Command Palette
Search for a command to run...
GrepSeek:用于直接语料库交互的搜索 Agents 训练
GrepSeek:用于直接语料库交互的搜索 Agents 训练
Alireza Salemi Chang Zeng Atharva Nijasure Jui-Hui Chung Razieh Rahimi Fernando Diaz Hamed Zamani
摘要
大型语言模型(LLM)搜索 agents 通过多轮推理与信息检索,在知识密集型语言任务中展现出巨大的潜力。大多数现有系统通过检索器访问信息,检索器接收关键词或自然语言查询,并基于预计算文档表示的索引返回排序后的文档列表。在本研究中,我们探索了一种互补视角,即搜索 agent 将语料库本身视为搜索环境,并通过执行可运行的 shell 命令来寻找证据。我们提出了 GrepSeek,这是一种优化的直接语料库交互(DCI)搜索 agent,旨在训练一个轻量级搜索 agent 从大型文本语料库中查找、过滤并组合证据。为解决直接在大型语料库上使用强化学习进行行为训练的不稳定性问题,我们提出了一种两阶段训练流程。首先,我们利用答案感知型 Tutor 与答案盲视型 Planner 构建冷启动数据集,以生成经过验证且具备因果依据的搜索轨迹。其次,我们采用组相对策略优化(GRPO)对初始化策略进行微调,使 agent 能够通过直接与语料库交互来优化其面向任务的搜索行为。为实现 DCI 的大规模实用化,我们进一步采用了一种保持语义的分片并行执行引擎。该引擎在保持与 shell 命令顺序执行完全一致的字节级等价性的前提下,将基于 shell 的检索速度最高提升了 7.6imes 倍。在七个开放域问答基准上的实验表明,GrepSeek 取得了最强的整体 token 级 F1 与 Exact Match 指标。我们的分析还揭示了纯词汇交互在处理具有显著表层形式变化的查询时所存在的局限性,这表明 DCI 是一种实用且具备竞争力的搜索 agent 方法,能够在现实世界中补充现有的检索范式。
一句话总结
GrepSeek 是一种直接语料库交互搜索 Agent,它使用可执行的 Shell 命令替代传统的基于索引的检索方法。该系统采用两阶段训练流水线,首先利用感知答案的 Tutor(导师)和盲视答案的 Planner(规划器)生成经过验证的轨迹,随后通过组相对策略优化(Group Relative Policy Optimization)细化策略。整个流程由一个保留语义的切片并行执行引擎加速,以实现可扩展的证据检索。
核心贡献
- 本文提出 GrepSeek,一种直接语料库交互搜索 Agent,通过可执行的 Shell 命令替代传统的基于嵌入的检索器,从原始文本语料库中定位、过滤并综合证据。
- 两阶段训练流水线通过感知答案的 Tutor 和盲视答案的 Planner 生成经过验证的搜索轨迹,随后利用组相对策略优化细化策略,从而稳定大型语料库上的强化学习过程。
- 保留语义的切片并行执行引擎将基于 Shell 的检索速度提升高达七倍。在单跳与多跳问答基准上的实证评估表明,该方法增强了面向任务的推理能力与证据组合效果。
引言
大型语言模型搜索 Agent 正日益应用于需要多步推理及跨海量文本集合进行证据综合的复杂知识密集型任务。传统检索增强系统依赖预计算的文档索引,这往往会引发语义混淆与僵化的分块边界,从而破坏精确的实体匹配与细粒度词汇过滤。尽管近期的直接语料库交互方法通过在原始数据上执行 Shell 命令绕过了这些索引,但其推理阶段严重依赖提示大型专有模型,导致计算成本高昂、响应缓慢,且为紧凑型 Agent 带来不稳定的强化学习轨迹。为突破上述局限,本文提出 GrepSeek,一种经过训练的开源权重搜索 Agent,通过学习确定性 Shell 操作直接与非结构化语料库交互。研究采用逆向链式 Tutor 与前向 Planner 框架稳定策略开发,利用组相对策略优化细化搜索行为,并实现保留语义的切片并行执行引擎,将检索延迟降低高达 7.6 倍。该集成方案将直接语料库交互转化为可扩展、低延迟的索引检索替代方案,在多跳推理基准上实现具有统计学显著性的性能提升,同时保持字节级精确的词汇精度。
数据集

- 数据集构成与来源:研究团队在来自 FlashRAG 仓库的七个标准化知识密集型问答基准上评估该方法。数据集划分为用于定向事实检索的单跳任务与用于迭代语料库探索的多跳任务。所有评估均基于 2018 年维基百科转储数据,包含 2100 万份文档,格式为单个 JSONL 文件。
- 各子集关键细节:
- Natural Questions (NQ):开放域划分,包含真实用户查询,需在无先验上下文的情况下匹配维基百科段落以回答问题。
- TriviaQA:精心策划的常识问答,答案通常包含在单个检索文档中。
- PopQA:基于 Wikidata 三元组构建的以实体为中心的数据集,专门针对罕见实体以测试长尾知识检索能力。
- HotpotQA:多跳问题,旨在强制模型在至少两篇独立的维基百科文章间进行推理。
- 2WikiMultihopQA:利用 Wikidata 属性构建,强制在多篇文档间建立明确的逻辑链与严格的推理步骤。
- MuSiQue:经过严格过滤的多跳数据集,通过串联单跳问题消除捷径推理与词汇重叠。
- Bamboogle:手工设计的问题,旨在击败标准搜索引擎,要求深度的多步证据收集。 训练集与评估集的确切规模记录于附录表格中。
- 数据使用方式:训练阶段仅使用 NQ 与 HotpotQA 的官方训练集,其余五个数据集作为分布外评估集。对于监督微调,研究团队构建了一个包含 10,000 个样本的冷启动数据集,采用 HotpotQA 与 NQ 示例的平衡混合,训练一个 epoch。该策略随后在全量 HotpotQA 与 NQ 训练集上通过 GRPO 强化学习进行 200 步优化。评估阶段在官方测试集上报告 token 级 F1 分数,仅在测试标签不可用时回退至开发集,精确匹配分数提供于附录。
- 处理细节:流水线摒弃传统的裁剪或元数据提取,将整个维基百科语料库视为平面文本文件,每行代表一个段落。系统提示词强制采用基于 Shell 的交互策略,指示模型通过
head -n 3或head -n 8等命令对搜索结果进行管道处理,以限制输出量并防止上下文溢出。在数据构建期间生成合成多轮轨迹,用于教授模型在纯文本推理步骤与单管道 Shell 命令之间交替执行。所有基准均通过 FlashRAG 进行标准化,以确保格式与评估协议的一致性。
方法
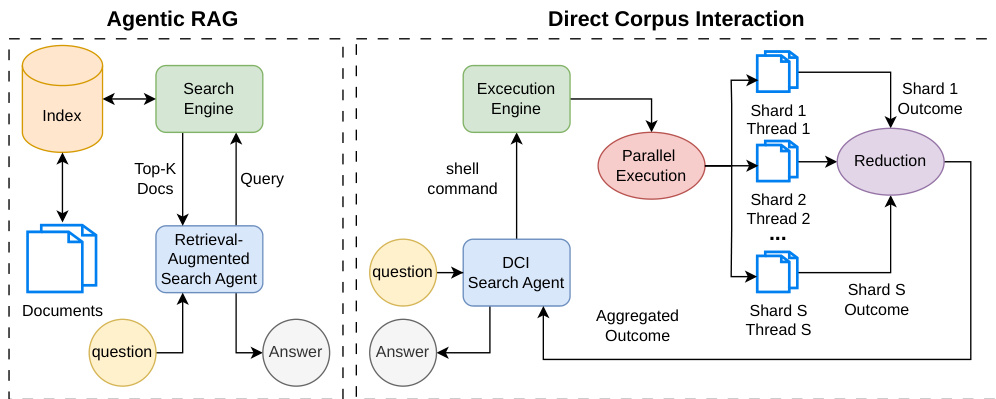
研究团队采用两阶段训练框架开发 GrepSeek,这是一种直接语料库交互(DCI)搜索 Agent,在 ReAct 框架内运行。该机制使其能够通过直接向原始文本语料库下发可执行的 Shell 命令,执行多跳推理与信息检索。框架图所示的整体架构与传统依赖预计算索引的检索增强生成(RAG)系统形成对比。DCI Agent 通过 grep 和 rg 等 Shell 命令序列与语料库交互,以查找、过滤并组合证据。该 Agent 的策略表示为 πθ,根据问题及历史交互记录生成包含推理轨迹与动作的轨迹。动作类型为 Shell 命令或输出最终答案的终止操作,执行引擎返回的观察结果将指导后续步骤。
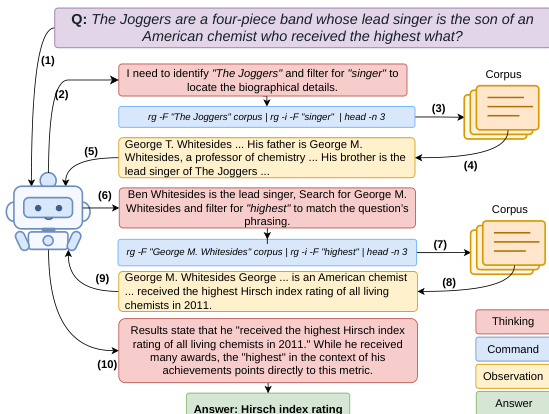
训练流程始于高质量冷启动数据集的构建,旨在稳定初始策略。该过程通过两阶段流水线实现,利用感知答案的 Tutor LLM 与盲视答案的 Planner LLM 生成经过验证且具备因果基础的搜索轨迹。在逆向阶段,Tutor 将查询与标准答案分解为子查询序列,随后逆向生成每个子查询对应的 Shell 命令,并通过掩码处理答案及其同义词确保命令不泄露答案。Tutor 迭代优化命令并验证检索文档是否支持目标答案,从而构建多跳证据链。该证据链随后被反转以符合时间顺序。在正向阶段,盲视答案的 Planner 仅基于因果历史生成推理轨迹与动作提议,Tutor 随后将其与验证过的命令对齐,确保推理过程扎根于可观测证据。该流程产出兼具真实性与可靠性的轨迹。
生成冷启动数据后,策略首先在合成轨迹上进行监督微调(SFT),以初始化稳定且具备因果基础的检索行为。SFT 阶段教导 agent 生成简洁命令并避免过度检索上下文。完成 SFT 后,策略进一步通过组相对策略优化(GRPO)进行优化。针对每个查询,策略采样五个轨迹组成的组,每个轨迹根据预测答案与标准答案之间的 token 级 F1 分数获得奖励,并结合一个验证轨迹结构有效性的二元格式指示器。GRPO 算法计算组内的相对优势,鼓励表现优于同查询其他轨迹的样本,同时降低对奖励尺度的敏感性。这种结合合成数据生成与 GRPO 的两阶段方法,解决了直接在大型语料库上使用强化学习导致的训练不稳定问题。

为实现 DCI 的规模化应用,系统采用切片并行执行引擎,在保持与顺序执行字节级等价的前提下,将基于 Shell 的检索速度提升高达 7.6×。该引擎对语料库执行一次性按行对齐的切片操作,将其划分为 S 个不相交分区。推理阶段,兼容的 Shell 管道通过线程池在 S 个分片上并行执行。引擎动态分类每个管道以判断其是否可安全并行。完全由无状态转换组成的管道(如 cut、tr、逐行 sed)在各分片上独立评估。最终输出通过特定策略的归约规则重建,例如纯无状态管道采用确定性拼接,Top-K 检索管道采用 k 路合并。该方法显著提升检索吞吐量,同时确保与顺序执行的行为等价性。系统进一步通过持久化搜索守护进程降低延迟,该进程将语料库保留在内存中,避免在连续工具调用时重复启动进程与加载语料库。
实验
实验在七个开放域问答基准上进行划分,严格区分分布内与分布外数据。研究通过性能对比、效率分析、消融实验与定性案例审查,评估 GrepSeek 与密集检索及稀疏检索基线的差异。评估结果验证了通过 Shell 命令进行直接语料库交互在精确词汇匹配与迭代证据过滤方面的优势,大幅提升多跳推理与实体消歧能力,同时显著降低内存与索引开销。然而,该方法本质上缺乏语义排序能力,且易受表面形式变化的影响,这在一定程度上限制了其在广泛改写查询中的有效性。最终结果表明,结构化、可解释的基于 Shell 的检索为复杂推理任务提供了高精度且资源高效的嵌入驱动系统替代方案。
消融实验评估了不同训练阶段对 GrepSeek 在单跳与多跳基准上性能的影响。结果表明,监督微调(SFT)与强化学习(GRPO)阶段均至关重要,移除任一步骤均会导致性能显著下降。不含 GRPO 的模型在所有数据集上表现均逊于完整模型,而不含 SFT 的变体退化最为严重,尤其在多跳任务中。完整模型取得最高平均分,证明两阶段对有效检索与推理的必要性。移除监督微调或强化学习阶段均会导致所有基准上的性能大幅下滑。缺乏强化学习的模型在每项数据集上表现均弱于完整模型,凸显策略优化的重要性。缺乏监督微调的变体整体性能下降幅度最大,强调强化学习前进行结构化轨迹初始化的必要性。

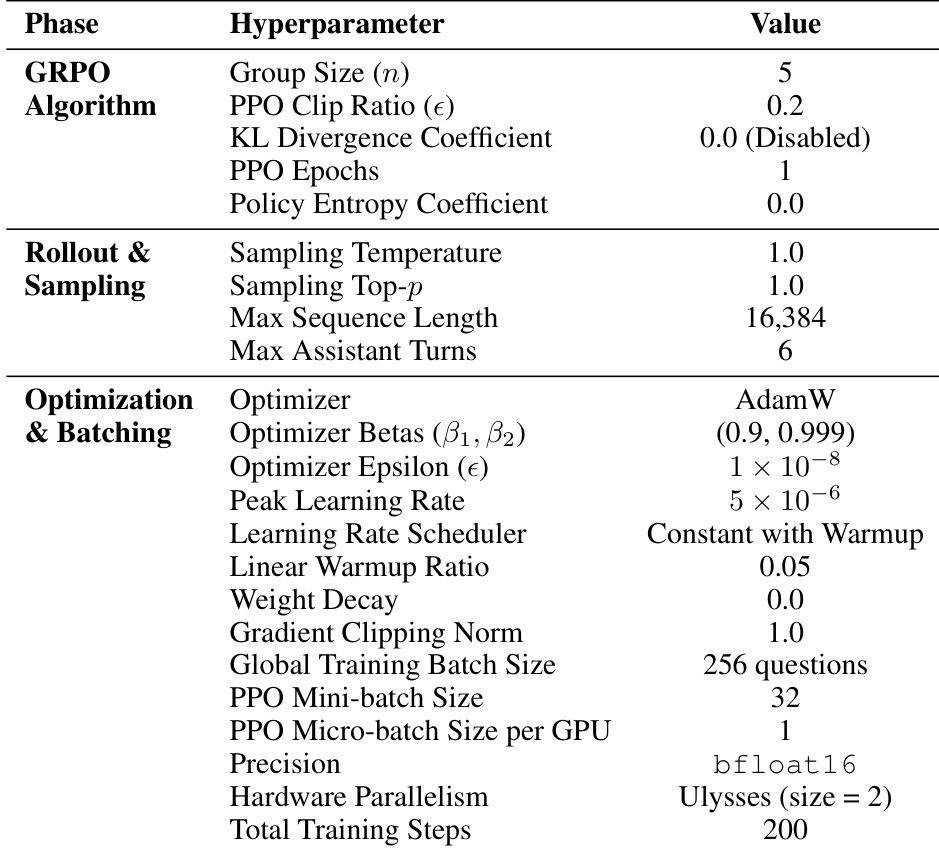
研究团队分析 GrepSeek 的强化学习配置,重点考察 GRPO 训练阶段。实验设置采用每组查询五个轨迹,PPO 裁剪比率为 0.2,并禁用 KL 散度与策略熵惩罚。推理生成阶段,系统采用采样温度 1.0 与 top-p 1.0,最大序列长度为 16,384 tokens,最多支持六轮助手交互。训练使用 AdamW 优化器,峰值学习率为 5e-6,配合线性预热与 200 步的恒定调度,采用 bfloat16 精度与 Ulysses 序列并行。GRPO 配置为每组五个轨迹,PPO 裁剪比率 0.2,不施加 KL 散度或策略熵惩罚。生成设置包含采样温度 1.0 与 top-p 1.0,最大序列长度 16,384 tokens 及六轮助手交互。训练基于 AdamW,峰值学习率 5e-6,线性预热后采用恒定调度,运行 200 步,使用 bfloat16 精度与 Ulysses 并行。
{"summary": "消融实验将 GrepSeek 与缺乏强化学习优化或监督微调的变体进行对比,表明两个训练阶段对性能均至关重要。移除任一组件均会导致所有数据集上的性能显著下降,其中缺乏监督微调造成的退化最为严重。在多跳基准上,GrepSeek 持续优于两种消融变体,说明结构化轨迹初始化与策略优化对有效检索与推理不可或缺。", "highlights": ["GrepSeek 在所有数据集上均显著优于缺乏强化学习或监督微调的变体。", "缺乏监督微调导致性能下降幅度最大,凸显其对稳定策略训练的重要性。", "GrepSeek 在多跳基准上对消融变体保持明显优势,表明两个训练阶段对复杂推理任务的价值。"]}

研究团队评估了 GrepSeek,该系统通过 Shell 命令实现直接语料库交互以增强检索推理。结果表明,相较于密集与稀疏检索基线,GrepSeek 在多跳推理任务中表现更优,主要归因于其精确的词汇过滤与迭代证据聚合能力。然而,该方法在处理语义变化与表面形式差异时存在局限,此时密集检索方法表现更佳。系统效率体现为低内存占用与无离线索引成本,但较长的推理轨迹导致推理延迟较高。GrepSeek 凭借精确词汇过滤与迭代证据聚合,在多跳推理任务上超越检索基线。系统对精确字符串匹配的依赖使其对表面形式变化敏感,导致在存在语义歧义的数据集上性能下降。GrepSeek 以极低内存消耗与无离线索引成本实现高效率,但扩展的推理过程带来较高的推理延迟。

研究团队将 GrepSeek 与多种检索增强基线进行对比,结果显示 GrepSeek 在多个基准上优于非 Agent 方法与经过训练的 Agent 方法,尤其在多跳推理任务中表现突出。尽管 GrepSeek 取得最高的整体平均性能,但在特定数据集上结果呈现分化,部分数据集性能显著提升,而另一些则略有下滑,特别是在存在词汇变化或语义歧义的场景。结果表明,通过基于 Shell 的检索进行直接语料库交互可为复杂推理提供高精度,但在表面形式变化面前可能显得脆弱。GrepSeek 在多个基准上实现最佳性能,尤其在多跳推理任务中超越非 Agent 与经过训练的 Agent 基线。在需要精确词汇匹配与迭代证据聚合的数据集上,GrepSeek 表现显著改进,但在存在语义歧义或表面形式变化的数据集上面临性能权衡。该方法依赖精确字符串匹配,对拼写差异与重音符号敏感,导致在密集检索器可通过语义相似性泛化的场景中出现失败。
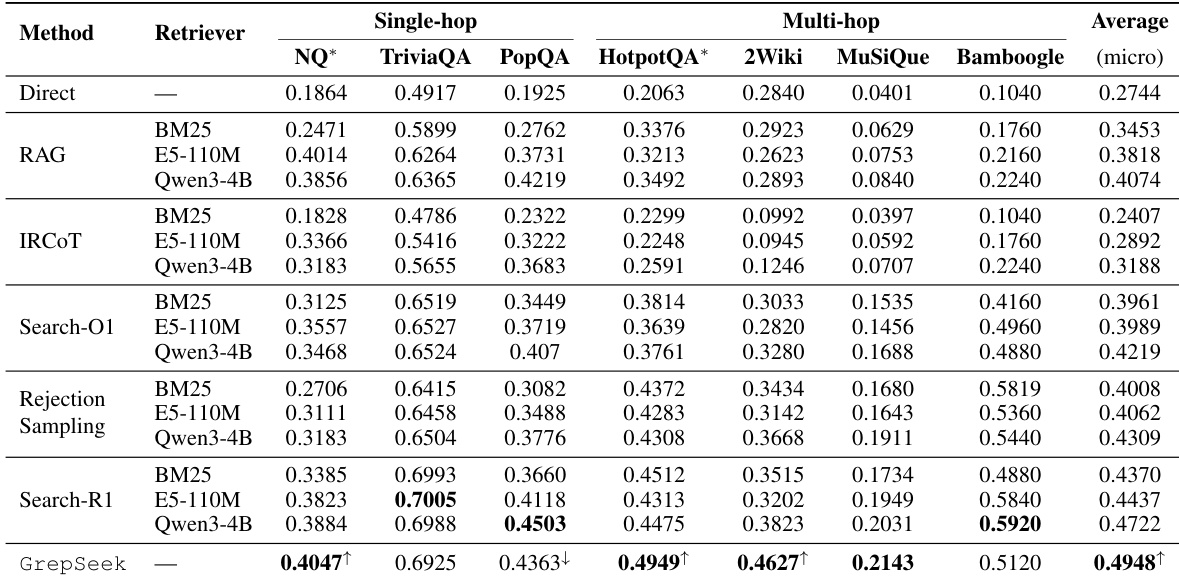
评估设置包含针对训练阶段的消融实验以及与检索基线的对比基准,旨在验证 GrepSeek 基于 Shell 的直接语料库交互方法。消融实验证实监督微调与强化学习均不可或缺,移除任一步骤均会导致性能显著下降,尤其在多跳推理任务中。对比结果表明,GrepSeek 凭借精确词汇过滤与迭代证据聚合在复杂多跳场景中表现优异,但其对精确字符串匹配的依赖使其对语义变化与表面形式差异较为敏感。总体而言,实验证明直接语料库交互能够实现高精度推理,但需通过结构化初始化与策略优化来维持其在多样化语言上下文中的鲁棒性。