。最终,专有模型表现大幅优于开源替代方案,后者尽管经过专项训练,在长程轨迹管理与答案最终化方面始终面临困难。