Command Palette
Search for a command to run...
LongTraceRL:从搜索 Agent 轨迹与评分标准奖励中学习长上下文推理
LongTraceRL:从搜索 Agent 轨迹与评分标准奖励中学习长上下文推理
Nianyi Lin Jiajie Zhang Lei Hou Juanzi Li
摘要
长上下文推理仍然是大语言模型面临的核心挑战,模型往往难以在大量干扰内容中定位并整合关键信息。具有可验证奖励的强化学习(RLVR)在该任务中展现出潜力,然而现有方法受限于低混淆度干扰项以及仅基于结果的稀疏奖励信号,无法对中间推理步骤进行监督。为解决这些问题,我们提出了LongTraceRL。在数据构建方面,我们通过知识图谱随机游走生成多跳问题,并利用搜索agent轨迹构建分层干扰项:agent已阅读但未引用的文档(高混淆度)以及在搜索结果中出现但从未被打开的文档(低混淆度),从而生成比随机采样或单次搜索构建的训练上下文更具挑战性的数据。在奖励设计方面,我们提出了一种量规奖励,利用每条推理链上的真实实体作为细粒度的实体级过程监督。该量规奖励仅应用于最终答案正确的响应(仅正样本策略),以区分正确响应之间的推理质量差异,并防止奖励黑客攻击。在五个长上下文基准测试上对三种推理大语言模型(4B--30B)开展的实验表明,LongTraceRL一致地优于强基线模型,并能够促进全面且基于证据的推理。代码、数据集和模型已开源,地址为 https://github.com/THU-KEG/LongTraceRL{https://github.com/THU-KEG/LongTraceRL}。
一句话总结
LongTraceRL 通过利用搜索 agent 轨迹构建分层干扰项,并部署评分标准奖励以进行细粒度、实体级的过程监督,从而推进长上下文推理能力。该方法有效克服了限制先前强化学习方法的稀疏结果信号与低混淆度干扰项问题。
核心贡献
- 长上下文训练数据构建方法:通过知识图谱随机游走生成多跳问题,并利用真实搜索 agent 轨迹构建分层干扰项。该方法以语义相关文档替代随机采样,显著提升训练难度。
- 实体级评分标准奖励:通过追踪每次推理跳步中的黄金实体提供细粒度过程监督。该仅正向策略仅应用于最终答案正确的回复,用于区分成功输出的推理质量并防止奖励黑客行为。
- 评估:在五个长上下文基准和三个参数量介于 4B 至 30B 的模型系列上进行了评估,结果均一致优于现有基线。该方法使 Qwen3-4B 相比其基础版本平均提升 5.7 分,并超越最强基线 2.5 分。
引言
长上下文推理对于大语言模型提取相关信息、执行多跳推理以及维持长文档连贯性至关重要,然而它仍是将具备推理能力的 AI 部署到现实应用中的关键瓶颈。先前具备可验证奖励的强化学习方法面临训练数据浅层化的问题,其依赖随机采样的语义无关干扰项,同时仅依赖结果奖励的稀疏信号无法监督中间推理步骤,导致模型可能凭借运气成功。为克服这些障碍,研究团队利用搜索 agent 轨迹构建分层且高混淆度的干扰项,并引入一种评分标准奖励,以在每次推理跳步中提供细粒度、实体级的过程监督。这种双重方法训练模型更有效地区分相关证据,并防止奖励黑客行为,从而在多种模型规模和基准测试中持续提升长上下文推理性能。
数据集

-
数据集构成与来源
- 研究团队使用 KILT 维基百科快照作为唯一知识源构建该数据集。该流程利用知识图谱结构生成带有可验证推理链的多跳问题,同时 agent 搜索行为提供真实的干扰项。
-
各子集关键细节
- 多跳问题生成:研究团队在维基百科超链接图上执行受控的八步随机游走。大语言模型在每一步从最多五个未访问候选项中选择下一个实体,并定期执行随机跳跃以丰富图谱探索。
- 问题合成:高性能大语言模型生成要求逐步推理所有路径实体才能解答的问题。提示词强制要求使用改写后的标识符、基于唯一属性的答案以及明确的中间黄金实体。
- 搜索轨迹收集:深度搜索 agent 记录搜索、打开文档和引用信息等操作。研究团队为每个问题采样五条独立轨迹,仅保留正确路径,并丢弃所有尝试均失败的问题。
- 干扰项分层:检索到的文档被分类为一级干扰项(agent 打开但未引用)和二级干扰项(出现在搜索结果中但从未被打开)。
-
数据使用与处理
- 训练应用:研究团队使用该数据集训练长上下文强化学习模型,特别针对大规模输入实现实体级推理监督。
- 上下文组装:研究团队应用 traj-tiered 策略,优先使用一级干扰项以最大化挑战难度,随后使用二级干扰项填充剩余上下文空间直至达到目标长度。所有文档均被打乱顺序以防止位置捷径。
- 过滤规则:仅保留展现目标导向搜索行为的轨迹。在五次尝试中未产生正确轨迹的问题将从最终收集中移除。文本未指定固定的训练集与验证集划分或静态混合比例,而是依赖动态的 traj-tiered 组装流程。
-
元数据构建与附加细节
- 元数据生成:每个样本包含问题文本、标准答案、一组黄金实体及其对应的维基百科段落,以及完整的 agent 轨迹日志。
- 处理限制:该数据集完全依赖百科知识,这可能限制推理的多样性。干扰项的质量与难度直接取决于所部署搜索 agent 的能力。
方法
LongTraceRL 框架包含两个核心组件:数据构建流程与强化学习框架。数据构建流程通过合成源自 agent 的干扰项来生成长上下文训练数据,而强化学习框架整合基于结果与基于过程的奖励以指导模型训练。
数据构建流程始于多跳问题生成步骤,其中实体路径源自知识图谱(如维基百科)上的随机游走。路径中的每个节点代表一个带有相关描述的实体,任务在于构建一个多跳问题,要求通过逐步推理得出最终答案,该答案对应路径中最后一个节点的属性。如下图所示,生成的问题必须简洁,包含的独特线索数量最多为实体数量的两倍,并确保答案由推理链唯一确定。

随后,框架通过模拟执行一系列搜索与打开操作以回答生成问题的 agent,来收集 agent 搜索轨迹。该过程生成包含黄金实体与文档的路径,构成训练数据的基础。轨迹进一步通过分层干扰项提取进行处理,文档根据其相关性与引用状态进行分类。这包括识别推理链中引用的黄金文档、已打开但未引用的一级文档,以及已搜索但未打开的二级文档,所有文档均用于构建具有挑战性的长上下文组装内容。
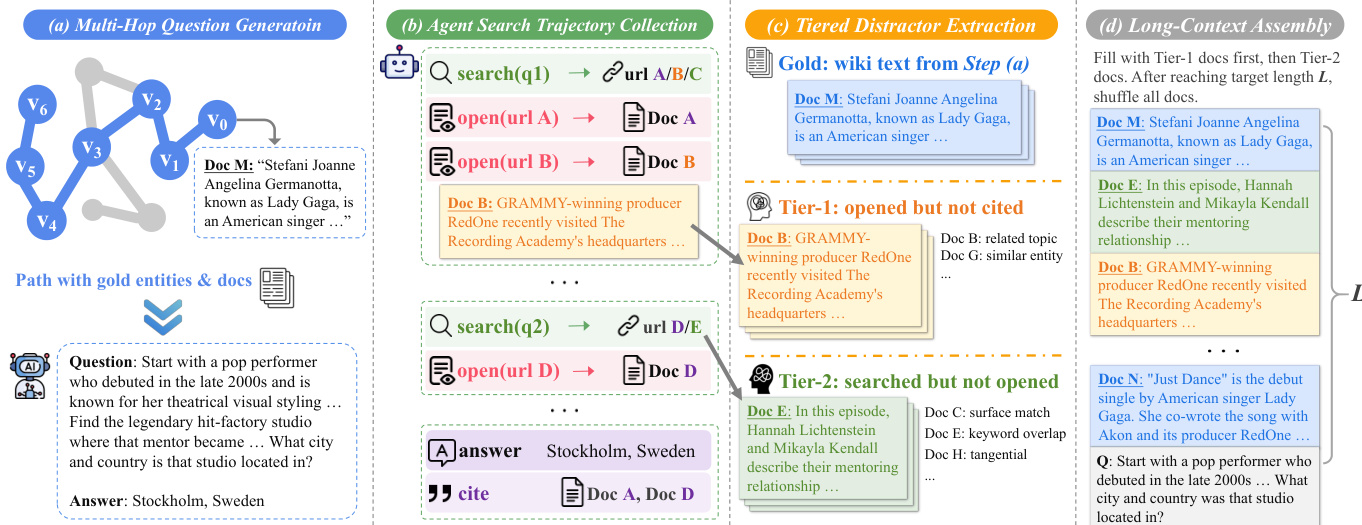
在强化学习阶段,框架采用组相对策略优化(GRPO)作为底层算法。奖励函数设计为结果奖励与评分标准奖励的组合。结果奖励为二值信号,由大语言模型裁判评估模型最终答案是否正确。评分标准奖励衡量模型回复中黄金实体的召回率,计算方式为回复中出现的黄金实体数量占黄金实体总数的比例。

为确保不同问题间的可比性,原始评分标准分数会在每组回复内归一化,即除以该组的最高原始分数,将奖励重新缩放至 [0, 1] 范围。采用仅正向奖励策略以防止奖励黑客行为,即评分标准奖励仅授予最终答案正确的回复。最终奖励为结果奖励与归一化评分标准奖励的加权组合,其中超参数 α 控制结果监督与过程监督之间的平衡。该设计激励模型生成基于相关证据的高质量推理。
实验
评估在多个模型系列和五个推理基准上测试了所提出的长上下文强化学习方法,将其与既定基线及系统性消融实验进行对比,以分离关键训练组件的影响。结果表明,该方法持续提升多跳推理与上下文锚定能力,主要得益于鼓励深思熟虑且实体对齐思考的评分标准奖励。进一步验证确认,精心筛选的基于轨迹的干扰项与仅正向奖励约束对维持训练稳定性及防止捷径行为至关重要。最终,该方法通过迫使模型解决冲突线索、消歧引用并严格遵循细微的问题约束,促进更深层次的上下文理解。
研究团队使用不同模型规模与配置在多个长上下文推理基准上评估 LONGTRACERL 的性能。结果表明,引入评分标准奖励组件显著提升性能,尤其在挑战性基准上,且方法的有效性对评分标准奖励权重敏感。平衡的奖励配置取得最佳结果,而移除仅正向策略或使用较弱的干扰项设计会导致性能下降。当包含评分标准奖励时,该方法在所有基准上均实现稳定提升,其中最具挑战性的 AA-LCR 基准提升幅度最大。性能对评分标准奖励权重敏感,中间权重值产生最佳整体结果,过高或过低均导致性能下降。移除仅正向奖励策略会导致明显性能下滑,尤其在推理密集型任务上,表明其在防止奖励黑客行为中的作用。

研究团队对比了用于训练长上下文推理模型的不同干扰项策略,重点关注干扰项混淆度对模型性能的影响。基于多层轨迹生成干扰项的 traj-tiered 策略与评分标准实体产生最高重叠度,并带来最佳整体性能。相比之下,随机与基于搜索的干扰项实体重叠度显著较低,导致性能较差。结果表明,更具挑战性的干扰项(尤其是与推理路径紧密对齐的干扰项)能够改善模型学习。traj-tiered 干扰项策略实现与评分标准实体的最高重叠度,并在下游基准上表现最佳。随机与基于搜索的干扰项与推理路径的实体重叠度低,导致训练信号较弱且模型性能较低。以实体召回率衡量的干扰项混淆度与下游性能高度相关,凸显其在训练数据质量中的重要性。
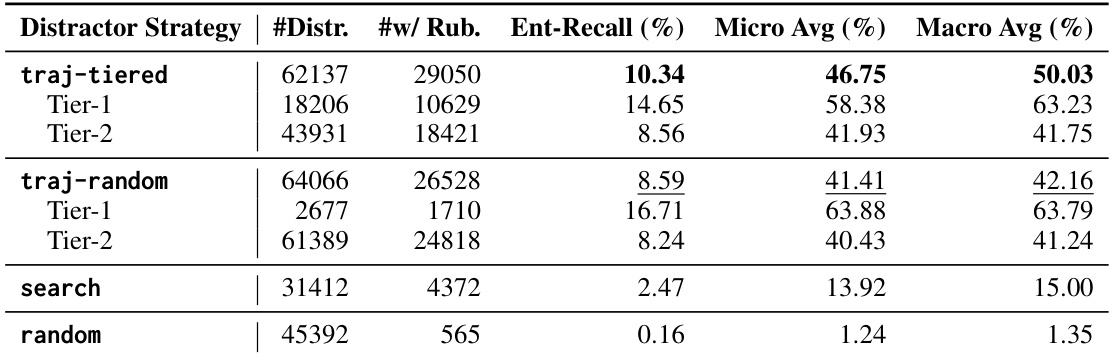
研究团队使用不同干扰项策略在多个长上下文推理基准上评估 LONGTRACERL 的性能。结果表明,轨迹分层干扰项方法取得最高平均分,优于随机、基于搜索及轨迹随机替代方案,尤其在 AA-LCR 基准上。该方法在所有评估基准上均稳定优于基础模型与其他基线。与随机、基于搜索及轨迹随机替代方案相比,轨迹分层干扰项策略在所有基准上实现最高平均性能。LONGTRACERL 显著提升基础模型在 AA-LCR 基准上的性能,取得所有方法中的最佳分数。该方法在多个基准上展现一致的提升,在使用轨迹分层干扰项策略时观察到最高平均分。

研究团队使用不同大语言模型骨干网络在多个长上下文推理基准上评估 LONGTRACERL 的性能。结果表明,与正负混合变体相比,仅正向奖励策略在所有基准上显著提升性能,最高增益出现在 AA-LCR 与 MRCR 基准上。该方法在所有评估模型与基准上均稳定优于基线。仅正向奖励策略在所有基准上取得最高平均分,优于正负混合变体。该方法在 AA-LCR 与 MRCR 基准上展现最显著的提升,表明其在挑战性推理任务上具备更强性能。性能增益在不同模型规模与系列中保持一致,证明其对模型规模与架构具有鲁棒性。

研究团队使用不同模型在多个长上下文推理基准上将 LONGTRACERL 与若干基线方法进行对比。结果表明,LONGTRACERL 在所有模型规模上均稳定取得最高平均性能,显著优于其他方法,尤其在 AA-LCR 与 LongReason 等挑战性基准上。性能提升归功于评分标准奖励与仅正向策略,二者引导模型生成更准确且基于证据的推理回复。与所有基线相比,LONGTRACERL 在所有模型与基准上取得最高平均分。该方法在挑战性基准上展现最显著增益,尤其在 AA-LCR 与 LongReason 上大幅超越其他方法。性能提升主要由评分标准奖励与仅正向策略驱动,二者鼓励准确且基于证据的推理,同时避免奖励黑客行为。
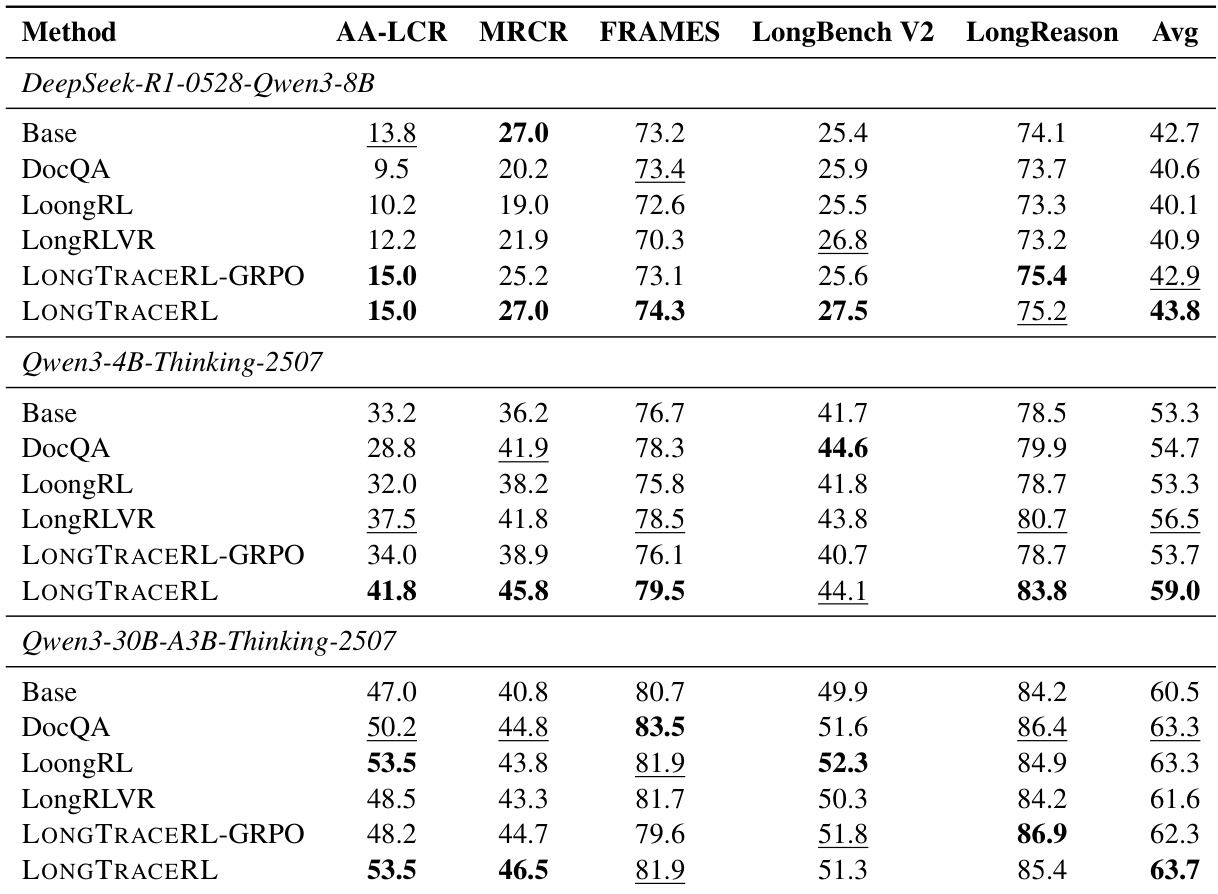
在多个长上下文推理基准与模型配置上的评估表明,LONGTRACERL 通过针对性的组件分析展现出对基线的持续优势。实验验证了平衡的评分标准奖励显著提升挑战性任务的性能,而具有高实体重叠度的轨迹分层干扰项比随机替代方案提供更强的训练信号。此外,将奖励限制为正向信号有效防止奖励黑客行为,并在不同模型架构上提升推理准确性。综合这些发现证实,评分标准引导奖励、高质量干扰项与仅正向反馈的协同整合推动了更准确且基于证据的长上下文推理。