Command Palette
Search for a command to run...
VideoMLA:用于分钟级自回归视频扩散的低秩潜在KV缓存
VideoMLA:用于分钟级自回归视频扩散的低秩潜在KV缓存
Hidir Yesiltepe Jiazhen Hu Tuna Han Salih Meral Adil Kaan Akan Kaan Oktay Hoda Eldardiry Pinar Yanardag
摘要
长 rollout 因果视频扩散技术已收敛于固定大小的滑动窗口 KV 缓存,近期的研究进展主要在此布局框架内,通过调整占据窗口的 tokens 或改变其位置编码方式来实现创新。作为流式内存与延迟主要来源的逐头 KV 布局本身,在很大程度上仍未发生改变。本文首次对视频扩散中的多头潜在注意力(Multi-Head Latent Attention, MLA)进行了研究。VideoMLA 使用共享的低秩内容潜在表示与共享的解耦 3D-RoPE 位置键,替代了原有的逐头键与值,从而在每个缓存层将每个 token 的 KV 内存占用降低了 92.7%。我们进一步探讨了 MLA 在视频扩散中取得成功的原因,尽管其在语言模型中常被引用的谱假设在此并不成立:预训练的视频注意力并非低秩结构,其 99% 能量有效秩远高于任何实际的潜在维度。在直接谱近似方法会预测出较大重构误差的压缩比下,VideoMLA 仍能保持高质量输出。研究表明,决定有效秩的是 MLA 的瓶颈结构,而非预训练谱:无论是谱初始化还是随机初始化,在初始化阶段即占据了近乎全部的秩预算,且训练过程在适应调整的同时保留了该预算。在 VBench 基准测试中,VideoMLA 的性能与短视界流式视频扩散基线持平,在长视界评估中取得了所有对比方法中的最佳综合得分,并在单张 B200 上将吞吐量提升了 1.23 倍。
一句话总结
VideoMLA 将多头潜在注意力(Multi-Head Latent Attention)集成到自回归视频扩散模型中,通过用共享的低秩内容潜在表示和解耦的 3D-RoPE 位置键替换每个头的键值缓存,在每一个缓存层将每个 token 的 KV 内存占用降低 92.7%,同时在预训练注意力谱超过实际潜在维度的情况下仍保持生成质量。
核心贡献
- 本文提出 VideoMLA,首次将多头潜在注意力适配至长 rollout 因果视频扩散任务,该方法用共享的低秩内容潜在表示和解耦的 3D-RoPE 位置键替换了密集的逐头键值。
- 理论分析表明,MLA 瓶颈而非预训练注意力谱决定了有效秩,使模型能够在高压缩比下保持生成质量,即使预训练视频注意力已超出实际潜在维度。
- 实证评估显示,VideoMLA 在每一个缓存层将每个 token 的键值内存占用降低 92.7%,同时在直接谱近似法会预测出显著重建误差的压缩级别下仍保持生成保真度。
引言
自回归视频扩散模型将双向教师模型转化为流式学生模型,通过滚动键值缓存按顺序生成帧,从而实现高效的长跨度视频合成。先前方法通过优化缓存窗口或替换注意力机制来提升生成稳定性或减少计算量,但它们要么保留密集的逐头键值布局,要么跳过跨缓存层的 token 级压缩。本文作者利用多头潜在注意力来弥补这一差距,将架构适配至视频扩散任务,该任务的内存配置与注意力谱与语言模型存在显著差异。通过用共享的低秩潜在表示替换传统缓存,该方法在无需牺牲流式生成质量的前提下大幅降低了内存开销。
数据集
- 数据集构成与来源:提交的摘录中未提供数据集构成或来源信息。
- 各子集的关键细节:文本中未详细说明子集规模、来源或过滤标准。
- 论文的数据使用方式:作者未指定训练集划分、混合比例或数据如何融入模型。
- 处理细节:摘录省略了任何裁剪策略、元数据构建或其他预处理步骤。
方法
本文作者提出 VideoMLA,这是一种通过重新设计逐头 KV 布局来降低因果视频扩散模型中每个 token 键值(KV)缓存内存的新型方法。该框架用共享的低秩内容潜在表示和跨头解耦的 3D-RoPE 位置键替换了密集的逐头键值,显著降低了内存占用。设计的核心在于对注意力机制的两部分分解。每个视频潜在 token xt 首先通过联合下投影 W↓KV 压缩为共享内容潜在 ctKV∈Rdc,并写入压缩后的 KV 缓存。该潜在表示承载 token 的内容信息。位置信息被解耦并单独存储。对于每个头 h,逐头键 kt,hnope 和值 vt,h 通过头特定的上投影 W↑,hK 和 W↑,hV 从 ctKV 重构。这种共享潜在结构意味着单次缓存读取即可生成所有逐头键值,从而消除了为每个 token 存储密集逐头状态的需求。位置信息由独立的 RoPE 分支处理。通过 WRK 从 xt 计算得到单个跨头共享的位置键 ktR 并存储于缓存中。在注意力计算阶段,该未旋转的键经 3D-RoPE 旋转生成 ktrope,用于注意力分数计算。查询路径遵循类似结构,包含从 xt 派生的查询潜在 ctQ,以及从 ctQ 计算并旋转的头特定位置查询 qt,hR。头 h 的注意力分数结合了由 qt,hnope 与 kt,hnope 内积生成的基于内容的分数,以及由 qt,hrope 与 ktrope 生成的位置分数。该设计将每个 token 的缓存大小从 2nhdh 个标量缩减至 dc+dhrope。如下图所示,这带来了内存的显著降低与更高效的推理流程,因为缓存仅存储压缩的内容潜在与共享位置键,逐头组件仅在注意力计算需要时进行重构。

实验
评估工作结合了固定内存下的批次扩展测试与人类感知研究,以评估生成视频对提示词的遵循度、时间连贯性与运动一致性。消融实验验证了 VideoMLA 能够将缓存压缩有效转化为显著的推理余量,同时在潜在维度选择上确立了清晰的质量与效率权衡。研究结果表明,适度压缩能够保留关键视觉细节,且平衡缓存内容与位置编码通道可最优地支持流式视频生成。这些结果证实了该方法在实际部署中的潜力,未来工作将聚焦于更长的生成跨度与更高分辨率。
作者分析了不同注意力机制的内存与计算复杂度,表明 MLA Local 通过利用压缩潜在表示与分离式注意力设计,在内存与计算量上均优于因果全注意力与因果线性注意力变体。结果表明,该方法在保持效率与性能的同时,实现了两项指标的显著下降。MLA Local 相较于因果全注意力与因果线性注意力机制降低了内存与计算复杂度。该方法通过采用压缩潜在表示与分离式注意力设计实现更低的内存与计算开销。该设计通过优化资源分配,在维持性能的同时支持高效扩展。
作者开展消融实验以分析关键超参数对 VideoMLA 性能的影响,重点关注内存效率与质量之间的权衡。结果表明,降低 KV 缓存维度可显著提升内存可扩展性,同时保持可接受的生成质量,通过在缓存内容与位置编码之间平衡分配通道可实现最优性能。模型采用教师强制、一致性蒸馏与分布匹配蒸馏相结合的方式进行三阶段训练。降低 KV 缓存维度带来显著的内存节省,并支持在不超出内存限制的情况下使用更大的批次大小。缓存内容与位置编码之间的通道平衡分配能取得最佳性能,且专用的 RoPE 子空间提升了时间与空间连贯性。训练流水线包含多个阶段,包括教师强制、一致性蒸馏与分布匹配蒸馏,以优化模型以实现高效推理。

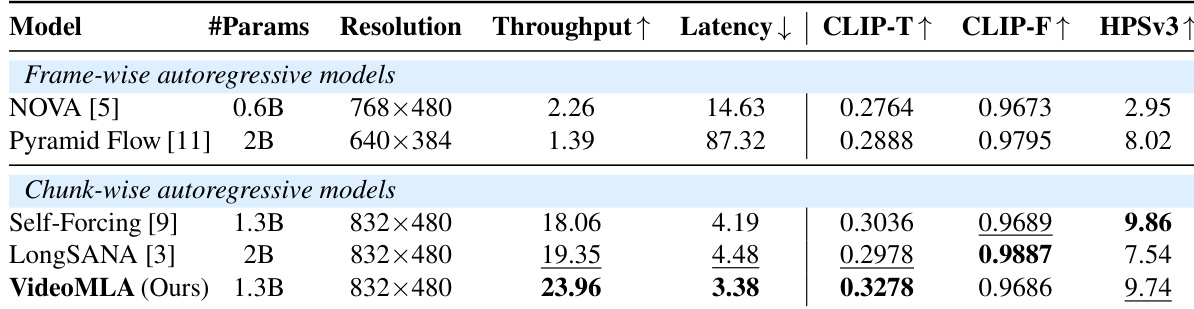
作者从参数量、分辨率、吞吐量、延迟以及 CLIP 与 HPSv3 指标表现等方面,将 VideoMLA 与其他自回归模型进行对比。结果表明,与逐帧模型相比,VideoMLA 实现了更高的吞吐量与更低的延迟,同时在质量指标上保持具有竞争力或更优的性能。VideoMLA 的吞吐量高于逐帧自回归模型,且延迟更低。在 CLIP-T 与 HPSv3 得分上,VideoMLA 优于其他分块自回归模型。VideoMLA 展现了效率与质量之间的良好平衡,在降低延迟的同时实现了具有竞争力的性能。
作者通过消融实验评估潜在维度与位置编码配置对模型性能的影响。结果表明,增加潜在维度可提升质量但会降低内存效率,而位置通道与内容通道之间的平衡显著影响语义保真度与时间连贯性。最优配置在内存节省与视频质量之间取得了平衡。提高潜在维度虽能改善质量,但会牺牲内存效率,且在较高数值下收益递减。位置通道与内容通道的划分影响语义保真度与时间连贯性,最优平衡点倾向于内容通道。最佳性能配置通过同时优化潜在维度与通道划分,实现了内存节省与视频质量之间的平衡。

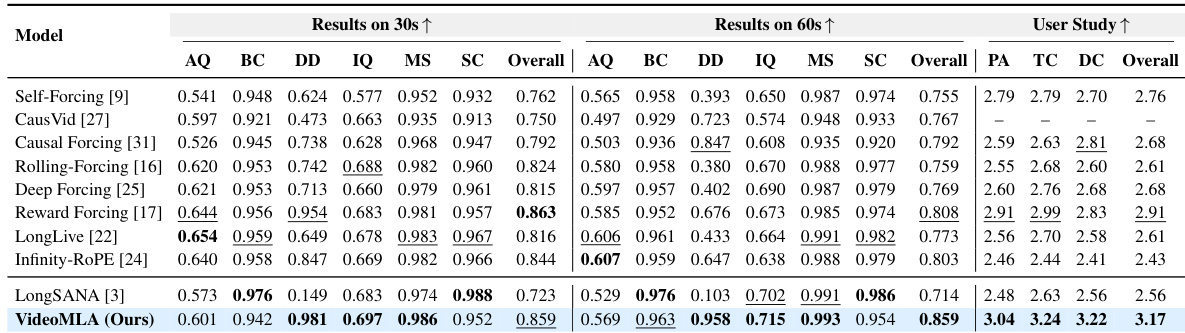
作者将 VideoMLA 模型与多种基线方法在多项指标上进行对比,涵盖质量与一致性得分。结果表明,VideoMLA 在大多数评估标准上达到具有竞争力或更优的性能,尤其在长跨度生成与感知质量方面表现突出,同时通过潜在压缩保持高效的内存使用。在不同生成长度下,VideoMLA 在关键质量与一致性指标上优于或持平现有方法。用户研究表明该模型具备高感知质量,在提示词遵循度与运动一致性方面获得高分。VideoMLA 在保持强劲性能的同时,通过高效的潜在压缩大幅降低了内存需求。
实验评估通过消融实验与针对现有自回归模型的对比基准,全面考察了 VideoMLA 的内存效率、计算复杂度与生成质量。结果验证了压缩潜在表示与分离式注意力设计在保留模型核心能力的前提下大幅降低了资源消耗。超参数分析进一步表明,平衡缓存内容与位置编码并优化潜在维度,能够实现内存节省与视频保真度之间的理想权衡。最终,该方法在显著降低延迟的同时,提供了与常规逐帧基线相媲美的生成质量与时间一致性。