Command Palette
Search for a command to run...
minWM:面向实时交互式视频世界模型的全栈开源框架
minWM:面向实时交互式视频世界模型的全栈开源框架
摘要
近期的视频扩散基础模型在高质量视频生成方面取得了显著进展,但将其转化为实时交互式视频世界模型仍具挑战性。交互式世界模型需要具备可控、因果且低延迟的推演能力,这在实践中要求涵盖数据构建、可控微调、自回归训练、少步蒸馏和流式推理的完整流水线。在本工作中,我们提出 minWM,一个用于构建实时交互式视频世界模型的全栈开源框架。minWM 提供了一条端到端的流水线,可将现有的双向 T2V/TI2V 视频基础模型转化为具备相机控制能力的少步自回归世界模型。具体而言,minWM 首先对带有相机控制功能的双向视频扩散模型进行微调,随后应用 Causal Forcing / Causal Forcing++ 流水线,包括 AR 扩散训练、因果 ODE 或因果一致性蒸馏以及非对称 DMD,将其蒸馏为用于低延迟推演的少步自回归生成器。该框架具有模块化与架构可扩展性:我们在代表性的开源骨干网络上进行了实例化,包括 Wan2.1-T2V-1.3B 和 HY1.5-TI2V-8B,涵盖了基于交叉注意力的条件注入与 MMDiT 风格架构。minWM 还支持将现有的视频世界模型(如 HY-WorldPlay)适配至新的数据分布、训练配方与延迟目标。除了发布可运行脚本、检查点、文档与推理代码外,我们还针对相机轨迹质量、可控性训练步数以及最小批次大小要求提供了实用的消融实验。我们希望 minWM 能够作为构建与适配实时交互式视频世界模型的可复现且可扩展的配方。项目页面:https://github.com/shengshu-ai/minWM
一句话总结
minWM 是一个模块化的全栈开源框架,通过结合相机条件微调、因果强制、因果一致性蒸馏与非对称 DMD 的流水线,将双向视频扩散模型转换为具备相机控制能力、仅需少数步骤的自回归世界模型,从而在 Wan2.1-T2V-1.3B 和 HY1.5-TI2V-8B 等架构上实现低延迟的交互式生成。
核心贡献
- 本文提出 minWM,这是一个全栈开源框架,提供模块化、端到端的流水线,用于将现有的双向文本到视频及图文到视频基础模型转换为具备相机控制能力的自回归世界模型。该框架将数据构建、可控微调、自回归训练、少步蒸馏和流式推理整合为可复现的工作流。
- 该框架执行两阶段转换方案:首先基于相机标注数据对双向扩散骨干网络进行微调以实现轨迹控制。随后应用 Causal Forcing 或 Causal Forcing++ 流水线,结合自回归扩散训练、因果 ODE 或一致性蒸馏以及非对称 DMD 后训练,将模型蒸馏为支持低延迟生成的少步自回归生成器。
- 该流水线在 Wan2.1-T2V-1.3B 和 HY1.5-TI2V-8B 骨干网络上进行实例化,以展示在跨注意力与 MMDiT 架构上实现实时交互式视频生成的能力。通过发布各训练阶段的中间检查点,并提供关于相机轨迹质量与训练配置的消融实验,该框架为可复现的世界模型开发提供了切实可行的指导。
引言
基于高质量扩散模型的视频基础模型已显著推动视觉生成技术的发展,但它们目前仍作为离线生成器运行,而非交互式世界模型。实时交互式应用要求具备因果生成能力、响应式相机控制以及低延迟的帧合成,但现有的转换技术仍分散在不相连的流水线中,且在数据准备、微调、自回归训练和蒸馏等环节需要大量人工操作。为弥补这一差距,本文提出 minWM,一个将完整工作流整合为单一可复现流水线的全栈开源框架。该框架采用两阶段策略,首先对双向视频骨干网络进行微调以赋予其相机控制能力,随后结合因果强制与非对称蒸馏技术将其转换为少步自回归生成器。该模块化架构使研究人员能够无缝地将现有基础模型适配为实时相机控制视频世界模型,同时支持流水线中途检查点保存与可定制的训练配置。
方法
本文提出 minWM,一个用于构建实时交互式视频世界模型的全栈框架,其运行依赖于两阶段流水线。整体架构始于数据准备,经过包含双向扩散微调和自回归蒸馏的训练阶段,最终实现低延迟推理。该流程以图像、文本和动作信号作为输入,首先进行数据过滤与重平衡,随后通过结构化标注生成适用于训练的数据集。该数据集用于微调具备相机控制能力的双向扩散模型,并采用 PROPE 作为相机参数的注入方法。该框架支持多种骨干网络,包括 Wan2.1-T2V-1.3B 和 HY1.5-TI2V-8B,从而能够将现有视频基础模型转换为具备相机控制能力的少步自回归生成器。
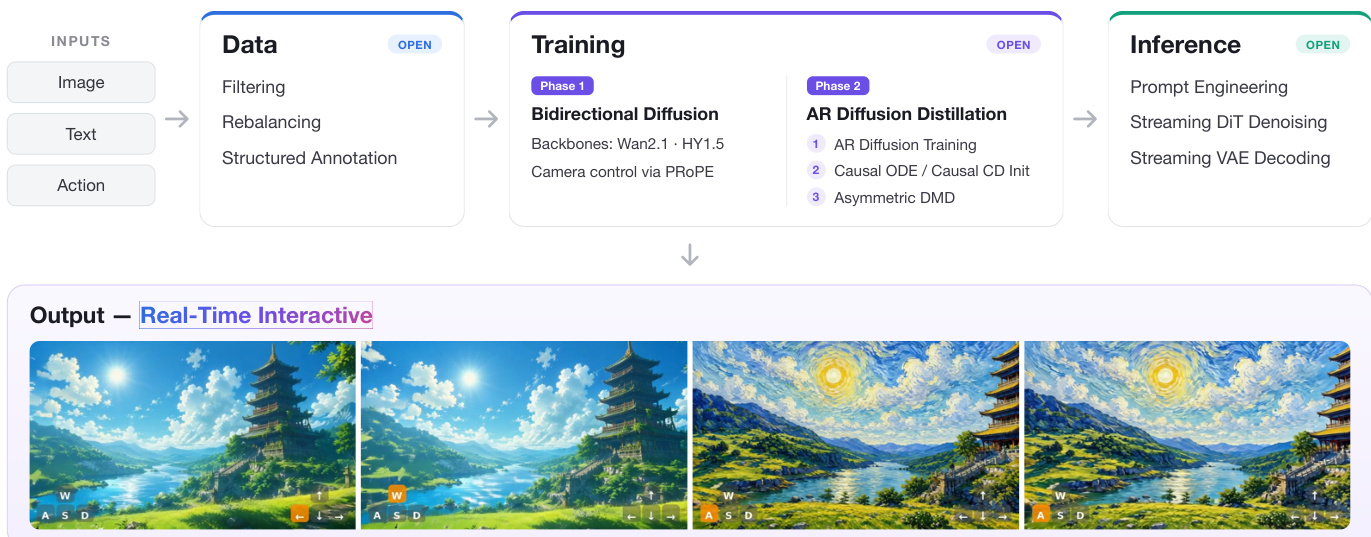
如图所示,训练阶段分为两个步骤。阶段一在微调后的模型上进行双向扩散训练,通过 PROPE 集成相机控制。该阶段使模型能够在保持原始自注意力结构的同时,具备基于相机轨迹进行条件生成的能力。阶段二为自回归扩散蒸馏(AR Diffusion Distillation),应用 Causal Forcing 或 Causal Forcing++ 流水线将双向模型转换为实时交互式自回归模型。该阶段包含自回归扩散训练、因果 ODE 或因果一致性蒸馏初始化,以及非对称 DMD 后训练。最终阶段为推理,支持流式 VAE 解码与提示词工程,从而实现实时交互式视频输出。该框架具备模块化与可扩展特性,支持将现有模型适配至新数据分布与延迟目标。
实验
评估环节使用具备少步蒸馏功能的自回归框架训练两个基础视频生成模型,以检验推理效率与相机控制能力。定性结果表明,该方法显著降低了首帧延迟,使生成过程中的播放更加流畅,同时成功保留了相机控制能力。消融实验进一步表明,稳健的相机控制依赖于高质量的真实轨迹数据、充足的训练迭代次数以及确保优化稳定性的最小批次大小。
本文对比了基于两种不同基础模型的多步双向模型与少步自回归模型的首帧延迟及加速比。结果表明,少步自回归模型显著降低了首帧延迟,并在保持相机控制生成能力的同时,相比多步双向基线实现了大幅加速。与多步双向模型相比,少步自回归模型在首帧延迟上实现了显著降低。针对两种基础模型,少步自回归模型均相比多步双向基线提供了显著的加速效果。尽管延迟得到改善,少步自回归模型仍完整保留了相机控制生成能力。
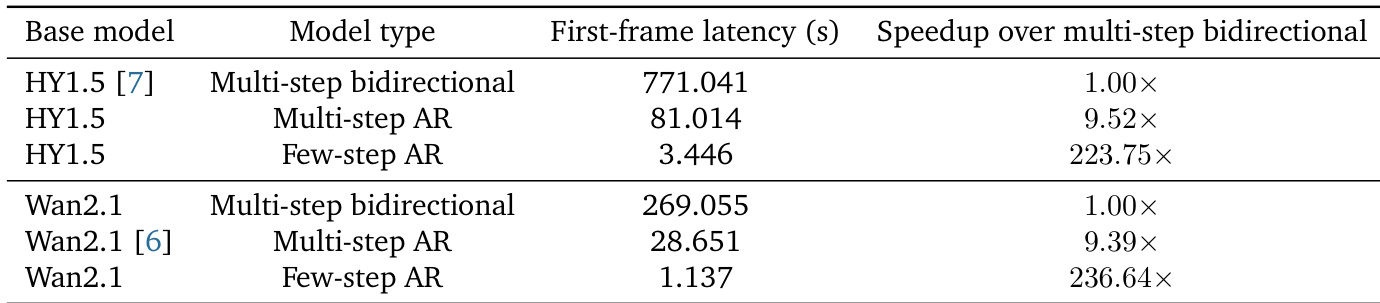
评估环节对比了两种不同基础模型上多步双向模型与少步自回归架构的初始生成延迟与处理速度。结果表明,少步自回归方法大幅加速了首帧生成并提升了整体推理效率。重要的是,这些性能提升是在成功保留模型相机控制生成能力的前提下实现的。