Command Palette
Search for a command to run...
MUSE-Autoskill:通过技能创建、记忆、管理与评估实现自我进化的智能体
MUSE-Autoskill:通过技能创建、记忆、管理与评估实现自我进化的智能体
Huawei Lin Peng Li Jie Song Fuxin Jiang Tieying Zhang
摘要
大型语言模型(LLM)智能体(Agent)依赖可复用的技能(skills)来解决复杂任务。然而,现有的技能创建方法将技能视为孤立且静态的产物,限制了其可复用性、可靠性及长期改进潜力。为此,我们提出了 MUSE-Autoskill Agent(基于记忆的技能演进智能体),这是一种以技能为中心的智能体框架,使智能体能够在统一的生命周期(创建、记忆、管理、评估与优化)下,通过创建、复用和优化技能,持续提升其任务求解能力。我们的框架支持智能体按需创建技能,跨任务存储并复用这些技能,高效地组织与选择技能,并通过单元测试和运行时反馈对技能进行评估与持续优化。此外,我们引入了技能级记忆(skill-level memory),旨在跨任务积累每个技能的经验,从而随着时间的推移实现更高效的复用与适应性调整。在 SkillsBench 上的实验提供了初步证据,表明通过生命周期管理的技能能够提高任务成功率、执行效率、复用率以及跨智能体迁移能力,突显了将技能视为具有长生命周期、具备经验感知能力且可测试的资产的重要性。
一句话总结
MUSE-Autoskill 是一个自演进 agent 框架,通过创建、memory、管理、评估和精炼的统一生命周期,解决了孤立和静态技能的局限性,利用技能级 memory 以及通过单元测试和运行时反馈进行的评估来实现持续改进,SkillsBench 实验表明其在任务成功率、效率、复用性和跨 agent 转移方面有所提升。
核心贡献
- 本文介绍了 MUSE-Autoskill Agent,这是一个无需训练的框架,将技能创建、memory、管理、评估和精炼统一到一个生命周期中。
- 该方法融合了技能级 memory 以跨任务积累每个技能的 experience,并使用单元测试驱动的评估在测试失败时自动触发精炼。
- SkillsBench 上的实验表明,生命周期管理的技能提高了任务成功率和效率,并在经验上验证了无需修改即可进行跨 agent 技能转移。
引言
大型语言模型 agent 需要可复用的技能来处理复杂的现实世界任务,但当前方法通常将这些能力视为孤立和静态的产物。这种方法限制了可靠性,因为先前的系统缺乏针对单个技能的结构化 memory,并且省略了通过单元测试进行的严格验证。作者介绍了 MUSE-Autoskill,它通过创建、memory 管理、评估和精炼统一了技能生命周期。其框架利用技能级 memory 积累 experience,并利用自动化测试触发持续自我改进。因此,agent 可以实现更高的任务成功率,并在不同系统之间转移经过验证的技能而无需额外训练。
数据集
-
数据集构成与来源
- 作者构建了一个包含来自 MUSE-Autoskill 运行时的 agent 技能和执行轨迹的数据集。
- 技能存储为与 Anthropic 的 Agent Skills 格式兼容的自包含目录。
- 轨迹记录在为每个任务调用创建的每个会话工作空间中。
-
每个子集的关键细节
- 技能: 每个条目都是一个以 kebab-case 名称为根目录的目录,包含一个
SKILL.md文件。该文件需要带有名称和描述的 YAML frontmatter。可选子目录包括脚本、测试和资源,尽管仅文档技能是主要模式。 - 会话: 每个任务都会在 agent 主目录下创建一个以类似 UUID 字符串命名的目录。此工作空间保存指令提示、提交的输入、输出产物和日志流。
- 事件:
events.jsonl文件捕获了每个计划、行动和观察的严格有序流。
- 技能: 每个条目都是一个以 kebab-case 名称为根目录的目录,包含一个
-
模型中的数据使用
- 作者使用
events.jsonl流用于附录 H 中的可复现性和分析。 ctx_state.json文件序列化对话 DAG 以支持跨会话恢复机制。- 元数据(如
run_meta.json)记录 reward、回合数和模型详情。
- 作者使用
-
处理与元数据构建
- 所有 memory 文件均使用纯 Markdown 格式,具有用于长期、短期和每个技能上下文的仅追加块。
- 沙盒执行通过将上传路由到
/sandbox/inputs/并将输出路由到/sandbox/outputs/来隔离进程。 - 技能身份依赖于冗余命名,其中目录名称必须与 frontmatter 名称字段匹配。
方法
MUSE-Autoskill Agent 作为一个以技能为中心的框架运行,旨在通过技能的动态创建、复用和精炼来解决复杂任务。该系统在统一的 agent 循环中集成了技能创建、执行、memory 管理和评估。
整体架构组织为四个主要组件:技能创建、技能管理、自我进化与修正以及 memory 机制。
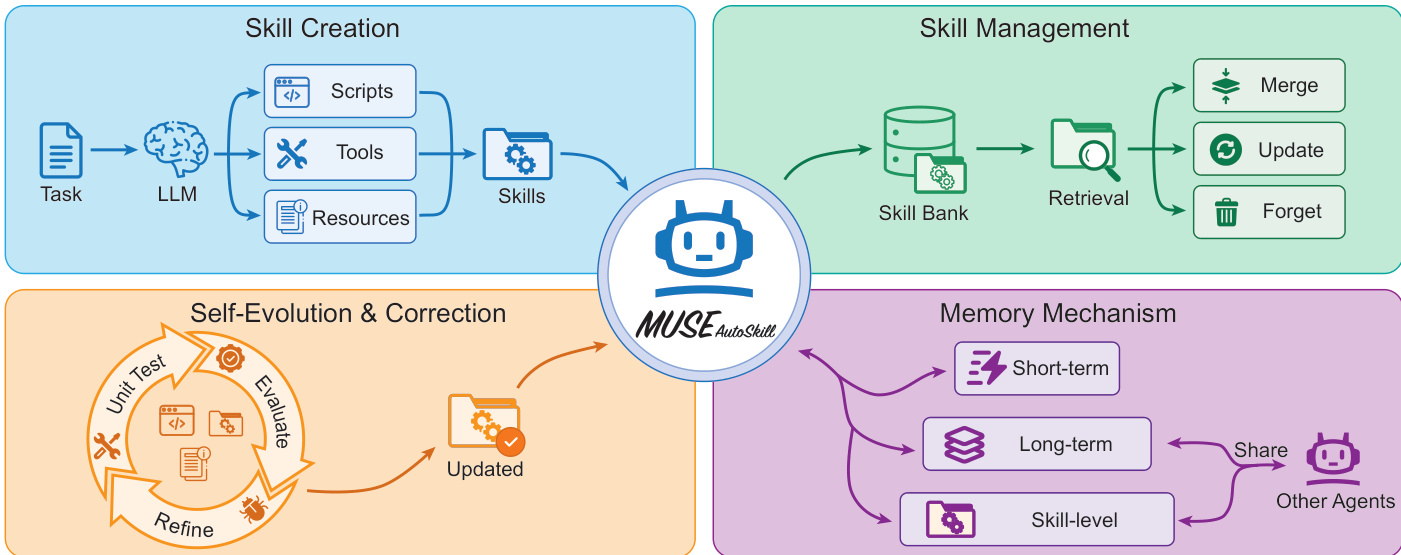
技能创建允许 agent 在现有技能不足时生成新能力。技能管理处理存储在技能库中的技能的检索、合并、更新和遗忘。自我进化模块通过单元测试和精炼循环确保质量。最后,memory 机制维护短期、长期和技能级 memory 以支持上下文保留和知识积累。
端到端工作流由运行 ReAct 循环的 Master Agent 驱动,与技能子系统交互。
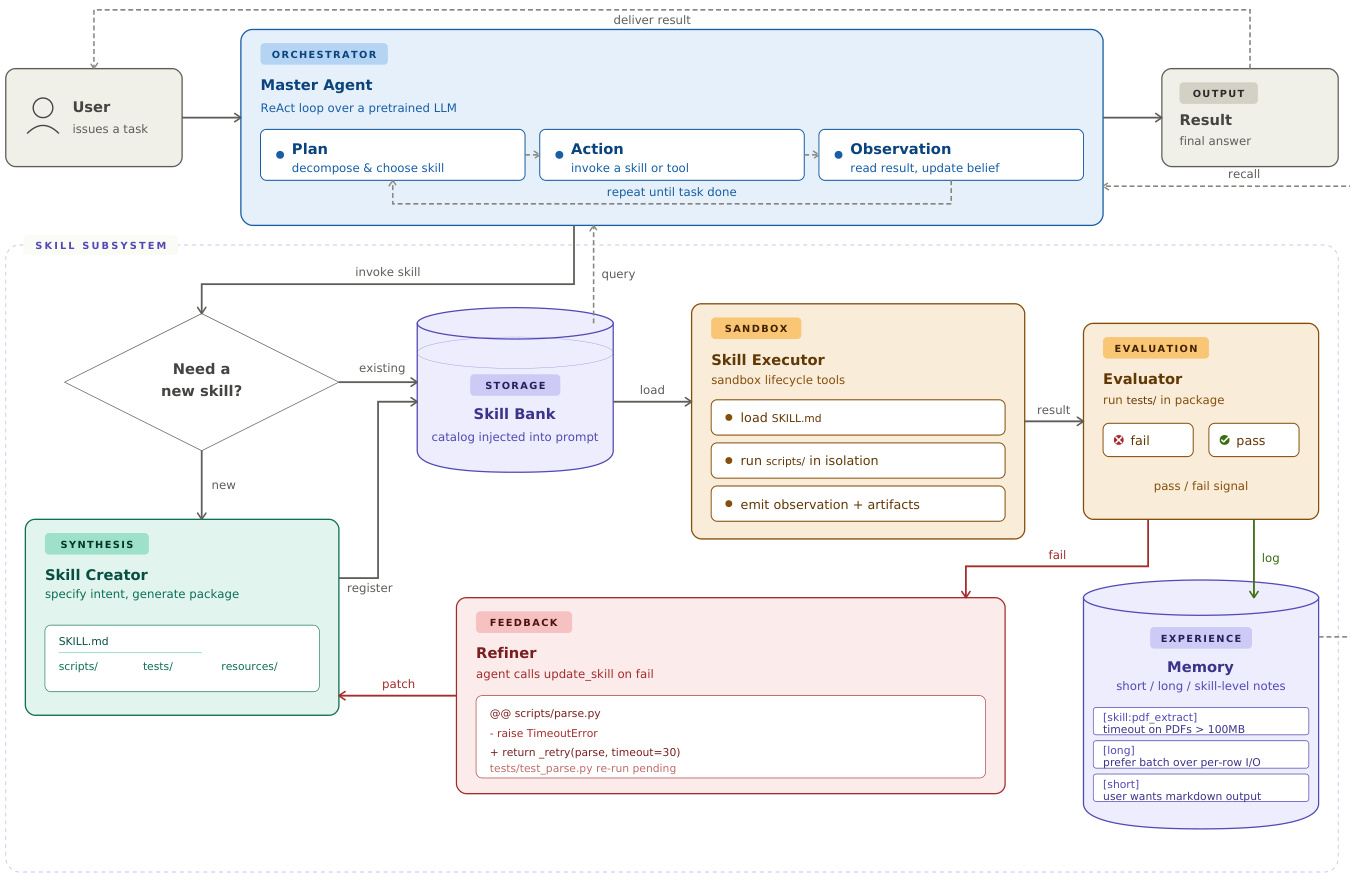
当用户发出任务时,Master Agent 进入规划、行动和观察的循环。在规划阶段,agent 分解问题并决定是调用现有技能还是创建新技能。如果需要新技能,系统会调度技能创建者来合成一个包含 SKILL.md 定义、可执行脚本和单元测试的包。然后在沙盒环境中对该包进行评估阶段。如果测试通过,技能将注册到技能库中,观察结果将记录到 memory 中。如果测试失败,精炼模块会根据错误反馈修补代码,循环重复直到技能得到验证。
为了在长视野任务期间管理上下文限制,agent 采用针对对话回合有向无环图(DAG)的自适应上下文压缩策略。
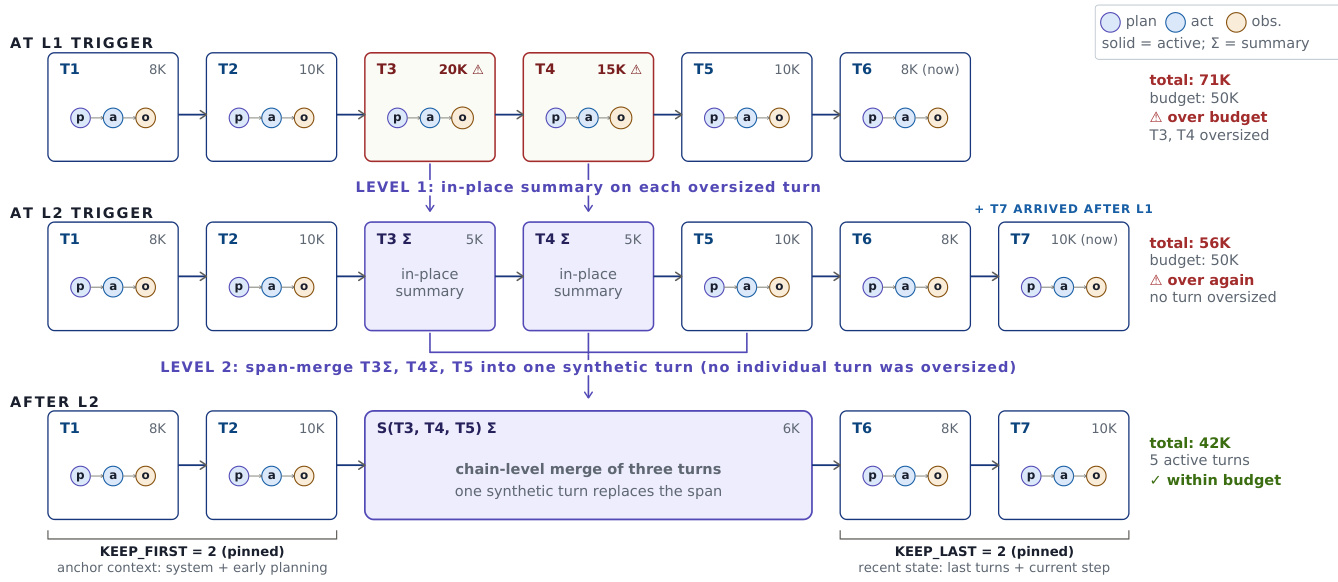
系统维护一个历史记录,其中前 K 个和后 K 个回合被固定以保留系统指令和最近状态。当总 token 数超过预算时,Level 1 压缩触发对单个过大回合的原地摘要。如果预算仍然超出,Level 2 压缩将连续的一系列中间回合合并为单个合成摘要节点。这种分层方法确保活动链保持在模型的上下文窗口内,同时保留完整的历史记录以供重放和分析。
实验
在 SkillsBench 基准测试上的评估表明,技能使用在不同系统设计下显著提高了 agent 性能,同时确立了 MUSE-Autoskill 比基线模型更有效地整合了这些内容。自动技能生成成功地从成功轨迹中提取高质量知识,这些知识通常超越人类编写的参考,并无缝转移到其他 agent 架构而无需修改。与基线和人类技能条件相比,这些生成的技能通过同时提高任务准确性和降低计算成本实现了帕累托最优结果。
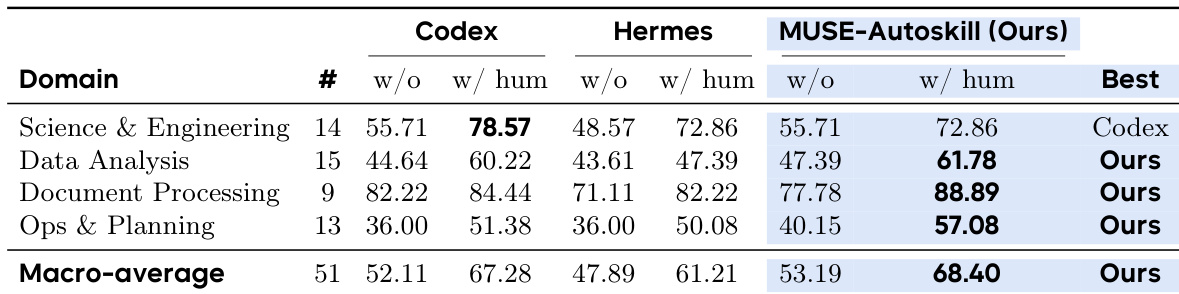
作者在 51 个任务的基准测试上评估了三个 agent,以衡量使用人类编写技能与依赖基础知识的影响。结果表明,提供技能显著提升了所有测试系统的性能。MUSE-Autoskill 展示了利用这些技能实现最高整体准确性的卓越能力。每个配备人类编写技能的 agent 都显示出任务完成率的显著提高。MUSE-Autoskill 在两种实验条件下始终确保顶级性能排名。技能的引入为所有 agent 带来了可比的相对收益,突出了该机制的普遍价值。

作者在涵盖四个领域的任务基准上评估了三个 agent,比较了无技能与使用人类编写技能的性能。结果表明,人类技能始终提高了所有 agent 的准确性,所提出的 MUSE-Autoskill 框架在两种条件下均实现了最高的宏平均分数。所提出的方法在大多数测试领域中优于基线 agent,特别是在数据分析、文档处理和操作规划方面表现出色。人类技能始终提高了所有评估 agent 的准确性。MUSE-Autoskill 在使用人类技能时实现了最高的宏平均性能。所提出的方法在四个领域类别中的三个中领先。
该表比较了三个 agent 的 token 使用情况,显示由于更深层的推理循环,MUSE-Autoskill 消耗的 token 明显多于 Codex 和 Hermes。虽然提示缓存占所有系统输入 token 的大部分,但添加人类技能的影响因 agent 而异,增加了 MUSE-Autoskill 和 Codex 的成本,但减少了 Hermes 的成本。MUSE-Autoskill 展示了最高的总体 token 消耗,在两种技能条件下使用的输入 token 明显多于其他 agent。提示缓存吸收了很大一部分输入负载,在所有 agent 和配置中处理了大约一半的总输入 token。添加人类技能导致效率趋势分歧,增加了 MUSE-Autoskill 和 Codex 的总 token 使用量,同时减少了 Hermes 的使用量。
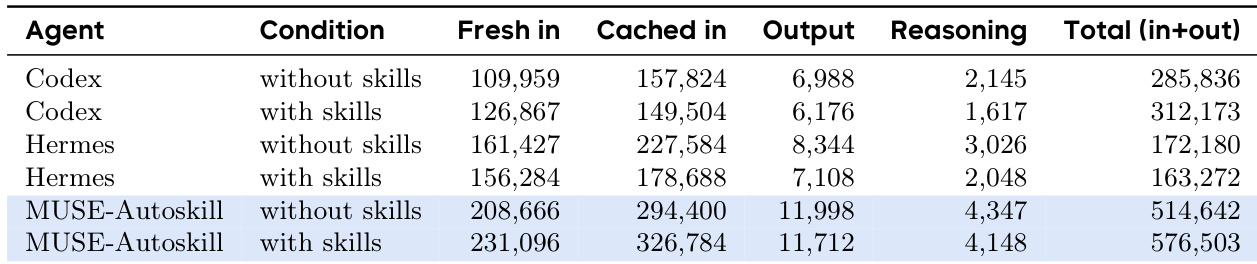
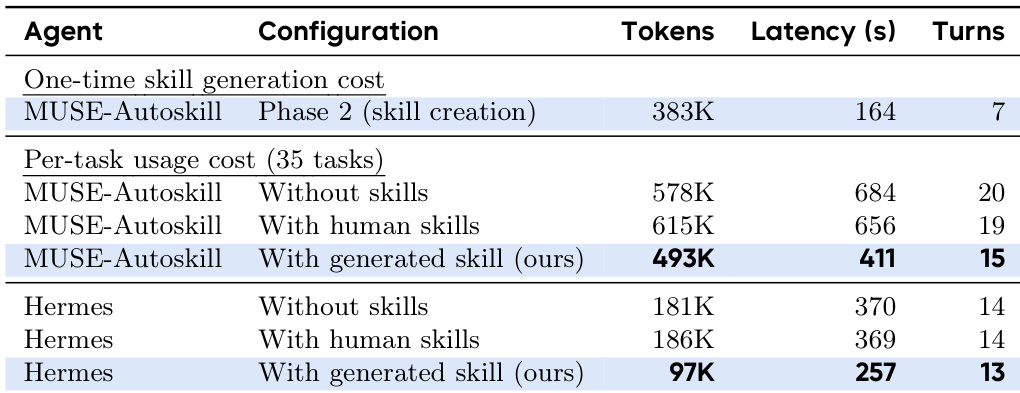
该表比较了 MUSE-Autoskill 和 Hermes agent 在不同配置下的技能生成和使用计算成本。它表明,虽然生成技能会产生一次性成本,但使用生成的技能比依赖人类技能或无技能更高效。两个 agent 在利用自动生成的技能时都实现了更低的 token 使用量、更低的延迟和更少的交互回合。与人类技能相比,生成的技能导致更低的 token 消耗和延迟。该框架减少了完成任务所需的回合数。技能创建的前期成本被使用期间的效率增益所抵消。
作者在 51 个任务的基准测试上评估了三个 agent,以评估技能使用和自动生成的影响。结果表明,MUSE-Autoskill 实现了最高的整体性能,而所有 agent 在利用人类编写技能时都显示出显著改进。此外,MUSE-Autoskill 自动生成的技能成功转移到其他 agent,显著提高了它们的准确性,并接近人类技能所见的性能水平。MUSE-Autoskill 在基线和技能辅助条件下始终优于 Codex 和 Hermes。与不使用技能相比,所有 agent 在利用人类编写技能时都经历了显著的准确性提升。MUSE-Autoskill 自动生成的技能成功转移到 Hermes,显著提升了其性能。
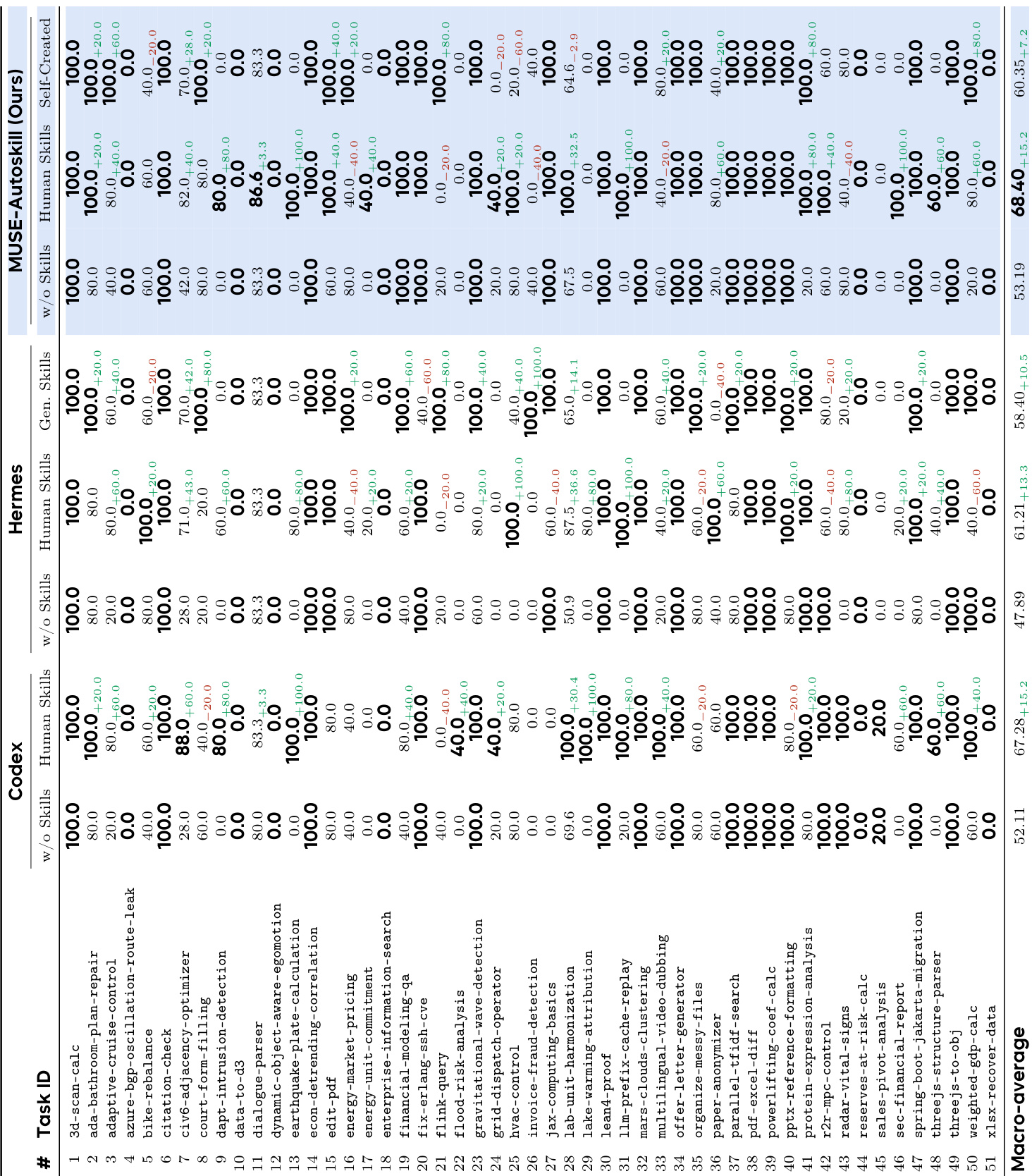
作者在多个领域评估了三个 agent,以衡量使用人类编写技能与自动生成技能对任务性能的影响。结果表明,为 agent 配备技能显著提高了所有系统的准确性,MUSE-Autoskill 始终实现最高的整体性能。此外,自动生成的技能被证明是高效的,与人类技能相比减少了延迟和交互回合,并成功转移到其他 agent,尽管由于更深层的推理,MUSE-Autoskill 产生了更高的总体 token 使用量。