Command Palette
Search for a command to run...
3DCodeBench: 基于代码的 Agentic 过程化 3D 建模基准测试
3DCodeBench: 基于代码的 Agentic 过程化 3D 建模基准测试
Yipeng Gao Lei Shu Genzhi Ye Xi Xiong Ameesh Makadia Meiqi Guo Laurent Itti Jindong Chen
摘要
通过代码进行程序化三维(Procedural 3D)建模正逐渐成为一种通用的范式,它能够提供确定性强、可直接用于引擎且具备精确可编辑性的资产,而这正是神经三维生成模型(Neural 3D Generators)所 inherently 缺乏的。然而,创作此类程序化内容需要深厚的三维软件 API 知识、参数化设计能力以及代码层面的几何推理技能。在本文中,我们提出了 3DCodeBench,这是一个用于评估视觉语言模型(VLM)智能体(Agents)在三维建模软件中进行程序化 3D 生成能力的系统性基准测试。具体而言,3DCodeBench 评估了 12 种先进的 VLMs 通过将文本和图像参考转化为三维建模软件所需的程序化代码,从而作为程序化 3D 建模器的有效性。鉴于自动化指标可能无法完全捕捉三维形状的感知质量,我们构建了 3DCodeArena,这是一个基于成对人类偏好(Pairwise Human Preferences)对生成的 3D 输出进行排名的平台。通过广泛的评估和结果分析,我们观察到:(1)失败主要源于 API 不匹配,而即使渲染成功,生成的几何体仍存在不连通或悬浮的三维几何组件问题;(2)测试时扩展(Test-time Scaling),例如更高的思维预算(Thinking Budgets)和多轮迭代优化,能整体提升性能。我们的发现凸显了高质量程序化编码数据对于推动商业级 VLMs 发展的重要需求。此外,有效的程序化 3D 建模需要一个强大的执行环境,以提供高保真反馈用于迭代优化。我们公开发布了 3DCodeBench,包括精心策划的大规模多模态(文本/图像)提示、程序化代码、三维对象三元组数据集、评估协议以及公开的 3DCodeArena 平台,旨在为探索基于 VLM 的程序化 3D 建模器提供基础工具包。
一句话总结
论文提出3DCodeBench,一个评估12个先进视觉语言模型将文本和图像提示转化为程序化3D代码的基准测试,并配套3DCodeArena用于成对人类偏好排序,揭示失败主要源于API不匹配、几何体分离或悬浮,而通过提高思考预算和多轮优化的测试时扩展可提升性能,同时发布精心整理的数据集和平台以推动基于VLM的程序化生成。
核心贡献
- 论文引入3DCodeBench,一个用于评估视觉语言模型agent在程序化3D生成上的基准,通过一个agent策管管道构建,产生包含212个对象类别、多模态提示、可执行Blender脚本和人工验证的3D三元组的数据库。
- 构建了3DCodeArena,一个收集成对人类对生成3D输出偏好的公开平台,并证明SigLIP-2视图相似度可作为人类判断的稳健自动代理。
- 对12个前沿VLM的广泛评估表明,测试时计算扩展和多轮agent优化可提高程序化代码质量,同时识别出API不匹配和分离几何体为主要失败模式。
引言
通过代码进行程序化3D建模对于在游戏、工业设计和机器人仿真中创建确定性、可编辑且引擎就绪的资产至关重要,但编写此类代码需要深厚的3D API和几何推理专业知识。以往的基准测试要么缺乏评估生成模型所需的对齐程序化代码,要么侧重于简单形状或场景编辑而非从零开始生成,或者忽略了真实3D设计工作流所需的迭代优化循环。作者引入3DCodeBench,一个标准化基准,将26K多模态提示与可执行Blender代码和3D几何体配对,涵盖212个不同类别,并辅以3DCodeArena,一个收集成对人类偏好的平台。他们针对12个前沿视觉语言模型的广泛评估表明,虽然模型能生成可执行脚本,但物理合理性和几何连贯性仍是主要瓶颈,而利用运行时反馈的多轮agent优化可显著提升输出质量。
数据集
作者从Infinigen的程序化工厂中构建了两个互补数据集,使用了一个agent策管管道并辅以人工验证。基准3DCodeBench是一个紧凑的评估集,而更大的策管语料库为代码生成模型提供微调数据。
-
3DCodeBench(评估基准)
- 212个不同的资产类别,涵盖有机实体、人造物体和建筑构件。
- 每个实例都是一个高保真(提示、独立Python代码、3D网格)三元组。
- 脚本复杂度高(中位数387行,平均531行,部分超过1000行),需要对3D结构和新的Blender API函数进行推理。
- 专用于3D代码生成的零样本或少样本评估。
-
策管3D代码数据(微调语料库)
- 12,963个实例,源自212个随机种子参数化的工厂(从243个完整对象工厂中筛选)。
- 每个实例提供:
- 一个文本提示,搭配三种标题风格(对象描述、程序化建模指令、工厂级规格)。
- 4张标准多视角参考图像(45°、135°、225°、315°)。
- 两个Blender 5.0 Python脚本:一个有纹理的工厂脚本和一个仅几何变体,总计约26K个代码样本。
- 一个烘焙的GLB真值网格。
- 所有三元组均通过完整的agent策管管道和人在回路验证。
- 用于3D代码生成模型的监督微调。
-
Agent策管管道
- 将深度嵌套的程序化工厂转换为干净、自包含的脚本。
- 技能库提供客观反馈:代码简化器、沙盒化Blender 5.0模拟器、基于VLM的视觉批评家(比较多视图渲染与参考图像)以及用于结构检查的网格分析器。
- 经验库积累可复用知识:类去重以保持多样性、部件组装模板、Blender 5.0 API迁移规则和代码组织标准。
- 人在回路验证作为最终质量控制;标注员手动审查执行可靠性、标题准确性(通过Gemini 3.1 Pro)和视觉对齐,并在agent失败时进行有针对性的干预。
-
多视图图像处理
- 所有参考渲染遵循严格的影棚产品摄影风格:单个物体居中,占据画面70–80%,纯浅灰/米白背景,前上方柔光漫射照明,四分之三前置视角(约30–45°旋转,约15°俯视),无场景元素,无文字或标签,色彩逼真、真实还原。
方法
作者将程序化3D生成形式化为一个策略学习问题,其中模型合成可执行代码,3D软件运行时将其编译为目标对象。形式化地,给定条件 c(包含文本和可选的参考图像),策略 π 生成一个脚本:
fπ=π(c)
一个确定性算子 E 随后执行此脚本以生成网格:
Mπ=E(fπ)
作者在Blender 5.0上实例化该框架,使 fπ 成为Blender Python脚本,但该方法与软件无关。
通过程序化代码生成3D对象的高层流程如下图所示,图像或文本提示由VLM处理,生成程序化代码,编译器将其执行成3D对象。
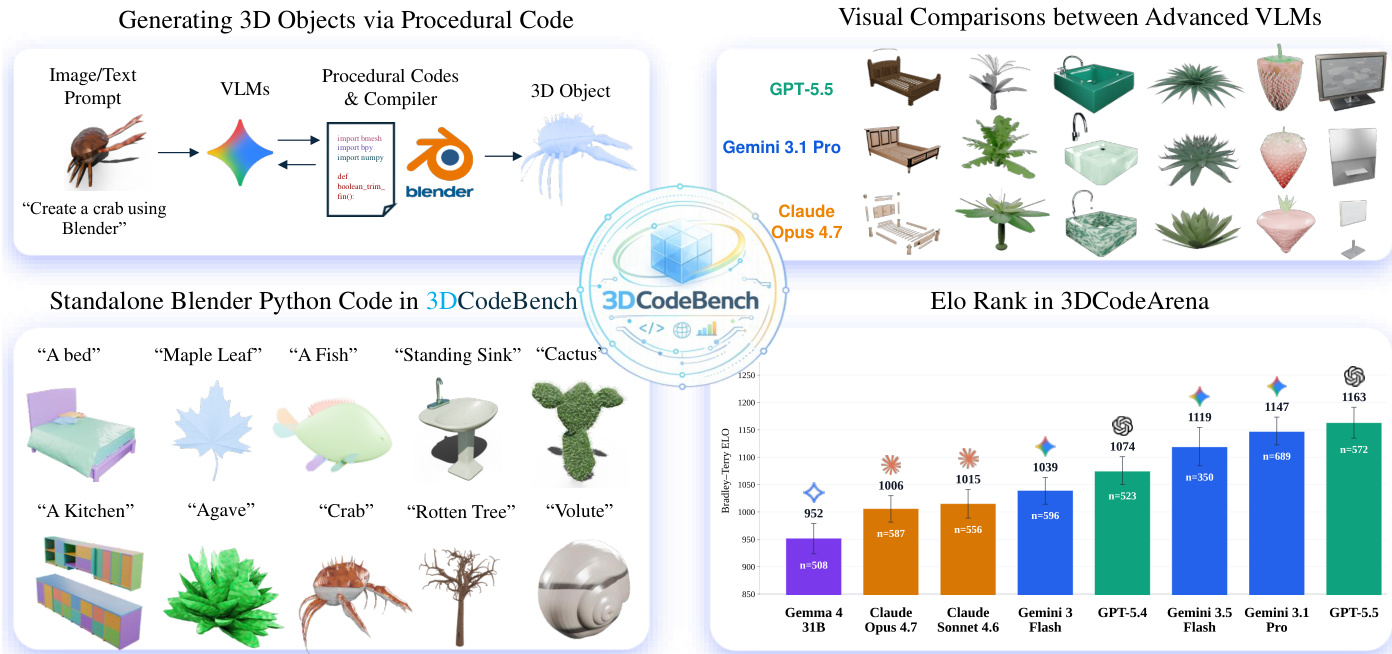
下图所示的详细架构涉及Coding Agent,它们接收文本指令、参考图像和程序化模拟器等输入。这些agent与VLM和人工检查器交互,生成由提示和相应程序化代码组成的高质量数据对。
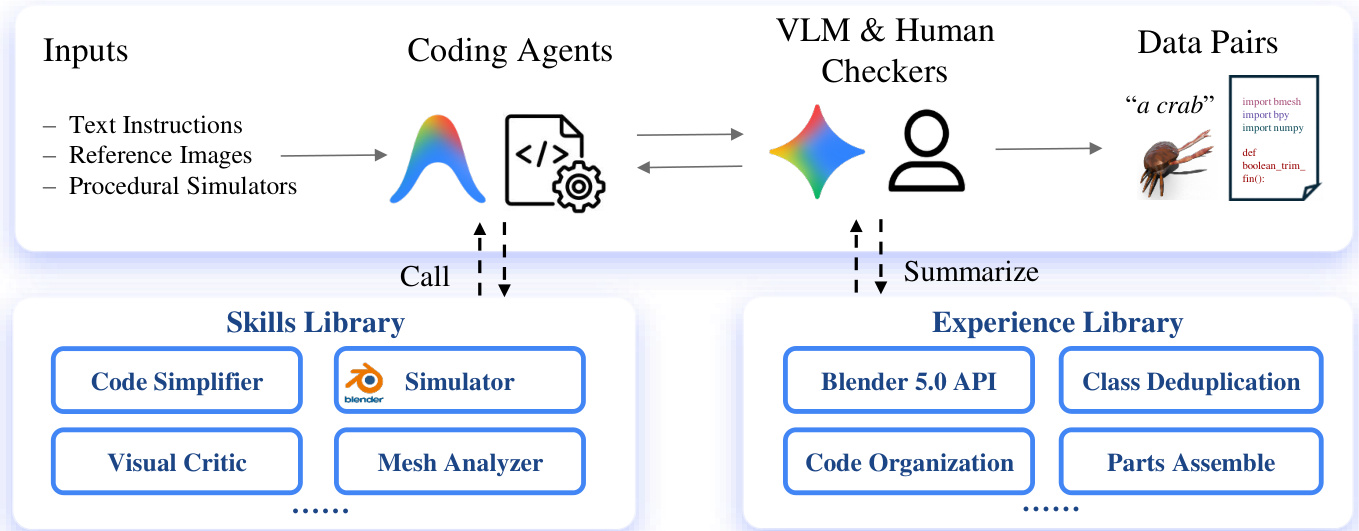
该框架由两个关键库支持。技能库提供代码简化器、模拟器、视觉批评家和网格分析器等工具。经验库积累关于Blender 5.0 API、类去重、代码组织和部件组装的知识。
为确保稳健的代码生成,作者对文本到3D和图像到3D任务均采用严格的系统提示。这些提示强制执行三个关键约束:严格的输出格式要求原始Blender 5.0 Python,不使用Markdown格式;目标环境限于一个封闭的允许库列表;以及行为代码要求,如生成一个位于原点的单个对象,不进行渲染或文件I/O。
对于图像到3D任务,模型接收参考图像,必须推断不可见侧面,交叉引用多个视图以解析深度和比例,并将几何细节再现为真实几何体而非平面。
为探究agent能力,作者允许 T≥1 次优化迭代。在第 t 步,策略根据执行日志或视觉反馈更新 fπ(t)。在多轮错误反馈循环中,如果脚本执行失败,系统以无状态方式向模型提供前一次代码和截断的Blender stderr,要求输出修正后的脚本。
对于视觉自我批评,模型评估基线可行的实例。它将生成的渲染与参考进行比较,并输出格式为NEEDS_FIX:NO或NEEDS_FIX:YES的决策,随后附上评估和修正代码。作者引入保守偏差,在渲染效果足够好时偏好NEEDS_FIX:NO,以避免破坏正常工作的代码。此外,对于文本到图像到3D的管道,一个元提示首先从文本描述生成一张照片级参考图像,然后将其输入到图像到3D代码生成器。
实验
评估结合了逐网格定量指标和人类投票竞技场,以对程序化3D生成中的视觉语言模型进行排名。增加的推理预算持续帮助轻量模型,但对前沿模型迅速饱和,而多轮错误反馈通过解决表面API不匹配问题,普遍提升了可执行性。Agent harness进一步提高可靠性,但并未改变条件形状保真度,且视觉自我批评被证明是任务不对称的,仅对文本到3D有益。LLM作为评判者,在展示渲染图像时与人类具有合理的一致性,但仅从代码评判则可靠性较低,采样温度0.7是推荐选择。
作者评估了在图像到3D任务中,不同输入视图数量对多个模型骨干的影响。结果显示,随着输入视图预算的增加,条件质量指标基本保持稳定,可执行性和感知相似度得分变化极小。虽然某些模型在额外视图下在3D结构对齐上略有提升,但使用单个输入视图相比,基于视图的相似度并没有一致改善。增加输入视图数量对所有测试骨干的可执行性和感知保真度几乎没有影响。结构对齐指标在某些模型上随更多视图略有改善,但提升幅度很小,且不是普遍一致。额外输入视图相比单个视图没有提供一致的相似度增益,因此作者使用多个视图主要是为了测试空间理解能力。
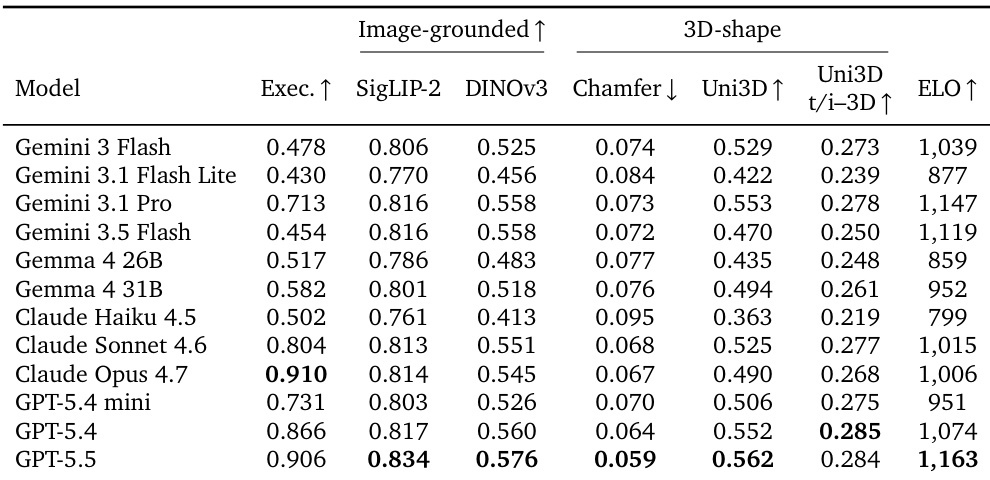
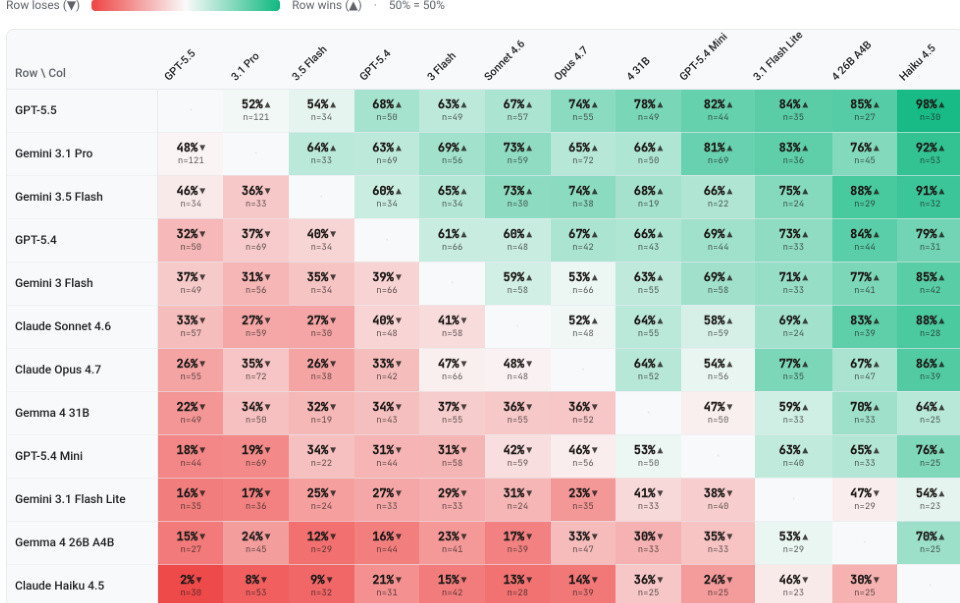
作者在3D代码生成基准上评估了多个前沿视觉语言模型,评估可执行性、感知保真度、3D形状准确性和人类偏好。GPT-5.5脱颖而出,成为整体表现最佳者,在人类偏好排名和大多数质量指标上领先,而Claude Opus 4.7实现了最高的脚本可执行性。结果显示出明显的能力差距,更重的前沿模型在生成有效代码和产生准确3D几何体方面显著优于轻量变体。GPT-5.5取得了最高的人类偏好排名,并在大多数感知和几何质量指标上领先。Claude Opus 4.7在所有测试模型中展现出最强的代码可执行性。轻量模型的可执行性和形状保真度明显低于其更大版本。
作者评估了一个文本到图像到3D的管道,该管道在3D代码生成前插入一个中间图像生成步骤。结果显示,仅依赖生成图像会降低性能,尤其是对轻量模型,与直接文本到3D生成相比。然而,将生成图像与原始文本提示结合,可恢复这一损失,并提高高容量骨干的感知相似度。在所有测试骨干上,与直接文本到3D基线相比,仅图像管道配置一致降低了SigLIP-2相似度得分。对于如Gemini 3.1 Pro和Gemma 4等高容量模型,结合生成图像与原始文本提示的组合模式,其SigLIP-2得分优于基线。轻量模型在仅图像模式下遭受严重性能下降,且由于推理预算有限,在组合模式下无法恢复。
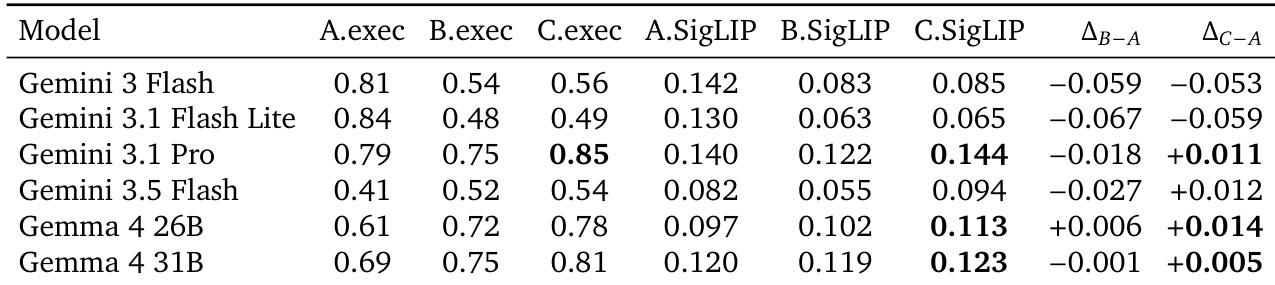
作者评估了前沿LLM和VLM能否在3D建模竞技场中,使用渲染图像或原始代码复制人类判断。结果显示,基于图像的评判与人类投票者达成显著一致,显著优于基于代码的评判,后者仅达到一般到中等相关性。在测试模型中,Gemini 3.1 Pro作为图像评判表现最佳,而Gemini 3.1 Pro和Gemini 3 Flash在代码评判中并列第一。与基于代码的评判相比,基于图像的评判实现了更高的准确性和与人类偏好的相关性。Gemini 3.1 Pro在图像评判性能上领先,但由于频繁使用平局和双方都差的判定,覆盖率较低。图像评判器在图像任务提示上始终优于文本任务提示,可能是因为参考视图提供了额外的视觉锚点。
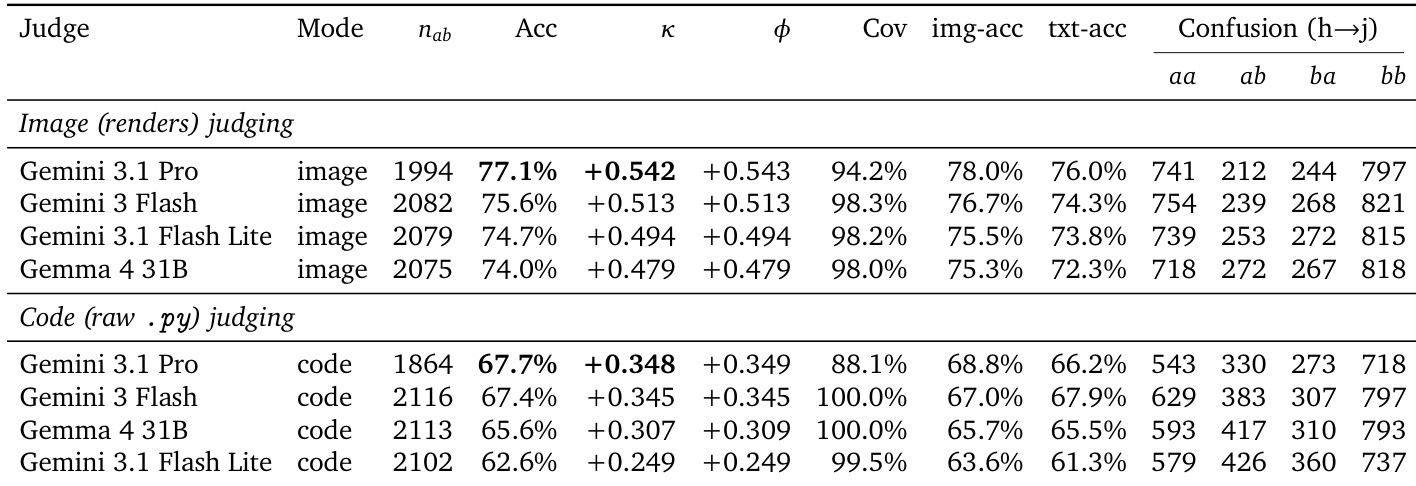
该表格呈现了一个公开人类投票竞技场的成对胜率矩阵,比较了不同前沿视觉语言模型生成的3D模型。模型按总体Elo评分排序,揭示了生成能力的清晰层级。排名靠前的模型在大多数直接对决中始终击败排名较低的模型,而位于排行榜底部的模型则输掉大部分成对比较。排名最高的模型取得了压倒性的胜率,在头对头比较中击败几乎所有其他模型,展现出卓越的3D生成质量。该矩阵展现出强烈的传递性排序,即排行榜上更高的模型始终击败下方模型,在网格中形成明显的胜负模式。较小或轻量模型在与前沿规模骨干的对抗中挣扎,经常输掉成对比较,表明程序化3D代码生成存在显著的能力差距。
在多项评估中,作者探究了前沿视觉语言模型在程序化3D代码生成上的表现,研究了输入视图数量、模型规模和中间图像合成的影响。增加输入视图数量带来的可执行性或感知保真度增益可忽略不计且不一致,主要用于测试空间理解能力,而一个明显的能力差距显现出来,即像GPT-5.5这样的大型模型在代码有效性和几何准确性上显著优于轻量对手。在3D代码生成前插入生成图像,单独使用时性能下降,尤其是对较小模型,但将图像与原始文本提示配对,可恢复甚至提高高容量骨干的质量。人类偏好竞技场和自动评判实验进一步表明,基于图像的评估与人类判断高度一致,而基于代码的评估则落后,且排名靠前的模型在强传递性层级中主导成对比较。