Command Palette
Search for a command to run...
Harness-1:利用状态外化 Harness 进行搜索代理的强化学习
Harness-1:利用状态外化 Harness 进行搜索代理的强化学习
Pengcheng Jiang Zhiyi Shi Kelly Hong Xueqiang Xu Jiashuo Sun Jimeng Sun Hammad Bashir Jiawei Han
摘要
搜索智能体(Search Agents)通常被训练为基于不断增长的对话/交互记录的策略模型:模型必须在进行搜索决策的同时,记住已观察到的信息、判断哪些证据有用、哪些约束仍未满足,以及哪些主张已被核实。我们认为,这种设计将过多的常规状态管理工作置于策略内部:强化学习(RL)被迫同时优化语义搜索决策和环境可以更可靠地维护的可恢复性记账(bookkeeping)工作。为此,我们引入了 Harness-1,这是一个包含状态管理搜索框架(Harness)的 200 亿参数检索子智能体(retrieval subagent),并使用强化学习在其内部进行训练。该搜索框架在环境侧维护工作记忆,包括候选池、带有重要性标签的精 curated 集、紧凑的证据链接、验证记录、压缩去重后的观察结果,以及基于预算感知的上下文渲染。策略则保留语义层面的决策,具体包括:搜索什么、保留或丢弃哪些文档、验证什么,以及何时停止。在涵盖网页、金融、专利和多跳问答(multi-hop QA)的八个检索基准测试中,Harness-1 实现了 0.730 的平均精 curated 召回率(average curated recall),比下一个最强的开源搜索子智能体高出 11.4 个百分点,并与参数量大得多的前沿模型(frontier-model)搜索器保持竞争力。
一句话总结
Harness-1 是一个 20B 搜索 agent,在状态化搜索 harness 中通过强化学习进行训练,该 harness 将常规状态管理外化到环境中,而策略保留语义决策,在涵盖网络、金融、专利和多跳 QA 的八个检索基准上实现了 0.730 的平均精选召回率,比下一个最强的开源搜索 subagent 高出 11.4 分。
核心贡献
- 本文介绍了 Harness-1,一个在状态化搜索 harness 中通过强化学习训练的 20B 搜索 agent。这种形式将常规状态管理从策略中移出并放入环境,以实现更可靠的记账。
- harness 维护环境侧的工作记忆,包括候选池、带有重要性标签的精选集、紧凑的证据链接和验证记录。策略保留语义决策,例如搜索什么、保留哪些文档以及何时停止。
- Harness-1 在涵盖网络、金融、专利和多跳 QA 的八个检索基准上实现了 0.730 的平均精选召回率。该方法比下一个最强的开源搜索 subagent 高出 11.4 分,并且与更大的前沿模型搜索 agent 保持竞争力。
引言
搜索 agent 通常作为增长中的转录本上的策略运行,它们必须在决定如何搜索的同时管理记忆和证据。这种形式将过多的常规状态管理置于策略内部,迫使强化学习优化语义搜索决策以及环境可以更可靠地维护的可恢复记账。研究引入了 Harness-1,一个在状态化搜索 harness 中通过强化学习训练的 20B 搜索 agent。该 harness 维护环境侧的工作记忆,包括候选池和验证记录,允许策略仅保留语义决策,例如搜索或验证什么。这种分离使 Harness-1 能够在八个检索基准上平均比现有的开源搜索 subagent 高出 11.4 分,同时与更大的前沿模型保持竞争力。
数据集
- 数据集构成与来源: 研究利用在 Harness-1 harness 内原生运行的 GPT-5.4 生成了监督微调轨迹。数据涵盖百科全书式网络搜索、金融备案、专利和多跳问答领域。
- 子集详情: 原始配额目标为 300 BC+、250 SEC、150 专利和 150 网络样本,以及简化变体。0.10 召回率门限过滤掉低质量轨迹,最终形成包含 899 条轨迹的语料库。
- 训练使用: 899 条轨迹经过每条轨迹的扩展,转化为回合条件数据,产生约 26K 个训练示例。该数据用于训练策略进行工具选择和文档管理。
- 处理与元数据: 搜索观察结果使用 BM25 句子压缩处理,限制为每个块的前 4 个句子。内容去重应用 MinHash-LSH,使用 64 个排列和 0.85 阈值。自动填充功能在首次搜索后将前 8 个重排序结果添加到精选集,并标记为 [AUTO-POPULATED] 标签。
方法
研究介绍了 Harness-1,这是一种围绕状态化认知卸载原则设计的检索 agent 架构。在该框架中,策略免于维护搜索状态的负担,使其能够专注于语义决策,例如查询构建和证据选择。环境维护一个在 episode 过程中演变的持久工作记忆。
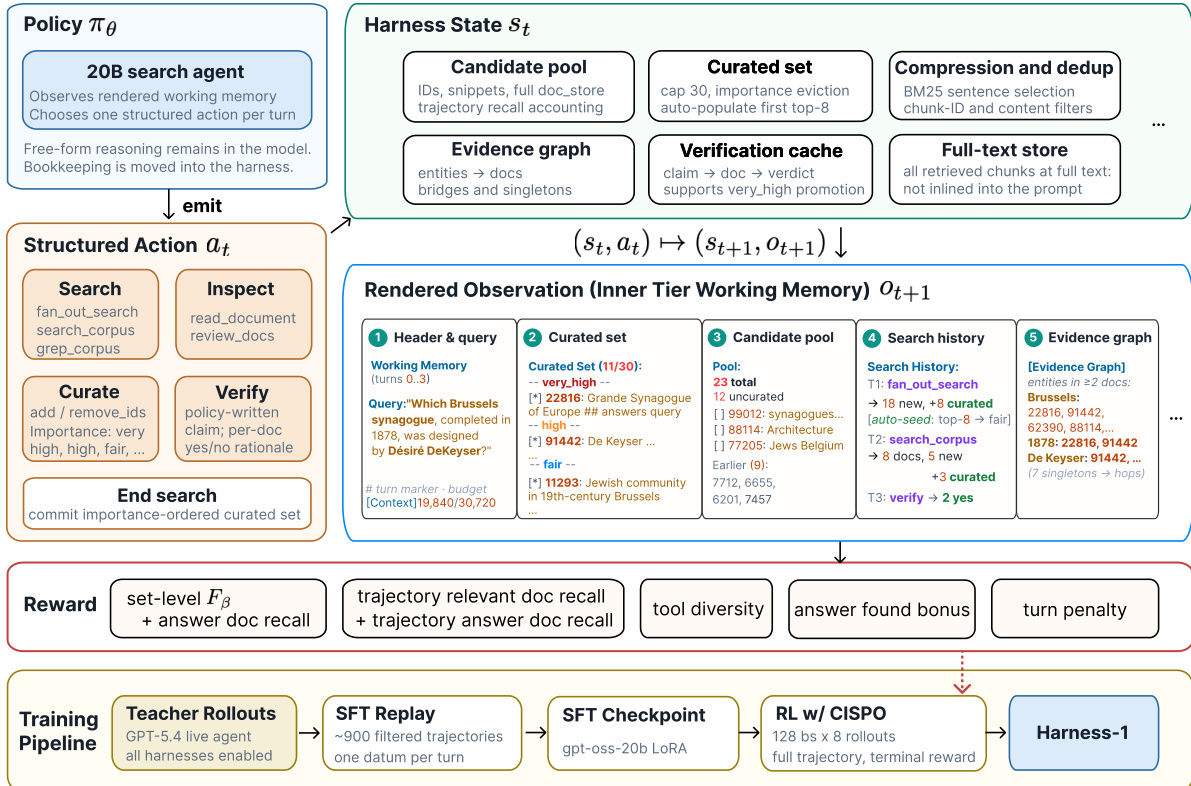
参考上方的框架图以查看策略与 harness 之间的交互。该系统作为一个状态机运行,其中转换定义为 (st,at)↦(st+1,ot+1)。harness 状态 St 包括未精选文档的候选池、最多 30 项并带有重要性标签的精选集、总结跨文档实体链接的证据图以及验证缓存。全文存储保留所有检索到的块以供后续检查,而不会使提示杂乱。
策略 πθ,实例化为 20B 参数模型,观察此状态的渲染版本,称为工作记忆。基于此观察,模型每回合发出单个结构化动作 at。这些动作分为检索、检查、精选、验证和终止。检索动作如 fan_out_search 和 search_corpus 将新证据带入候选池。精选动作允许策略向精选集添加或移除文档,并分配重要性级别,如 very_high、high、fair 或 low。验证动作使策略能够编写声明并根据全文存储进行检查。
为了确保高效的训练和推理,harness 采用派生状态渲染。搜索观察结果使用 BM25 句子选择进行压缩,并在到达提示之前通过内容指纹进行去重。渲染的观察结果 Ot+1 包括带有查询的标题、按重要性分组的精选集、候选池、搜索历史和证据图。这种紧凑表示防止上下文溢出,同时保留可操作信息。
训练管道由两个阶段组成。首先,在由教师 agent 生成的轨迹上执行监督微调 (SFT)。此阶段教会模型正确的工具调用格式以及搜索后精选的节奏。其次,使用 CISPO 算法应用强化学习 (RL)。RL 过程使用终端奖励信号在完整搜索 episode 上优化策略。该奖励结合了集合级质量指标、轨迹覆盖、答案证据奖金、工具多样性激励和回合惩罚,以鼓励高效和准确的搜索行为。
实验
Harness-1 在八个不同的检索基准上进行了评估,使用以召回率为导向的指标来评估证据覆盖范围,对比开源和前沿基线。该 agent 在保留的迁移任务上表现出比源族基准更强的增益,验证了其学习的是通用搜索操作而非特定数据集模式。消融研究表明,禁用 harness 机制会导致策略回归到浅层搜索模式,而模块化 RAG 测试显示这些精选集提高了下游答案的准确性。
本文介绍了 Harness-1,一个 20B 搜索 agent,在开源检索模型中实现了最强的平均召回率,同时与更大的前沿模型保持竞争力。结果强调,该 agent 的性能严重依赖于状态化 harness 设计,这使得其在保留的迁移基准上比训练数据源具有更好的泛化能力。消融实验进一步证明,特定的 harness 机制对于高质量证据精选至关重要,因为移除它们会导致性能显著下降。Harness-1 在平均精选召回率方面优于其他开源 agent 和大多数前沿模型,只有 Opus-4.6 在平均表现上更好。该模型表现出卓越的迁移能力,在训练集中未包含的基准上显示出比训练集中包含的基准更大的性能增益。禁用单个 harness 机制会导致召回率和最终答案准确率的持续下降,验证了状态化接口的重要性。
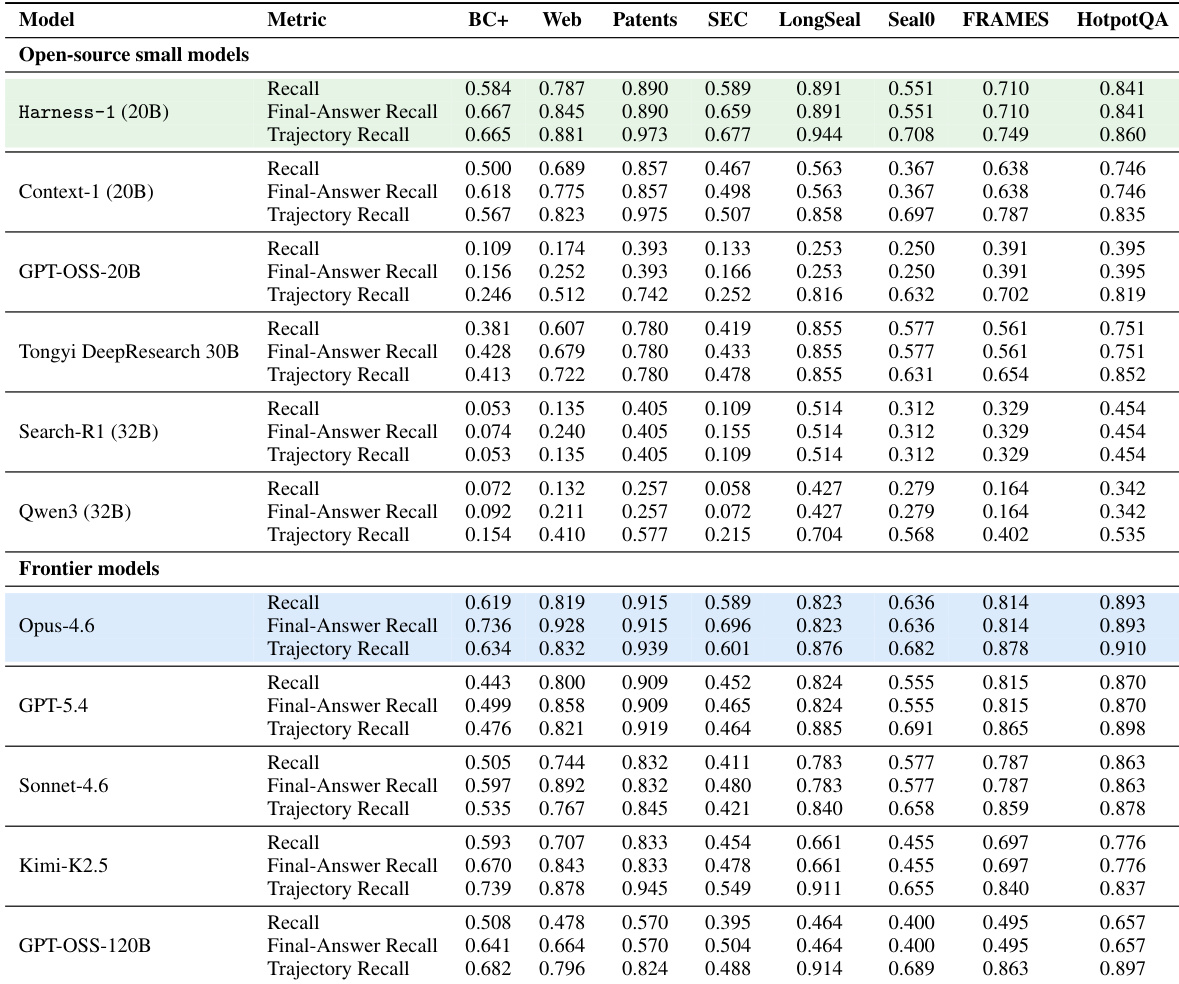
该表格展示了 Harness-1 系统在 BrowseComp+ 基准上的消融研究,隔离了各个推理时机制的影响。结果表明,大多数组件,如重要性标签和证据图,对于维持搜索质量至关重要,因为禁用它们会导致性能下降。此外,同时移除所有 harness 机制会导致比任何单个消融更严重的召回率下降,证实状态化接口对于 agent 有效精选证据的能力是根本性的。禁用大多数单个 harness 机制会导致最终答案召回率持续下降。harness 的累积效应显著,完整系统以较大优势优于所有机制禁用的版本。内容指纹去重是唯一的例外,由于数据集中存在近重复黄金文档,移除后显示出轻微的性能提升。
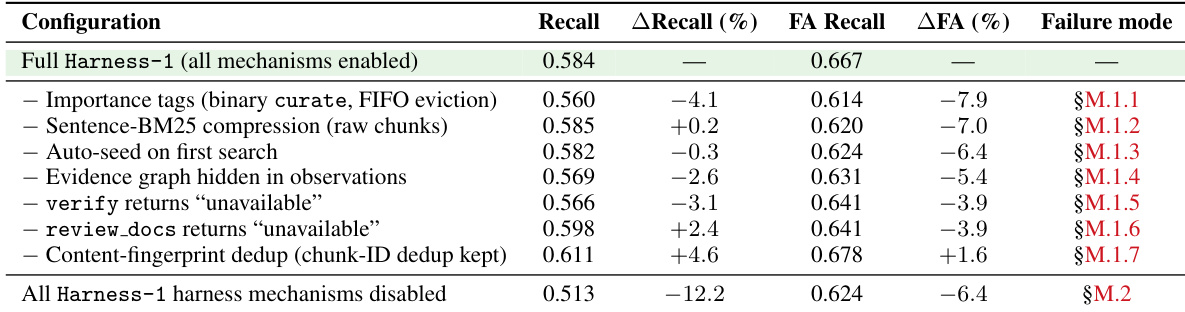
研究评估了 Harness-1 与开源和前沿检索模型,以评估召回率和迁移能力。在 BrowseComp+ 基准上的消融研究隔离了各个推理时机制的影响,揭示重要性标签和证据图等组件对于维持搜索质量至关重要。这些结果证实,状态化 harness 设计对于有效的证据精选是根本性的,因为禁用这些机制始终会导致召回率和最终答案准确率的显著性能下降。