Command Palette
Search for a command to run...
ResearchMath-14K:通过 Agents 扩展研究级数学
ResearchMath-14K:通过 Agents 扩展研究级数学
Guijin Son Seungyeop Yi Minju Gwak Hyunwoo Ko Wongi Jang Youngjae Yu
摘要
数学的前沿由那些尚未知晓其解的问题所界定,然而目前尚不清楚语言模型能否在无需人工干预的情况下有意义地参与此类问题。主要障碍在于缺乏大规模的研究级数学数据集。为此,我们推出了ResearchMath-14k,该数据集包含14,056个问题,通过多agent流水线从学术来源精心整理而成,使其成为迄今为止规模最大的研究级数学问题集合。我们进一步生成了ResearchMath-Reasoning数据集,其中包含来自两个开源模型的220K条教师轨迹。我们发现其中反复出现回避行为,例如未尝试解答和伪造引用。有趣的是,在八个开放权重模型中,新一代模型每条轨迹产生的引用数量多出5.6倍,伪造引用数量多出5.0倍。在对ResearchMath-Reasoning进行agent过滤后,对参数量从4B至30B的Qwen3模型进行微调,其性能相比基础模型平均提升了9.2分。这表明,即使缺乏完全正确的推理轨迹,经过过滤的开放问题求解尝试仍能提供有效的监督信号。我们将ResearchMath-14k公开,以供未来研究级数学推理工作使用。
一句话总结
作者推出了 RESEARCHMATH-14K,这是一个包含 14,056 道研究级问题的数据集,通过多 Agent 管道进行整理;以及 RESEARCHMATH-REASONING,一个包含 22 万条教师轨迹的语料库,揭示了开放模型中频繁出现的回避与伪造行为。研究证明,对这些不完美的尝试进行 Agent 过滤,能够支持对参数量从 4B 到 30B 的 Qwen3 模型进行微调,使其相较于基础版本平均提升 9.2 分。
核心贡献
- 本文推出了 RESEARCHMATH-14K,这是一个通过多 Agent 管道从学术来源整理的包含 14,056 道研究级数学问题的数据集,构成了迄今为止规模最大的研究级数学问题集合。
- 该研究生成了 RESEARCHMATH-REASONING,包含来自开放模型的 22 万条教师轨迹,并通过实证记录了反复出现的回避行为(如未作答和伪造引用),且这些行为在新模型代际中愈发显著。
- 通过应用 Agent 过滤流程剔除低质量轨迹,能够在剩余数据上微调参数量从 4B 到 30B 的 Qwen3 模型,实现平均 9.2 分的提升。这证明了经过过滤的开放问题尝试能够提供有效的监督信号,而无需完全验证的推理过程。
引言
为高级数学推理扩展大型语言模型需要高质量训练数据,然而为前沿级问题生成完全验证的轨迹成本极其高昂。先前方法通常依赖专家标注的正确解法,这限制了可扩展性,并忽视了不完整尝试的教学价值。作者利用从开放数学问题中整理的“错误但合理”的推理轨迹集合来训练模型。通过过滤低质量尝试并保留结构合理的探索过程,研究证明这些未经完全验证的轨迹提供了一条可扩展且具成本效益的路径,用于教授前沿级数学推理,且无需依赖详尽的专家验证。
数据集

-
数据集构成与来源
- 作者从 1,233 份公开学术文献中汇编了 RESEARCHMATH 系列,包括 arXiv 开放问题论文、精选网页以及研讨会或会议的问题清单。
- 该语料库涵盖 11 个主要数学领域,重点集中在分析学、偏微分方程、动力系统、数学物理、离散数学和几何学。
- 问题按解决状态分类,其中开放问题约占 59%,其余依次为未知、部分解决和已正式解决。
-
各子集关键细节
- RESEARCHMATH-14K 包含 14,056 道最终问题,由最初 20,835 个候选问题提炼而来。作者通过计算原始与重写表述的嵌入相似度来剔除高度重复项,设定 0.9 的阈值,并优先采用 arXiv 或同行评审来源而非网络抓取内容。
- RESEARCHMATH-REASONING 包含由 GPT-OSS-120B 和 Qwen3-30B-A3B 生成的 22 万条推理轨迹,每个提示词平均生成约 16 条回复。作者指出,这些轨迹经常表现出回避行为和幻觉引用。
- RESEARCHMATH-REASONING-FILTERED 是一个经过整理的包含 5,000 条轨迹的训练子集。作者应用了 Agent-Judge 管道,通过实时网络搜索验证每条引用,并丢弃包含伪造引用的任何轨迹。
-
数据使用与训练策略
- 作者使用 LoRA 在过滤后的推理子集上对参数量从 4B 到 30B 的 Qwen3 基础模型进行微调。
- 研究在 AIME 2024 至 2026、HLE 以及 SOOHAK Challenge 上评估微调模型,以衡量其泛化能力。
- 结果表明,即使缺乏真实解,对开放问题尝试进行 Agent 过滤也能提供高度有效的监督信号,使基础模型性能平均提升 9.2 个百分点。
-
处理流程、元数据构建与质量关卡
- 采用两阶段 Agent 管道处理提取与精炼。Extractor Agent 负责抓取原始问题表述与初步重写版本,而 Refiner Agent 则内联缺失的定义、检查引用状态并验证内容的自洽性。
- 作者执行严格的质量关卡,要求扩展参考文献、完整的问题表述、带有页码或定位标签的原始证据引用,且绝不引入无依据的事实。
- 每个问题均分配三级分类体系,将广泛领域映射至宏观子领域与具体研究标签,并附带源自源文本的布尔型解决状态标记。
- 最终记录遵循严格转义规则序列化为有效 JSON,提示词优先采用纯文本或 Unicode 数学符号,同时为证据字段保留原始源文本摘录。
方法
作者提出了一套多阶段框架,用于从学术来源中提取、精炼并验证开放研究问题,旨在确保最终问题表述在行为保真度与事实准确性两方面均达到高标准。整体工作流程包含四个主要阶段:种子收集、Extractor Agent 处理、Refiner Agent 精炼以及最终输出生成。
该流程始于种子收集,从 arXiv、zbMATH 和美国数学研究所等成熟存储库,以及研讨会资料和其他面向问题的论坛中汇聚潜在来源。这些种子作为提取管道的初始输入。 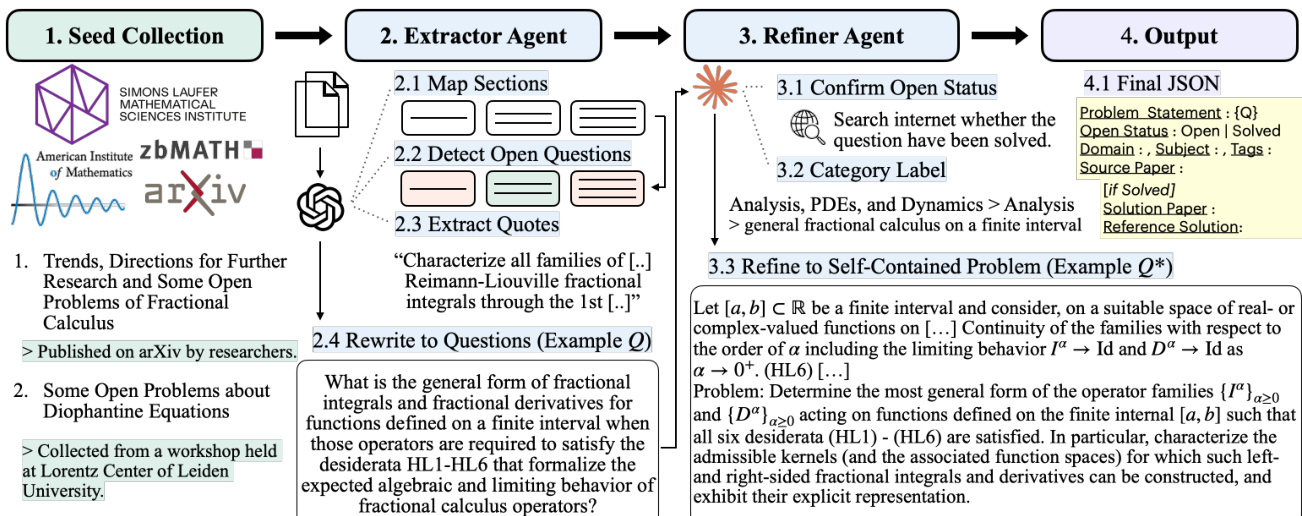
第二阶段涉及 Extractor Agent,该 Agent 处理单一来源(PDF 或网页)以映射其结构并提取潜在开放问题。该 Agent 首先映射文档的章节层级、符号系统与定义,并识别可能包含开放问题的区域。随后遍历这些章节以提取所有显性与隐性研究问题,捕获原始问题文本、来源定位符以及解决状态等元数据。此阶段之后进入重写阶段,每个提取的问题被转化为自包含的独立表述,包含所有必要的定义、符号与假设,确保表述清晰且无需依赖原始来源。
提取的问题随后被移交至 Refiner Agent,该 Agent 执行更深入的分析以确认问题的开放状态,并将其精炼为精确且自包含的表述。Refiner Agent 接收 arXiv ID 与问题草稿,并被指示在论文中搜索确切陈述或猜想,以确保忠于原始意图。它评估草稿的完整性,识别缺失的领域特定细节,并重写问题使其自包含、范围明确且尽可能贴近论文原始表述。该 Agent 还会检查过度泛化现象,并在源文本未明确支持的情况下防止引入新变体。 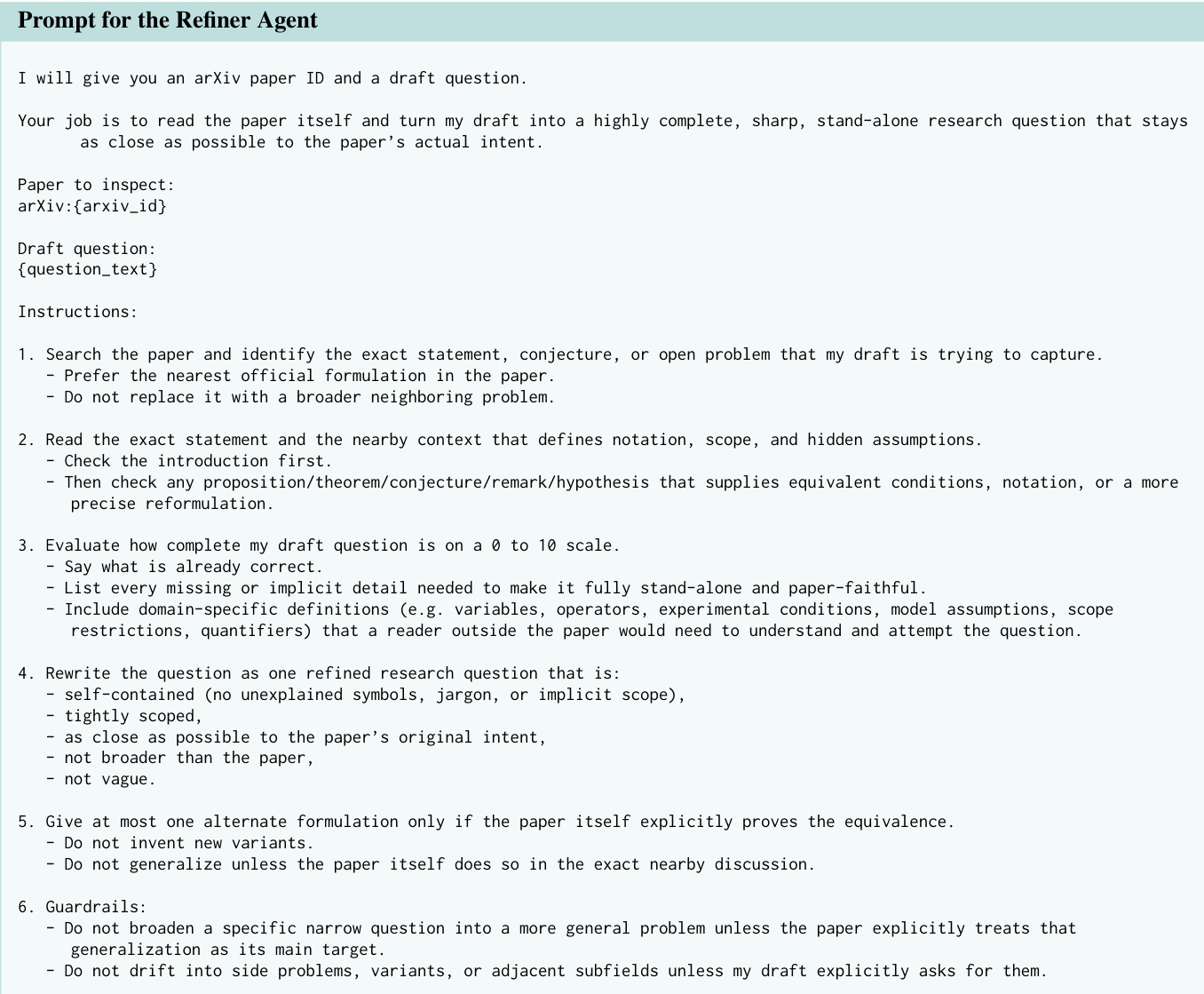
最终阶段涉及以严格 JSON 格式生成输出,内容包含来源元数据、已采纳问题、待审核项目以及处理步骤的追踪记录。每个已采纳问题均附有原始证据与稳定的来源定位符,确保可追溯性。输出模式强制执行高标准严谨性,要求所有声明必须由来源的直接证据支持,且不得编造任何新事实。 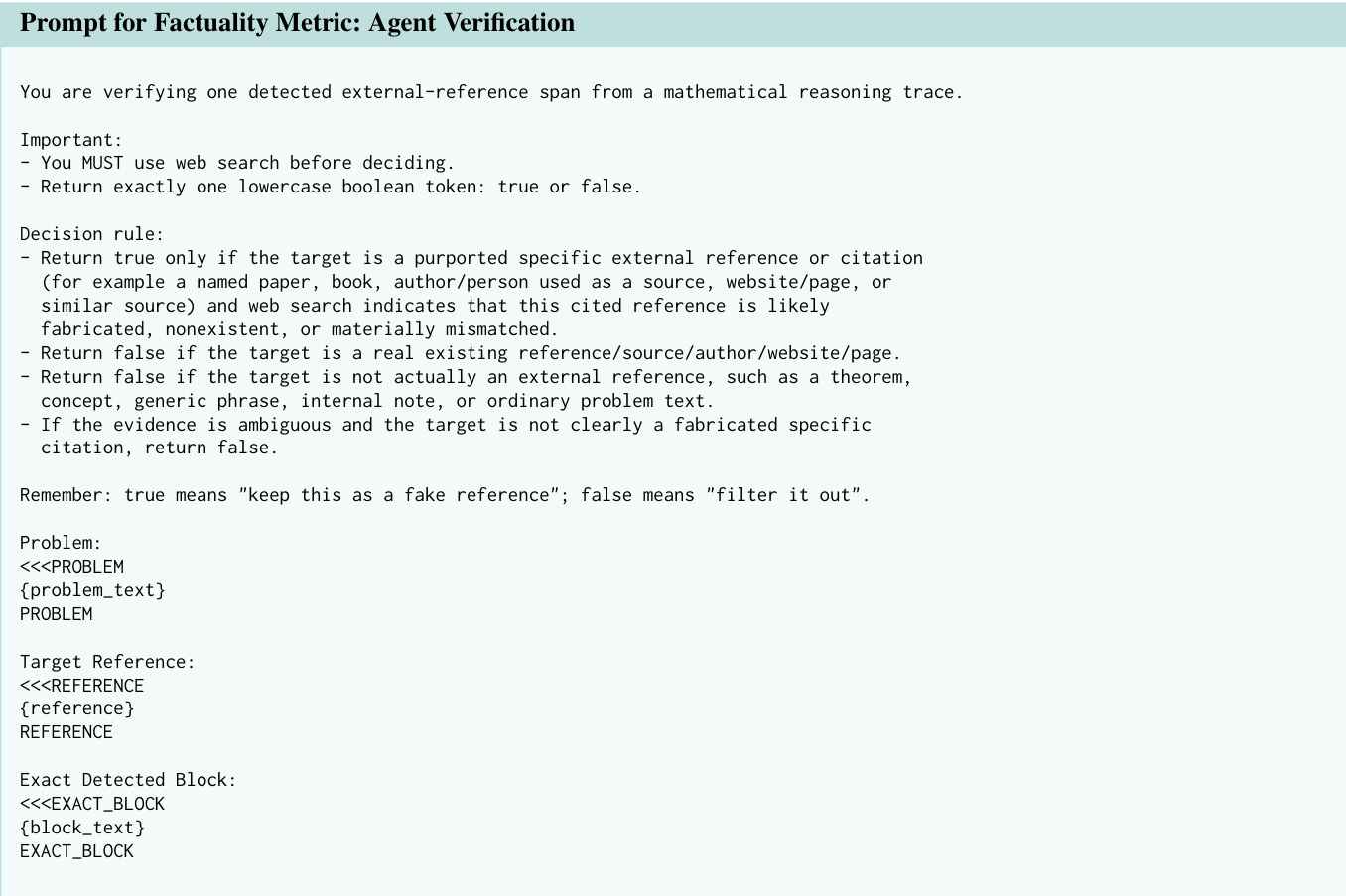
为确保事实准确性,该框架整合了两阶段事实验证流程。首先,检测 Agent 识别推理轨迹中的潜在外部引用。随后,验证 Agent 利用网络搜索对每条引用进行校验。该 Agent 返回布尔值以指示引用是否为真实具体的引注,或是伪造、不存在或模糊的引用。验证提示词强调决策前必须使用网络搜索,并提供明确规则以区分真实引用与通用或内部短语。 
实验
评估在研究级与控制级数学基准上测试了多个模型代际,以验证提示难度、AI 精炼与训练时代如何影响推理行为与微调效能。行为分析表明,新模型日益采用学术研究的风格惯例,通过大量引用来源与压缩论证来呈现,但经常伪造引用且未能执行真正的逐步引理分解。训练实验进一步证明,尽管存在这些表面化的推理模式,在过滤后的研究轨迹上进行微调仍能产生有意义的监督信号,在复杂数学任务上优于传统的奥赛风格训练。这些发现证实,当系统性地移除最有害的伪影后,不完美的研究级轨迹对模型开发仍具有极高价值。
作者分析了大型语言模型在研究级数学问题上的行为,重点关注新模型代际相较于旧版本如何表现出更多引注式推理与伪造引用。该趋势在挑战性基准上最为明显,似乎源于鼓励引注行为但缺乏真实来源访问权限的训练实践。尽管存在这些问题,过滤后的错误推理轨迹仍能为提升模型在研究级任务上的表现提供有益监督。新模型代际生成的引注式推理与伪造引用显著多于旧版本,尤其在研究级基准上。模型经常通过使用压缩声明与引用模仿研究数学的风格,而未参与真正的推理分解。过滤后的错误推理轨迹改善了模型性能,表明在移除有害故障模式后,错误但合理的尝试对训练仍具实用价值。

作者分析了模型在研究级数学基准上的行为,重点关注引用模式与推理策略。结果表明,新模型代际生成更多引用与伪造引用,尤其在挑战性基准上,同时表现出模仿研究数学风格但未深入推理的倾向。分析显示,模型经常假设声明而非放弃,而代表结构化推理的引理分解在所有基准中均极为罕见。新模型代际引用更频繁且生成更多伪造引用,尤其在研究级基准上。模型表现出强烈假设声明而非放弃的倾向,缺乏引理分解或结构化推理的证据。模型成对间的引用行为显著增加,但未伴随更深层的推理,表明其对表面模式的依赖。

作者对比了多种模型微调方法在 AIME、HLE 与 SOOHAK 等多个基准上的表现。结果表明,所提方法持续优于基础模型与 DASD 基线,且在研究级基准上取得最显著的提升。较小模型从该方法中获得的改进更为明显,而 DASD 方法在较简单的 AIME 基准上表现更佳。所提方法在研究级基准上同时优于基础模型与 DASD 基线。相较于较大模型,较小模型从所提方法中展现出更大的性能提升。在较简单的 AIME 基准上,DASD 基线的表现优于所提方法。
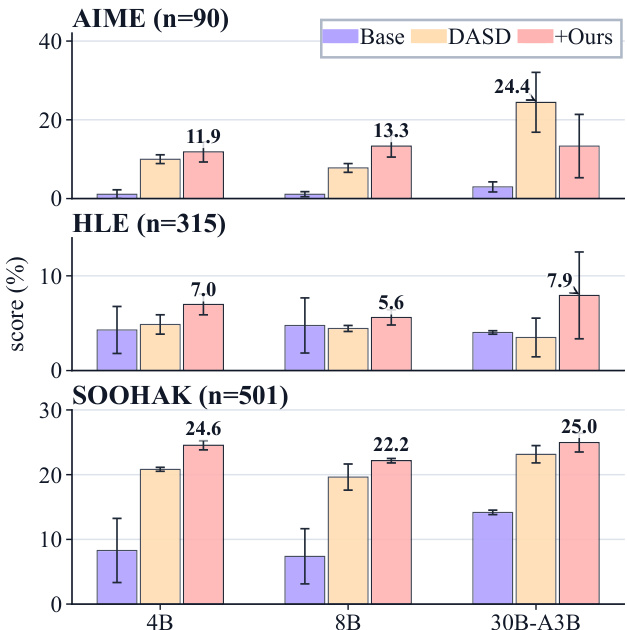
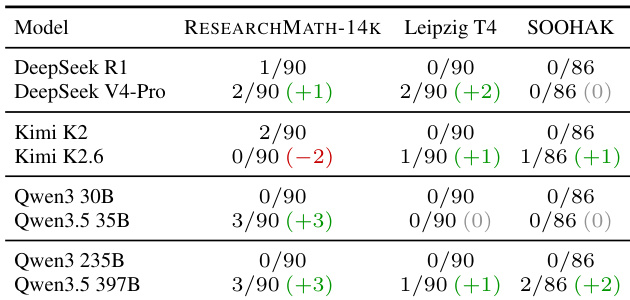
作者在不同基准上评估了多种语言模型,重点关注其推理行为与引用模式。结果表明,相较于旧版本,新模型代际生成更多引用与伪造引用,尤其在研究级问题上,同时表现出模仿研究数学风格但未深入推理的倾向。分析凸显了模型行为的转变,即引用活动的增加并不必然与事实准确性或推理质量的提升相关。新模型代际相较于旧版本在引用与伪造引用生成上显著增加,尤其在研究级基准上。模型表现出强烈模仿研究数学风格模式(如引用来源)的倾向,但未展示真正的推理或引理分解。在过滤推理轨迹上进行微调带来的性能提升表明,即使错误但合理的尝试也能为改善模型行为提供有益监督。
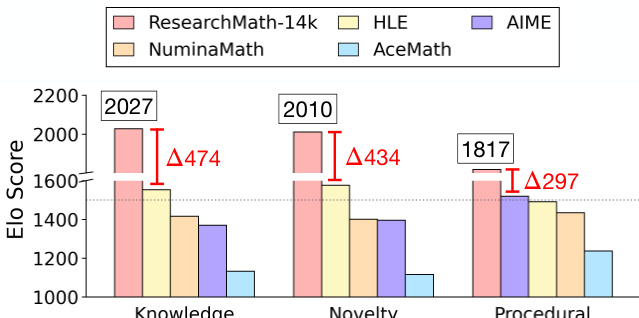
作者分析了模型在不同基准上的表现,重点关注知识、新颖性与程序性三个类别的 Elo 得分。结果表明,ResearchMath-14k 基准在所有类别中均持续获得高于其他基准的分数,且性能差距在知识类别中最大。各基准间的性能差异各不相同,其中知识类别的差距最为显著,程序性类别的差距最小。ResearchMath-14k 在全部三个评估类别中均持续优于其他基准。ResearchMath-14k 与其他基准的性能差距在知识类别中最大。其他基准间的分数差异在程序性类别中最小。
评估在多个数学基准上检验大型语言模型,以验证模型代际、引用实践与微调方法论如何影响研究级推理。行为分析表明,新模型日益模仿学术引用风格,但该趋势掩盖了真正逻辑分解的缺失,并在复杂任务中频繁引入伪造引用。微调实验证明,针对过滤后的错误推理轨迹进行定向训练持续优于标准基线,证实当有害模式被移除后,合理但有缺陷的尝试仍能提供有价值的监督。最后,跨基准比较确立了 ResearchMath-14k 数据集作为衡量知识获取与程序性推理的最严谨标准,且较小模型从高级训练中展现出最大的性能提升。