Command Palette
Search for a command to run...
信任域同策略蒸馏
信任域同策略蒸馏
Xingrun Xing Haoqing Wang Boyan Gao Ziheng Li Yehui Tang
摘要
在线策略蒸馏(OPD)是大语言模型(LLMs)高效后训练的一项基础技术,在agent学习、多任务增强和模型压缩方面具有广泛应用。然而,当教师模型与学生分布存在显著差异时,OPD训练会变得不稳定,因为教师对学生生成的tokens的监督可能会产生不可靠的策略梯度,甚至导致优化失败。本研究通过信用分配策略解决可靠的在线策略token级监督问题,并提出信任区域在线策略蒸馏(TrOPD)。该方法具有以下特点:1)信任区域在线策略学习:TrOPD仅在教师提供可靠监督的区域执行OPD,从而缓解分布不匹配下K1反向KL估计器的优化难度。2)异常值估计:针对异常值区域,我们探索了梯度裁剪、掩码和前向KL估计,以降低不可靠监督带来的不利影响。3)离线策略引导:学生模型从教师前缀继续生成,并利用前向KL模仿离线策略引导,鼓励向可靠区域进行在线策略探索。实验表明,TrOPD在数学推理、代码生成和通用领域基准测试中,始终优于当前最优的OPD基线方法,包括OPD、EOPD和REOPOLD。
一句话总结
作者提出了信任域在线策略蒸馏(Trust Region On-Policy Distillation, TrOPD)框架,该框架通过将在线策略蒸馏限制在教师监督可靠的区域内来稳定大语言模型的后训练过程,利用梯度截断和前向KL估计缓解异常值的影响,并借助教师前缀提供离线策略引导以鼓励稳健的在线策略探索。
核心贡献
- 本文建立了面向推理的在线策略蒸馏统一基准,在一致的训练设置下评估数学、代码生成、指令遵循和STEM推理任务。该框架实现了内存高效的 K1 和 top-k KL 估计器,证明了传统方法在分布不匹配时无法有效抑制错误的策略梯度。
- 该工作引入了信任域在线策略蒸馏(TrOPD),根据学生生成的 token 与教师模型的解码一致率,将其划分为信任区域和异常值区域。通过将优化限制在可靠的监督区域,并对异常值应用 top-k 前向KL估计器,该方法有效缓解了由分布偏移引起的不稳定策略梯度。
- 在 DeepSeek-Qwen2.5-1.5B 和 Qwen3-SFT-1.7B 上的实证评估表明,该框架在数学、代码生成、指令遵循和STEM基准测试中,将推理性能最高提升了 6.18 分。该方法在满足实际内存限制的前提下,实现了紧凑推理模型的稳定后训练。
引言
作者利用在线策略蒸馏来训练小型推理模型,使其能够复现大型推理模型的复杂思维链能力,同时大幅降低推理成本。然而,先前方法往往面临训练不稳定的问题,因为学生生成的轨迹经常偏离教师模型的可靠监督区域,从而产生错误的策略梯度并导致训练崩溃。为解决此问题,作者引入了信任域在线策略蒸馏,通过评估师生解码一致性对 token 进行划分,以隔离出可靠的监督区域。该方法通过应用 top-k 前向KL估计器保留来自异常值的有效信号,并整合离线策略模仿引导来稳定学习过程,最终建立了一个统一基准,证明了该方法在数学、代码生成和STEM推理任务上能带来显著的性能提升。
方法
作者采用一个三部分框架来解决语言模型中在线策略蒸馏(OPD)的不稳定性问题,尤其是在学生与教师分布显著发散时。整体架构旨在通过区分学生输出分布中可信与不可信的区域,确保可靠的 token 级监督。如下图所示,该框架分为三个主要组件:信任域在线学习(Trust-Region On-Policy Learning)、异常值估计(Outlier Estimation)和离线策略引导(Off-Policy Guidance),分别针对优化过程中的特定挑战。
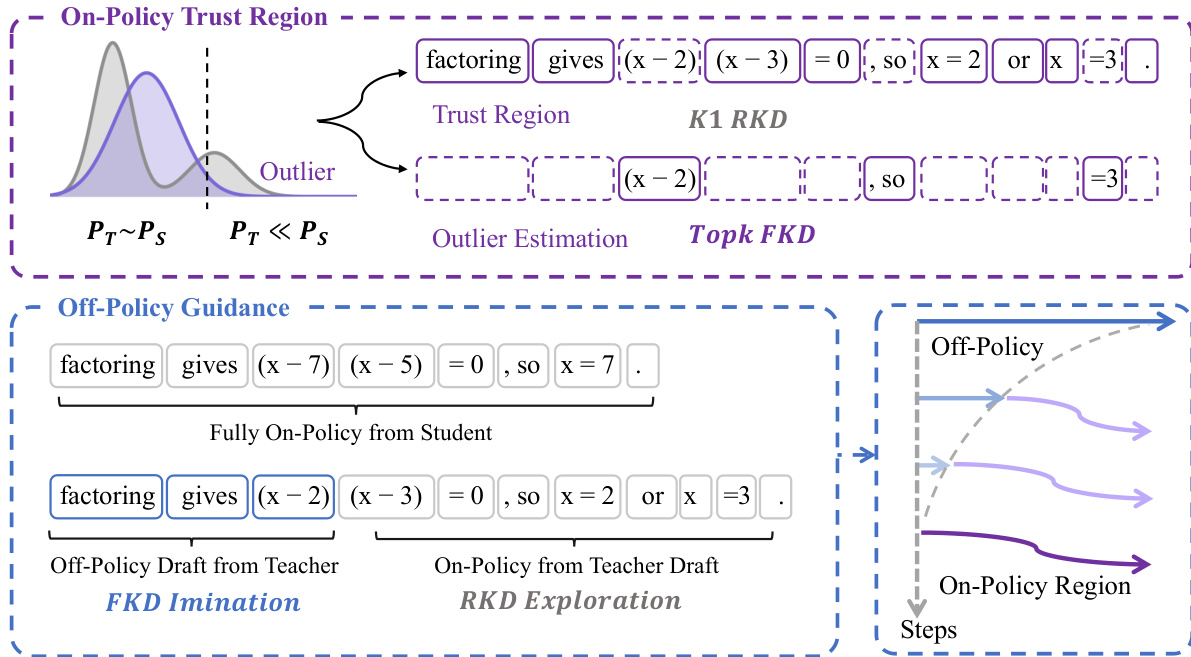
第一个组件“信任域在线学习”将蒸馏限制在学生策略分布与教师分布相近的区域,即 PT≈PS 的区域。在这些区域内,K1 逆向KL估计器提供稳定且无偏的梯度信号,从而实现有效的策略优化。该框架通过比较师生概率分布来识别此信任区域,确保蒸馏仅在教师能够提供可靠监督的区域进行。这缓解了与 K1 估计器相关的优化难题,否则当学生在教师低概率区域生成序列时,该估计器会遭遇极端的负梯度问题。
第二个组件“异常值估计”处理学生分布与教师分布发散的区域,即 PT≪PS。在这些异常值区域,策略梯度变得不可靠并可能破坏训练稳定性。为此,该框架采用梯度截断、掩码处理和前向KL估计来降低这些不利信号的影响。前向KL估计在这些区域尤为有效,因为它会惩罚学生生成教师不支持的序列,相较于逆向KL,它能提供更稳定且信息量更丰富的梯度信号。
第三个组件“离线策略引导”鼓励学生探索教师支持的轨迹。该方法让学生从教师前缀开始生成,从而模仿离线策略引导。学生从这些前缀继续生成,并使用前向KL模仿教师行为,以此鼓励向可靠区域进行在线策略探索。此机制帮助学生克服了低质量学生自生成(SoG)轨迹的局限,使其能够获取不属于自身策略分布的高质量响应。
这些组件共同构成了一个稳健且稳定的在线策略蒸馏框架,确保学生获得可靠监督并能有效学习教师策略。信任域优化、异常值处理与离线策略引导的整合,使该框架能够突破现有OPD方法的关键瓶颈,从而在多个领域实现性能提升。
实验
实验在统一的单域与多域推理设置下对离线策略蒸馏方法进行基准测试,以评估其在受限词汇表条件下的稳定性、泛化能力和有效性。对散度目标的评价表明,独立的 top-k 前向KL会产生扭曲的梯度,而对过滤和截断策略的分析显示,基于熵的选择和奖励截断因超参数敏感而带来不一致的收益。消融实验与对比测试验证了所提出的TrOPD框架通过有效利用感知异常值的 token 选择与信任域学习,在数学、STEM和代码任务上持续优于基线方法。最终结果表明,针对长思考模型的稳健蒸馏需要细致的异常值管理与互补优化策略,结合多种方法为未来改进提供了有前景的方向。
作者在统一设置下评估了多种OPD方法,重点关注其在单域与多域蒸馏任务中的表现。结果表明,TrOPD在不同配置下均持续优于基线方法,在数学推理和通用领域任务中均有提升,同时展现出与AOPD等互补方法的兼容性。TrOPD在单域和多域蒸馏任务中均取得稳定的性能增益。该方法优于依赖奖励截断或基于熵的 token 选择的方法,证明了感知异常值优化的有效性。将TrOPD与AOPD结合可进一步提升性能,表明不同优化策略具有互补优势。

作者分析了长思考推理模型离线策略蒸馏(OPD)中不同散度目标与优化策略的有效性。他们评估了基于信任域学习和异常值估计的方法,并对比了其在单域与多域蒸馏任务中的表现。结果表明,信任域方法优于依赖基于熵的过滤或奖励截断的现有方法,且将信任域学习与离线策略引导相结合能带来持续改进。在离线策略蒸馏中,信任域学习方法优于基于熵的过滤和奖励截断。用于训练的感知异常值 token 选择比基于熵的选择表现更好。将信任域学习与离线策略引导相结合,可在不同蒸馏设置下带来一致的性能提升。

作者在推理模型OPD的语境下评估了多种异常值估计与离线策略引导方法,重点关注其对数学与通用推理任务性能的影响。结果表明,引入感知异常值策略和离线策略引导能带来持续的性能提升,所提出的TrOPD框架在单域与多域蒸馏设置中均优于现有方法。FKL等基于感知异常值的方法在OPD中提升了基线和过滤策略的性能。带有离线策略引导的TrOPD在不同蒸馏配置下持续优于标准OPD及其他先进方法。将TrOPD与并行的AOPD目标结合可进一步获得性能增益,表明不同优化策略之间存在互补优势。
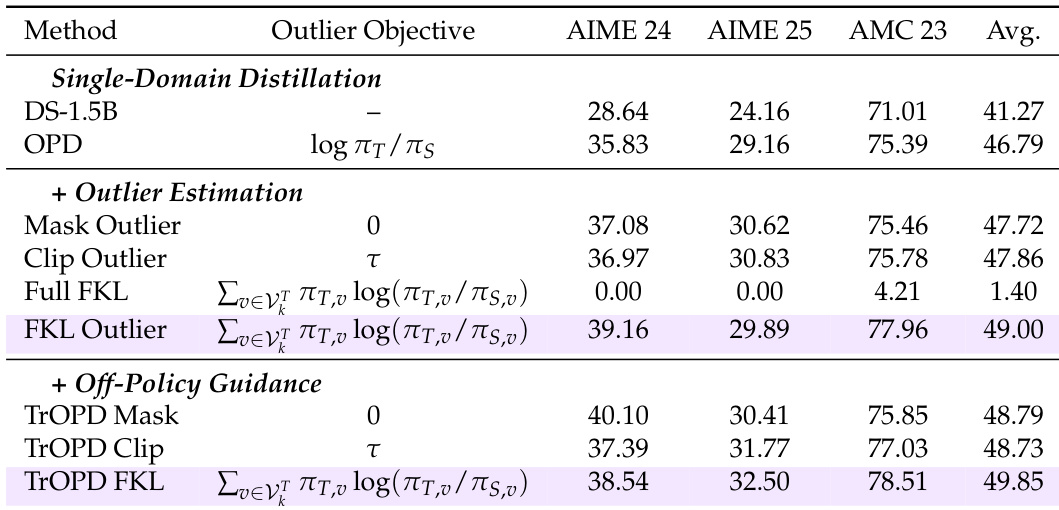
作者在统一设置下评估了多种OPD方法,重点关注其在单域与多域推理任务中的有效性。结果表明,TrOPD在不同领域和学生模型上均持续优于基线方法,在数学推理和泛化能力方面提升显著。感知异常值 token 选择的有效性得到凸显,尤其是在异常值区域使用FKL,而将TrOPD与AOPD结合可进一步增强性能。TrOPD在数学与通用推理任务中持续优于基线方法。在异常值区域使用FKL的感知异常值 token 选择被证明比基于熵的过滤或奖励截断更有效。将TrOPD与AOPD结合带来进一步的性能提升,表明不同优化策略具有互补优势。
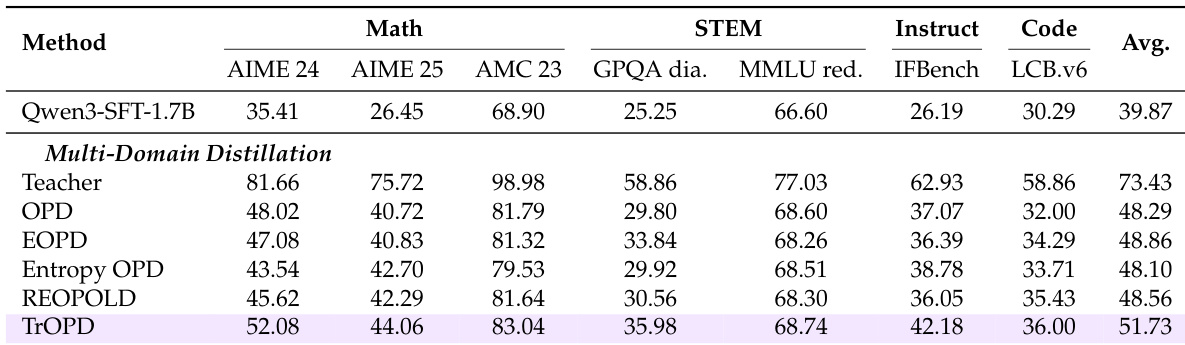
作者在单域与多域蒸馏设置下评估了多种OPD方法,重点关注数学推理和通用领域任务。结果表明,TrOPD在不同配置下均持续优于基线方法,证明了信任域学习与感知异常值 token 选择的有效性。将TrOPD与AOPD结合可进一步提升性能,表明不同优化策略具有互补优势。TrOPD在单域与多域蒸馏设置中均优于现有OPD方法。TrOPD中的感知异常值 token 选择比基于熵或奖励截断的策略表现更佳。将TrOPD与AOPD结合带来进一步改进,暗示不同优化方法之间存在互补优势。
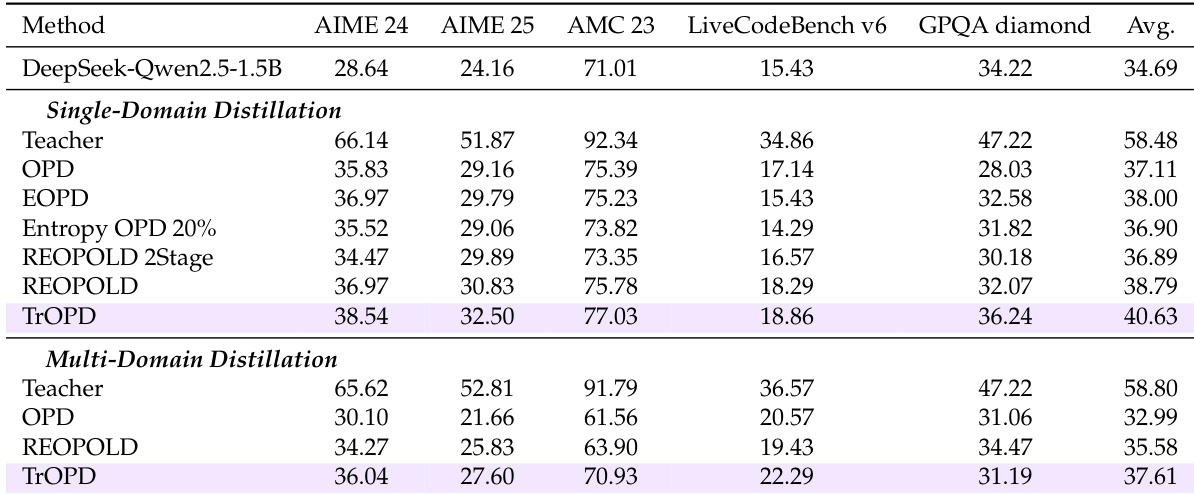
作者在统一框架下评估了多种离线策略蒸馏方法,涵盖单域与多域任务,重点关注数学与通用推理性能。实验验证了所提出的TrOPD框架通过有效的信任域学习和感知异常值 token 选择,持续优于依赖基于熵的过滤或奖励截断的基线方法。此外,将TrOPD与AOPD整合带来了额外增益,证明了结合不同优化策略的互补价值,并确立了感知异常值蒸馏作为训练长思考推理模型的稳健方法。