Command Palette
Search for a command to run...
VLM3:视觉语言模型是原生3D学习者
VLM3:视觉语言模型是原生3D学习者
Zhipeng Cai Zhuang Liu Yunyang Xiong Zechun Liu Vikas Chandra Yangyang Shi
摘要
视觉语言模型(VLMs)通过提示(prompting)使单一模型能够解决多种视觉任务,并在语义理解方面展现出极具前景的性能。然而,3D 理解目前仍很大程度上依赖于具有复杂任务特定设计的专家级视觉模型。本研究的核心观点是:VLMs 是原生的 3D 学习者。我们深入的大规模研究表明,实现高效 3D 学习只需满足三个条件:1) 焦距统一(focal length unification),2) 基于文本的像素参考(text-based pixel reference),以及 3) 数据混合与缩放(data mixture and scaling)。事实上,许多构成专家级视觉模型基础的条件——如模型架构变更、大规模模型、复杂的数据增强以及包含回归公式在内的复杂损失函数等——并非必要条件。基于此,我们提出了 VLM^3,这是一种设计极简且可扩展的方法,使标准 VLMs 能够掌握多样化的 3D 任务。VLM^3 不仅大幅提升了 VLM 的深度估计精度(从 0.84 提升至 0.9),还支持像素级对应(pixel correspondence)、相机位姿估计(camera pose estimation)以及对象级 3D 理解等多种 3D 任务,在保持标准架构和基于文本的训练方式的同时,其精度可与专家级视觉模型相媲美。我们相信,VLM^3 为简单且可扩展的 3D 学习开辟了一条新的范式。
一句话总结
作者提出了 VLM3,这是一种可扩展的方法,证明了视觉语言模型通过焦距统一、基于文本的像素引用以及数据混合与扩展,是原生的 3D 学习者。该方法将深度估计精度从 0.84 提升至 0.9,并实现了像素对应、相机姿态估计和物体级 3D 理解,同时使用标准架构和基于文本的训练达到了专家视觉模型的精度。
核心贡献
- 一项大规模研究确立了焦距统一、基于文本的像素引用和数据混合扩展足以实现有效的 3D 学习。这一发现挑战了专家视觉模型基础的必要性,例如架构变更、重度数据增强和复杂的回归损失。
- 提出的 VLM^3 使标准 VLM 架构能够通过焦距调整至 1000 像素以及 [0, 2000) 范围内的归一化基于文本的像素引用来处理多样的 3D 任务。这种方法通过依赖标准的基于文本的训练程序,避免了额外的编码器或特定任务模块。
- 实验结果表明,该方法将 VLM 深度估计精度从 0.84 提升至 0.9,同时在像素对应和相机姿态估计等任务上匹配专家视觉模型的性能。物体级 3D 理解也在无需复杂特定任务设计的情况下与这些能力一同实现。
引言
从 2D 输入理解 3D 几何是视觉智能的核心,但与传统专用专家模型相比,视觉语言模型(VLMs)在细粒度任务上表现历来不佳。先前的研究要么专注于粗略的物体级理解,要么依赖复杂的特定任务架构和损失,从而损害了标准 VLM 的兼容性。作者证明了 VLM 本质上具备 3D 学习能力,并提出 VLM3 以在不修改模型结构的情况下释放这一潜力。它们利用焦距统一、基于文本的像素引用和数据扩展,使标准 VLM 能够在包括深度估计和相机姿态在内的多样任务上匹配专家精度。这种方法消除了对重度数据增强或回归损失的需求,同时保持了可扩展的设计。
方法
作者提出了 VLM3,这是一个可扩展的框架,旨在使标准视觉 - 语言模型(VLMs)掌握多样的 3D 理解任务,而无需复杂的架构修改。核心理念依赖于通过预处理和提示工程解决 3D 数据中的基本歧义,而不是设计特定任务的头或损失。
该方法的一个主要组成部分是焦距统一。为了解决 3D 视觉中常见的相机歧义问题,框架调整输入图像的大小,使其焦距标准化为 1000 像素。此预处理步骤允许在不同来源之间进行有效的混合数据训练。与之前需要渲染视觉标记来引用特定像素的方法不同,VLM3 采用基于文本的引用策略。通过将像素空间归一化到水平和垂直轴的 [0,2000) 范围,模型可以通过自然语言提示理解和生成精确的像素坐标。如下面的架构比较所示,VLM3 (c) 避免了先前物体级方法 (a) 和 DepthLM (b) 中发现的额外模块或渲染标记。

这种基于文本的方法显著提高了效率和可扩展性。它允许在训练期间为同一图像打包多个问题而无需复制输入,使模型能够从每个样本的 10 个标记像素中学习,而不仅仅是 1 个,且开销可忽略不计。此外,该框架利用数据混合和扩展作为关键要素。作者发现,简单地根据数据集大小进行适当加权的训练数据扩展通常比复杂的数据增强或架构调整更有效。
该框架在四个不同的 3D 任务中得到演示:物体级 3D 理解、度量深度估计、像素对应估计和相机姿态估计。参考下面的任务性能细分,它突出了 VLM3 如何在这些领域与专家视觉模型实现具有竞争力的精度。
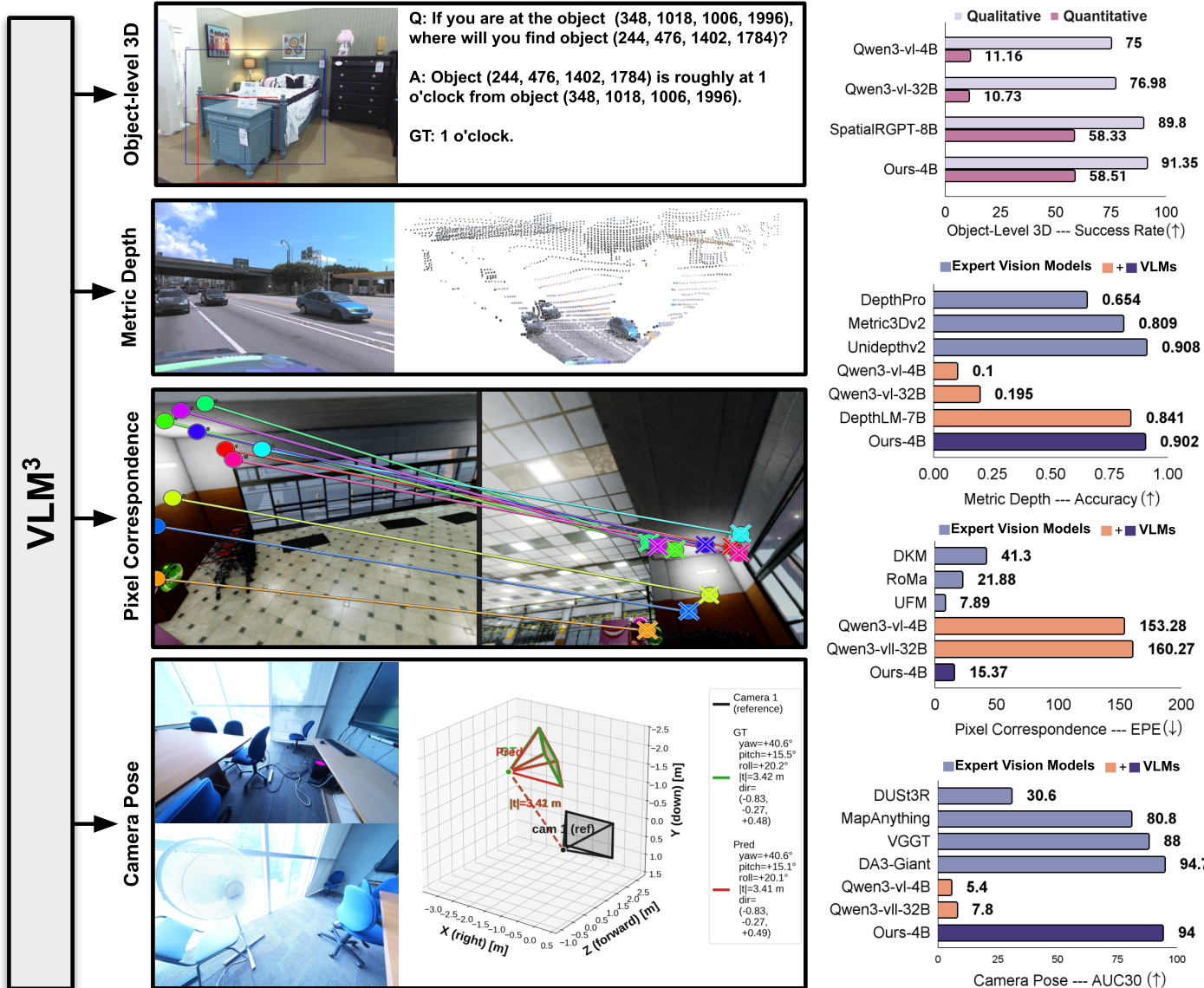
在实现方面,作者利用 Qwen3-vl-4B 作为基础 VLM 并应用标准的基于文本的有监督微调(SFT)。在相机内参不可用的情况下,使用预训练的单图像校准模型在统一之前进行估计。这种极简设计证明,当提供正确的数据预处理和引用策略时,标准 VLM 可以作为原生的 3D 学习者运行。
实验
该研究验证了 VLM3 在四个不同的 3D 理解任务中的通用性,范围从单视图度量深度估计到多视图相机姿态估计。实验表明,该模型在视觉语言模型中实现了最先进的性能,并使用简化的基于文本的提示范式匹配专家视觉系统,无需专用编码器。进一步的分析证实,基于文本的像素引用表现与视觉提示相当,同时强调仔细的数据混合加权比增加模型大小对扩展更具影响力。
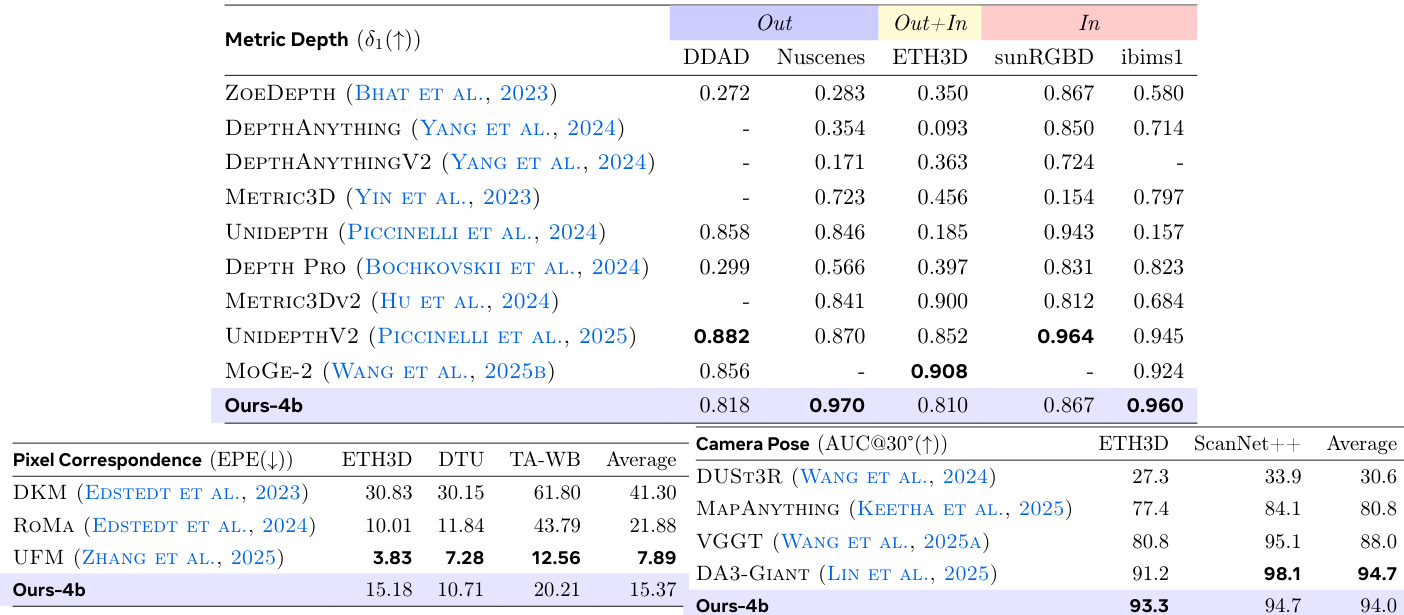
作者在他们提出的模型 VLM3 上评估了三个不同的 3D 理解任务,包括度量深度估计、像素对应和相机姿态估计。结果表明,这个紧凑的 4B 参数模型在各种数据集上实现了与专用专家视觉模型相当的性能,通常在不要求复杂架构变化的情况下匹配或超越先前的最先进方法。具体而言,该模型在深度估计和相机姿态估计方面实现了具有竞争力的精度,同时在像素对应方面显著优于基线 VLM。该模型在 NuScenes 和 iBims1 数据集上达到了顶级性能,与 UniDepthV2 等专用深度估计模型媲美。所提出的方法显著降低了与基线 VLM 相比的错误率,并在平均像素误差上优于专家模型 DKM 和 RoMa。该模型达到了与 SOTA DA3-Giant 方法几乎相同的平均精度,显著优于其他近期方法如 VGGT。
作者评估了像素引用方法、数据混合加权和模型大小如何影响 3D 理解能力。结果表明,基于文本的像素引用是视觉提示的可行替代方案,而专门的数据混合加权显著优于标准基线。此外,较小的 4B 模型优于较大的 32B 和 8B 模型,表明当前的数据规模可能更适合较小的架构。基于文本的像素引用实现了与视觉提示方法相当的精度。自定义数据混合加权产生了比均匀或基于数据集大小的加权更高的性能。较小的 4B 模型在相同数据量下实现了优于较大的 32B 和 8B 模型的精度。

作者展示了一个在四个不同的 3D 理解任务中实现最先进性能的模型,包括度量深度估计和物体级推理。结果表明,这种方法在单视图和多视图设置中显著优于通用 VLM 和专用专家模型。值得注意的是,该方法使用较小的模型大小且无需像额外编码器这样的复杂架构变化就实现了这些高精度水平。该模型在所有比较的 VLM 中获得了度量深度估计的最高平均精度。它在物体级 3D 理解的定性和定量评估中超越了专用基线。多视图任务中的性能显示出实质性提升,特别是在减少像素对应误差和提高相机姿态估计精度方面。
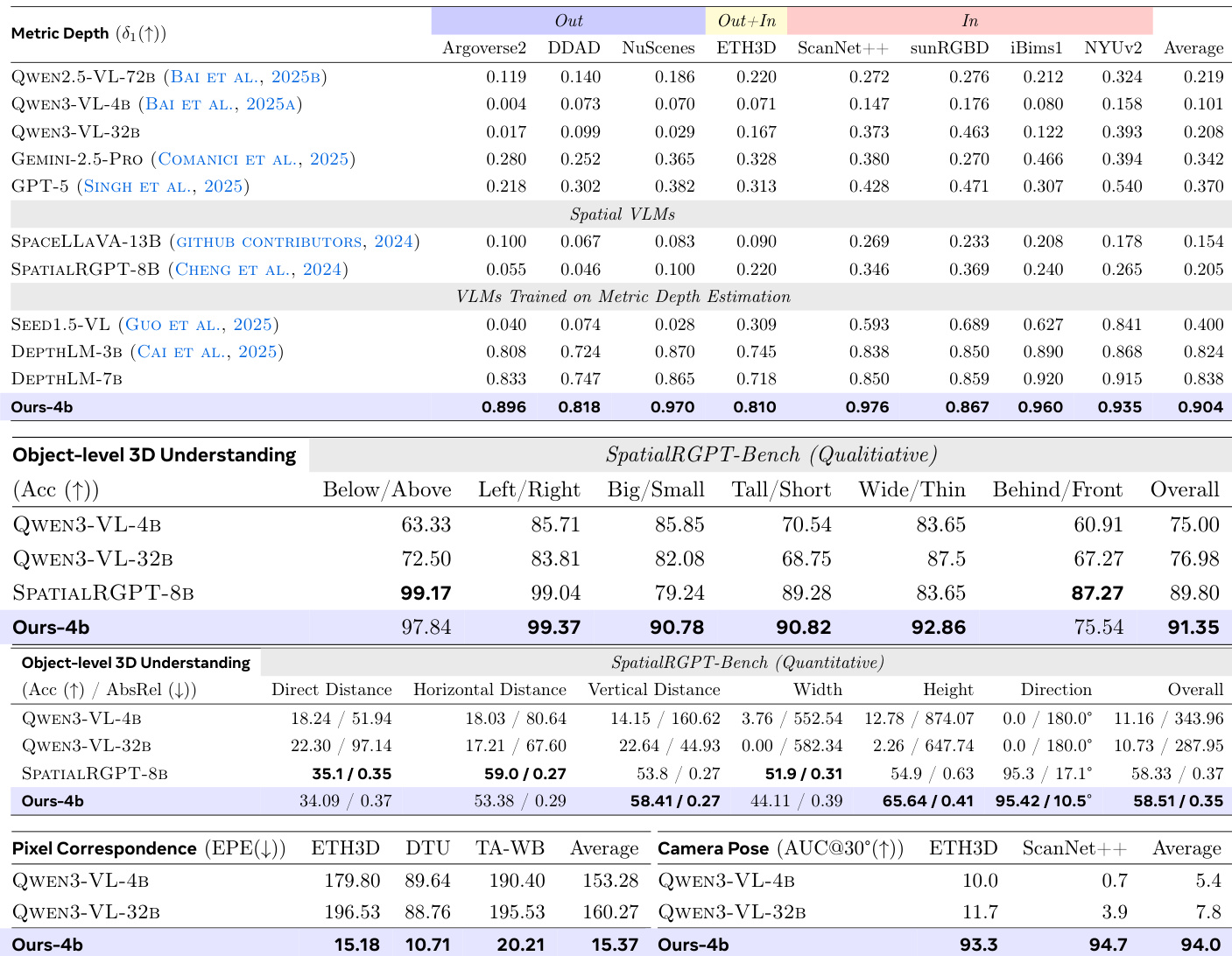
作者在一个紧凑模型上评估了多样的 3D 理解任务,包括度量深度估计、像素对应和相机姿态估计,证明了在不进行复杂架构变化的情况下实现了与专用专家模型相当的性能。消融研究表明,基于文本的像素引用是视觉提示的有效替代方案,而专门的数据混合加权显著增强了性能。值得注意的是,较小的模型配置优于较大的架构,从而在单视图和多视图设置中获得了顶级精度,超越了通用 VLM 和专用基线。