Command Palette
Search for a command to run...
用于同策略蒸馏的信赖域行为混合
用于同策略蒸馏的信赖域行为混合
Daniil Plyusov Alexey Gorbatovski Alexey Malakhov Nikita Balagansky Boris Shaposhnikov Daria Korotyshova Daniil Gavrilov
摘要
同策略蒸馏(OPD)在从自身策略采样的前缀上训练学生模型,同时使其匹配更强的教师模型。该方法解决了离线蒸馏中的前缀不匹配问题,但早期的学生模型 rollout 序列可能仍然较差,致使教师监督作用于较弱或低质量的前缀上。我们提出了信任域行为混合(TRB)方法,这是一种预热策略,该方法在以学生为中心的KL信任域内,使用最接近教师的行为策略替换早期的 rollout 策略,同时保持逐前缀 reverse-KL OPD 损失不变。KL预算将逐渐退火至零,因此预热结束后训练将恢复为纯粹的学生模型 rollout。在两种数学推理蒸馏设置下,TRB在对比方法中取得了最优的平均性能。
一句话总结
Trust-Region behavior Blending (TRB) 是一种用于 on-policy distillation 的 warmup 方法。该方法在以学生为中心的 KL trust region 内部,使用最接近 teacher 的 behavior policy 替换学生早期低质量的 rollouts,在保留 per-prefix reverse-KL loss 的同时,在两种数学推理 distillation 设置中实现了最强的平均性能。
核心贡献
- Trust-Region behavior Blending (TRB) 在 on-policy distillation 中,使用受限于学生中心化 KL trust region 的 behavior policy 替换早期的学生 rollouts,以保留监督质量。
- 该方法优化早期 prefix 分布,而非修改生成后的目标或 token 选择,其 KL 预算会 anneal 至零,从而在 warmup horizon 结束后恢复纯学生 rollouts。
- 在两种数学推理 distillation 设置下的实验表明,TRB 在 vanilla on-policy distillation 及其他 teacher-guidance 基线方法中取得了最强的平均性能。
引言
知识蒸馏将大型 teacher 模型的推理能力迁移至较小的 student 模型,但传统方法存在 exposure bias 问题,因为学生仅在固定的 teacher prefix 上进行训练,而非基于自身的 rollouts。On-policy distillation 通过在学生实际生成的轨迹上进行监督来解决此问题,但早期训练依然脆弱,因为能力较弱的学生生成的 prefix 质量较低,而较强的 teacher 干预又可能破坏 on-policy 保证。作者利用 Trust-Region behavior Blending (TRB) 在 student 周围严格的 KL trust region 内优化 teacher-guided behavior policy,从而稳定早期的 rollout 收集过程。该方法在不修改底层 distillation 目标的前提下,为关键的 warmup 阶段提供 targeted teacher supervision,且当 student policy 成熟后,混合机制会按系统计划 annealed。
方法
作者基于 trust-region 优化框架设计了 Trust-Region behavior Blending (TRB),这是一种用于 on-policy distillation (OPD) 的 warmup 策略。该策略在遵循学生中心化 trust region 的前提下,将 rollout 生成导向 teacher policy,从而提升早期训练的稳定性。其核心思想是在训练初期,用一种平衡接近 teacher 程度与遵循 student 当前行为的行为策略,替换 student 自身生成 prefix 的策略。该方法保留了在整个训练过程中保持不变的 reverse-KL OPD loss,但修改了用于收集 prefix 的采样分布。该 behavior policy 被定义为在相对于当前 student policy 的 KL-divergence 约束下最接近 teacher 的策略,从而确保生成的 prefix 既具备 teacher 的引导信息,又不会与 student 的当前行为产生过度偏离。
参考框架示意图,该图展示了在给定 prefix h 处的优化过程。Student policy πS 在策略空间中表示为一个点,Teacher policy πT 为另一个点。πS 周围的虚线圆表示学生中心化的 KL trust region,由约束条件 DKL(μ∥πS)≤ε 定义。Behavior policy μ∗ 是在满足该约束的前提下,最小化到 teacher policy 的 KL 散度 DKL(μ∥πT) 的解。该解位于 trust region 的边界上,是在允许偏差范围内最接近 teacher 的策略。该图强调,最优策略 μ∗ 是通过平衡 teacher 与 student 的影响获得的,且该约束确保策略不会过度偏离 student 的当前分布。
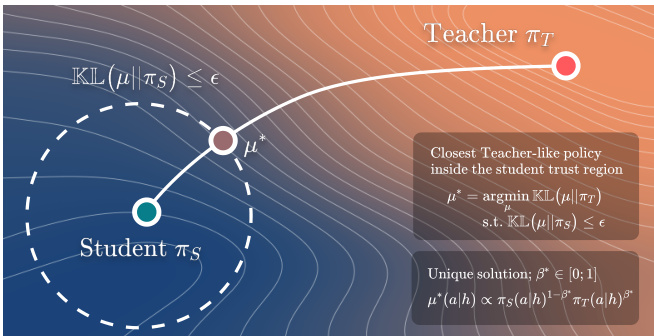
Per-prefix behavior policy 被定义为约束优化问题的解。在 prefix h 处,目标是找到一个策略 μ∗(⋅∣h),使其最小化到 teacher policy πT(⋅∣h) 的 KL 散度,同时确保到 student policy πS(⋅∣h) 的 KL 散度不超过预设预算 ε。该问题表述为:
μ∗(⋅∣h)=μargminDKL(μ∥πT)s.t.DKL(μ∥πS)≤ε,∑aμ(a)=1,μ(a)≥0.该优化过程会选择在当前 student policy 局部偏差范围内、最接近 teacher 的分布,从而在保持稳定性的同时有效引导学生向 teacher 靠拢。该问题的解具有闭式表达式,以加权方式结合 student 与 teacher policy。具体而言,behavior policy 表示为:
μβ(a∣h)=Zβ(h)πS(a∣h)1−βπT(a∣h)β,其中 β∈[0,1] 控制 teacher 影响程度,Zβ(h) 为归一化常数。最优值 β∗(h) 是满足 KL 散度约束的最大可行 β:
β∗(h)=max{β∈[0,1]∣DKL(μβ∥πS)≤ε}.当 ε=0 时,策略保持与 student policy 一致。若 teacher policy 本身满足约束条件,则 behavior policy 直接退化为 teacher policy。否则,通过二分法计算 β∗(h),利用 DKL(μβ∥πS) 关于 β 的单调性确保收敛。
为进一步控制从 teacher-guided 到 student-driven 采样的过渡,TRB 采用了 annealed warmup 调度策略。KL 预算 ε 在 warmup horizon K 期间逐渐降低,从初始值 ε0 线性递减至零。步骤 k 的预算表示为:
εk=ε0(1−Kk),k≤K.该 annealing 机制确保早期 rollouts 更多受到 teacher 影响,提供稳定的监督;随着训练推进,策略逐渐恢复为纯 student rollouts,使学生最终能够从自身行为中学习。该机制引入两个关键超参数:初始 KL 预算 ε0 与 warmup horizon K,它们决定了 warmup 阶段 teacher guidance 的强度与持续时间。
实验
评估部分在两组 Qwen3 teacher-student 模型对上,将 TRB 与 vanilla OPD 及 persistent off-policy 基线方法进行对比,以验证有限的早期行为引导是否能提升最终的推理性能。基准测试对比证实,TRB 通过比固定混合策略更有效地利用相同局部求解器,取得了更优的平均结果;早期训练分析则表明,targeted warmup 干预成功将初始 rollouts 向与 teacher 对齐的 prefix 偏移。这些发现表明,短暂的早期引导能有效解决初始阶段 student-teacher 的对齐偏差,而在整个训练期间维持 off-policy 行为则会导致收益递减并产生不必要的计算开销。
作者通过实验评估了 TRB 方法,该方法利用来自 teacher 的有限早期引导以改善 OPD 结果。结果表明,TRB 在两组模型对设置中均取得了最高的平均性能,优于采用更强或更 persistent off-policy 引导的基线方法。该方法在初始训练阶段效果最为显著,此时它会将 student 的早期 rollouts 向更有潜力的 prefix 偏移,而当 student 与 teacher 行为趋于一致时,收益会逐渐递减。与其他 off-policy 方法相比,TRB 在两组模型对设置中均实现了最佳平均性能。TRB 的有效性高度集中于早期训练阶段,无需依赖 persistent teacher guidance。该方法通过将 student 的早期 rollouts 引导至在 teacher 与 student 延续下更可能取得成功的 prefix,从而提升了训练初期表现。
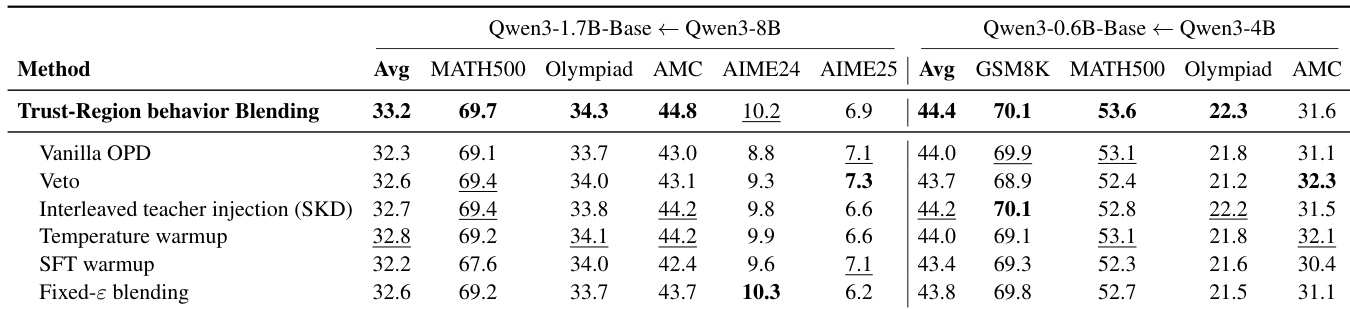
作者在两组模型对设置中将 Trust-Region Behavior Blending (TRB) 与多种基线方法进行对比,结果表明 TRB 在所有任务上均取得了最高的平均性能。结果显示,来自 teacher 的早期引导能够改善最终结果,TRB 的表现优于采用 persistent teacher guidance 或不同 warmup 策略的方法。性能最优的方法在 Qwen3-1.7B-Base 设置中的得分始终高于较小的 Qwen3-0.6B-Base 设置。TRB 在两组模型对设置中均实现了最佳平均性能,优于所有基线方法。与采用 persistent teacher guidance 或固定 epsilon blending 的方法相比,TRB 展现出更优的结果。TRB 与其他方法之间的性能差距在较大的模型对设置中最为显著。
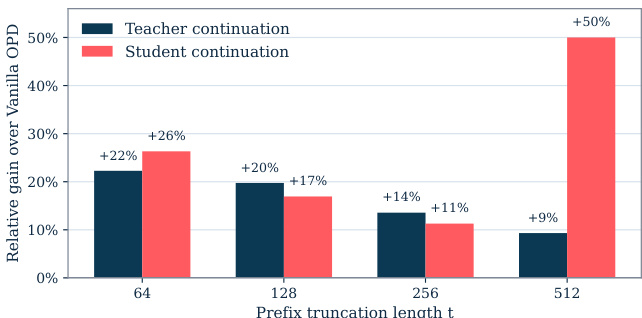
作者通过比较 warmup 阶段的 teacher 与 student continuation 策略,分析了早期行为引导对 off-policy distillation 的影响。结果表明,在不同 prefix 截断长度下,teacher-guided continuation 始终优于 student continuation,且随着 prefix 长度增加,性能差距逐渐扩大。Teacher continuation 相较于 vanilla OPD 的相对提升在更长截断长度下更高,这表明当 student 的初始 rollouts 距离 teacher 分布越远时,早期引导的效果越显著。在所有 prefix 长度下,teacher continuation 均比 student continuation 提供更高的相对收益。Teacher continuation 的性能优势随 prefix 截断长度的增加而扩大。Teacher continuation 相较于 vanilla OPD 的相对提升在较长 prefix 长度下更为明显。
作者在两组模型对配置下将 Trust-Region Behavior Blending 与多种 off-policy 基线方法进行对比,以评估有限的早期 teacher guidance 如何影响 distillation 结果。主要实验验证了,在初始训练阶段策略性地应用 brief teacher guidance 能够通过将早期 rollouts 引导至成功的 prefix 来显著提升最终性能,而 continuous guidance 则收益递减。对 warmup 策略的次要分析证实,teacher-guided continuation 始终优于 student-led 方法,且当初始 rollouts 与目标分布显著偏离时,提升最为明显。综合来看,这些发现表明,在优化 off-policy distillation 时,targeted early intervention 是一种比 persistent supervision 更高效且有效的策略。