Command Palette
Search for a command to run...
面向无瓶颈统一多模态模型的表示强制
面向无瓶颈统一多模态模型的表示强制
摘要
统一多模态模型(UMMs)旨在通过单一模型处理感知与生成任务。然而,现有的UMMs在图像生成方面仍依赖于一个冻结的、独立预训练的VAE,这造成了结构上的瓶颈。简单地移除该模块会导致质量差距,因为模型必须从原始像素中同时学习高层结构和低层细节。在本文中,我们提出了表示强制(Representation Forcing, RF)技术,该技术通过将表示预测转化为模型的固有能力来弥补这一差距。具体而言,RF强制解码器在像素之前自回归地预测视觉表示作为中间tokens;这些tokens随后保留在上下文中,以在同一骨干网络内指导像素扩散。通过将感知输出中的表示转化为生成目标,RF消除了对外部生成潜在空间的需求。我们发现,RF同时提升了理解与生成能力。在图像生成方面,带有RF的像素空间模型达到了与最先进的基于VAE的统一模型相当的水平。在图像理解方面,像素空间RF通常优于其基于VAE的变体。综上所述,这些结果为迈向端到端、无瓶颈的UMMs迈出了有效的一步。
一句话总结
Representation Forcing 通过自回归地将视觉表征预测为中间 token,以在单一骨干网络内引导像素级扩散,从而消除统一多模态模型中的结构性瓶颈。该方法生成了一种像素空间架构,其在生成能力上媲美基于 VAE 的最先进统一模型,并在图像理解方面通常表现更优。
核心贡献
- 该研究提出 Representation Forcing 技术,通过训练解码器自回归地将视觉表征预测为中间 token,从而摆脱对冻结的外部变分自编码器的依赖。这些 token 保留在序列中,为共享 transformer 骨干网络内的像素空间扩散提供结构引导。
- 受控实验表明,该像素空间模型在标准文生图生成基准上达到了与基于 VAE 的最先进统一模型相当的水平,同时保留了精细纹理。该方法在图像理解任务上也优于其 VAE 对应模型,表明其与联合多模态建模具有更高的兼容性。
- 通过将感知输出重新用作生成目标,该方法建立了一个端到端的统一表征空间,能够直接从原始像素中学习高层结构与底层细节。该设计通过实现原生能力而无需依赖独立预训练的潜在空间,推动了完全统一的多模态建模。
引言
统一多模态模型旨在单一架构内同时处理视觉感知与图像合成,这是构建通用多模态智能的基础要求。然而,现有系统依赖一个冻结的、独立预训练的 VAE 将图像压缩为潜在变量后再进行扩散,这造成了结构性瓶颈,限制了生成质量并破坏了端到端训练。移除该外部组件会迫使网络直接从原始像素中同时学习高层语义与底层纹理,导致生成质量严重下降。作者利用 Representation Forcing 解决此问题,通过训练解码器自回归地将视觉表征预测为中间 token。这些 token 保留在注意力上下文中以引导像素空间扩散,成功消除了对 VAE 的依赖,同时提升了生成保真度与多模态理解能力。
方法
作者采用了一种统一多模态模型架构,旨在实现像素空间生成的端到端训练,且无需依赖外部潜在空间。核心框架称为 Representation Forcing,运行于共享的 transformer 骨干网络中,处理由文本 token、表征 token 和像素块组成的统一序列。该序列结构支持理解与生成任务,模型联合训练以预测文本、生成视觉表征并渲染图像。该架构基于混合 Transformer(MoT)设计构建,所有 token 共享相同的自注意力层,但会根据其类型被路由到特定模态的前馈专家模块。这些专家模块分别专用于多模态理解、表征 token 预测和像素生成,使模型能够在保持通用注意力机制的同时实现处理专业化。
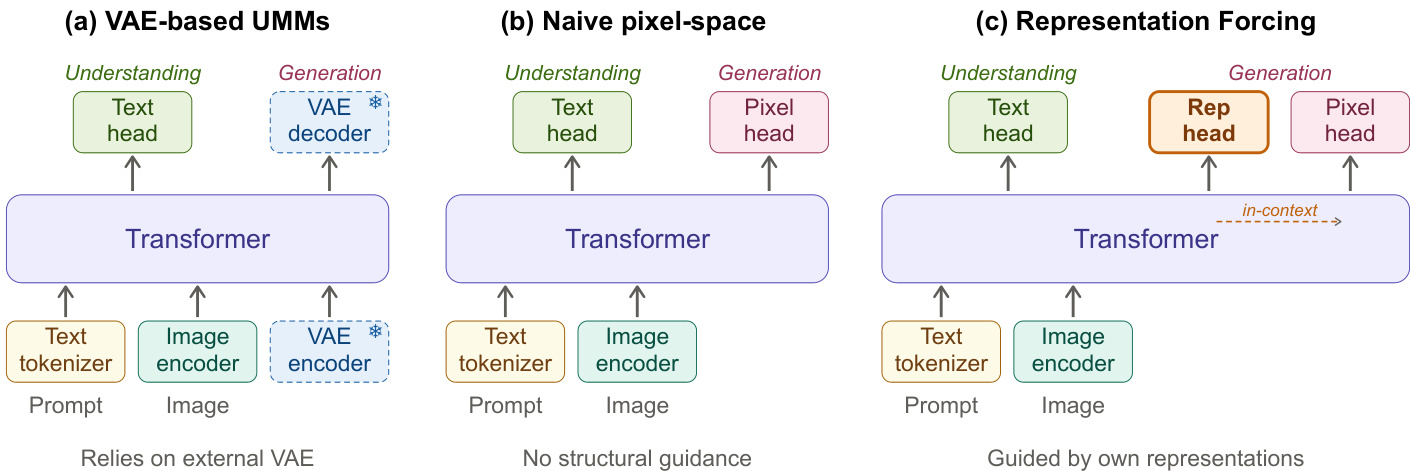
该框架集成了一款图像编码器,具体为支持 NaViT 风格可变分辨率的 DINOv3 ViT-H+/16,并与模型其余部分联合训练。在训练过程中,编码器从输入图像中提取连续的视觉特征,随后通过在线向量量化将其离散化为表征 token 序列。该过程使用编码器指数移动平均(EMA)副本以稳定特征表征,确保码本更新能够逐步适应不断变化的特征。码本包含 K=16,384 个可学习的原型嵌入,每个像素块级别的特征根据余弦相似度被分配至最近的原型。这种离散化操作生成了一组表征 token 序列,其镜像了图像的空间布局,并嵌入了可学习的二维空间与身份嵌入。生成的表征 token 被整合到序列中,作为像素空间生成的上下文条件。
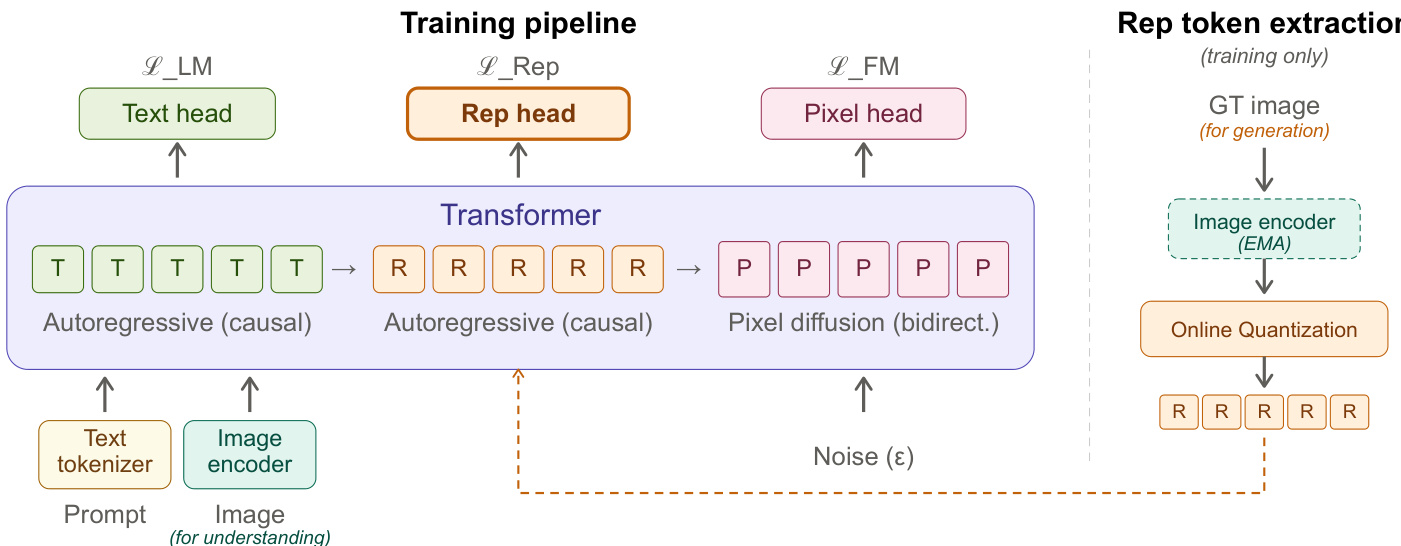
该模型采用联合目标进行端到端训练,目标包含三个组成部分:用于文本预测的语言建模损失 LLM、用于预测离散化视觉表征的表征预测损失 LRep,以及用于像素生成的流匹配损失 LFM。流匹配损失采用基于速度损失的 x-prediction 公式进行构建,其中解码器在时间 t 根据噪声输入 zt=tx+(1−t)ϵ 预测干净的图像像素块。损失函数定义为 LFM=E∥vθ−v∥2,其中 v=x−ϵ 且 vθ=(xθ−zt)/(1−t)。训练期间,表征 token 作为真实标签提供;而在推理阶段,解码器仅根据文本提示自回归地生成这些 token。这些预测出的表征 token 保留在序列中,作为像素空间扩散过程的上下文条件。注意力机制确保表征 token 中编码的高层结构通过标准自注意力影响像素生成,无需额外的交叉注意力模块。训练流水线支持无分类器引导,通过在训练期间以 0.1 的概率独立丢弃文本条件和表征 token 序列来实现。
实验
评估将引入 Representation Forcing 的新型像素空间模型与成熟的基于 VAE 的统一多模态架构在标准文生图与视觉理解基准上进行了对比。生成测试表明,该方法成功弥合了像素空间方法与基于 VAE 方法之间的质量差距,在组合生成与密集提示跟随方面取得了具有竞争力的表现。理解评估显示,Representation Forcing 持续提升了高层视觉理解能力,该像素空间变体通过消除潜在瓶颈并实现多模态表征的更紧密对齐,最终超越了基于 VAE 的对应模型。总体而言,这些结果验证了端到端像素空间统一模型在提供强大生成质量与稳健视觉理解方面的有效性。
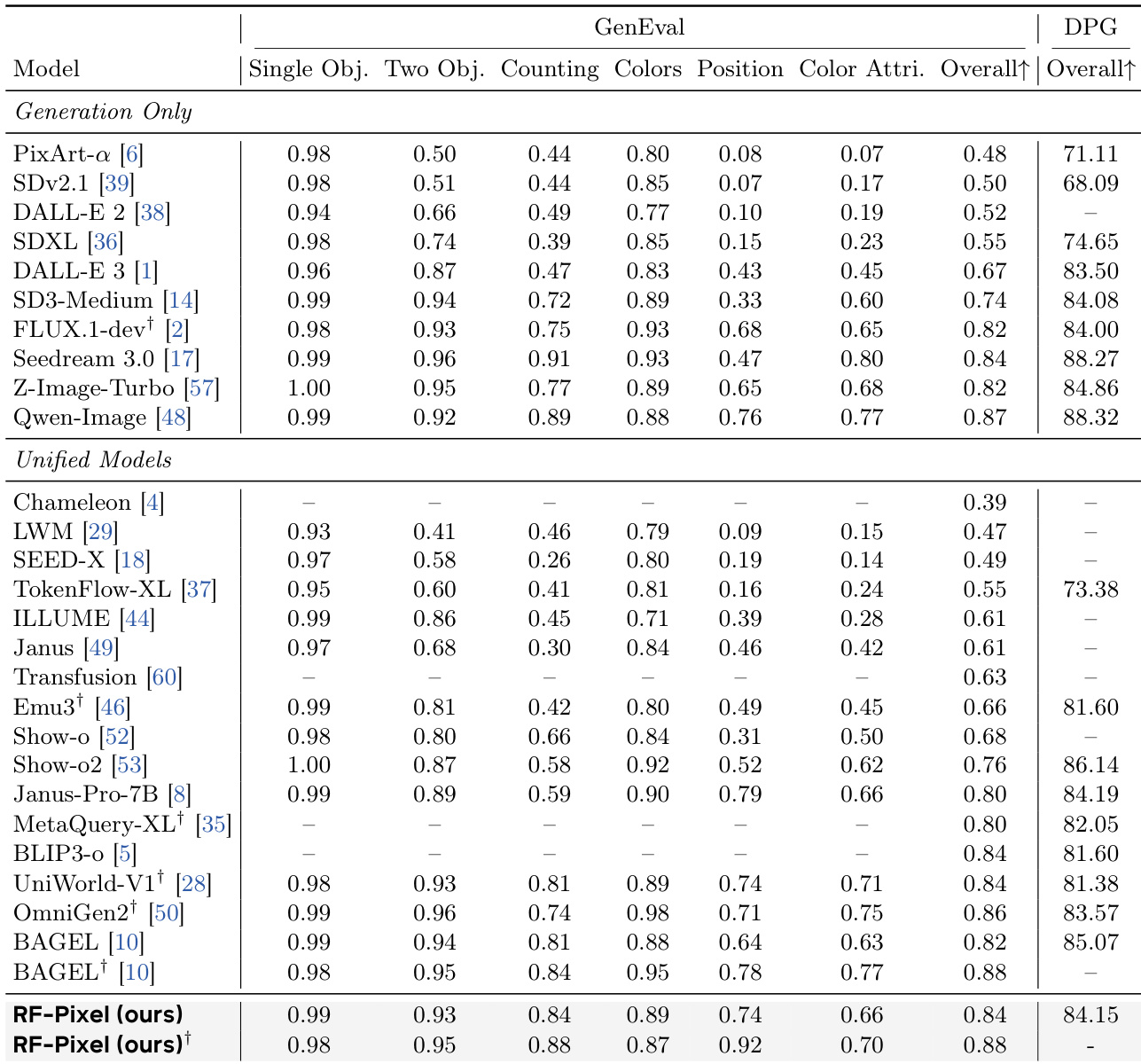
作者在文生图基准上评估了该像素空间模型,并将其性能与依赖预训练生成组件的现有模型进行对比。结果表明,该模型达到了具有竞争力的生成质量,并在多个基准上提升了理解能力,相较于基于 VAE 的方法,像素空间设置下的增益更为显著。Representation Forcing 在不同模型架构下均提升了生成与理解性能。引入 Representation Forcing 的像素空间模型在大多数视觉理解基准上优于基于 VAE 的模型。Representation Forcing 显著改善了高层视觉理解任务,但在面向文档的理解方面仅有轻微下降。

作者在文生图基准上评估了其像素空间模型,并与现有模型对比性能。结果显示,该模型在 GenEval 上取得了具有竞争力的分数,在使用语言模型重写器后性能进一步提升,并在图像理解任务上表现出强劲实力,尤其在通用视觉理解方面超越了基于 VAE 的方法。在组合生成任务上,该模型达到了与最先进统一模型相当或更优的性能。Representation Forcing 在多个基准上提升了理解能力,尤其是在通用视觉理解方面。采用 Representation Forcing 的像素空间生成在大多数评估任务中优于基于 VAE 的生成,表明统一表征空间带来了收益。

作者评估了 Representation Forcing (RF) 对不同生成路径下图像理解性能的影响,对比了有无 RF 的基于 VAE 与像素空间模型。结果表明,RF 在两种设置下均提升了理解能力,在通用视觉理解任务上增益更大,且像素空间模型相较于基于 VAE 的模型表现出一致的改进。作者将像素空间模型的优越性能归因于外部 VAE 潜在空间的缺失使得理解与生成之间的对齐更为紧密。RF 在基于 VAE 与像素空间生成路径上均提升了理解性能,在通用视觉理解任务上增益更为明显。引入 RF 的像素空间模型在大多数基准上优于基于 VAE 的模型,表明理解与生成之间的对齐效果更好。性能提升主要集中在需要高层视觉理解的任务上,而面向文档任务的性能仅有轻微下降。

作者在文生图基准上评估了其像素空间模型 RF-Pixel,并与现有的仅生成模型及统一多模态模型进行对比。结果显示,RF-Pixel 在组合生成与密集提示跟随方面达到了具有竞争力的表现,在无需依赖独立预训练生成组件的情况下,性能达到或超越了最先进模型。该模型在各类视觉任务中也展现出强大的理解能力,特别是在像素空间生成中从表征强制中获益良多。RF-Pixel 在组合生成与密集提示跟随上达到具有竞争力的表现,与最先进统一模型持平,且未使用预训练生成模块。Representation Forcing 在多个基准上持续改善理解能力,相较于基于 VAE 的生成,像素空间生成中的增益更为显著。采用 Representation Forcing 的像素空间生成在大多数基准上优于基于 VAE 的生成,尤其在通用视觉理解任务中表现突出。
作者评估了引入 Representation Forcing (RF) 的像素空间模型在图像生成与理解任务上的表现,将其与有无 RF 的基于 VAE 及像素空间模型进行对比。结果表明,RF 在两条路径上均提升了理解性能,在像素空间模型中增益更大,尤其是在通用视觉理解基准上,同时在面向文档的任务上性能略有下降。引入 RF 的像素空间模型在大多数基准上优于引入 RF 的基于 VAE 模型,表明统一表征空间实现了理解与生成的更紧密融合。RF 在基于 VAE 与像素空间模型上均提升了理解性能,在通用视觉理解基准上增益更为显著。引入 RF 的像素空间模型在八项基准中的六项上优于引入 RF 的基于 VAE 模型,尤其在通用视觉理解方面。RF 导致文档与图表理解任务的性能轻微下降,表明其在文本与布局理解方面存在一定局限。
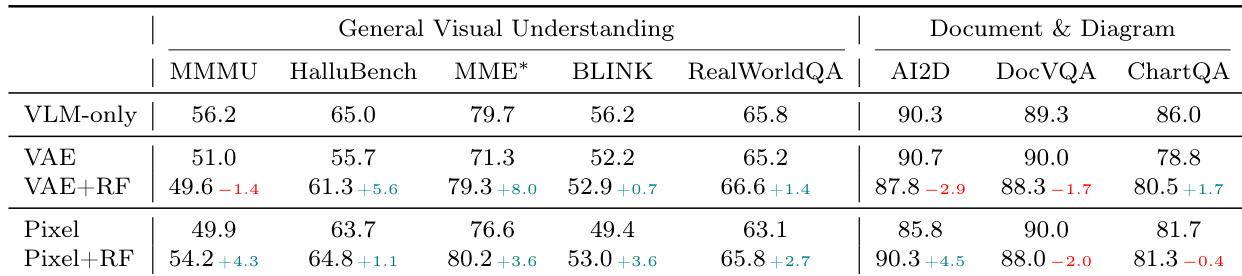
实验在文生图生成与视觉理解基准上评估了引入 Representation Forcing 的像素空间模型,并将其性能与基于 VAE 的架构及预训练统一模型进行验证。结果表明,Representation Forcing 在两条生成路径上持续改善视觉理解能力,像素空间实现因生成与表征之间的更紧密对齐而带来更优的理解效果。尽管该模型在无需依赖预训练组件的情况下达到了具有竞争力的生成质量,但在面向文档与布局理解的任务上存在轻微权衡。总体而言,研究结果证实,在单一像素空间表征中统一生成与理解能力,能够有效弥合视觉推理与组合能力之间的差距。