Command Palette
Search for a command to run...
Qwen-VLA:统一任务、环境与机器人具身中的视觉-语言-动作建模
Qwen-VLA:统一任务、环境与机器人具身中的视觉-语言-动作建模
摘要
具身智能通常通过针对操作或导航等单一任务的专业模型进行研究,导致能力碎片化,且在任务、环境与机器人形态之间的泛化能力受限。在本工作中,我们探讨了异构具身决策问题是否能够在单一视觉-语言-动作模型中得到统一。我们提出了Qwen-VLA,这是一种统一的具身基础模型,通过基于DiT的动作解码器,将Qwen的视觉-语言建模栈从感知、理解与推理扩展至连续动作与轨迹生成。Qwen-VLA采用大规模联合预训练配方,在多样化数据源上进行训练,涵盖机器人操作轨迹、人类第一人称演示、合成仿真数据、视觉与语言导航数据、以轨迹为中心的监督信号以及辅助视觉-语言数据。为支持多种机器人平台,我们引入了具身感知提示条件化机制,其中特定于机器人的文本描述用于明确当前具身形态与控制协议。我们进一步将操作、导航与轨迹预测纳入统一的动作与轨迹预测框架,从而在机器人形态、任务族与环境之间实现可迁移的视觉定位、空间推理与连续动作生成。在操作、导航及以轨迹为中心的基准测试上的实验表明,在场景布局、背景、光照、物体配置及机器人形态发生变化时,模型均展现出稳定的多任务性能与分布外泛化能力。Qwen-VLA-Instruct在LIBERO上取得97.9%的成绩,在Simpler-WidowX上取得73.7%的成绩,在RoboTwin-Easy/Hard上分别取得86.1%/87.2%的成绩,在R2R上的OSR为69.0%,在RxR上的SR为59.6%,在真实世界ALOHA实验中平均OOD成功率为76.9%,在DOMINO动态操作中零样本成功率为26.6%。
一句话总结
Qwen-VLA 通过基于 DiT 的解码器和具身感知提示条件控制,将 Qwen 的视觉-语言建模架构扩展至连续动作与轨迹生成,从而在任务、环境与机器人具身形态之间统一具身决策,并在包括 LIBERO、R2R、RxR 以及真实世界 ALOHA 和 DOMINO 平台在内的操作、导航与轨迹基准测试中,提供稳定的一致多任务性能与分布外泛化能力。
核心贡献
- Qwen-VLA 是一个统一的具身基础模型,通过基于 DiT 的动作解码器将视觉-语言主干网络扩展至连续动作与轨迹生成。该架构将操作、导航与轨迹预测重构为共享的动作与轨迹预测问题,使视觉定位与空间推理能力能够在不同机器人形态与任务家族间迁移。
- 分阶段训练策略解决了预训练语言主干网络与随机初始化解码器之间的优化不对称问题。该方法首先训练解码器将语言指令解压缩为动作先验,随后再进行视觉定位。框架同时采用具身感知提示条件控制,在输入前添加特定机器人的文本描述,以使共享模型与平台特定的控制协议对齐。
- 在操作、导航与轨迹基准测试中的评估表明,大规模联合预训练能够带来稳健的多任务性能与分布外泛化能力。统一策略在 LIBERO、Simpler-WidowX、RoboTwin、R2R 和 RxR 上取得了高成功率,同时在真实世界的 ALOHA 和 DOMINO 动态操作任务中保持了具有竞争力的零样本性能。
引言
具身智能要求机器人感知环境、理解语言并执行物理任务,然而当前系统仍局限于狭窄的任务与特定的机器人设计。这种专业化限制了跨领域迁移,并阻碍了在多样化真实场景中的可扩展学习。为此,本文作者提出 Qwen-VLA,这是一种统一的视觉-语言-动作模型,将操作、导航与轨迹预测重构为单一的动作与轨迹生成问题。该模型在预训练多模态主干网络之上挂载基于 DiT 的动作解码器,并利用具身感知文本提示,在不改变架构结构的前提下适配不同机器人平台。通过在异构数据集上进行大规模联合预训练,并采用分阶段优化流程(首先在仅文本模拟数据上建立语言条件动作先验,随后进行视觉定位),该模型在不同环境与形态下实现了稳健的多任务性能与强大的分布外泛化能力。
数据集

-
数据集构成与来源 本文作者构建了一个大规模异构预训练语料库,旨在统一视觉、语言与动作建模。该混合数据集整合了五大核心数据家族:真实与模拟的机器人操作轨迹、人类第一人称演示、合成仿真环境、移动导航片段以及辅助视觉-语言数据集。数据来源涵盖十余个公开机器人基准测试、大规模人类视频语料库、专有内部收集数据以及内部生成的仿真流水线。
-
各子集关键细节
- 机器人操作轨迹占据语料库的约 74.2%,整合了 DROID 和 RT-1 等公开数据集、InternData 与 GR00T 的仿真数据、超过 1,000 小时的专有遥操作录制数据,以及约 800 万条合成仿真轨迹。
- 人类第一人称演示占比 6.0%,来源于 Ego4D、EPIC-KITCHENS、EgoDex、EgoVerse 和 Xperience,用于提供可扩展的真实世界操作先验。
- 合成仿真数据分为视觉条件控制与纯文本组件,在随机生成的桌面场景中生成超过 35.9 万条 VLA 轨迹,并在六种机器人形态上生成约 720 万条纯文本运动学轨迹。
- 导航数据占混合数据集的 7.5%,包含用于指令跟随、物体搜索与目标追踪的长视野移动机器人片段。
- 辅助视觉-语言数据占剩余的 8.5%,包含细粒度动作描述、自动驾驶 VQA 基准测试、2D 空间定位样本以及通用多模态推理语料库。
-
训练用途与混合比例 本文作者将整理后的混合数据集用于两个独立的训练阶段。在预训练阶段,模型以指定的采样权重从完整的异构混合数据中学习,在纯文本模拟数据上完成初始的语言-动作对齐后,逐步引入视觉定位。针对多任务监督微调,作者精心筛选了一个专用子集,包含通用视觉-语言样本、具有 16 步动作预测视野的仿真操作演示,以及成功完成的 8 步视野导航片段。微调目标在下一个 token 预测与流匹配之间取得平衡,将视觉-语言 tokens 的权重设为 0.1,动作 tokens 的权重设为 1.0,从而在保留基础视觉理解的同时优先优化运动策略。
-
处理流程、元数据与裁剪策略 本文作者实施了广泛的预处理流程以标准化异构输入。各数据集的动作维度采用 1% 与 99% 分位数的量化映射进行归一化,裁剪至 -1 到 1 的范围,同时保留原始控制协议。通过指定平台类型、机械臂配置与控制频率的文本提示注入具身特定元数据。多相机观测数据使用边界 tokens 进行明确标注,以引导选择性注意力。语言指令经过严格的一致性过滤以剔除错位标注,密集动作描述则通过两阶段视觉-语言模型流水线生成,并辅以人工验证。作者还应用多阶段轨迹清洗流程以移除损坏帧、静态录制与异常片段,同时通过对本体感知状态进行有限差分计算来重建缺失的动作标签。完整轨迹进一步被分割为子任务序列以提供多粒度监督,第一人称视频则进行密集采样以捕捉细粒度运动细节。
方法
Qwen-VLA 模型旨在单一框架内统一视觉、语言与动作生成,实现跨多样化任务与机器人平台的具身控制。整体架构由视觉-语言主干网络与流匹配动作专家组成。基于 Qwen3.5 的主干网络通过 Transformer 中的早期融合机制,将视觉 tokens 与文本 tokens 结合处理,支持对图像、视频与语言的联合推理。该主干网络辅以基于 DiT 风格的流匹配策略头,用于生成连续动作序列。动作专家作为单流解码器运行,接收主干网络的隐藏状态与含噪动作块作为输入,通过带有 AdaLN 时间步条件控制与多段 RoPE 对齐的联合自注意力机制进行处理。这种解耦设计使动作专家能够专注于细粒度动作预测,同时保留主干网络预训练的感知与推理能力。模型采用联合目标进行端到端训练,结合用于动作预测的流匹配损失与用于视觉-语言理解的标准下一个 token 预测损失。
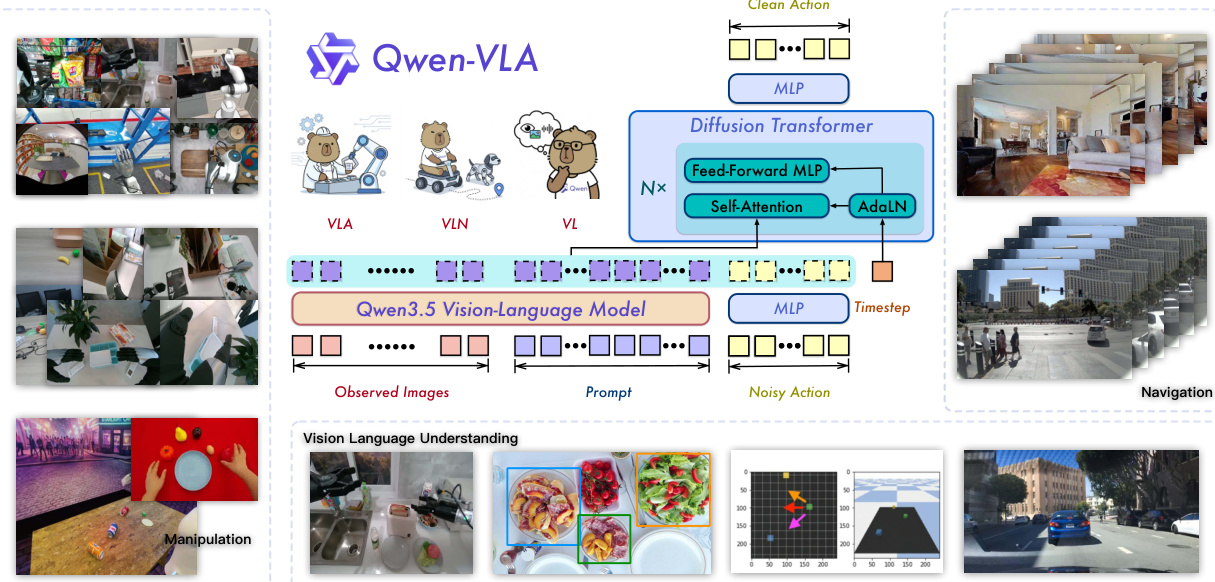
该模型通过统一的条件预测框架支持多种具身任务。在每个时间步,模型接收视觉上下文 ot、语言指令 x、具身描述 e 以及可选的任务标识符 z。模型训练目标是在固定预测视野 H 内预测目标序列 yt:t+H−1,其中该序列表示共享动作与轨迹空间中的动作或轨迹。对于操作任务,这包含末端执行器位置等机器人动作;对于导航任务,由航点组成;对于轨迹预测,表示连续空间路径;对于第一人称数据,则捕获结构化姿态空间中的人类运动。这种统一表述实现了异构数据集上的联合优化。
为处理多样化的机器人具身形态,模型采用具身感知提示条件控制。每个训练样本前均附带遵循标准化模板的文本提示,明确指定机器人平台、机械臂配置与控制协议。该提示由主干网络处理并用于条件控制动作专家,使单一模型无需独立的策略头即可处理多种控制协议。统一的动作表示进一步支持了这一设计,将所有控制信号视为共享张量接口中的实值向量序列。每个样本贡献一个目标张量 Y∈RH×K,具有固定预测视野 H 与通道维度 K,其中仅相关的 c 个通道处于激活状态,其余通道进行零填充。逐通道二值掩码 M 确保仅有效条目参与损失梯度计算,从而使单组 DiT 参数能够处理所有控制模式。
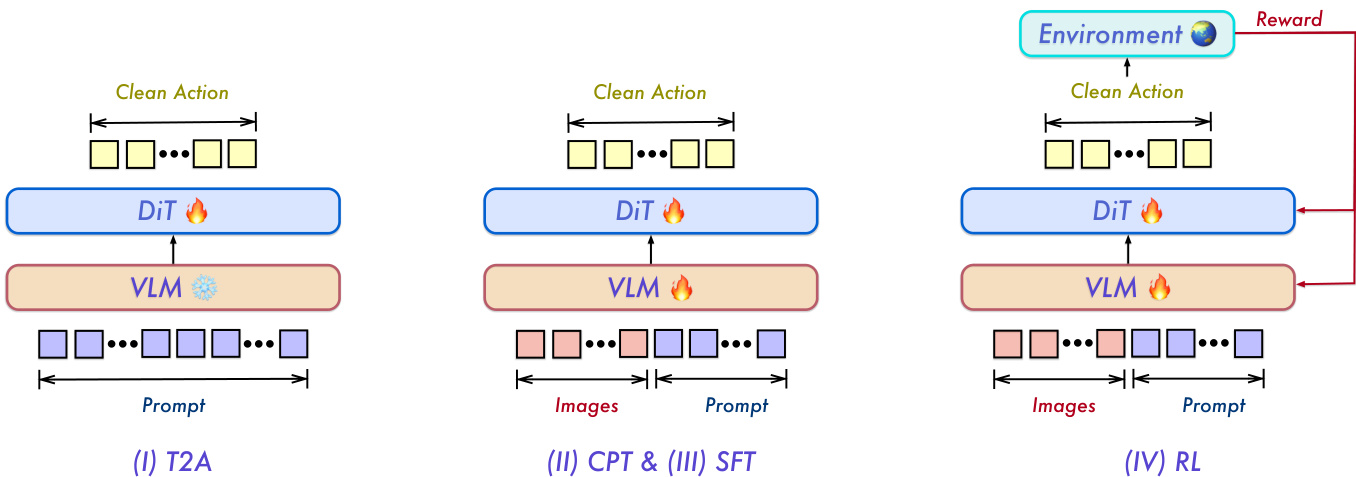
训练流程遵循四阶段渐进式策略,以稳定学习过程并弥合离散视觉-语言 tokens 与连续动作轨迹之间的差距。第一阶段为文本到动作(T2A)预训练,冻结主干网络,仅在语言与具身提示上训练 DiT 动作解码器,不使用视觉输入。这迫使解码器学习由语言与具身形态索引的动作空间结构化先验。第二阶段为持续预训练(CPT),解冻两个模块,在异构数据混合体上进行训练,将动作先验锚定于视觉观测。第三阶段为监督微调(SFT),分化为多任务与真实机器人两条路径,使模型与精心筛选的演示数据对齐。最后,第四阶段为强化学习(RL),在仿真环境中利用稀疏二值奖励直接优化策略以实现任务成功。这种分阶段方法确保解码器在接触视觉输入前学会结构化动作先验,从而防止联合训练过程中的不稳定性。
实验
在仿真环境、真实世界机器人平台及连续导航基准测试中的广泛评估验证了 Qwen-VLA 作为高能力通用模型的表现,通过联合多具身预训练与指令微调,其性能匹配甚至超越了特定具身形态的专业模型。实验表明,大规模预训练建立了稳健的空间与运动学先验,使模型无需任务特定适配即可对未见物体、多样化视觉条件与动态移动目标实现强大的零样本泛化。补充消融研究证实,战略性设计的文本到动作预训练、视觉-语言协同训练与强化学习优化共同提升了策略的果断性与闭环成功率,同时保持了在保留任务上的性能。最终结果证明,具有极小架构开销的统一架构能够在多样化具身环境中实现可靠且可迁移的操作与导航。
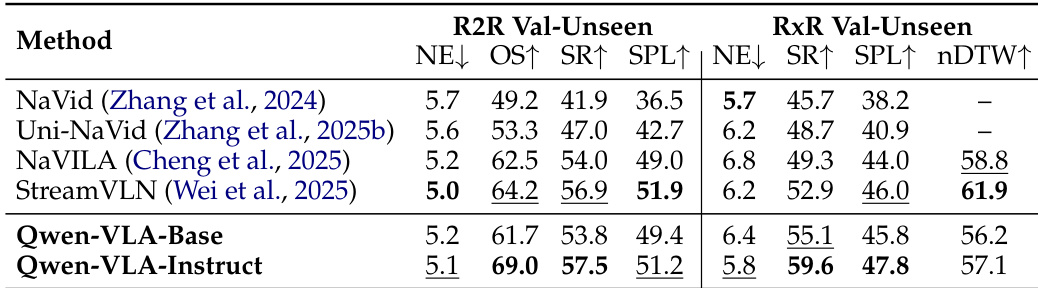
本文作者在视觉-语言导航基准测试中评估了 Qwen-VLA 的导航能力,将 Base 与 Instruct 变体与开源基线进行对比。结果表明,Qwen-VLA-Instruct 在 R2R 与 RxR 基准测试的多数指标上均取得最佳性能,在成功率与成功率加权路径长度上超越现有方法。Qwen-VLA-Instruct 在 R2R 与 RxR 基准测试中均实现了最高成功率。Qwen-VLA-Instruct 在 R2R 与 RxR 基准测试的成功率加权路径长度上优于现有基线。通过在 VLA 与 VLN 数据上进行联合训练,该模型在 R2R 与 RxR 基准测试中均保持了具有竞争力的性能。
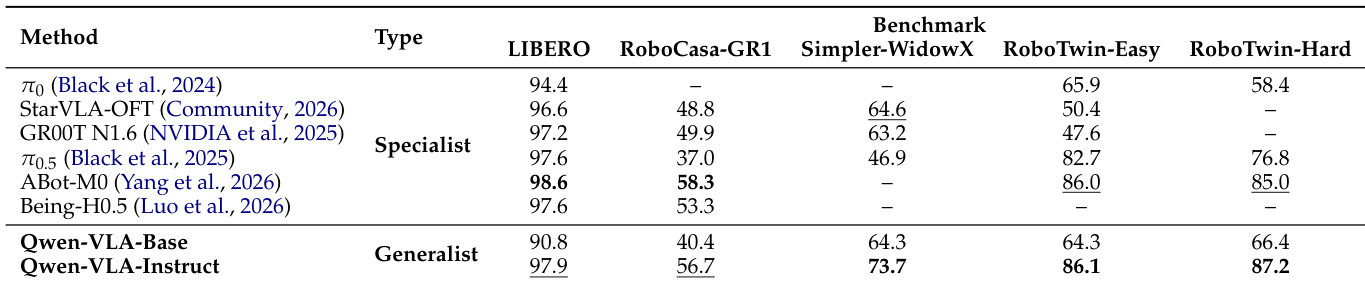
本文作者在多个机器人操作基准测试中评估了通用模型 Qwen-VLA,并将其性能与针对单一任务训练的专业模型进行对比。结果表明,通用模型在各类基准测试中取得了具有竞争力或更优的成功率,证明了无需逐任务适配即可在不同机器人具身形态间实现有效的迁移学习。指令微调进一步提升了性能,尤其在更复杂的任务上,且模型在仿真与真实世界场景中均表现出对分布外场景的强大泛化能力。单一通用模型在多个机器人操作基准测试中取得了与专业模型相当或更优的性能。指令微调显著提升了性能,尤其是在复杂任务与分布外设置下。该模型在真实世界操作任务中对未见视觉条件、物体实例与语言指令展现出强大的泛化能力。
本文作者通过对比三种策略(无状态、状态置于 VLM 提示中、状态置于 DiT 中)评估了状态条件控制对机器人操作性能的影响。结果表明,所有策略间的性能差异极小,仅在引入本体感知信息时观察到微小提升。流匹配动作解码器依赖相对位移与多相机提供的充足视觉信息,这可能降低了对显式状态输入的需求。在所有条件控制策略中,引入本体感知状态仅带来微小的性能提升。流匹配动作解码器通过关注相对动作位移,减少了对显式状态条件控制的需求。多视角视觉观测提供了关于机器人构型的充足信息,从而最小化了状态输入的收益。

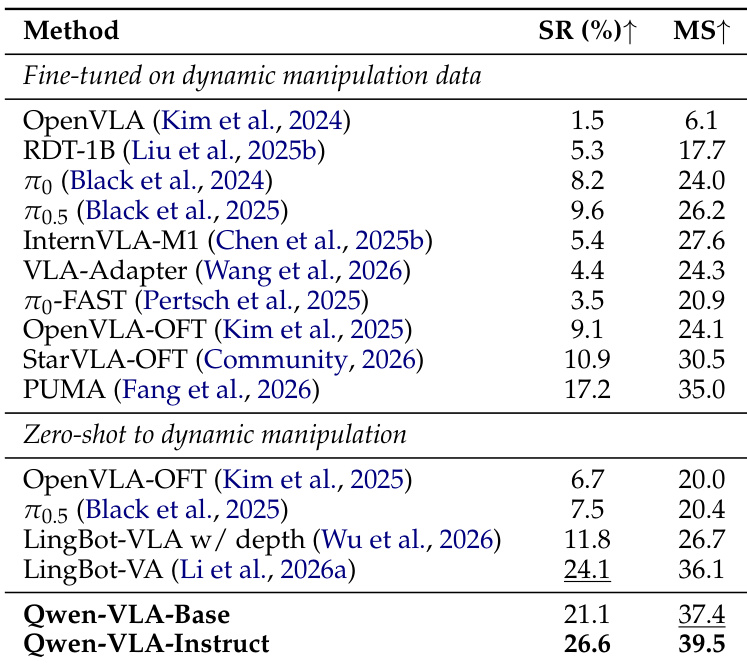
本文作者评估了 Qwen-VLA 在动态操作任务中的性能,并在 DOMINO 基准测试中将其与多种基线进行对比。结果表明,Qwen-VLA-Instruct 取得了最高的成功率与操作得分,超越了零样本与微调方法。尽管未在动态操作数据上进行训练,该模型仍展现出对移动物体的强大零样本泛化能力。Qwen-VLA-Instruct 在 DOMINO 基准测试中取得最佳性能,优于所有其他方法。与零样本及微调基线相比,该模型在成功率与操作得分上均有显著提升。Qwen-VLA-Instruct 在未进行任何动态操作微调的情况下,对动态操作任务展现出强大的零样本泛化能力。
{"summary": "本文作者在 ALOHA 机器人上评估了 Qwen-VLA 在真实世界操作任务中的性能,重点关注域内与分布外泛化能力。结果表明,相较于从头训练的模型,基于预训练基础模型微调的模型在所有评估类别中均取得了显著更高的成功率,证明了大规模预训练在真实世界部署中的有效性。", "highlights": ["相较于从头训练,基于预训练基础模型微调在域内与分布外任务上均显著提升了性能。", "预训练模型在所有分布外泛化类别(包括颜色、实例、位置、背景与指令变化)中均实现了最高成功率。", "该模型对未见视觉条件、物体实例与指令变化展现出强大的泛化能力,表明预训练向真实世界设置的成功迁移。"]

实验在视觉-语言导航与多样化机器人操作基准测试中评估了 Qwen-VLA,以检验其泛化能力、指令遵循能力与真实世界适用性。结果表明,经过指令微调的通用模型无需逐任务适配即可持续优于专业基线,而大规模预训练被证明对稳健的域内与分布外泛化至关重要。此外,该模型对动态场景与复杂视觉变化展现出强大的零样本适应能力,由于多视角视觉反馈已足够充分,显式本体感知状态输入仅带来微小收益。总体而言,这些发现凸显了该模型的多功能推理能力、有效的迁移学习特性,以及应对复杂机器人部署的实际就绪状态。