Command Palette
Search for a command to run...
OCC-RAG:面向忠实问答的最优认知核心
OCC-RAG:面向忠实问答的最优认知核心
Maksim Savkin Mikhail Goncharov Alexander Gambashidze Alla Chepurova Dmitrii Tarasov Nikita Andriianov Daria Pugacheva Vasily Konovalov Andrey Galichin Ivan Oseledets
摘要
语言模型开发的最新进展一直由规模所定义,每一代模型都将更多世界知识吸收进其权重中。然而,许多实际应用从强大的推理能力中获得的收益,远大于从广泛的参数化知识中获得的收益。在此背景下,面向特定任务的小型语言模型(SLMs)提供了一种具有理论依据的设计选择。我们提出了最优认知核心(Optimal Cognitive Core, OCC),这是一系列基于该前提构建的SLMs。作为OCC的一个变体,我们推出了OCC-RAG,该模型针对基于提供上下文的忠实问答(QA)进行了优化。该任务与OCC的设计方法直接契合,要求在利用所提供段落进行多跳推理的同时,忽略已记忆的知识。为训练OCC-RAG,我们实现了一种新颖的流水线,用于大规模合成多上下文、多跳QA数据,生成了一个包含超过三百万个示例的语料库,旨在针对多跳推理、严格的上下文忠实度以及校准后的拒绝回答进行优化。我们发布了OCC-RAG-0.6B和OCC-RAG-1.7B,两者均在该语料库上进行了中期训练。这些模型能够生成带有来源引用的结构化推理轨迹,且引用均基于上下文中的逐字原文。通过OCC-RAG,我们证明了紧凑的、面向特定任务的SLMs在多项基准测试(包括多跳推理(HotpotQA、MuSiQue、TAT-QA)、忠实度(ConFiQA)和拒绝回答(MuSiQue-Un))中,能够匹配或超越规模为其2 -- 6倍的通用模型。
一句话总结
OCC-RAG 是一款面向特定任务的小型语言模型,专为忠实、基于上下文的问答而优化。该模型利用一种新颖的数据合成管线,整合超过三百万个多跳训练样本,生成带有来源引用的结构化推理轨迹,并在多跳推理(HotpotQA、MuSiQue、TAT-QA)、忠实度(ConFiQA)及拒答(MuSiQue-Un)基准测试中,表现达到或超越参数量为其两至六倍的通用模型。
核心贡献
- 本文提出 Optimal Cognitive Core (OCC) 系列小型语言模型,具体包含 OCC-RAG-0.6B 与 OCC-RAG-1.7B 两个变体。该系列模型在架构设计上优先保障多跳推理能力与严格的上下文依赖,而非依赖庞大的参数化知识。
- 一种新颖的数据合成管线生成了超过三百万个多上下文、多跳问答样本用于模型训练,使模型能够生成带有精确来源引用的结构化推理轨迹,并在上下文信息不足时实现校准后的拒答机制。
- 在 HotpotQA、MuSiQue、TAT-QA、ConFiQA 及 MuSiQue-Un 等基准上的综合评估表明,这些紧凑型架构在多跳推理、忠实度与拒答任务中,表现达到或超越参数量为其二至六倍的通用模型。
引言
研究针对实际应用场景中对于上下文问答系统的需求,提出在推理能力上优先于前沿语言模型所依赖的海量参数化知识。以往方法在此类场景下常出现失效,因为大型模型倾向于用记忆事实覆盖提供的文本,从而导致幻觉产生,并在多跳或不可答题目上表现不佳。为突破这些局限,研究提出 Optimal Cognitive Core 概念,并具体推出 OCC-RAG 系列小型语言模型。该系列模型专为严格的上下文依赖而设计。研究利用新颖的数据合成管线生成超过三百万个多跳训练样本,以强制实施基于证据的推理与校准拒答。最终生成的 0.6B 与 1.7B 模型能够输出带有精确来源引用的结构化推理轨迹,并在忠实度、多跳推理及拒答基准测试中,持续超越参数量为其二至六倍的通用模型。
数据集

- 数据集构成与来源: 研究通过整合清洗后的英文维基百科段落与从 MuSiQue 训练集中提取的结构化知识,构建了一个大规模推理语料库。实体规范化基于 Wikidata 本体进行锚定,并采用 DRAGON 基准分类法来定义题目复杂度。
- 子集详情与过滤规则: 最终语料库包含约 325 万个问答对。单跳样本(278 万个)使用 gpt-oss-120B 从维基百科段落生成,干扰上下文通过 TF-IDF 余弦相似度挖掘,且每个段落上限保留前二十个匹配项。多跳样本(共计 42.7 万个)由 MuSiQue 数据合成。研究将其转换为 RDF 知识图谱,并利用 SPARQL 模板采样特定子图结构,覆盖简单、两跳及三跳的竹节式题目。拒答子集(4.3 万个对)通过将缩减的上下文窗口输入至经过 SQuAD 微调的 DeBERTa 模型来构建,并将不匹配项标记为硬性拒答案例。
- 训练用途与混合比例: 所有生成的问答对均分配至训练集。数据混合显著偏向单跳数据,该部分消耗了 80 亿 Qwen3 tokens 中的约 77.6 亿。在所有子集中,干扰上下文始终占据 token 预算的 35% 至 75%,以确保模型能够在学习黄金段落的同时掌握处理无关信息的能力。
- 元数据构建与处理管线: 每个问答对均通过 Qwen3.5-27B 生成结构化推理轨迹进行增强,遵循固定模式,包含查询分析、来源分析、推理、答案及二元状态字段。研究禁用了模型的原生思维模式以控制成本并防止冗余的内部轨迹。推理轨迹经历四步验证流程:格式完整性检查、精确答案匹配、使用 Qwen3-4B 的 LLM-as-judge 验证,以及针对过度推理的过滤机制(丢弃超过 1,256 tokens 或包含超过十个手动思维标记的轨迹链)。段落级分块仍作为基础的上下文单位,所有最终输出均严格为抽取式且自包含。
方法
研究利用结构化推理框架设计 OCC-RAG 模型架构,重点强调多跳推理、上下文忠实度与校准拒答。模型推理过程的核心由一个顺序工作流定义,该流程从查询与上下文输入开始,依次经过独立的分析阶段,最终生成答案与状态判定。框架示意图见  。
。
第一阶段为查询分析,旨在解析题目以识别所需信息。随后进入来源分析阶段,模型对提供的上下文段落进行评估,每个段落均标记有唯一的来源标识,以确定哪些来源包含相关信息。接下来的推理阶段整合已识别来源的信息,应用推断与验证等逻辑步骤以得出结论。该流程的输出为状态(ANSWERABLE 或 UNANSWERABLE)及最终答案。这种模块化结构确保推理过程的每一步都明确锚定于输入上下文。
模型通过监督微调在由结构化推理轨迹生成的合成数据上进行训练。训练目标聚焦于响应 tokens,完整提示词/响应格式的设计旨在镜像评估设置,从而消除训练与测试之间的分布差异。提示词由随机顺序排列的题目与上下文段落组成,每个段落均标注数字标识。响应部分包含按照定义结构格式化的详细推理轨迹,最终答案与可回答性判定嵌入于轨迹内部。特殊 tokens 用于划分提示词与响应的不同组件,其嵌入向量初始化为对应自然语言名称的子词嵌入的平均值。
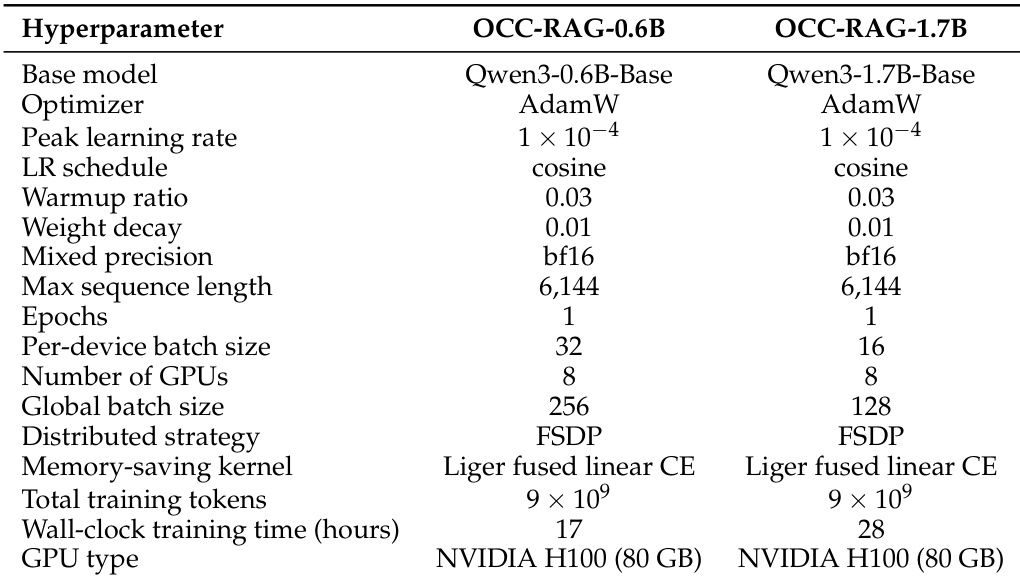
训练语料库包含三个子集:单跳、多跳单上下文与多跳多上下文。为强调多跳推理能力的培养,多跳子集在每个 epoch 中的过采样倍数为单跳样本的三倍。该数据混合策略在提升多跳准确率的同时,未对单跳任务性能造成负面影响。OCC-RAG-0.6B 与 OCC-RAG-1.7B 模型均基于 Qwen3-Base 模型衍生而来,因其初始评估表现优异而被选中。两个模型均使用 8 块 NVIDIA H100 GPU 在约 9×109 tokens 上进行训练,完整训练细节见附录。
实验
评估从三个核心维度检验 OCC-RAG 模型:多跳推理、对提供上下文的忠实度,以及在证据不足时的拒答能力。这些实验验证了紧凑型模型是否能够准确综合多源信息、严格遵循反事实提示词而非依赖参数化知识,并在上下文缺失时恰当拒答。定性结果表明,模型成功将提供证据置于记忆事实之上,同时在保持强大拒答能力的情况下未受体积限制。最终研究指出,定向训练使小型语言模型能够实现可靠、基于上下文的推理与校准拒答,为扩展更大规模通用模型提供了高效替代方案。
研究使用评估上下文依赖与推理能力的基准对模型的多跳推理、忠实度与拒答性能进行测试。评估重点考察模型遵循提供上下文的能力、处理多跳题目的表现,以及在证据不足时拒答的准确性。结果表明,小型模型在特定维度上可达到与大型模型相当的性能。模型在需要上下文依赖与推理的数据集上进行多跳推理、忠实度与拒答评估。尽管体积小于多数基线模型,OCC-RAG 模型在忠实度与拒答指标上仍取得具有竞争力的结果。评估包含测量 In-Accuracy、F1、记忆比率与拒答准确率的基准,以全面考察模型行为的不同方面。

研究对比了两个 OCC-RAG 模型,即 0.6B 与 1.7B 参数变体,两者除模型规模与批次大小外,采用相似的超参数进行训练。两个模型均使用相同的基础架构与训练配置,较大模型需要更长的训练时间与更大的全局批次大小。训练配置支持在 NVIDIA H100 GPU 上进行高效的分布式训练,采用混合精度与余弦学习率调度。两个 OCC-RAG 模型均使用相同的基础架构与训练配置,主要差异在于模型规模与批次大小。训练配置采用余弦学习率调度、混合精度以及基于 FSDP 的分布式训练。较大模型需要更长的训练时间与更大的全局批次大小,反映了其规模的增加。
研究在需要上下文依赖与避免幻觉的基准上,对多种语言模型的多跳推理、忠实度与拒答任务进行评估。结果表明,OCC-RAG 模型尽管规模显著更小,但在忠实度与拒答方面相比大型模型仍取得具有竞争力或更优的性能,展现出在不依赖记忆知识情况下的有效上下文遵循能力。OCC-RAG 模型在忠实度与拒答指标上表现突出,在上下文依赖基准上超越大型模型。尽管体积仅为后者的二至六分之一,OCC-RAG 模型在多跳推理与拒答任务上的表现达到或超越参数量最高达 4B 的模型。OCC-RAG-1.7B 在忠实度与拒答方面取得最佳结果,展现出对提供上下文的强遵循能力,以及在证据不足时的有效拒答表现。
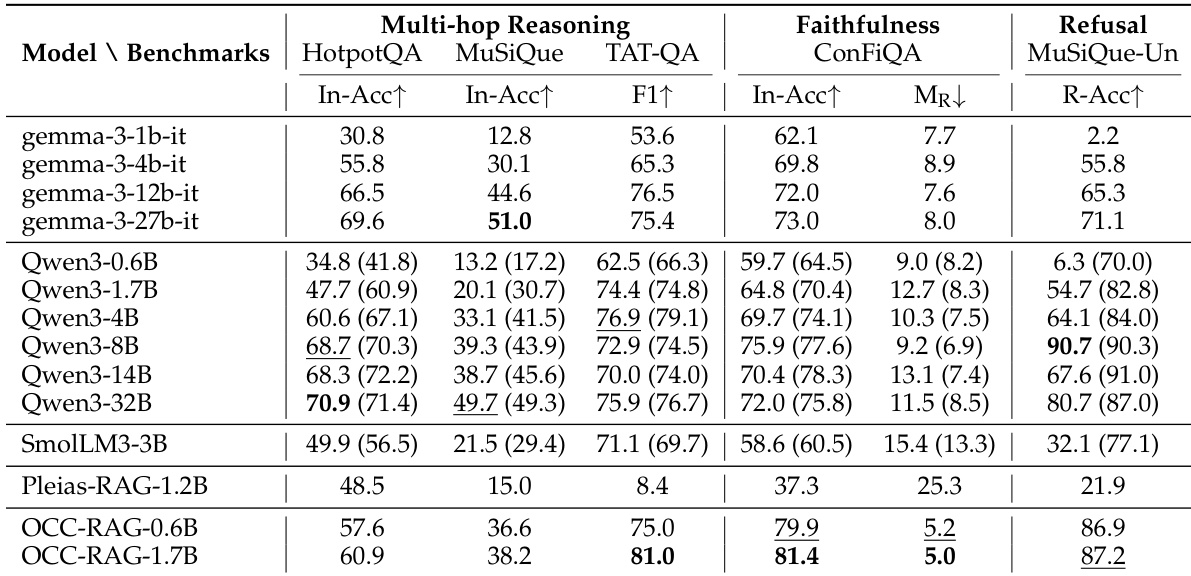
评估采用专为检验多跳推理、忠实度与拒答能力设计的基准,具体验证模型遵循提供上下文的能力,以及在证据不足时恰当拒绝回答的表现。尽管参数量显著更小,OCC-RAG 变体在对比大型基线模型时仍取得具有竞争力或更优的性能,尤其在上下文依赖与基于证据的拒答方面表现突出。这些定性结果表明,高效的模型缩放策略能够在不依赖记忆知识的前提下,有效维持强大的推理能力并最小化幻觉。