Command Palette
Search for a command to run...
框架更新并非框架增益:解耦自进化大语言模型智能体中的进化能力
框架更新并非框架增益:解耦自进化大语言模型智能体中的进化能力
摘要
大型语言模型(LLM)智能体正越来越多地以围绕可编辑外部框架(harnesses)构建的系统形式部署,这些框架包括提示(prompts)、技能(skills)、记忆(memories)和工具(tools),它们在无需更改模型参数的情况下塑造任务执行过程。框架自进化(Harness self-evolution)通过利用执行证据更新这些框架,从而实现对此类智能体的自适应优化。然而,模型在任务解决方面的基础能力是否预示其进行框架自进化的能力——即哪些模型能产生有效的框架更新,以及哪些模型真正从中受益——这一问题尚不明确。我们分析了两种框架自进化能力:(i) 框架更新能力(harness-updating),即从执行证据中生成有用的持久性框架更新的能力;(ii) 框架受益能力(harness-benefit),即在任务解决过程中从更新后的框架中获益的能力。我们的分析揭示了两个主要发现。首先,框架更新能力在基础能力上呈现平坦分布:不同能力层级的模型所产生的框架更新带来的提升惊人地相似;即便是 Qwen3.5-9B 产生的更新,其效果也与 Claude Opus 4.6 相当。其次,框架受益能力与基础能力呈非单调关系:弱能力层级的模型从更新框架中获益较少,中等能力层级的模型获益最多,而强能力层级的模型获益则少于中等能力层级。我们将弱能力层级收益较低的现象归因于两种失败模式:弱能力层级的模型可能无法激活相关的框架组件,或者虽然激活了这些组件,却未能忠实地遵循其指示。这些发现表明,在能力预算分配上,应更侧重于投资任务解决智能体本身,而非进化机制(evolver);同时,在智能体训练中应重点关注框架调用(harness invocation)和长程指令遵循(long-horizon instruction following)。我们的源代码已在公开渠道提供,访问地址如下。
一句话总结
本分析将 harness-updating 与 harness-benefit 在自进化 LLM agent 中解耦,以揭示 harness-updating 在不同层级间产生相似的增益,其中 Qwen3.5-9B 的更新产生的增益与 Claude Opus 4.6 相当,而 harness-benefit 呈非单调性,中层模型受益最多,表明能力预算应优先投向 task-solving agent 而非 evolvers。
核心贡献
- 该工作引入了一个受控的能力分析框架,将 harness-updating 与 harness-benefit 分离,以分别测量这些能力。该方法独立地改变 agent 和 evolvers,以隔离特定能力,而不是混淆端到端增益。
- 实验表明,harness-updating 能力在不同基础模型层级间保持平稳,无论底层模型大小如何,产生的增益相似。结果显示,来自较小模型如 Qwen3.5-9B 的更新产生的性能改进与来自更强模型如 Claude Opus 4.6 的改进相当。
- 分析揭示 harness-benefit 能力遵循非单调模式,其中中层模型受益最多,而弱层模型无法激活或忠实遵循 harness artifacts。这些发现表明应优先关注 task-solving agent 而非 evolver,并在 agent 训练中针对 harness 调用和长视野指令遵循。
引言
大型语言模型 agent 越来越多地依赖可编辑的外部 harness,如 prompts、tools 和 memory,以在不更新模型权重的情况下塑造行为。虽然 harness 自进化允许这些系统通过根据执行证据完善 artifacts 来适应,但先前的评估通常将 agent 的基础性能与更新的质量以及 agent 利用它们的能力混淆。作者通过区分 harness-updating(产生有用 artifacts 的能力)和 harness-benefit(在任务解决期间利用它们的能力)来解耦这些因素。他们的分析揭示更新能力在不同模型层级间保持一致,而受益能力在中间层级达到峰值,表明开发者应优先投资于 task-solving agent 而非 evolver。
数据集
- 数据集构成: 该研究在三个基准上进行评估:用于软件工程的 SWE-bench Verified、用于真实服务器工具使用的 MCP-Atlas,以及用于基于技能执行的 SkillsBench。
- 子集详情: SWE-bench Verified 包含来自 12 个 Python 仓库的 500 个人工验证任务,其中补丁必须通过隐藏测试。MCP-Atlas 包含 500 个任务,需要在 36 个服务器上进行编排,使用基于声明的评分标准。SkillsBench 提供跨 11 个领域的 86 个任务,具有确定性验证器。
- 评估协议: 团队采用原位设置,其中任务在证据更新当前 harness 之前根据之前的 harness 进行评分。通过率是任务流上聚合的主要指标。
- 处理与约束: harness 编辑是特定于基准的。SWE-bench 和 SkillsBench 限制编辑仅限于技能目录,而 MCP-Atlas 允许更改 prompts 和 memory 文件。所有模型使用固定的 prompt 模板和进化预算以保持一致性比较。
方法
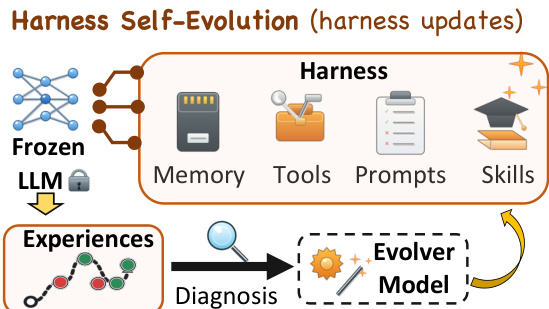
该研究利用一种 harness 自进化协议,旨在通过在任务执行期间更新围绕固定模型的外部 harness 来适应 LLM agent。在此框架中,agent 尝试一系列任务,并且 harness 根据 agent 的执行证据迭代更新。这种方法区分了参数化模型主干和非参数化上下文,允许在不重新训练底层 LLM 的情况下持续改进。
请参阅框架图以可视化整体架构。系统由连接到包含 Memory、Tools、Prompts 和 Skills 的动态 Harness 的 Frozen LLM 组成。该过程作为一个闭环运行:收集执行经验并进行诊断,进而输入到 Evolver Model。Evolver Model 随后生成更新以修改 Harness 组件,例如注入新技能或完善 prompts,以更好地处理未来任务。
形式上,在进化步骤 t,agent 定义为 At=(f,Ht),其中 f 代表固定模型主干,Ht 表示 harness 状态。系统遵循 f 保持恒定而 Ht 的可编辑组件(例如 prompts、skills、memories)更新的协议。evolver e 作为更新过程,将执行证据转换为 harness 修改。给定之前的 harness Ht−1 和累积的执行证据 Dt,evolver 提出更新 ΔHt 并应用它以获得下一个 harness 状态:
ΔHt=e(Ht−1,Dt),Ht=Apply(Ht−1,ΔHt).进化协议遵循 T 步的迭代循环。在每一步,agent At−1 尝试解决一批任务 Xt,输出执行轨迹 τt,x 和最终输出 yt,x。证据 Dt 从这些交互中收集,evolver 为后续步骤生成更新的 harness Ht。
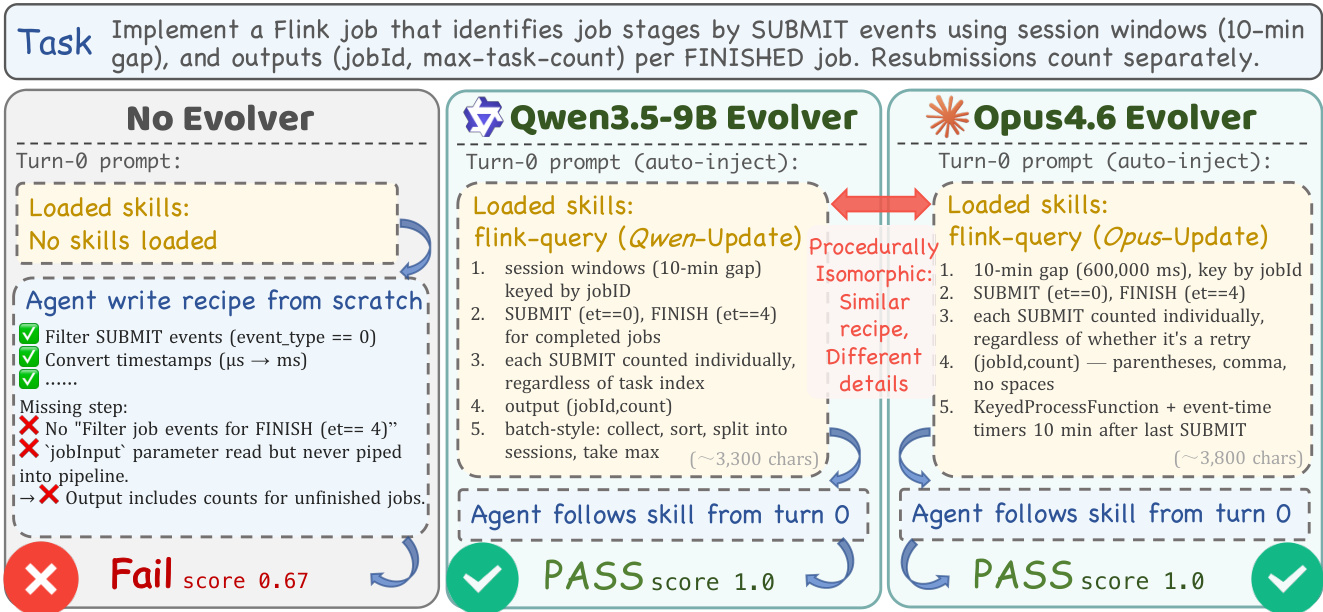
如下图所示,该方法的实际应用涉及 evolver 诊断失败并将特定过程技能注入 harness。比较说明了没有 evolver 的 agent 由于缺少步骤而无法完成 Flink 作业任务的场景。相比之下,利用 Qwen3.5-9B 或 Opus4.6 Evolver 的 agent 成功通过了任务。这一成功归因于 evolver 自动将 flink-query 技能注入加载的技能列表。该图强调,虽然不同的 evolver 模型可能产生具有相似逻辑的过程同构配方,但注入技能的具体细节和措辞不同,但两者都导致了 base agent 本会失败的成功结果。
实验
本研究通过解耦 harness-updating(模型根据执行证据生成改进)和 harness-benefit(模型在任务解决期间利用这些更新),评估了七个 LLM 和三个 agentic benchmarks 上的 harness 自进化。实验揭示 harness-updating 能力与基础模型强度无关,而 harness-benefit 遵循非单调模式,其中中层模型获益最多,而较弱模型由于无法激活 artifacts 或遵循指导而挣扎。这些发现表明系统设计应优先将能力投资于 task-solving agent,并训练其可靠地调用和遵循外部 harness 指令。
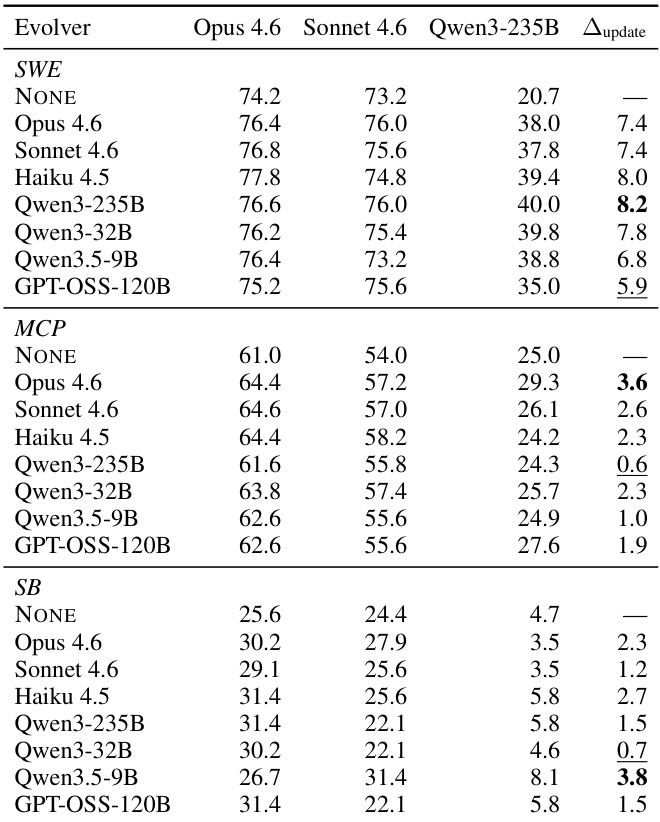
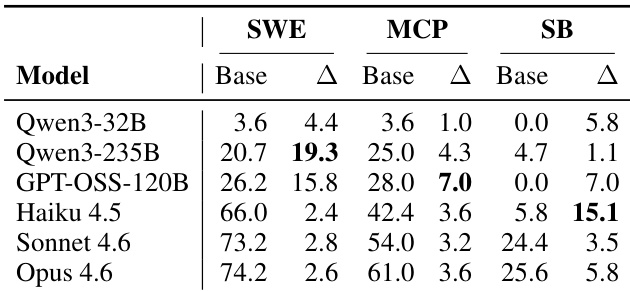
作者通过在不同基准上将各种 evolver 模型与固定的 task-solving agent 配对来评估 harness-updating 能力。结果表明,生成有用 harness 更新的能力在不同模型层级间相对一致,没有单个 evolver 主导所有任务。此外,最终系统性能更多由 task-solving agent 的基础能力驱动,而非使用的特定 evolver 模型。harness-updating 增益在 evolver 能力层级间保持稳定,表明较小模型可以产生与较大模型相当的更新。没有 evolver 模型在所有基准上始终优于其他模型,表明有效性取决于任务领域而重新洗牌。task-solving agent 的基础能力是进化后性能的主导因素,而 evolver 身份贡献的方差较少。
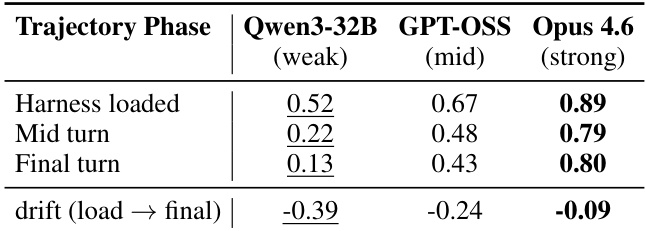
作者分析每阶段遵循分数以诊断为什么弱层模型从 harness 更新中获得的收益较低。结果表明,虽然强模型在整个任务执行期间保持稳定的遵循,但较弱模型随着轨迹展开遭受显著漂移。这表明存在长视野指令遵循瓶颈,其中较弱模型的遵循衰减比其强对应模型陡峭得多。强模型在所有轨迹阶段保持最高的遵循分数。弱模型在从加载到最后一步的遵循中表现出最大的负向漂移。中层模型表现出中等程度的遵循衰减,介于弱模型和强模型性能之间。
作者通过测量不同能力模型的激活、遵循和成功率来分析 harness 自进化中的 agent 端能力。数据显示,较弱模型同时遭受低技能加载率和差的对加载指令的遵循,而较强模型始终激活并遵循 harness artifacts。值得注意的是,中等能力模型显示出高激活率,但在遵循方面挣扎,表明加载技能并不保证有效利用。弱层模型表现出明显低于强层模型的技能加载率,在大多数轨迹中无法激活 harness artifacts。强层模型表现出对加载技能的优越遵循,保持高遵循率,而较弱模型经常偏离指令。中层模型的激活和遵循之间存在差异,其中高技能加载率不一定转化为高指令遵循性能。
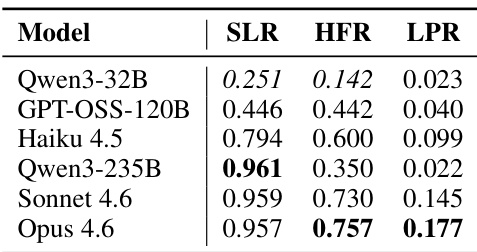
作者分析七个 LLM 和三个基准上的 harness-benefit 能力,以确定哪些模型从更新的 agent harness 中受益最多。结果表明,harness 进化带来的改进相对于基础模型能力是非单调的,其中中层模型显示出最大增益,而较弱和较强模型受益较少。这种模式表明弱模型难以激活或遵循 harness 指令,而强模型由于性能上限面临收益递减。与较弱或较强的对应模型相比,中层模型从 harness 进化中显示出最高的改进。强模型在接近基准性能上限时经历有限的增益。弱模型由于难以激活和遵循过程指导而无法有效利用 harness 更新。
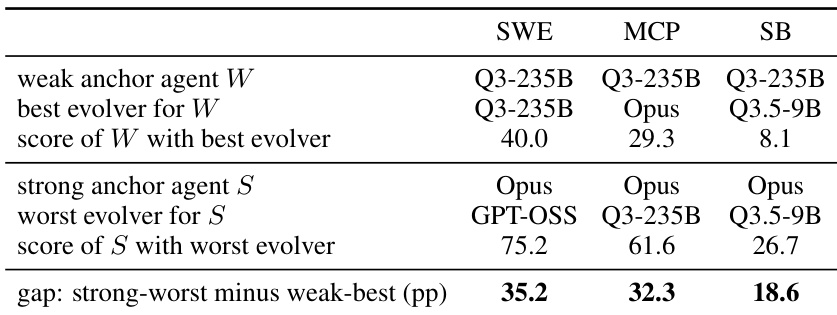
作者分析极端配对,其中最强的 task-solving agent 使用其最差的 evolver,最弱的 agent 使用其最好的 evolver。结果表明,强 agent 在所有基准上始终显著优于弱 agent,证明 agent 的基础能力是进化后性能的主要决定因素。即使与效果最差的 evolver 配对,强 agent 仍保持对弱 agent 的实质性性能领先。性能差距在所有测试基准上有利于强 agent,突显了 agent 能力对 evolver 质量的优势。结果表明,优化 task-solving agent 比优化负责生成 harness 更新的模型产生更大的回报。
作者通过将各种 evolver 模型与多个基准上的固定 task-solving agent 配对来评估 harness-updating 能力。研究发现,task-solving agent 的基础能力是性能的主要决定因素,超过了使用的特定 evolver 模型。虽然中层模型从 harness 进化中受益最多,但较弱模型在指令遵循方面挣扎,而较强模型面临收益递减,表明优化 agent 比优化 evolver 产生更大的回报。