Command Palette
Search for a command to run...
COLLEAGUE.SKILL:基于专家知识蒸馏的自动化AI技能生成
COLLEAGUE.SKILL:基于专家知识蒸馏的自动化AI技能生成
Tianyi Zhou Dongrui Liu Leitao Yuan Jing Shao Xia Hu
摘要
LLM agents 越来越被期望不仅要完成孤立的任务,还要承载对人类专业知识、判断力和交互风格的有界表示。构建此类以人为基础的 agent 仍然具有挑战性,因为与特定人员或角色相关的可操作知识通常嵌入在异构痕迹中,而非以清晰的指令形式书写。现有的记忆与人格系统仅能捕捉此类证据的片段,而技能框架提供了可移植的打包格式;然而,目前尚缺乏将这些痕迹提炼为可检查、可修正且可供 agent 使用的技能的端到端工作流。我们提出了一种自动化的痕迹到技能提炼系统,通过专家知识蒸馏生成以人为基础的 AI 技能。给定目标人员或角色的相关材料,COLLEAGUE.SKILL 会生成一个包含两条协同轨道的版本化技能包:一条能力轨道用于实践、心智模型和决策启发式方法,另一条受限行为轨道用于沟通风格、交互规则和修正历史。该技能包支持检查、调用、通过自然语言反馈进行更新、回滚、跨 agent 主机安装,并可选择性地准备用于受控分发。我们描述了该开源系统中实现的工件契约、生成工作流、修正生命周期、部署面以及领域预设。截至撰写本文时,该公开仓库已获得约 18.5k GitHub stars;技能画廊收录了来自 165 位贡献者的 215 项技能,所有列出的技能卡片累计获得超过 100k stars。该系统展示了以人为基础的技能如何被表示为可移植、可修正的包,而非不透明的提示词或隐藏的记忆。
一句话总结
作者提出了 COLLEAGUE.SKILL,这是一个自动化的专家知识蒸馏系统,能够将目标人物的异构轨迹转化为版本化的技能包。该技能包包含用于决策启发式的“能力轨道”和用于交互规则的“受限行为轨道”,使该包能够被审查、通过自然语言反馈进行更新,并安装到多个 Agent 主机中。
核心贡献
- 本文介绍了 COLLEAGUE.SKILL,一种自动化的轨迹到技能蒸馏系统,可将异构的人类交互轨迹转化为可移植的、人物锚定(person-grounded)的 AI 技能。
- 该方法生成包含两个协同轨道的版本化技能包,明确将操作能力(实践、心智模型和决策启发式)与受限行为约束(沟通风格、交互规则和修正历史)分离开来。
- 该系统提供了一个透明的工作流,支持包审查、自然语言反馈、状态回滚以及跨 Agent 主机的安装,以确保蒸馏出的技能在部署环境中始终保持可编辑、可移植且可追溯。
引言
随着大语言模型(LLM)Agent 从执行孤立指令向承载可复用专业知识演进,该领域正迅速采用模块化技能架构,将领域知识与交互模式打包以供按需部署。然而,将聊天日志、文档和公开记录等非结构化人类轨迹转化为结构化的 Agent 能力仍然是一个重大挑战。早期的记忆与人格系统通常会将此类证据碎片化,或依赖缺乏来源追溯、修正机制和明确使用边界的黑盒提示词。作者利用自动化蒸馏流水线,通过 COLLEAGUE.SKILL 系统弥补了这一空白。该系统可将异构的人类轨迹转化为版本化、可移植的技能包。通过明确分离操作能力与受限行为约束,该框架使用户能够在多个 Agent 主机上审查、修正、回滚并部署人物锚定的技能,同时保持对源材料和分发限制的完全透明。
数据集

- 数据集构成与来源: 作者构建了一个以公众人物为中心的人物锚定技能生态系统,主要素材来源于第一人称作品、长篇访谈、已记录的决策以及明确标注的推论。语料库还通过社区对 COLLEAGUE.SKILL 平台的贡献进一步扩大。
- 子集详情: 虽然未明确说明各子集的具体规模,但数据围绕专属的名人预设(preset)和模块化社区技能进行组织。每条条目均经过筛选,优先保留内容详实的长篇材料,并明确排除简短摘要和低质量的内容聚合器。
- 数据使用与训练: 作者利用此精选数据集进行公开来源的专家蒸馏。在推理阶段,系统会追踪证据的可用性,并在源材料匮乏时自动降低置信度分数,防止模型使用通用的人格文本填补空白。该流水线支持迭代创建、版本化修正以及透明的公开分发。
- 处理与元数据构建: 预处理流水线在合并研究笔记之前,会自动完成字幕提取、语音转写和文本清理工作。专用的质量检查器会评估每个制品的心智模型覆盖度、风格模式、内部矛盾、溯源链接以及版权合规性。所有证据约束和质量指标均被打包为显式元数据,随最终的分发输出一同提供。
方法
作者利用结构化流水线进行人物锚定的技能蒸馏,旨在将异构的人类轨迹转化为可移植、可审查且可治理的技能制品。核心框架称为 COLLEAGUE.SKILL,通过一系列明确定义的阶段运行:轨迹接入、预设路由、双轨蒸馏、制品生成和产品化。如下图所示,该流程始于轨迹接入阶段,在此阶段收集工作文档、聊天日志、评审意见或公开访谈等原始材料并本地存储。这些输入随后通过预设路由器进行路由,该路由器根据源类型和治理假设选择适当的领域特定配置(例如同事、名人或关系)。选定的预设定义了证据范围、访问控制以及调用语义。 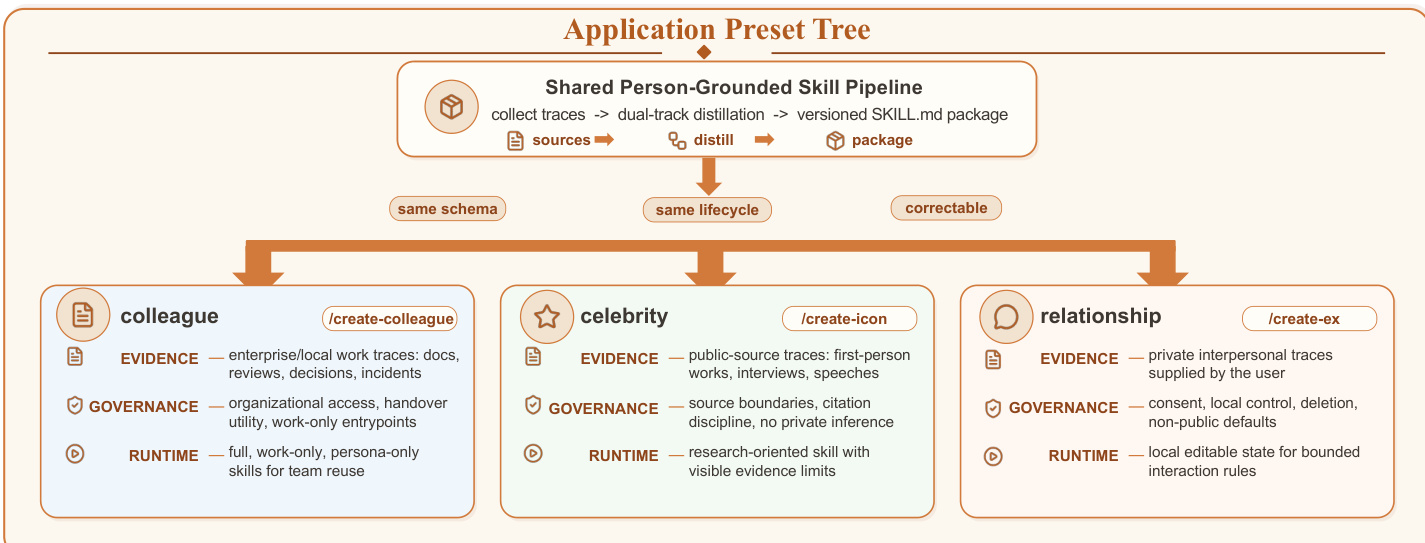
路由完成后,双轨蒸馏阶段将技能拆分为两个独立的轨道:能力轨道与人格轨道。能力轨道捕获源自源材料的持久性心智模型、程序化判断和技术标准,而人格轨道则编码受限行为约束、交互规则和表达偏好。这种分离确保生成的技能在专家判断与表面行为之间保持清晰界限,从而支持独立调用完整模式、仅能力模式或仅人格模式的入口点。双轨表示是系统设计的核心,它防止了事实知识与交互风格的混淆,并支持组合性与正确性。 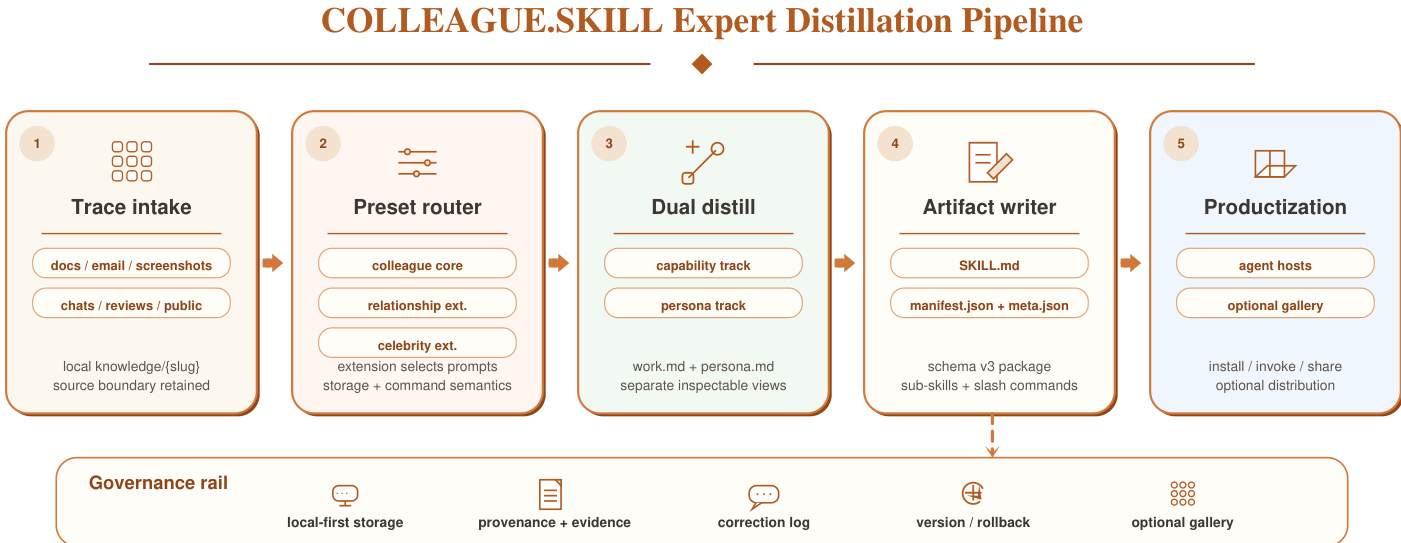
随后,蒸馏出的轨道由制品生成器处理,该生成器将元数据规范化为版本化架构,并渲染最终的技能包。该包包含一个结合双轨的主 SKILL.md 文件,以及独立的 work.md 和 persona.md 源文档、可独立调用的子技能,以及 manifest.json 和 meta.json 等元数据文件。生成器确保与 Agent Skills 标准保持一致,其中 SKILL.md 作为必需入口点,可选文件则提供脚本或参考内容。最终生成的制品是一个自包含的版本化包,可安装至受支持的 Agent 主机,通过可选画廊进行分享,或通过修正记录进行修改。 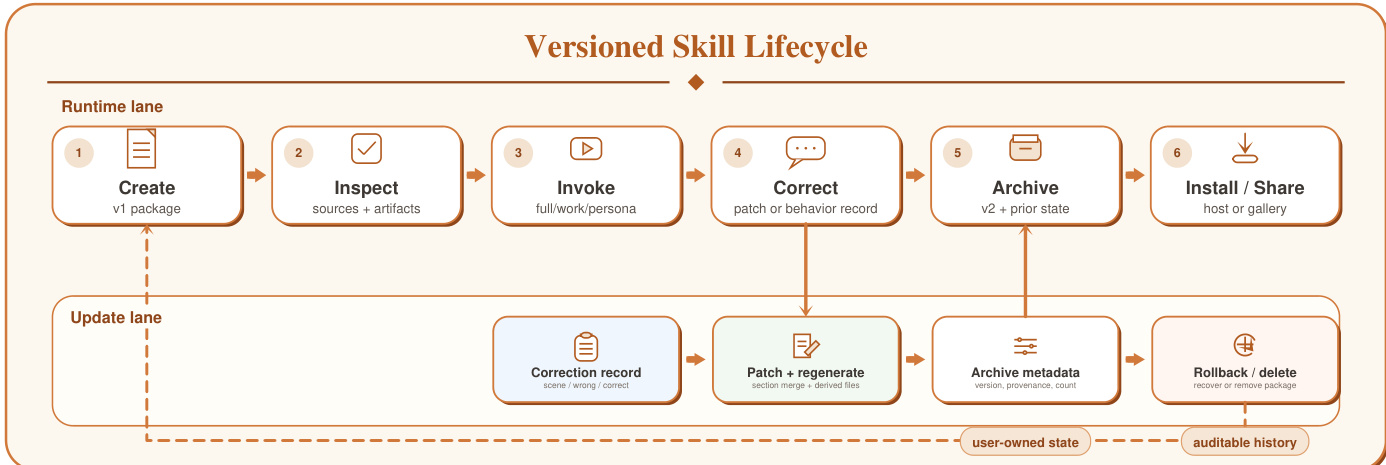
该系统支持全面的技能管理生命周期,包括修正、回滚和可选的分发。修正通过处理器进行,该处理器解析自然语言反馈,并生成用于能力更新的 Markdown 补丁或用于行为调整的结构化修正记录。这些更改会触发制品的重新生成,递增生命周期版本号并保留先前状态。版本管理器支持列表查看、备份、回滚和清理归档,确保制品在长期运行中保持可审计和可修正。该生命周期由治理护栏(governance rail)提供支持,强制实施本地优先存储、来源追溯和用户拥有的修正日志,从而使整个过程透明且可问责。