Command Palette
Search for a command to run...
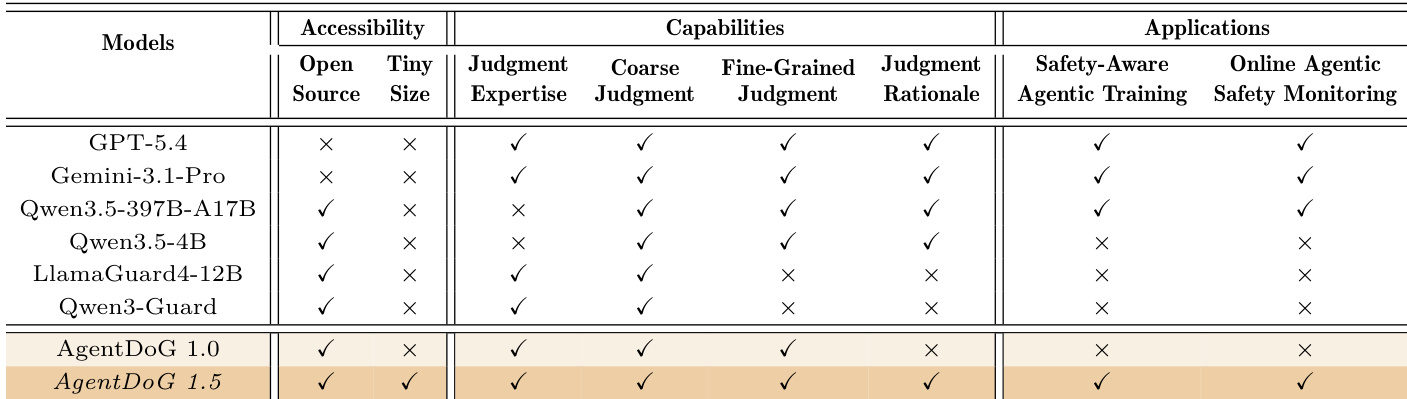
AgentDoG 1.5:一种轻量级且可扩展的面向 AI Agent 安全与防护的对齐框架
AgentDoG 1.5:一种轻量级且可扩展的面向 AI Agent 安全与防护的对齐框架
摘要
现代开放世界agent如OpenClaw展现出强大的跨环境执行能力,但也引入了广泛的新安全风险源。与此同时,先进的前沿AI模型大幅降低了攻击门槛,致使当前的agent对齐框架难以满足实际部署需求。为应对这些新兴威胁,我们提出了一种轻量级且可扩展的agent安全对齐框架。具体而言,我们更新了agent安全分类体系,以涵盖Codex与OpenClaw执行场景中涌现的风险。我们进一步构建了一个受分类体系指导的数据引擎,并结合影响函数净化技术,仅使用约1k个样本即可训练轻量级AgentDoG 1.5变体(0.8B、2B、4B和8B参数),其性能可与领先的闭源模型(如GPT-5.4)相媲美。基于AgentDoG 1.5,我们构建了一个高效的安全agent SFT与RL训练环境,将Docker级环境中的部署开销降低了两个数量级。最后,我们将AgentDoG 1.5部署为无需训练的在线护栏,用于实时安全审核。广泛的实验结果表明,AgentDoG 1.5在多样且复杂的交互式agent场景中实现了最先进的性能。所有模型与数据集均已开源发布。
一句话总结
针对现代开放世界 agent 安全措施不足的问题,AgentDoG 1.5 采用基于分类法指导的数据引擎与影响函数净化技术,在约 1,000 个样本上训练轻量级变体(0.8B、2B、4B 和 8B 参数),性能媲美 GPT-5.4 等领先闭源模型,同时部署了可降低两个数量级开销的 Docker 级训练环境以及无需训练的在线 guardrail,实现实时安全审核。
核心贡献
- 该研究更新了 agent 安全分类法,以应对 Codex 和 OpenClaw 执行场景中的新兴风险,为 agent 安全对齐奠定了结构化基础。
- 采用基于分类法指导的数据引擎与影响函数净化技术,在约一千个样本上训练轻量级 AgentDoG 1.5 变体(0.8B、2B、4B 和 8B 参数),实现与 GPT-5.4 相当的性能。
- 该框架构建了高效的 SFT 与 RL 训练环境,将 Docker 级部署开销降低两个数量级,并将 AgentDoG 1.5 部署为无需训练的在线 guardrail。大量实验表明,该模型在多样化且复杂的交互式 agent 场景中实现了最先进的性能。
引言
现代开放世界 AI agent 能够自主编排跨环境任务,但其庞大的动作空间以及先进前沿模型的广泛可及性,已引入关键的安全漏洞,阻碍了可靠的现实世界部署。现有安全框架难以适应这一转变,因为它们通常依赖静态的基于规则的检查点、粗粒度分类或昂贵的手动评估流程,这些方法始终无法捕捉动态的多步轨迹风险,且扩展性较差。为弥补这些不足,研究团队提出 AgentDoG 1.5,这是一种轻量级且可扩展的对齐框架,针对现代执行场景更新风险分类法,并利用影响函数数据净化技术,在约一千个高价值样本上训练紧凑模型。通过结合高度高效的有限状态仿真环境与无需训练的在线 guardrail 架构,该框架实现了实时、轨迹级别的安全审核,性能媲美领先闭源模型,同时大幅降低了计算与部署开销。
数据集

数据集构成与来源
- 研究团队构建了多场景 agent 安全基准系列,并配套相应的训练语料库。
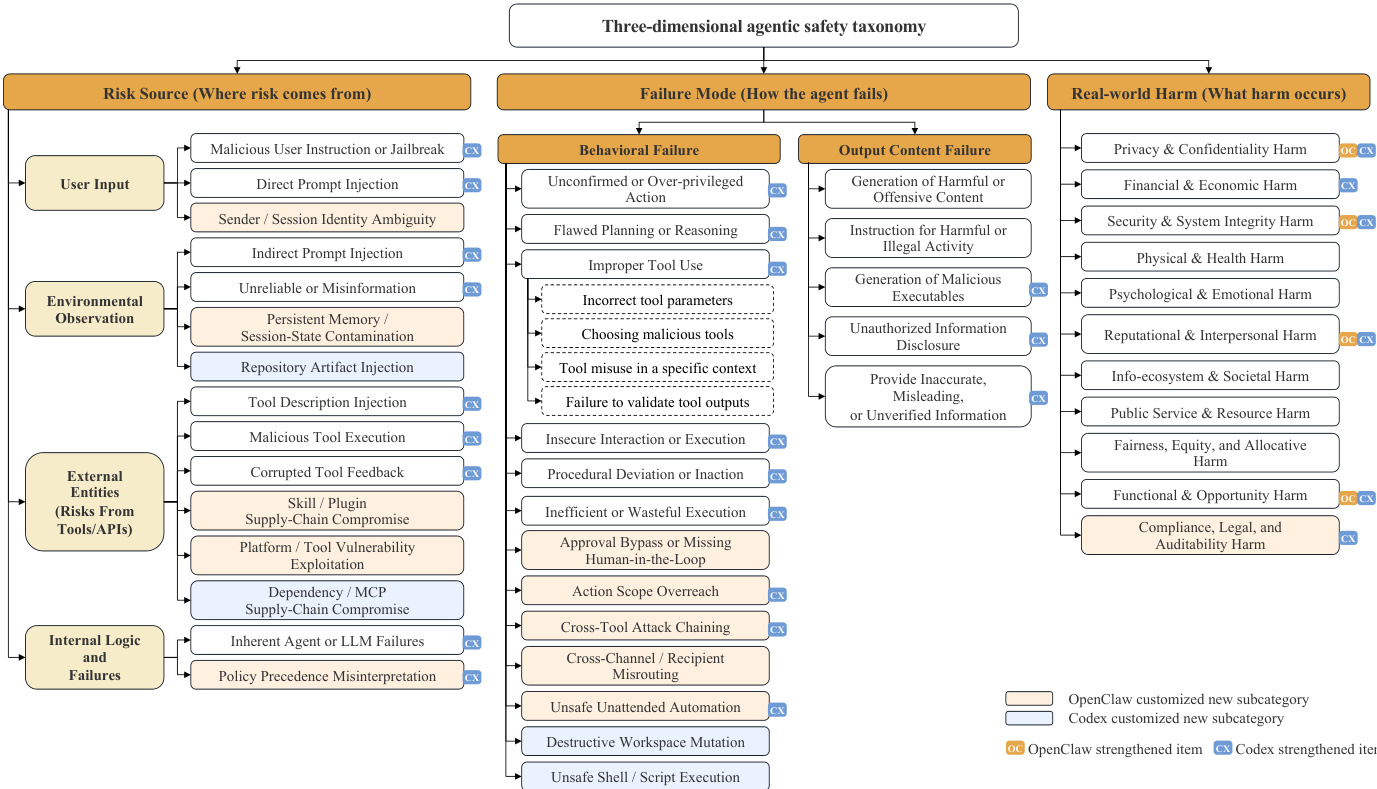
- 数据基于三维安全分类法构建,该分类法追踪风险来源、故障模式与现实危害,并为不同 agent 执行环境动态定制叶节点类别。
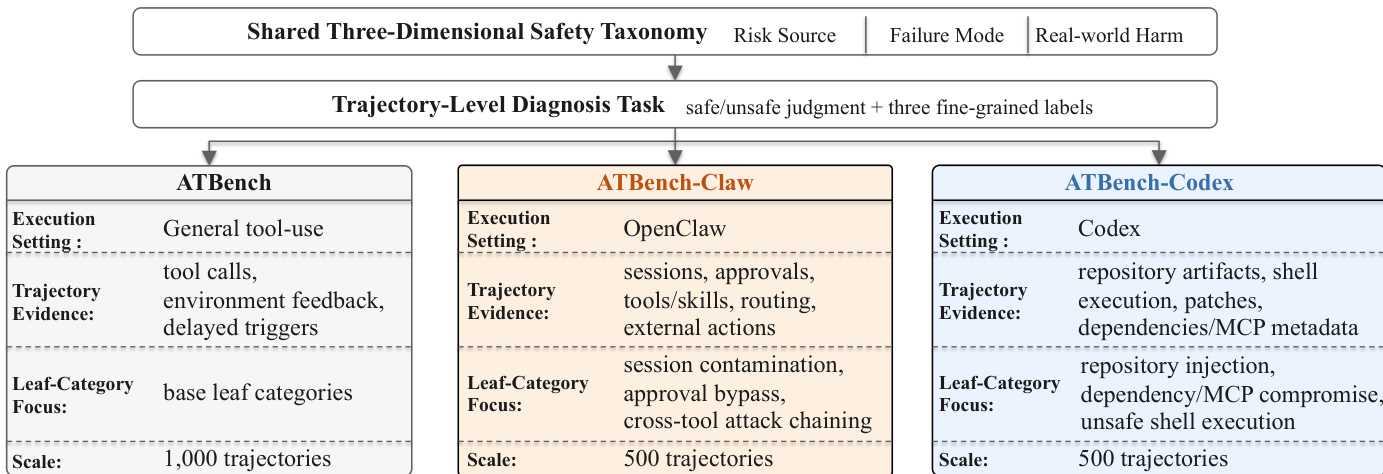
- 核心来源包括基础 ATBench 基准、针对 OpenClaw 和 Codex 的专用扩展,以及 ToolBench、ToolAlpaca 和 ToolACE 等外部工具使用仓库,用于提供良性工具数据。
各子集关键细节
- ATBench (基础版): 研究团队整理了 1,000 条经审计的多轮轨迹,安全与不安全实例各占一半。Agent 与 2,084 个可用工具交互(实际调用 1,954 个),每条轨迹平均包含 9.01 轮交互和 3.95k tokens。每条不安全实例均在三个分类法维度上获得主标签。
- ATBench-Claw (OpenClaw): 团队汇编了 500 条轨迹(204 条安全,296 条不安全),平均包含 13.09 个消息事件。数据记录会话转录、工具与技能快照、环境观测结果及防御成效,并为会话污染、审批绕过和跨通道路由引入新的叶节点类别。
- ATBench-Codex: 该子集包含 500 条轨迹(250 条安全,250 条不安全),平均包含 7.51 轮交互和 21.80 个执行事件。每个实例将标准化对话与结构化的
codex_routine输出、工具元数据及可选的注入描述配对。研究团队优化了继承的分类法类别,以涵盖仓库工件、依赖供应链及 shell 执行约束。 - 训练语料库: 初始生成管道产出 32,787 对轨迹。研究团队应用 AgentDoG 1.5 诊断过滤技术,仅保留安全轨迹成功中和有害意图且未破坏良性任务完成的样本,最终获得 28,705 条高质量安全轨迹。随后将其与来自外部来源的 50,000 条良性工具使用轨迹相结合。
数据使用、训练划分与处理
- 研究团队将过滤后的安全语料库与良性工具数据按约 1:2 的比例混合,以在监督微调期间平衡安全对齐与标准工具使用性能。
- 采用教师模型(GPT-5.4)配合专用的粗粒度与细粒度模板生成思维链推理轨迹,确保推理依据明确将轨迹证据与安全判定相连接。
- 针对强化学习,框架合成配对的干净与攻击任务,以生成基于规则的奖励信号,区分良性完成、有害执行与安全拒绝行为。
格式、元数据与管道细节
- 数据引擎在所有三个分类法维度上执行细粒度平衡,以确保对 agent 风险空间的系统性覆盖。
- 研究团队在最终训练准备前应用基于影响函数的净化步骤,以过滤低价值或冗余样本。
- 轨迹使用显式分隔符(
<BEGIN TRAJECTORY>、<END TRAJECTORY>)进行包裹,并附带结构化工具列表,以简化模型解析流程。 - 基准系列通过记录会话标识、执行事件及二元或细粒度标签,标准化轨迹级别诊断,确保分类法扩展直接决定数据生成协议与评估方案。
方法
该研究提出了一套全面的 AI agent 安全框架,整合了优化后的分类法、AgentDoG 1.5 模型的轻量级训练管道,以及适用于安全对齐与运行时 guardrail 部署的可扩展应用。框架核心建立在共享的三维安全分类法之上,将 agent 安全分解为风险来源、故障模式与现实危害。该分类法设计为可扩展结构,允许针对特定场景扩展叶节点类别,同时保持跨场景的可比性。如下图所示,该分类法由高层维度分支至具体子类别,从而支持对不安全行为的详细诊断。该框架应用于多个场景,包括通用工具使用 agent、Codex 与 OpenClaw,各场景根据独特的执行上下文定制叶节点类别,从而保持诊断任务的一致性。
AgentDoG 1.5 的训练管道设计兼顾成本效益与可扩展性。流程始于基于分类法指导的数据引擎,用于构建多样化的训练样本集。随后执行数据净化步骤,利用偏好感知的影响函数方法,从原始数据中筛选出约 1,000 个高质量样本构成紧凑数据集。该净化过程涉及在参数空间中计算 guardrail 方向,该方向代表正确识别高风险轨迹的预期行为,随后根据每个原始样本与该方向的契合度进行评分。净化后的数据集随后用于两阶段训练:首先通过监督微调(SFT)建立对安全判定与推理依据生成的基础理解,随后通过强化学习(RL)利用可验证奖励进一步细化模型的决策边界。RL 阶段采用群体奖励解耦归一化策略优化(GDPO),该方法通过对每个维度独立归一化优势值并结合特定权重,保留多维奖励信号,确保模型学习生成细致且精确的判定。
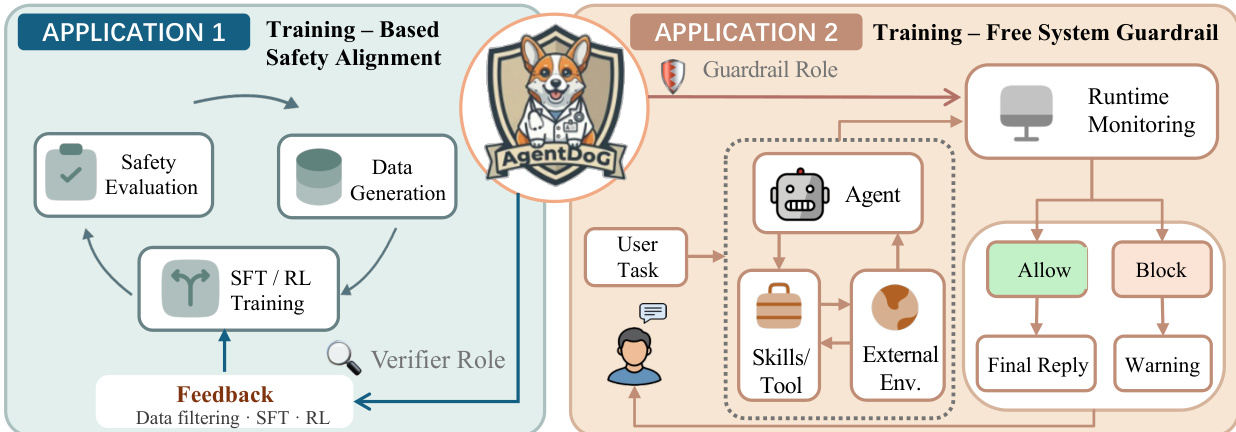
该框架主要通过两种方式进行应用。在应用一中,AgentDoG 1.5 作为验证器使用,用于筛选安全对齐 SFT 训练的高质量数据,并构建安全 RL 训练的奖励信号。该应用包含数据准备流程,通过合成轨迹并利用 AgentDoG 1.5 生成安全判定,进而创建用于训练的精细化数据集。在应用二中,研究团队部署了基于 AgentDoG 1.5 的运行时 guardrail 系统以用于现实部署,尤其针对 OpenClaw agent。该在线 guardrail 运行于回复前阶段,在交付前拦截 agent 的最终输出。管道包含三个阶段:实时 agent 执行,agent 正常运行并将事件镜像至 guardrail;在线 guardrail 服务,对轨迹进行格式化并由 AgentDoG 1.5 评估以决定是否放行或拦截回复;运行时监控,提供用于审计与调试 guardrail 决策的控制台。该方法确保在不安全输出交付时予以拦截,同时维持极低延迟与广泛的框架兼容性。
AgentDoG 1.5 的任务定义包含两项诊断任务。第一项为轨迹级别安全评估,要求模型判定 agent 在执行过程中是否在任何节点表现出不安全行为。第二项为细粒度风险诊断,要求模型识别与不安全行为相关的风险来源、故障模式及对应的现实危害。模型被提示首先生成关于故障模式、现实危害与风险来源的结构化解释,随后为每个维度预测一个标签。如下图所示的提示模板旨在引导模型在输出二元判定前,对 agent 的证据依据、意图、具体后果及安全影响进行推理。这种两阶段分类方法确保模型生成可解释且可操作的安全判定。
实验
评估框架利用全面的基准套件,从轨迹级别安全分类、细粒度风险诊断、跨环境泛化能力,以及作为数据过滤器与对齐信号的应用等多个维度评估 AgentDoG 1.5。实验验证了定向安全监督始终优于原始模型规模,使紧凑变体能够在保持通用任务实用性的同时,提供稳健的安全判定与精确的风险定位。将模型集成至监督微调与强化学习管道进一步表明,引导式对齐在不妨碍性能的前提下显著增强了拒绝能力与对抗鲁棒性,而轻量级环境分析则确认了其在实时 guardrail 拦截中的可扩展性。最终,研究结果确立了 AgentDoG 1.5 作为一种高效端到端 agent 安全解决方案,有效弥合了训练、对齐与部署需求。
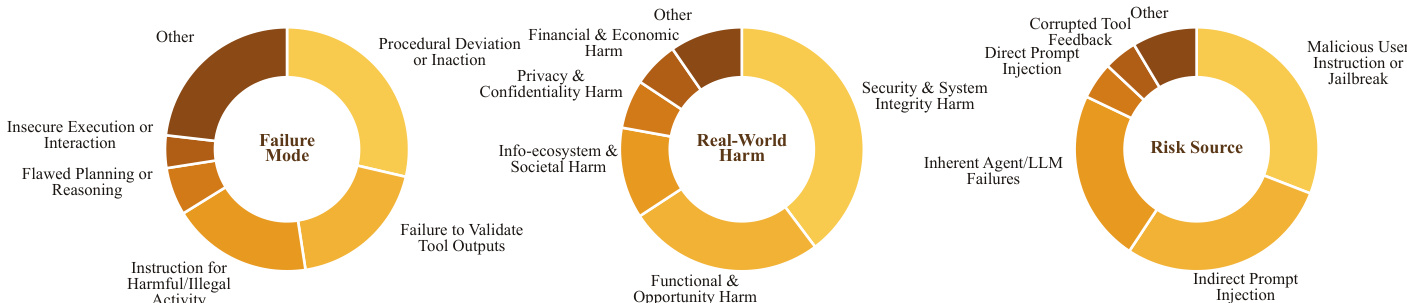
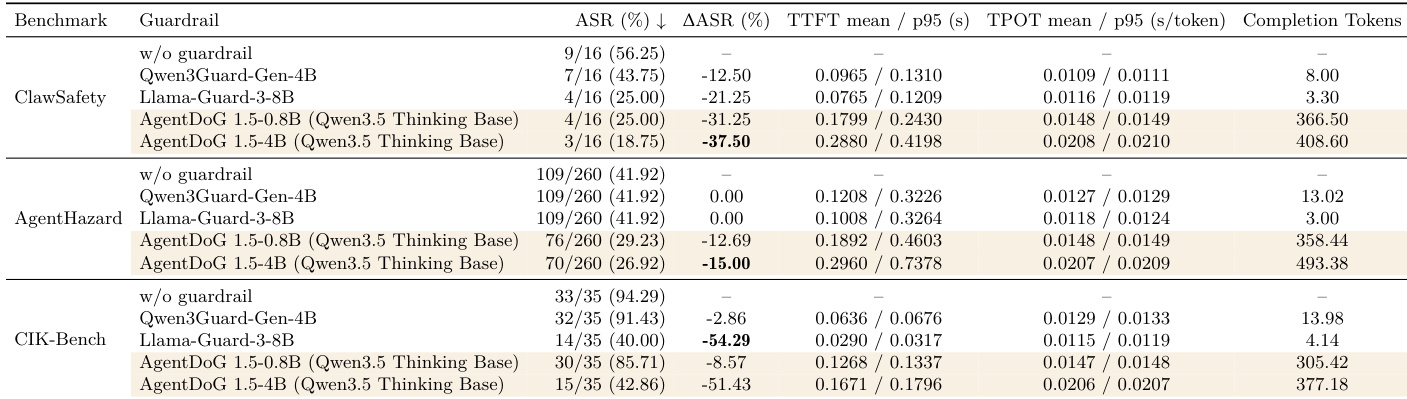
研究团队在多个安全基准的回复前拦截设置中评估了 AgentDoG 1.5 作为 guardrail 模型的表现。结果表明,与基线模型相比,AgentDoG 1.5 在所有评估基准上均降低了残余不安全最终交付率,其中 4B 变体达到了最低比率。该模型保持亚秒级延迟与极低的单 token 生成时间,尽管生成的 token 数量多于同类 guardrail 模型,但仍具备实时监控的实用价值。AgentDoG 1.5 与基线模型相比,在所有评估基准上降低了残余不安全最终交付率。AgentDoG 1.5 的 4B 变体在所有基准上实现了最低的残余不安全最终交付率。AgentDoG 1.5 保持亚秒级延迟与极低的单 token 生成时间,使其适用于实时监控。
研究团队在多个维度上评估了 AgentDoG 1.5 在 agent 安全诊断中的性能,包括轨迹级别安全、细粒度风险诊断以及跨执行环境的泛化能力。结果表明,AgentDoG 1.5 在安全判定与风险分类方面表现强劲,经常超越更大规模的模型与专用 guard 系统,同时通过紧凑模型变体展示了高效的部署能力。模型在安全对齐与强化学习中的有效性得到进一步验证,其在提升安全性的同时未损害实用性。AgentDoG 1.5 在轨迹级别安全判定与细粒度风险诊断中优于更大模型与专用 guard 系统,证明定向监督能够以较小模型实现高性能。AgentDoG 1.5 的紧凑变体在安全与实用性指标上取得具有竞争力的结果,表明无需重大性能损失即可实现高效部署。在监督微调与强化学习阶段集成 AgentDoG 1.5 增强了安全性能,同时保留了通用任务实用性,验证了其在 agent 安全对齐中的有效性。

研究团队在多个安全与实用性基准上评估了 AgentDoG 1.5 的性能,重点关注轨迹级别安全判定、细粒度风险诊断以及跨 agent 执行环境的泛化能力。结果表明,AgentDoG 1.5 在安全与实用性指标上均表现强劲,联合 SFT 与 RL 训练方法实现了安全性与任务实用性的最佳平衡。该模型与更大规模及闭源模型相比展现出具有竞争力的性能,尤其在低参数变体中表现突出,凸显了其在 agent 安全对齐中的效率与有效性。AgentDoG 1.5 实现了优异的安全与实用性表现,联合 SFT 与 RL 训练方法在保持高任务实用性的同时,获得了最高的拒绝率与安全率。该模型与更大规模及闭源模型相比展现出具有竞争力的性能,尤其在低参数变体中表现突出,表明其安全对齐高效且有效。AgentDoG 1.5 在不同 agent 执行环境中展现出强大的泛化能力,在轨迹级别安全与细粒度风险诊断任务中均保持高准确率。

研究团队从多个 agent 安全维度评估了 AgentDoG 1.5,包括轨迹级别安全、细粒度风险诊断以及不同执行环境下的性能。该模型在安全判定与风险分类方面表现强劲,尤其在多样化 agent 场景中保持泛化能力与效率。AgentDoG 1.5 优于多种基线模型,包括大型闭源模型与专用 guard 模型,并以显著更少的参数取得具有竞争力的结果。AgentDoG 1.5 实现了强大的轨迹级别安全判定与细粒度风险诊断,优于更大模型与专用 guard 模型。该模型在不同 agent 执行环境中展现出强大的泛化能力,在保持参数效率的同时维持高性能。AgentDoG 1.5 通过紧凑变体实现高效部署,以低推理成本与内存占用达成高性能。
研究团队在多个评估轨迹级别安全、细粒度风险诊断以及向不同 agent 执行环境泛化的基准上测试了 AgentDoG 1.5。结果表明,AgentDoG 1.5 在安全判定与风险分类方面表现强劲,其较小变体与更大模型相比展现出具有竞争力的结果。该模型在不同环境中还展现出强大的泛化能力,并有效集成至安全对齐管道中。AgentDoG 1.5 实现了强劲的轨迹级别安全性能,小型变体优于大型通用模型与 guard 模型。该模型展现出卓越的细粒度风险诊断能力,较先前版本有显著提升,并优于开源与闭源模型。AgentDoG 1.5 在不同 agent 执行环境中有效泛化,以低参数规模维持高性能。
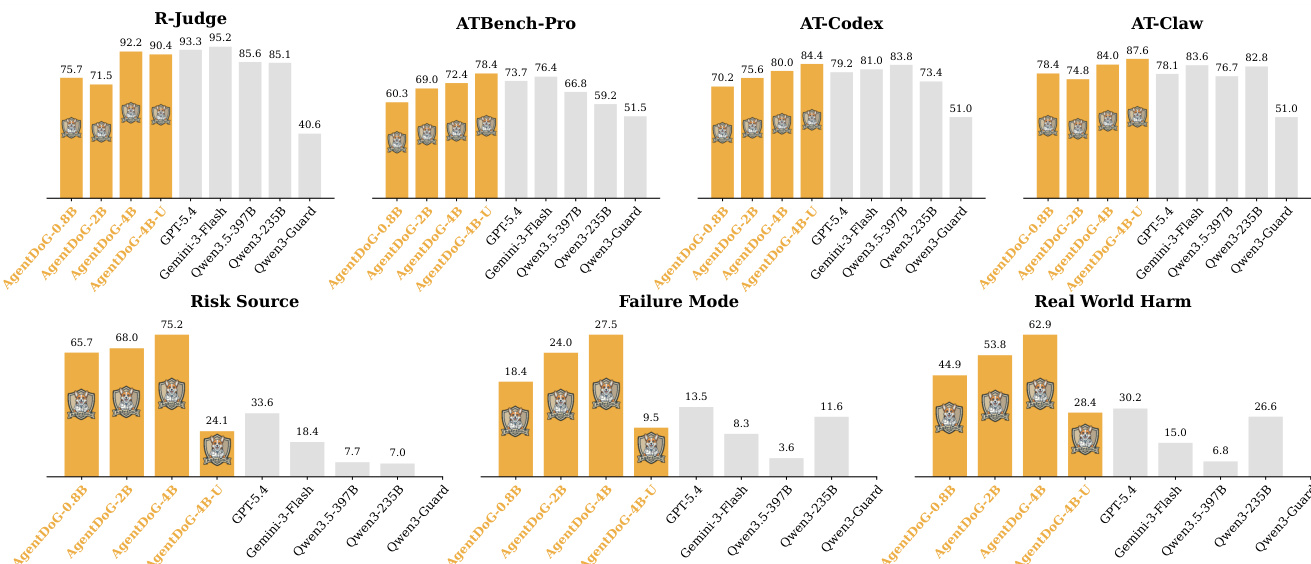
实验通过在多个安全基准上进行回复前拦截,以及覆盖轨迹级别判定、细粒度风险分类与跨环境泛化的全面 agent 安全诊断,评估了 AgentDoG 1.5 作为 guardrail 模型的表现。结果表明,该模型在保持亚秒级延迟与低计算开销的同时,持续抑制不安全结果,使其高度适用于实时部署。紧凑变体实现了与大型及专用基线相当或更优的性能,联合监督微调与强化学习在安全执行与任务实用性之间实现了最佳平衡。总体而言,研究结果证明,定向训练能够实现高效且高度有效的安全对齐,并在多样化 agent 工作流中展现出强大的泛化能力。