Command Palette
Search for a command to run...
YoCausal:视频生成距离世界模型还有多远?——因果视角
YoCausal:视频生成距离世界模型还有多远?——因果视角
You-Zhe Xie Yu-Hsuan Li Jie-Ying Lee Kaipeng Zhang Yu-Lun Liu Zhixiang Wang
摘要
随着视频扩散模型(VDMs)向世界模型演进,一个关键问题随之浮现:它们是否真正理解了因果性,还是仅仅过度拟合了统计时间模式?现有的基准测试大多依赖合成数据,受限于仿真到现实的差距,难以实现现实世界的泛化。我们提出了YoCausal,这是一个受认知科学中期望违背(VoE)范式启发的两级基准。通过零成本地对真实世界视频进行时序反转作为自然反事实样本,YoCausal建立了一个任意可扩展的评估协议。第一级引入了反向惊讶指数(RSI),通过去噪损失量化时间箭头感知能力。第二级引入了因果认知指数(CCI),该指数利用视觉语言模型(VLM)将数据集划分为因果与非因果子集,从而将真正的因果推理与时间偏差解耦。对13个最先进的视频扩散模型的评估表明,感知时间箭头并不意味着理解因果性,且与人类水平的因果认知相比仍存在显著差距。
一句话总结
YoCausal 建立了一个两级基准,通过将时间反转的真实世界视频视为自然反事实样本,评估了十三种最先进的视频扩散模型。该基准采用反向惊讶指数(Reverse Surprise Index)来量化时间之箭感知,并利用视觉-语言模型分层派生的因果认知指数(Causality Cognition Index)来剥离真实的因果推理与时间偏差,从而揭示当前生成系统与人类级因果认知之间的显著差距。
核心贡献
- 本文提出 YoCausal,一个用于评估视频扩散模型因果认知的两级基准。该基准将时间反转的真实世界视频视为自然反事实样本,从而消除了合成数据集中固有的仿真到现实(sim-to-real)差距。
- 该框架定义了反向惊讶指数,通过去噪损失量化时间之箭感知;并定义因果认知指数,通过视觉-语言模型对数据集进行分层,有效剥离了真实的因果推理与时间偏差。
- 对 13 种最先进视频扩散模型的评估表明,时间感知并不等同于因果理解。结果揭示了与人类认知相比存在显著的性能差距,同时证实因果能力随模型架构独立扩展,且与美学质量无关。
引言
随着视频扩散模型向世界建模能力迈进,理解真实的因果关系而非仅仅学习统计时间模式,已成为机器人技术和自主仿真等应用的关键。然而,先前的评估方法高度依赖合成数据集或受控实验室录制,产生了限制现实世界泛化能力的仿真到现实差距,且往往侧重于判别式任务而非生成式先验。为解决这一问题,作者提出了受认知科学“期望违背”(Violation of Expectation)范式启发的可扩展两级基准 YoCausal。该方法利用时间反转的真实世界视频作为自然反事实样本,计算衡量时间之箭感知的反向惊讶指数,并使用视觉-语言模型计算因果认知指数,以将真实的因果推理与简单的时序偏差隔离开来。综合测试表明,尽管当前模型能够检测时间方向性,但在因果理解方面与人类水平仍存在显著差距。
数据集

- 数据集构成与来源:作者完全基于现有的真实世界视频档案构建了可扩展的评估基准 YoCausal。该方法无需合成渲染或受控环境,使基准能够以零成本跨多样化日常场景任意扩展。
- 子集划分:最终数据集包含 1,232 个视频,分为四个主题领域:
- 通用(General):500 个片段,源自 Moments in Time,保留原始 3 秒时长以捕捉无约束的日常事件。
- 物理(Physics):132 个片段,源自 Physics IQ,限制为每场景前 5 秒以强调机械、光学和热力学现象。
- 人类动作(Human Action):400 个片段,源自 Kinetics-400,每个裁剪为 3 秒以代表多种目标导向的人类活动。
- 动物动作(Animal Action):200 个片段,源自 Animal Kingdom,截断为 3 秒以覆盖多物种的多样化非人类行为。
- 数据使用与评估策略:作者仅将该数据集用于模型评估而非训练。通过对每个片段应用零成本的时间反转来生成自然反事实对。随后,根据是否存在明显的因果关系交互,将数据集划分为因果子集与非因果子集,从而支持因果认知指数的计算。模型性能通过反向惊讶指数进行量化,该指标通过比较正向序列与反转序列的去噪损失来衡量时间感知。
- 预处理与标注流程:为保证跨不同模型架构的评估一致性,作者实施了标准化的预处理流程。该流程包括通过中心裁剪或自动纵横比桶选择进行分辨率适配、使用 FFmpeg 进行帧率重采样,以及针对长视频的时间窗口处理(其中部分片段会用前序片段的上下文帧进行填充)。作者还对全部 1,232 个样本进行了人工标注以确立性能上限,由于方向线索不明确,将约 20% 标记为未知,并在最终评分中赋予其中性胜率。
方法
作者利用一个两级评估框架来衡量视频扩散模型(VDM)的因果认知,该框架围绕量化模型对时间方向的感知及其对因果违背的敏感性构建。如图下图所示,整体架构包含三个主要阶段:数据集构建、一级时间感知测量和二级因果解耦。
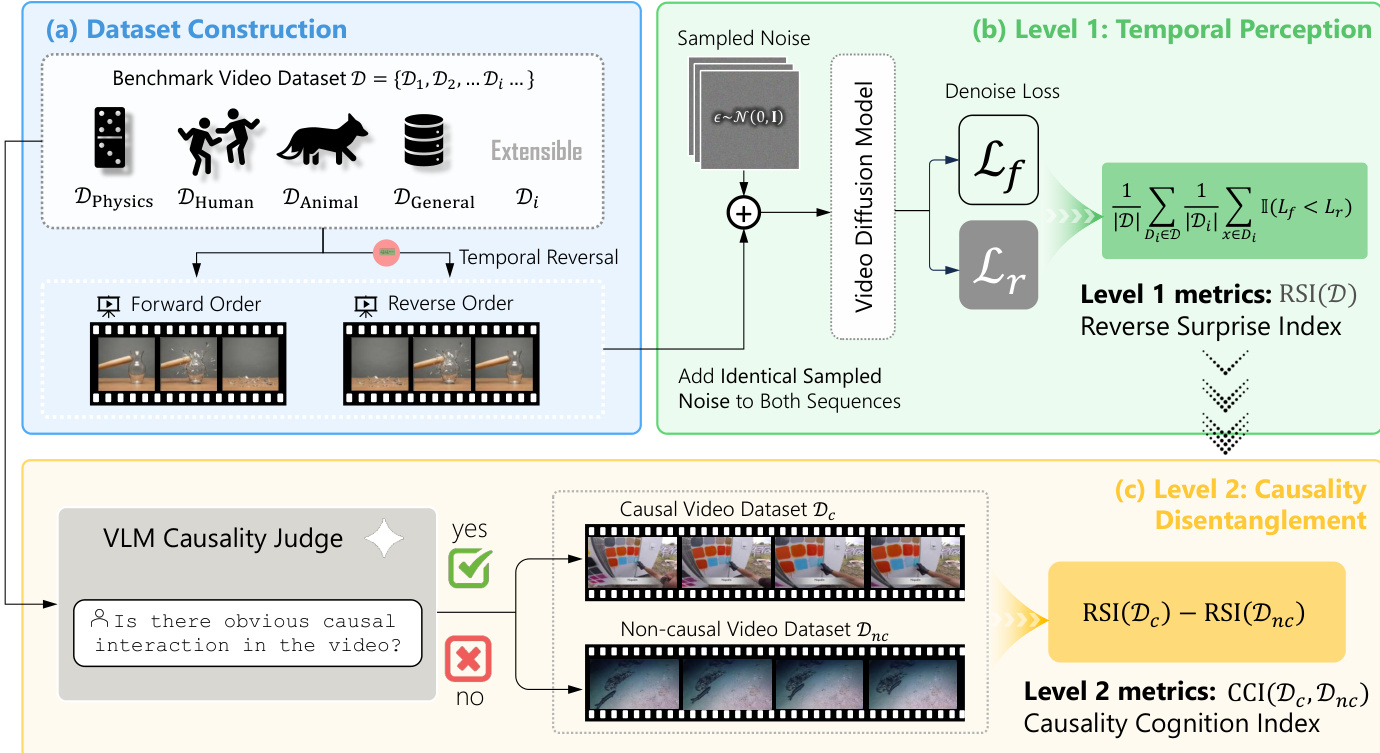
该框架始于可扩展的数据集构建过程,其中基准数据集 D 由多个子数据集 {Di} 组成,每个子数据集代表一个特定领域(如物理、人类动作或动物)。对于数据集中的每个视频,都会生成一个时间反转版本,从而创建正向(xf)与反转(xr)序列对。这构成了第一级评估的基础。
评估的核心在于使用去噪损失作为模型惊讶度的代理指标,该概念在第 3.2 节中进行了形式化定义。作者采用期望违背(VoE)范式,其中模型的惊讶度通过其分配给特定视频序列的概率来衡量。在 VDM 的语境下,去噪损失(定义为真实噪声与模型预测之间期望平方误差)充当这一代理指标。更高的去噪损失对应更低的分配概率,表明更大的惊讶度。该损失针对正向和反转序列分别计算。
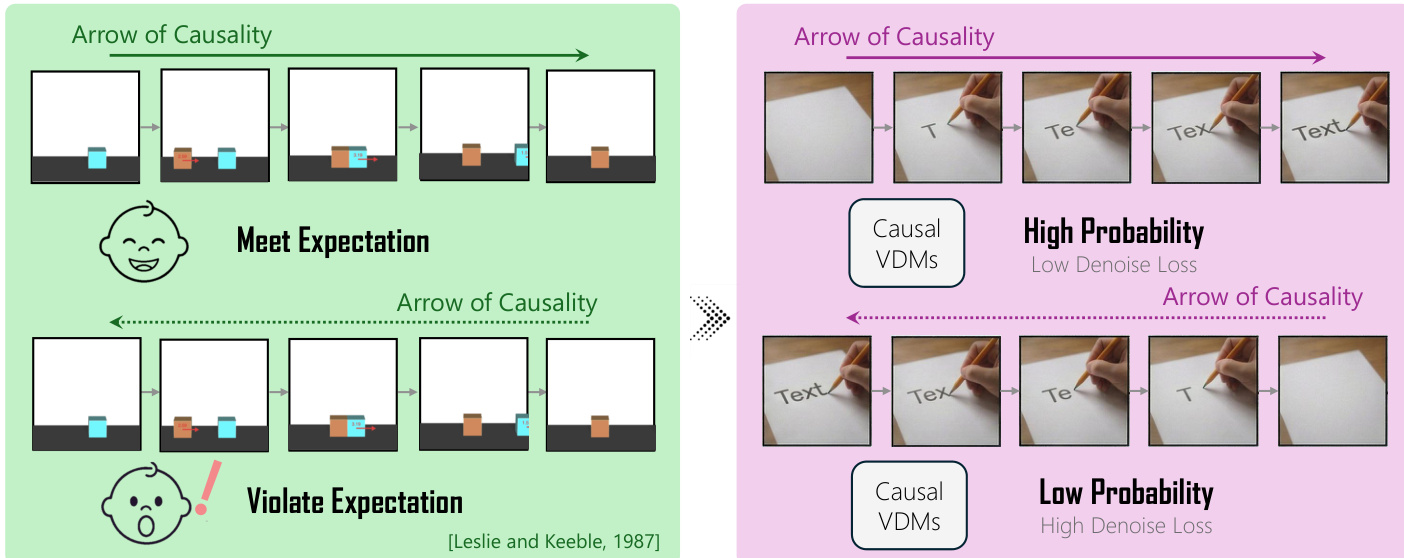
框架的一级使用反向惊讶指数(RSI)来测量模型对时间之箭的感知。如图所示,RSI 通过比较每个视频的正向序列去噪损失(Lf)与反转序列去噪损失(Lr)来计算。该指数定义为模型为正向序列分配更低损失的样本比例,即 Lf<Lr。计算时从扩散过程中均匀采样 K=10 个时间步,并在每个时间步向两个序列施加相同的高斯噪声以确保公平比较。RSI 提供了衡量模型区分正确时间顺序能力的指标。
框架的二级旨在将真实的因果理解与单纯的统计时间模式解耦。作者指出,模型对反转视频的惊讶可能源于两个因素:时间之箭的反转与因果关系的反转。为隔离因果信号,数据集根据是否存在明显的因果关系交互被划分为因果子集 Dc 与非因果子集 Dnc。该划分过程通过视觉-语言模型(VLM)实现自动化,模型在精心设计的提示词引导下对视频是否包含因果关系进行分类。

因果认知指数(CCI)随后定义为因果子集与非因果子集 RSI 的差值:CCI(D)=RSI(Dc)−RSI(Dnc)。该差分度量抵消了时间之箭敏感性的共同混淆因素,从而隔离出模型对因果违背的独立敏感性。正的 CCI 表明模型认为反转的因果视频比反转的非因果视频更为异常,暗示其已捕捉到真实的因果认知。
完整的评估流程如算法 1 所述,依次编排上述步骤。首先计算所有视频及其反转版本的去噪损失(阶段 1),随后计算整个数据集的 RSI(阶段 2)。接着,利用 VLM 将数据集分层为因果与非因果子集(阶段 3)。最后,计算各子集的 RSI 并推导 CCI(阶段 4)。这种两级方法为评估 VDM 的因果认知提供了一种稳健且可扩展的方案。
实验
该评估采用 YoCausal 基准,对十三种最先进的开源视频扩散模型进行因果认知评估,利用反向序列识别测量时间之箭感知,并使用因果认知指数评估因果理解。消融研究与跨指标分析验证了性能源于内化的时序与因果推理,而非底层熵动力学或图文不对齐,同时证实因果感知是一种独立于视觉质量的独特能力。定性结果表明,当前模型仅具备初步的因果理解,显著落后于人类表现,但该能力随模型规模扩大与架构演进持续稳定提升。最终,本研究建立了一个稳健的框架,用于将因果认知与基础时间感知解耦,并证明扩展定律能有效推动视频生成高级认知能力的发展。
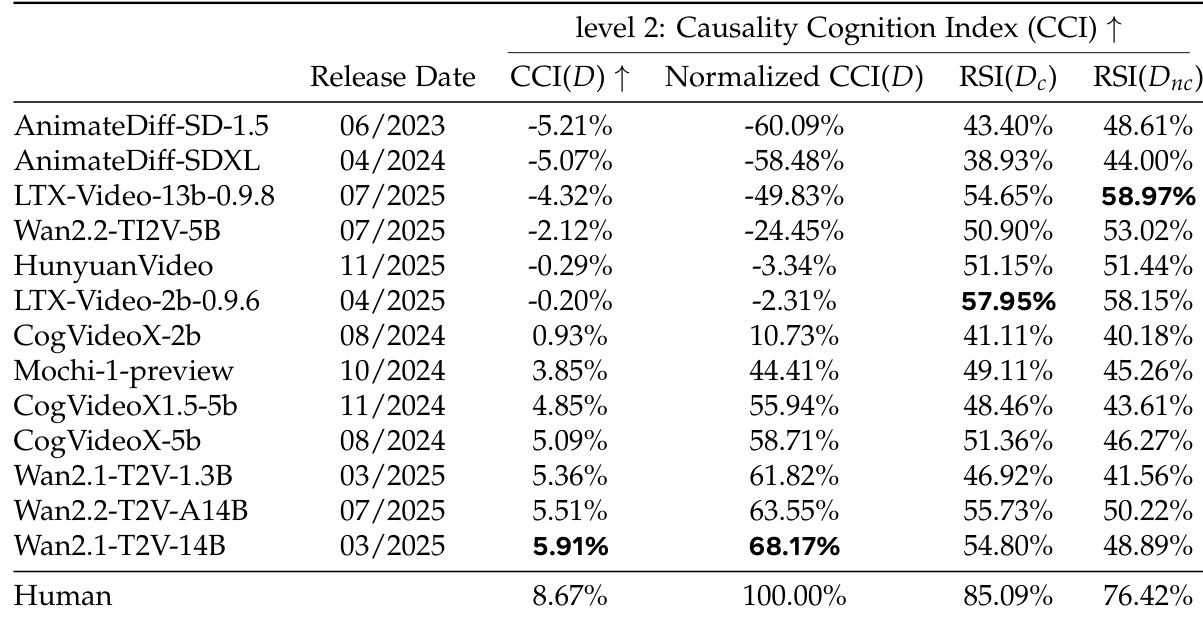
作者使用评估时间方向感知与因果理解的两级框架,对 13 种开源文生视频扩散模型的因果认知进行评估。结果表明,高保真模型在两项指标上表现通常更优,但模型性能与人类级因果认知之间仍存在明显差距。评估显示,因果认知随模型规模与发布日期提升,且不受图文不对齐或底层熵线索驱动。与低保真模型相比,高保真模型在时间方向与因果理解指标上均取得更好成绩。因果认知随模型规模与发布日期改善,表明扩展定律已延伸至高级认知能力。该评估框架对 VLM 的选择具有鲁棒性,且未受图文不对齐或底层熵动力学的干扰。

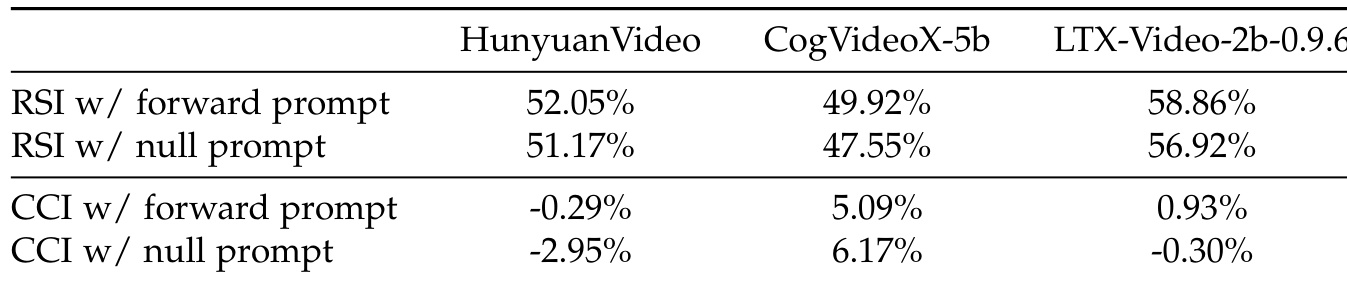
作者在前向提示与空提示条件下,使用 RSI 和 CCI 两项指标评估视频扩散模型的因果认知。结果表明,模型在不同提示类型下表现一致,RSI 值反映时间感知,CCI 反映因果理解。这些指标在不同提示设置下的稳定性支持了测量信号源于内化认知而非图文不对齐的观点。RSI 与 CCI 指标在前向与空提示条件下保持一致,表明对提示条件具有鲁棒性。模型展现出不同水平的时间与因果感知,部分模型获得较高 RSI 分数,另一些则呈现正的 CCI 值。空提示下判别模式的持续性表明,测量信号源自内化认知而非图文不对齐。
作者利用两级框架分析视频扩散模型的因果认知,跨多个子集评估时间方向感知与因果理解。结果表明,高保真模型在时间感知上表现更佳,而因果认知与模型规模及发布日期相关,印证了扩展效应。该基准对不同评估者具有鲁棒性,且未受视觉质量或提示不对齐的干扰。与低保真模型相比,高保真模型展现出更强的时间感知。因果认知与模型规模及发布日期相关,表明扩展定律适用于高级认知能力。该基准不受评估者差异、视觉质量或提示不对齐的影响。

作者采用评估时间方向感知与因果理解的两级框架,对 13 种开源视频扩散模型的因果认知进行评估。结果表明,高保真模型在两项指标上通常表现更优,人类表现作为性能上限。该框架揭示因果认知独立于单纯的时间感知,并受模型架构与规模影响,这由其与发布日期及参数量的相关性所证实。与低保真模型相比,高保真模型在时间方向与因果认知指标上均展现更优性能。人类表现始终优于所有模型,作为因果认知的基准。因果认知与时间感知相互独立,因为在某项指标上表现优异的模型在另一指标上可能表现较差,这表明两者属于不同的认知能力。
作者使用两级框架评估一组开源视频扩散模型的因果认知,同时测量时间方向感知与因果理解。结果表明,高保真模型在时间感知上通常表现更佳,而因果认知因模型而异,并受架构与规模因素影响。通过跨指标分析、熵控制子集及消融研究验证了该评估框架的稳健性及其与人类因果偏好的对齐程度。与低保真模型相比,高保真模型通常表现出更强的时间感知与因果认知。该评估框架将因果认知与单纯的时间之箭感知区分开来,表明模型可能在一项指标上得分较高而在另一项上得分较低。因果认知与模型规模及发布日期相关,表明扩展定律已延伸至高级认知能力。
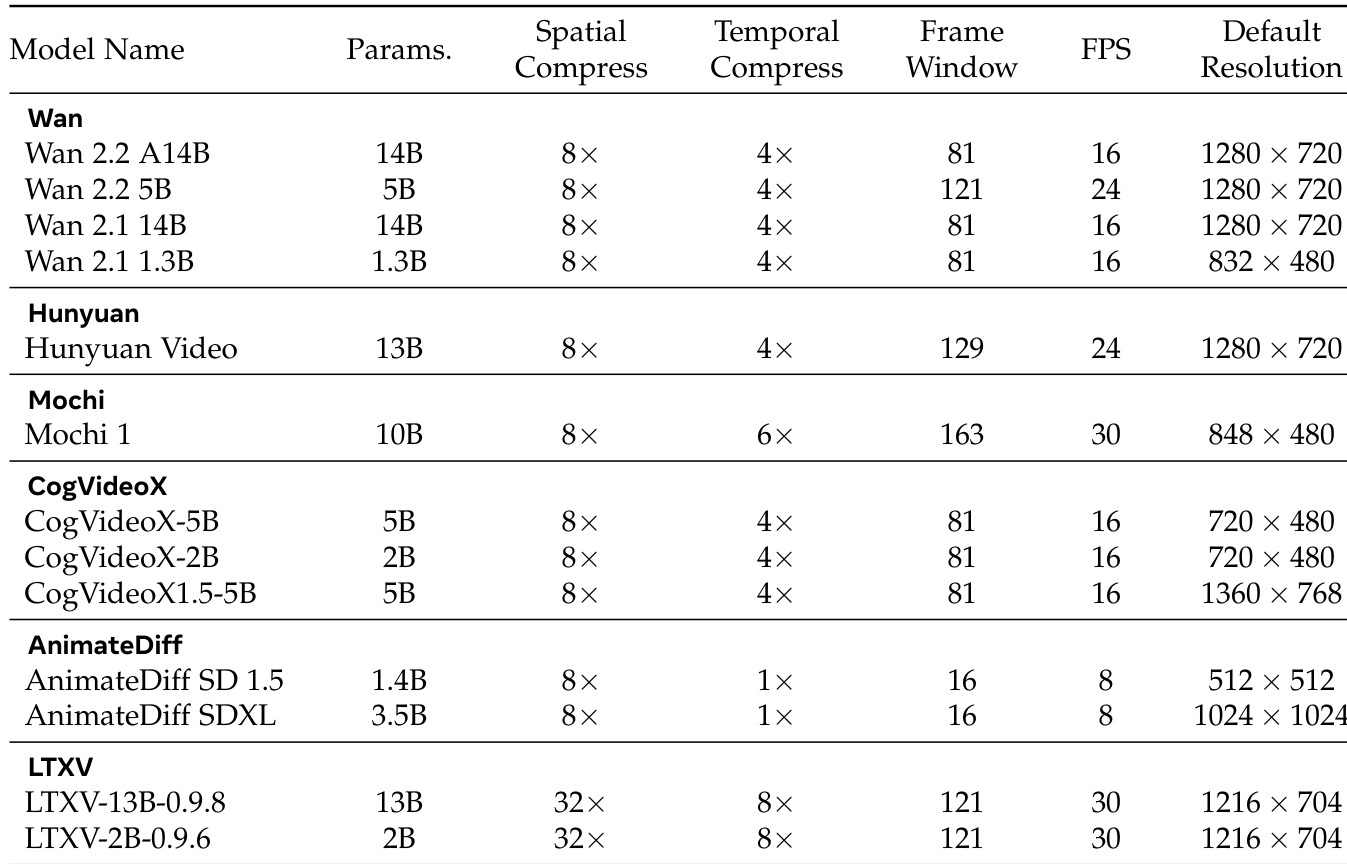
本研究采用两级评估框架,对多种开源视频扩散模型的时间方向感知与因果理解进行评估。定性分析表明,高保真模型在两个领域均持续展现更优性能,而因果推理随模型规模与发布日期呈现可预测的扩展趋势。重要的是,该框架成功将因果认知与基础时间感知隔离,并对提示变化、评估者差异及底层视觉伪影保持鲁棒性。尽管取得上述进展,人类表现仍是明确的性能上限,凸显了人工因果推理中持续存在的差距。