Command Palette
Search for a command to run...
SwanVoice:面向独白与对话的富有表现力长文本零样本语音合成
SwanVoice:面向独白与对话的富有表现力长文本零样本语音合成
Ruiqi Li Yu Zhang Changhao Pan Ke Lei Xiang Yin Cheng Yang
摘要
零样本文本转语音(TTS)在单说话人合成方面已取得显著进展,但富有表现力的长篇幅多说话人对话合成仍具挑战。一种常见的变通方案是使用独白TTS模型逐轮合成,再将结果拼接。此举不仅增加了推理成本,还常常破坏轮次间的声学一致性、对话连贯性与情感连续性。近期的对话TTS系统已开始针对该场景展开研究,但仍难以同时兼顾表现力连贯性、可控的说话人切换以及独白质量。本文提出SwanData-Speech与SwanVoice。SwanData-Speech利用真实场景音频构建独白与对话语料库,采用Swan Forced Aligner进行考虑停顿的单词级对齐,并借助RobustMegaTTS3处理发音困难样本。基于上述数据,SwanVoice是一款支持1至4名说话人的零样本TTS模型,融合了25 Hz VAE、带有考虑停顿符号与拼音替换的原始文本条件控制,以及带有说话人轮次条件控制的流匹配DiT。训练过程从独白语音起步,逐步过渡至混合与真实对话数据,随后采用DiffusionNFT进行后训练,并引入音素级与说话人相似度奖励。在SwanBench-Speech基准测试中,SwanVoice在独白与对话设置下均取得了高于所有已评估开源基线模型的丰富度与层次结构得分,但内容准确性仍是当前的主要瓶颈。音频演示请访问 https://swanaigc.github.io//#swanvoice。
一句话总结
SwanVoice 是一款支持一至四名说话人的零样本文本转语音模型。该模型通过整合 25 Hz 的 VAE、带有停顿感知符号与拼音替换的原始文本条件输入,以及支持说话人轮次输入的流匹配 DiT 架构,来生成表现力丰富的长篇幅独白与对话。同时,采用从独白到对话数据的分阶段训练流程,并结合基于音素级与说话人相似度奖励的 DiffusionNFT 后训练策略,在保持声学一致性的同时实现了可控的说话人切换。
核心贡献
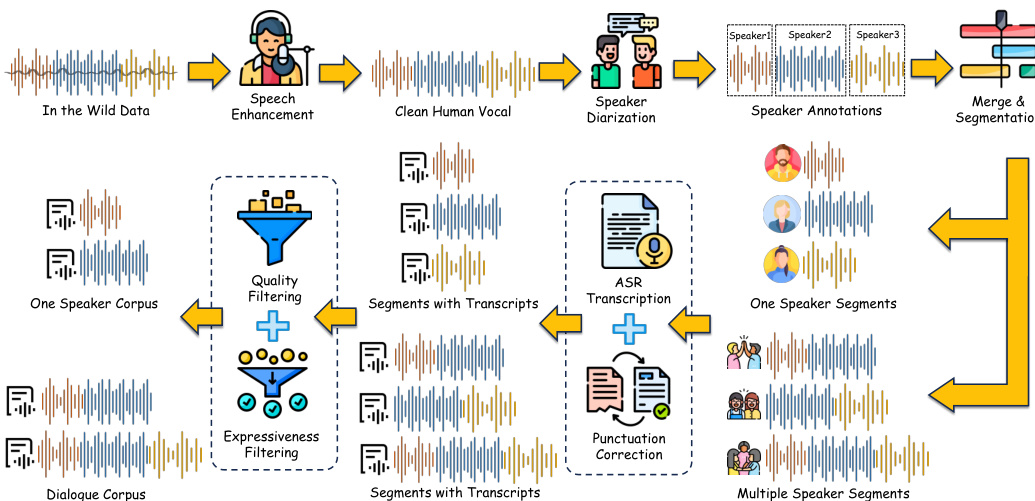
- SwanData-Speech 利用 Swan Forced Aligner 对自然音频进行停顿感知的词级对齐,并使用 RobustMegaTTS3 处理发音困难案例,从而构建独白与对话语料库。该数据集提供了训练对话系统所需的结构化时间标注,使系统能够在长轮次对话中保持连贯性。
- SwanVoice 是一款支持一至四名说话人的零样本文本转语音模型,融合了 25 Hz VAE、带有停顿感知符号与拼音替换的原始文本条件输入,以及支持说话人轮次条件的流匹配 DiT 架构。该模型经历了从独白数据到真实对话数据的渐进式训练,并采用基于音素级与说话人相似度奖励进行优化的 DiffusionNFT 后训练。
- Swan Forced Aligner 摒弃了传统的帧分类方法,采用显式的词与空白状态交错拓扑结构,在解码过程中强制执行单调结构约束。该架构降低了计算开销,支持低延迟的 Viterbi 解码,并为长篇幅结构化音频提供可靠的时间边界。
引言
现代零样本文本转语音系统在单人叙述方面表现优异,但生成表现力丰富的长篇幅多说话人对话对于播客、互动媒体和广播剧等应用仍然至关重要。以往的方法通常单独合成各个话轮并进行拼接,这会引入声学不一致性,破坏情感连贯性,并增加推理延迟。自回归设计因顺序解码延迟进一步加剧了这些问题,而现有的对话模型常因 ASR 标点符号对齐不准而难以精确控制停顿,且在微调过程中经常牺牲独白质量。为解决这些不足,作者提出了 SwanData-Speech,这是一种数据整理流程,利用轻量级且具备停顿感知能力的强制对齐器从真实音频中提取高质量的独白与对话子集。基于该数据集,作者推出了 SwanVoice,这是一款支持最多四名说话人的零样本模型,融合了 25 Hz VAE、带有显式停顿标记的原始文本条件输入以及流匹配 DiT 架构。该模型采用分阶段训练课程与基于奖励的后训练策略,在保持独白保真度的同时,提供连贯且可控的多说话人对话生成。
数据集
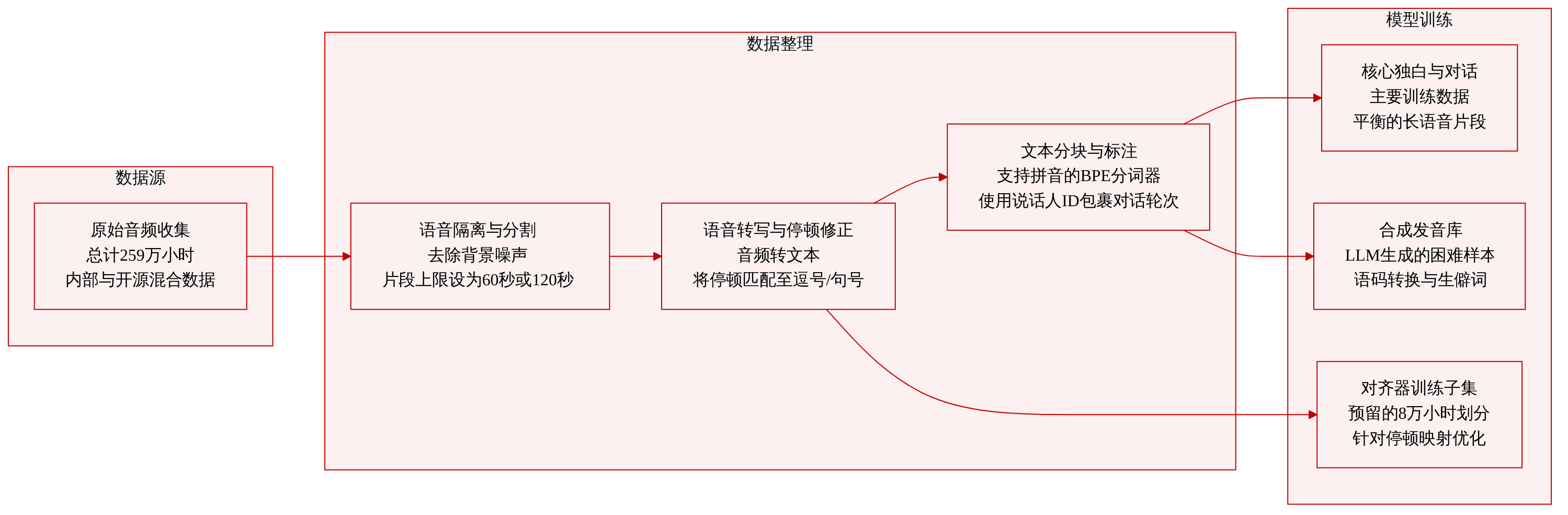
-
数据集构成与来源: 作者收集了约 259 万小时的原始音频语料,主要来源于字节跳动内部仓库,并辅以精心整理的开源中英文数据集。总计包含约 224 万小时中文语音与 35 万小时英文语音。
-
子集划分与过滤: 原始数据被划分为用于模型训练的独白池与对话池,并单独划分出 8 万小时的子集用于训练和评估 Swan Forced Aligner。为解决发音边缘案例,作者生成了一个名为 RobustMegaTTS3 的合成子集,该子集结合了字典派生条目、2 万例中文困难案例、2 万例英文困难案例,以及覆盖 13 种对话场景的 10 万例中英混合语音样本。
-
处理与裁剪策略: 原始录音通过 3D-Speaker 工具包进行人声隔离与说话人日志分析。团队采用滑动窗口贪婪合并策略处理长录音,将独白片段上限设为 60 秒,对话片段上限设为 120 秒。对话合并需包含两至四名说话人,且静音间隔需低于两秒,短于 0.1 秒的片段将作为噪声丢弃。随后,强制对齐器通过将声学停顿映射到特定 tokens 来修正标点符号,所有音频在最终重采样至 24 kHz 之前均保留原始采样率。
-
模型使用与元数据构建: 作者将原始文本直接输入基于 BPE 的 CosyVoice tokenizer,该 tokenizer 针对中文采用一对一字符编码以降低稀疏性,并省去独立的图音转换预处理步骤。文本流中集成了专用的停顿 token,词表扩充了 1,549 个拼音音节。训练期间,中文字符会被随机替换为拼音以提升发音鲁棒性。说话人身份通过在每个话轮前后包裹
<S{id}>与</S{id}>标签进行追踪,这些标签随后被转换为与 token 流对齐的并行说话人标签序列。独白与对话池构成核心训练数据,而合成子集则为罕见与模糊案例注入字典级发音知识。
方法
SwanVoice 的整体框架包含用于语音表示的变分自编码器(VAE)与用于文本转语音合成的流式 Transformer,并采用课程学习策略以确保训练稳定性,同时设置后训练阶段用于误差修正。训练与推理流程详见框架图。
如下方所示,VAE 模块是语音表示的基础组件。给定输入语音波形 s,变分编码器 E 将 s 映射为潜在表示 z,随后由波形解码器 D 进行解码,以 s^=D(z)=D(E(s)) 的形式重建信号。为降低计算成本并促进语音与文本的对齐,编码器在时间维度上以 d 的因子对输入波形进行下采样。编码器架构遵循 Ji 等人的设计,解码器则基于 HiFi-GAN 构建。为提升感知保真度并捕捉高频细节,模型使用多种对抗判别器进行训练,包括多周期判别器(MPD)、多尺度判别器(MSD)与多分辨率判别器(MRD)。整体训练目标结合了谱域重建损失 Lrec、轻量级 KL 正则项 LKL 以及 LSGAN 风格的对抗损失 LAdv,最终损失函数为 L=Lrec+LKL+LAdv。压缩率为每秒 25 个潜在帧。
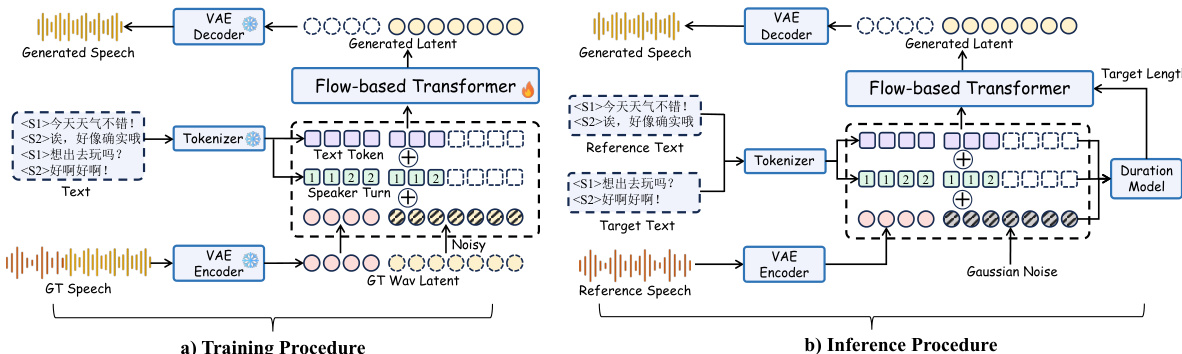
合成模型为一种基于流的 Transformer,根据参考语音片段与目标文本序列生成语音。训练过程中,模型以参考语音波形和目标文本为输入,通过 VAE 编码器对参考语音进行编码以获取潜在表示。目标文本经过分词后,模型利用时长模型估计目标长度。随后,基于流的 Transformer 结合文本与参考语音条件生成潜在表示,并通过 VAE 解码器将其还原为波形。训练过程旨在优化模型,以最小化生成语音与真实语音之间的差异,VAE 的编码器与解码器构成生成过程的核心骨干。如下方所示,推理过程遵循相似结构,但利用参考语音片段与目标文本合成语音,以保留参考语音的说话人身份与发音风格。模型首先将参考语音转录为特定说话人的文本,通过发音速率启发式方法估计目标时长,并在生成早期阶段采用 sway sampling 捕捉粗略的语音轮廓。语音与文本的对齐主要由初始去噪步骤决定,VAE 解码器随后将目标潜在表示转换为波形。
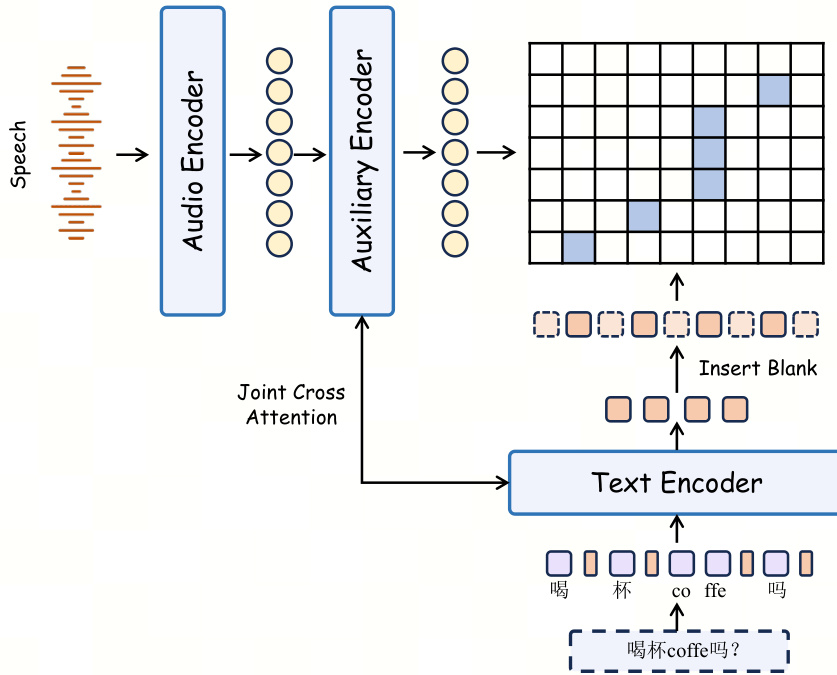
为解决从复杂对话数据中学习语音与文本对齐的挑战,作者采用三阶段课程学习策略。第一阶段为独白预训练,模型从零开始在独白语音数据上进行训练,建立基础合成能力与可靠的语音文本对齐。该阶段辅以发音困难案例与代码切换合成样本。第二阶段为混合对话训练,在独白数据与拼接的 2 至 4 人对话数据混合集上训练预训练模型,为学习说话人转换提供中间过渡。第三阶段为监督微调(SFT),在独白数据与真实 2 至 4 人对话数据混合集上训练模型,使模型能够学习更高层级的对话连贯性。监督训练完成后,进入后训练阶段,利用在线强化学习针对发音与音色奖励对模型生成的样本进行优化。该阶段采用无价值函数的优化策略,即 DiffusionNFT,通过流匹配目标对前向过程执行策略优化。奖励机制聚焦于音素级一致性与说话人相似度,框架支持根据部署优先级对多种奖励进行加权求和。
实验
实验使用既定基准与基于大语言模型的评估器,从声学保真度、语义准确性与表现力质量三个维度对长篇幅文本转语音及强制对齐系统进行评估。SwanVoice 通过将长篇幅语音视为连续上下文而非孤立话轮,在独白与对话生成中展现出卓越的表现力丰富度与结构连贯性,同时保持具有竞争力的声学及语义性能。尽管取得上述进展,该模型在内容准确性与多说话人切换方面仍存在局限,表明需要更稳健的对齐与发音控制机制。作为合成框架的补充,专用的强制对齐器在时间戳预测准确率方面达到开源模型领先水平,有效支撑了高质量长篇幅音频生成的整体流程。
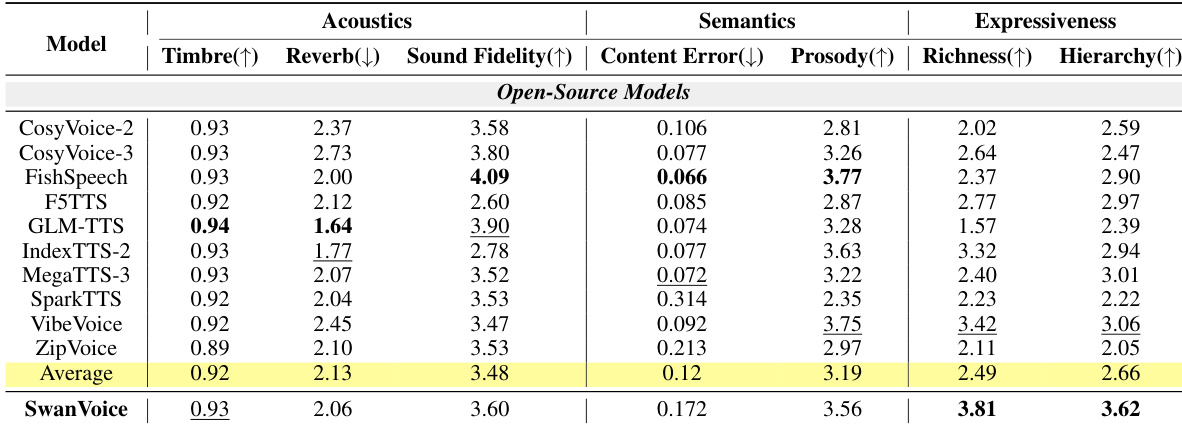
{"summary": "作者从声学、语义与表现力指标评估长篇幅 TTS 模型,SwanVoice 在大多数类别中取得领先或接近领先的成绩。结果显示,SwanVoice 在表现力指标上优于开源基线模型,尤其在丰富度与层级感方面表现突出,同时在声学及语义方面保持竞争力。", "highlights": ["相较于所有开源模型,SwanVoice 在丰富度与层级感方面取得最高的表现力得分。", "SwanVoice 在声学指标上表现具有竞争力,具备出色的声音保真度与音色一致性。", "SwanVoice 保持了较高的韵律连贯性,且内容错误率接近开源模型平均水平。"]
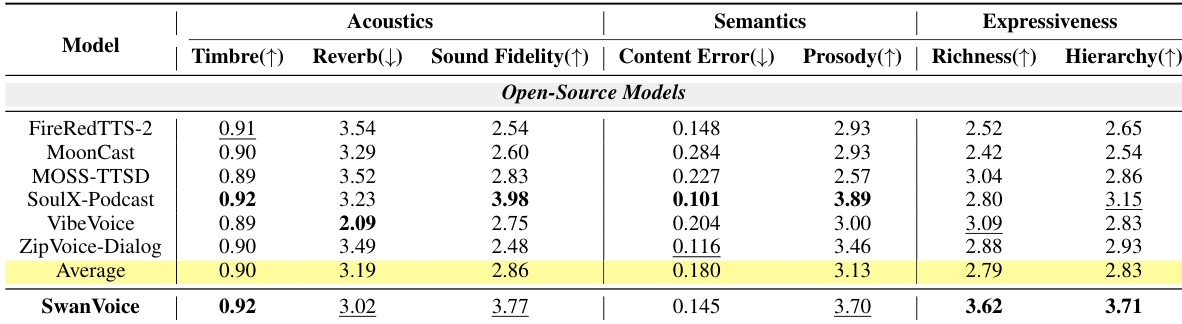
作者从声学、语义与表现力指标对长篇幅 TTS 模型进行评估,结果表明 SwanVoice 在表现力相关指标上相较于开源基线模型取得最高分。尽管并非在所有类别中均居首位,但其在声学及语义方面表现具有竞争力,尤其在表现力丰富度与层级感上表现突出。结合零样本独白与对话生成的背景分析模型性能,SwanVoice 在表现力方面优于其他开源模型,同时在其他维度保持合理分数。相较于所有被评估的开源模型,SwanVoice 在丰富度与层级感方面均取得最高表现力得分。在声学及语义方面,SwanVoice 维持竞争力表现,具备出色的音色一致性与韵律连贯性。相较于最强基线模型,该模型在表现力指标上取得显著提升,尤其在长篇幅语音生成方面。
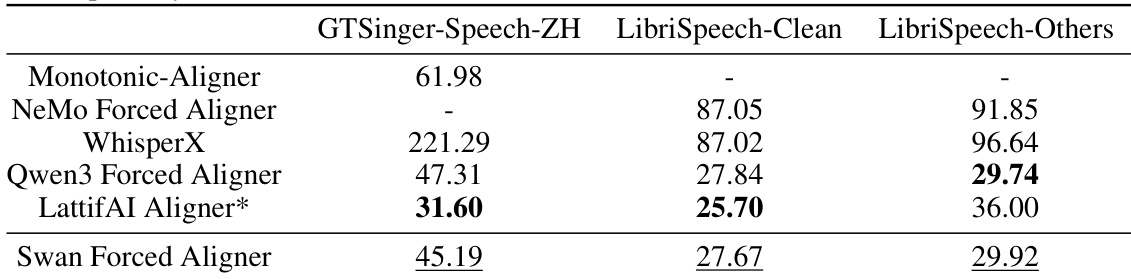
作者在两个测试数据集上将 Swan Forced Aligner 与多种基线强制对齐器进行性能对比,结果显示该模型在中英文基准测试中均取得开源模型最佳成绩。模型展现出强大的对齐精度,尤其在中文数据集上表现优异,在英文基准测试中与专有系统竞争相当。Swan Forced Aligner 在中文基准测试中达到开源性能最优。在英文数据集上,该模型表现具有竞争力,结果接近最佳专有系统。在中文与英文测试集上,该模型的对齐精度相较于其他开源对齐器均有显著提升。
评估设置将 SwanVoice 与 Swan Forced Aligner 与现有开源及专有基线模型进行对比,以验证其在长篇幅语音合成与精确音素对齐方面的有效性。SwanVoice 在独白与对话生成中提供卓越的表现力质量,在保持强大声学保真度与语义准确性的同时,在韵律丰富度与层级感方面显著超越其他开源模型。与此同时,该强制对齐器在中文数据集上达到最高开源对齐精度,在英文基准测试中与商业系统保持高度竞争力。总体而言,这些实验表明两款模型在各自领域均展现出稳健的定性性能。