Command Palette
Search for a command to run...
一种用于多域强化学习中跨域干扰与恢复的局部扰动理论
一种用于多域强化学习中跨域干扰与恢复的局部扰动理论
Lei Yang Siyu Ding Deyi Xiong
摘要
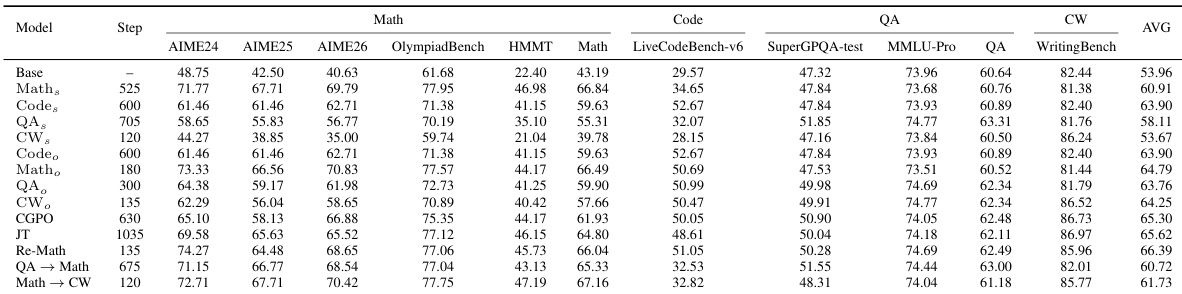
强化学习(RL)后训练能够提升大型语言模型(LLM)在数学推理、代码生成、问答及创意写作(CW)等单一领域上的表现,然而针对某一领域的训练往往会损害其在其他领域上的性能。基于灾难性遗忘或全局梯度冲突的现有解释尚不完整:即使全模型梯度几乎正交,仍可能发生显著的干扰。我们表明,单领域强化学习会产生稀疏且幅度较小的参数修改,且发生显著变化的神经元之间重叠度较弱;然而,不同领域仍共享大量活跃的计算路径,在这些路径上,更新方向决定了参数调整是产生协同作用还是相互冲突。受此观察启发,我们在多领域强化学习的局部扰动模型下证明,后续领域的训练主要通过一个二阶损伤项损害先前领域,而在所观察到的稀疏路径结构下,该损伤项会集中于一个低维的共享冲突子空间中。此外,短暂的领域刷新能够收缩该子空间上的有害分量,从而在限制附带损害的前提下实现选择性恢复。与理论预测一致,在 Code rightarrow Math rightarrow QA rightarrow CW 之后进行短暂的 Re-Math 刷新,可将 Math 领域的得分从 57.66 恢复至 66.04,同时基本保留了其他领域的性能,从而取得了 66.39 的最佳平均分。除刷新策略外,针对 Math-QA 对构建的稀疏代理冲突坐标集上执行无需训练的滚动回滚操作,也能部分恢复 Math 领域的性能,这为局部损伤提供了直接的代理层级证据。上述结果为多领域强化学习中的干扰与恢复机制提供了局部层面的机理解释。
一句话总结
作者们为大语言模型开发了一种局部扰动理论,将跨领域干扰解释为集中在低维共享冲突子空间中的二阶损伤项,并引入了一种简短的领域刷新机制,以选择性恢复早期任务的性能。在代码、数学、问答和创意写作的顺序训练后,Re-Math 刷新将数学推理分数从 57.66 提升至 66,验证了该方法的有效性。
核心贡献
- 单领域强化学习生成稀疏且幅值较小的参数更新,在发生最大变化的神经元之间重叠极小,这表明跨领域干扰源于共享活跃计算路径上冲突的更新方向。
- 局部扰动模型证明,顺序领域训练主要通过集中在低维共享冲突子空间内的二阶损伤项来削弱早期能力。
- 针对性的 Re-Math 刷新在该子空间内选择性收缩有害更新,实证将数学推理性能从 57.66 恢复至 66,同时保留了其他领域的能力。
引言
强化学习后训练对于赋予大语言模型多样化能力至关重要,然而顺序多领域训练经常引发非对称性退化,即优化某一任务会损害其他任务的性能。基于灾难性遗忘或全局梯度冲突的先前解释并不充分,因为即使全模型梯度近乎正交,仍可能发生显著的干扰,这使得局部损伤在聚合层面变得不可见。作者们提出了一种局部扰动理论,将跨领域干扰归因于集中在低维共享冲突子空间中的二阶损伤项,并证明尽管神经元层面的重叠较弱,但稀疏的参数编辑仍会通过重叠的活跃计算路径产生破坏性交互。他们进一步表明,简短的领域刷新能够以几何方式收缩这些有害组件,从而在限制附带损伤的前提下选择性恢复受损技能。代码、问答和创意写作能力的保留以及数学推理能力的显著恢复验证了这一点。
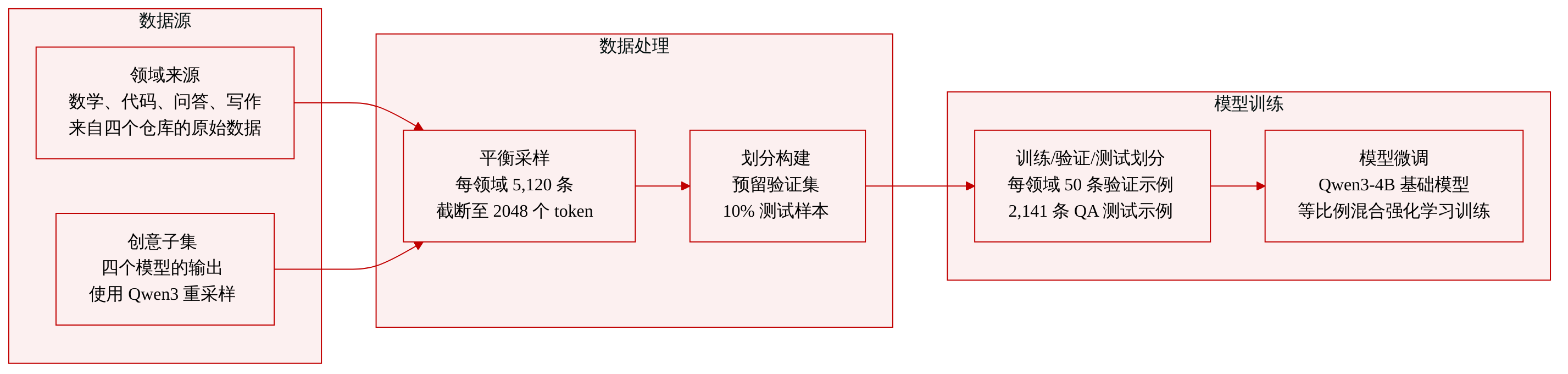
数据集
-
数据集构成与来源: 作者们构建了一个平衡的多领域强化学习数据集,涵盖数学推理、代码生成、问答和创意写作。数据来源于 OpenR1-math、KlearReasoner-CodeSub-15K、SuperGPQA 以及 crownelius/Creative-Writing 系列。
-
子集详情: 每个领域恰好包含 5,120 个训练样本。数学子集直接从 OpenR1-math 采样,代码子集来自 KlearReasoner-CodeSub-15K,问答子集则按子领域和难度从 SuperGPQA 中分层采样。创意写作子集融合了四个来源子集的样本(Sonnet4.6-800x、Gemini3Pro-2700x、Reasoning-KimiK2.5-600x 和 Qwen3.5Plus-2000x),并使用 Qwen3-235B-A22B-Instruct-2507 重新采样了 2,560 条回复以生成更新后的参考答案。验证集包含数学领域的 30 道 AIME25 题目,以及其余每个领域各 50 个保留样本。测试集包含 2,141 个问答样本和 1,203 个 MMLU-Pro 样本,均从非训练用的 SuperGPQA 和 MMLU-Pro 数据中采样。
-
使用与混合策略: 作者们在所有四个领域应用相等的混合比例,为每个任务分配 5,120 个样本,以在多领域强化学习期间保持领域暴露的平衡。该合并数据集作为微调 Qwen3-4B-Thinking-2507 基础模型的训练语料。
-
处理与裁剪: 所有训练提示词均截断至最大 2,048 tokens 长度。作者们通过从原始来源中明确移除训练数据来构建验证和评估划分,随后对剩余的问答和 MMLU-Pro 记录采样 10% 以确保测试集的无偏性。
方法
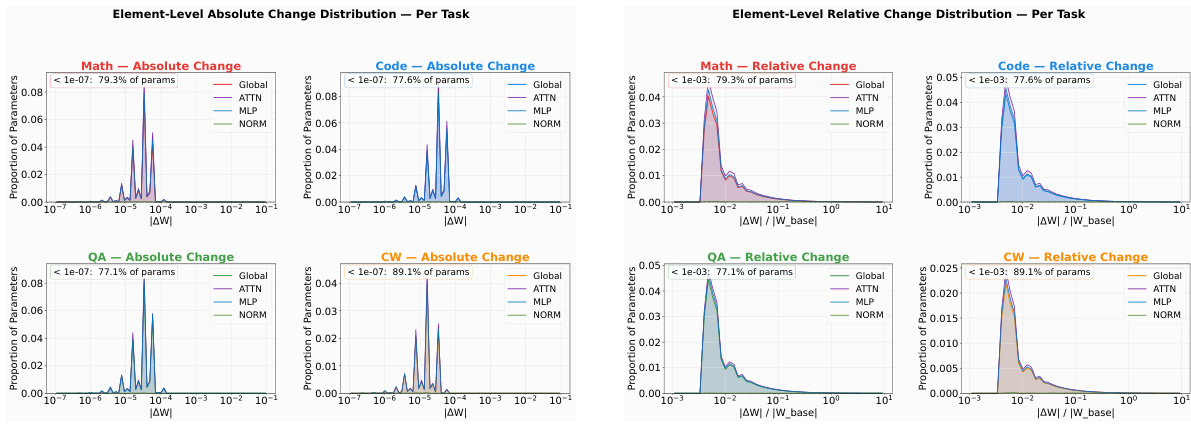
作者们通过顺序在不同领域训练时导致性能退化的结构机制,研究了多领域强化学习(RL)中的跨领域干扰。核心见解在于,干扰并非源于全局参数冲突,而是源于共享活跃计算路径内的局部交互。该框架始于以下观察:特定领域的 RL 更新是稀疏的、幅值较小的,且在不同领域间表现出微弱的重叠,这一点在相对于基础模型分析参数变化时得到证实。具体而言,在单领域专家模型中,约 77% 至 89% 的参数绝对变化低于 10−7,相对变化低于 10−3,这表明领域 RL 起到的是温和扰动作用,而非全局重写。这种稀疏性在神经元层面得到进一步检验,作者们将 MLP 中间通道定义为神经元,并聚合其 gate、up 和 down 投影中的参数变化以计算编辑幅值。针对每个领域,选取编辑幅值最大的前 10% 神经元,并使用 Jaccard 系数测量领域间的两两重叠。如下所示,这些重叠率始终较低,所有领域对的平均系数均低于 0.19,表明不同领域修改的神经元子集基本不重叠。 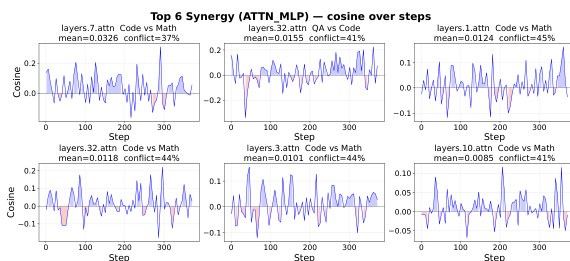
尽管存在这种微弱的编辑重叠,作者们证明跨领域干扰仍可能因沿共享活跃计算路径的方向错位而发生。为对此进行建模,他们引入了一个低维共享活跃冲突子空间 SA,B,该空间捕捉了参数空间中后续领域 B 的更新能够影响早期领域 A 目标的方向。引入该子空间的原因是观察到,尽管领域 RL 更新是稀疏且不同的,但它们仍可能通过共享的功能单元进行交互。领域 B 对领域 A 的干扰被量化为早期领域目标函数的增量 LA(θA∗+δB)−LA(θA∗),其中 θA∗ 为在领域 A 训练后的检查点,δB 为领域 B 诱导的局部更新。在标准局部平滑假设下,作者们推导出该干扰由 LA 在 δB 方向上的二阶曲率所主导。具体而言,干扰的主导项为 21δB⊤HA(θA∗)δB,其中 HA(θA∗) 是 LA 在 θA∗ 处的海森矩阵。该结果表明,即使更新很小或很稀疏,若与早期领域目标的高曲率方向对齐,仍会导致显著的性能退化。
通过将更新 δB 投影到共享活跃冲突子空间 SA,B,该分析进一步将二阶损伤局部化。命题 2 对此进行了形式化,表明干扰主要由投影 PSδB 决定,主导项为 21(PSδB)⊤HA(θA∗)(PSδB),误差项处于可控范围内。这种分解揭示出,干扰取决于后续领域更新中位于共享冲突子空间内的分量,而非完整更新。因此,低参数重叠并不意味着低干扰;若后续领域更新在 SA,B 上的投影较大,仍会损害早期领域。这也解释了全局梯度近乎正交为何能与选择性退化共存:尽管全模型梯度可能近乎正交,但沿共享曲率敏感方向的局部二阶位移仍可能主导损伤。
随后,作者们提出了一种简短刷新机制以恢复受影响领域的性能。从退化检查点 θ0=θA∗+δB 开始,对领域 A 的简短刷新执行梯度下降更新 θt+1=θt−αgA(θt)。在假设 LA 限制于 SA,B 时具有正曲率,且正交补空间向该子空间的反向耦合较弱的条件下,SA,B 内的有害分量呈几何级数收缩。定理 1 量化了该衰减过程,表明 ∥PS(θt−θA∗)∥2≤(1−αμA)t∥PSδB∥2,其中 μA>0 为局部曲线下界。这种几何收缩意味着,早期刷新步骤即可快速移除导致早期领域退化的分量,而无需进行完整重训练。恢复过程具有选择性,因为刷新主要收缩领域 A 敏感的分量,而其他领域的影响因全局近乎正交性而受到限制。作者们进一步将该分析扩展至交替刷新,表明一次交替刷新周期近似于加权多领域目标上的下降步骤,这可能导致领域间的局部帕累托平稳妥协。该框架为选择性干扰与恢复提供了局部解释,强调控制局部路径级交互是实现稳定且可扩展多领域 RL 的关键。
实验
评估利用跨推理与创意任务的顺序多领域强化学习,以研究模型训练期间的跨领域干扰。梯度与激活分析验证,性能退化并非源于全局梯度冲突或直接参数重叠,而是稀疏更新沿共享活跃计算路径交互所致,从而产生局部且定向的损伤。任务级恢复实验与无需训练的权重空间干预进一步证实,该干扰具有高度选择性,可通过简短的领域刷新或对冲突代理的针对性回滚高效缓解,最终证明多领域退化源于低维共享子空间上的二阶损伤,而该损伤允许有效的局部修正。
作者们考察了顺序强化学习中的跨领域干扰,表明性能退化并非由全局梯度冲突或广泛的神经元编辑引起,而是源于稀疏更新沿共享活跃计算路径的交互。结果表明,简短刷新能够以极小的附带影响选择性恢复某一领域的性能,且对冲突子空间代理进行针对性回滚可在无需重训练的情况下显著恢复丢失的性能。跨领域退化源于共享活跃计算路径上的稀疏更新,而非全局梯度冲突。简短刷新选择性恢复领域性能,对其他领域的副作用有限。对冲突子空间代理的针对性回滚可在无需重训练的情况下恢复大部分性能损失。
作者们通过分析梯度交互、活跃计算路径及参数更新的方向对齐情况,研究了多领域强化学习中的跨领域干扰。结果显示,干扰并非由全局梯度冲突驱动,而是由影响共享计算路径的稀疏更新引起,方向对齐决定了该效应是协同还是冲突。这些发现得到了通过简短刷新和针对性回滚实验在任务级恢复性能的支持,且附带效应极小。跨领域干扰源于共享活跃计算路径上的稀疏更新,而非全局梯度冲突。共享神经元上更新的方向对齐决定了干扰是协同还是冲突,领域对之间观察到非对称效应。简短刷新与针对性回滚实验证明了性能的选择性恢复,且对其他领域的影响有限。
作者们考察了多领域强化学习中的跨领域干扰,重点关注稀疏更新如何沿共享计算路径交互。结果表明,尽管全局梯度近乎正交且参数变化稀疏,但数学、代码和问答等领域共享活跃计算路径,从而导致定向干扰。简短刷新或对冲突子空间代理的针对性回滚可在副作用有限的情况下选择性恢复性能。这些发现支持局部冲突机制,而非全局梯度对抗。跨领域干扰由沿共享活跃计算路径的稀疏更新驱动,而非全局梯度冲突。简短刷新或针对性回滚可选择性恢复性能,对其他领域的影响极小。干扰具有定向与非对称特征,后续领域训练对早期领域的影响更为显著。
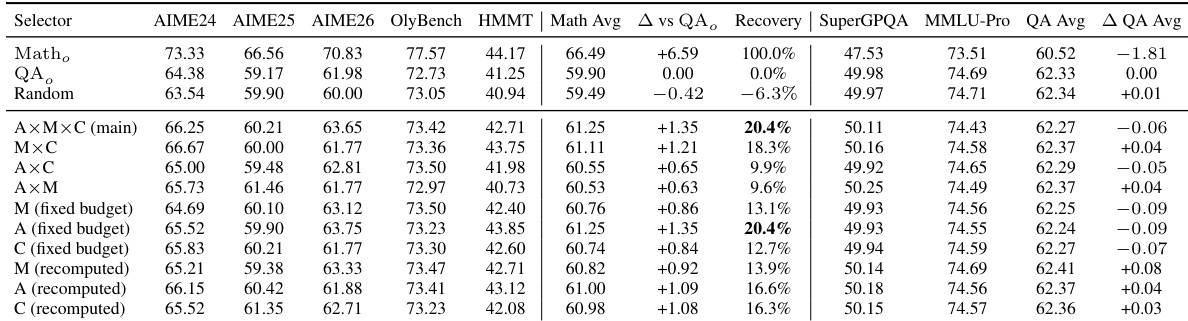
作者们分析了多领域强化学习中的跨领域干扰,表明性能退化并非源于全局梯度冲突或直接神经元重叠,而是稀疏更新影响共享活跃计算路径所致。他们证明,简短刷新能够以极小影响选择性恢复某一领域的性能,且对冲突子空间代理的针对性回滚可在无需重训练的情况下恢复大量损伤。结果表明,干扰具有定向与局部特征,领域间的性能变化呈现选择性与非对称性。跨领域退化源于共享活跃计算路径上的稀疏更新,而非全局梯度冲突或神经元重叠。简短刷新选择性恢复目标领域性能,对其他领域的副作用有限。对冲突子空间代理的针对性回滚可在无需重训练的情况下恢复大量损伤,从而支持干扰的局部化特性。

作者们研究了多领域强化学习中的跨领域干扰,聚焦于稀疏更新如何沿共享计算路径交互。结果显示,干扰并非由全局梯度冲突引起,而是源于共享活跃路径上的局部更新,方向对齐决定了协同或冲突。该研究通过简短刷新的选择性恢复及对冲突坐标的针对性回滚验证了这一点,证明无需重训练即可缓解损伤。干扰源于共享计算路径上的局部更新,而非全局梯度冲突。简短刷新选择性恢复性能,对其他领域的副作用极小。对冲突坐标的针对性回滚可在无需重训练的情况下恢复大量损伤。
实验通过分析跨多个知识领域的梯度交互、方向对齐及活跃计算路径,评估了顺序强化学习中的跨领域干扰。分析表明,性能退化源于稀疏参数更新沿共享计算路径的交互,而非全局梯度冲突或广泛的神经元重叠。通过简短刷新周期与针对性回滚程序的验证证实,干扰具有高度局部化与非对称特征,前者选择性恢复领域性能,后者在无需重训练的情况下恢复大量损伤。这些发现确立了一个结论:缓解跨领域退化需要解决稀疏路径交互问题,而非应用广泛的梯度修正。