Command Palette
Search for a command to run...
语言模型推理中的带重置的信用分配
语言模型推理中的带重置的信用分配
Ankur Samanta Akshayaa Magesh Ayush Jain Youliang Yu Daniel Jiang Kavosh Asadi Kaveh Hassani Paul Sajda Jalaj Bhandari Yonathan Efroni
摘要
当前基于可验证奖励的强化学习(RLVR)方法在对语言模型进行后训练时,通常将单一的最终奖励均匀地传播至所有中间步骤。对于涉及长步多步推理任务的语言模型而言,这种机制给每一步分配相同的信用(credit),从而模糊了哪些步骤对观察到的结果贡献最大。直接从对结果影响最大的步骤中学习,可以为策略更新提供更有意义的信号,从而实现高效学习。此类机制同样存在于生物系统中,生物体会重新访问高影响力的决策点,并从基于这些状态模拟的反事实“如果……会怎样”(what if)结果中学习。受此启发,我们研究了利用“重置”(resets)改进信用分配的RL后训练方法,即通过从可改进状态的反事实结果中学习来提升性能。重置操作是指重新进入之前访问过的状态,并重新采样后续序列,从而将结果差异归因于从该状态做出的决策。在本工作中,我们认为,当重置状态存在更优动作(即该状态具有显著的改进潜力)时,重置技术对信用分配尤为有效。我们提出了两种基于重置的RLVR语言模型后训练方法:随机重置策略优化(Random-Reset Policy Optimization, RRPO)和自重置策略优化(Self-Reset Policy Optimization, SRPO)。这两种方法均从失败轨迹中选取一个重置状态,并从中重采样多个后缀(suffix)延续序列,且仅针对这些后缀token应用策略梯度。可以将这种共享前缀(shared-prefix)的组视为一组反事实的 rollout(探索轨迹),其结果差异将信用归因于发散的 suffix tokens。两者的区别在于重置状态的选择方式:RRPO在所有推理步骤中均匀随机选择,而 SRPO 则通过自我定位(self-localization)首个错误步骤来选择。SRPO 不需要外部步骤级反馈,它利用了一个发现:语言模型能够足够准确地自我定位失败的结构化推理轨迹中的首个错误思维,从而驱动自我纠正。为了量化通过自我定位错误带来的收益相对于随机重置的提升,我们采用了保守策略迭代(Conservative Policy Iteration, CPI)框架,这是一种基础的策略优化算法。CPI 通过随机重置获取在线策略(on-policy)状态样本,估计优势值(advantages),并执行保守的策略更新。我们将此算法称为基于随机重置的CPI(CPI-with-random-resets, CPI-RR)。我们将 CPI-RR 的性能与另一种假设能获得信用分配预言机(oracle)访问权限的 CPI 算法变体进行比较:该预言机是一个针对可改进状态的成员资格测试,用于判断某状态是否存在优势值大于阈值 τ 的动作。由此产生的变体被称为 CPI-CARO,它仅从可改进状态中提取重置状态,并仅在这些状态上应用策略更新。我们证明,CPI-CARO 将样本复杂度降低了 1/pπ2,并将每次迭代的改进幅度提高了 1/pπ,其中 pπ 为达到可改进状态的在线策略概率。在一个涵盖数学、科学、战略和常识推理的10项基准测试套件中,SRPO 的表现优于 GRPO 以及使用自我纠正或共享前缀延续方法的当代 RL 基线方法。我们还在代码领域测试了 SRPO,结果显示它收敛至更高的通过率,且学习速度比 GRPO 和 RRPO 快 2–3 倍。高质量的自我定位带来了更高的纠正率和更好的后缀组效果:前缀干净(正确)的情况下的纠正率几乎是前缀错误情况的 2 倍,这确立了显式自我定位作为信用分配预言机的不完美但有效的代理作用。这种对定位质量的敏感性激励着人们进一步改进基于重置的 RL 中的定位技术,以实现更高效的学习。
一句话总结
来自多家机构的研究者提出 Self-Reset Policy Optimization (SRPO),一种强化学习方法,通过在语言模型推理中重置并从自我识别的错误步骤重新采样,来创建反事实后缀组,将结果差异归因于特定决策,从而改善信用分配。在数学、科学和编程基准测试中,该方法的学习速度比 GRPO 快 2–3 倍,且准确率更高。
核心贡献
- 引入了 Random-Reset Policy Optimization (RRPO) 和 Self-Reset Policy Optimization (SRPO),这两种基于重置的强化学习方法通过从失败轨迹中的重置状态重新采样后缀延续,并仅对这些后缀 token 应用策略梯度,从而改善信用分配。
- 使用保守策略迭代的理论分析表明,与随机重置 (CPI-RR) 相比,通过信用分配预言机从可改进状态进行重置 (CPI-CARO) 可将样本复杂度降低 1/pπ²,并将每次迭代的改进程度提高 1/pπ,其中 pπ 是达到此类状态的同策略概率。
- 在包含 10 个推理基准(数学、科学、策略、常识)和编程领域的实验表明,SRPO 优于 GRPO 和当前的 RL 基线,收敛到更高的通过率,并且学习速度比 GRPO 和 RRPO 快 2–3 倍;更高质量的自我定位产生的纠正率几乎是错误定位的两倍。
引言
用于语言模型后训练的标准可验证奖励强化学习 (RLVR) 方法,会将单一的结果奖励均匀地分配给推理轨迹中的每个 token。这种均匀分配忽略了一个事实,即某些推理步骤直接决定了最终的成功或失败,从而稀释了学习信号,并阻碍了对错误步骤的针对性优化。作者通过引入基于重置的信用分配方法来解决这一局限性,该方法返回到中间状态并重新采样反事实延续,从而可以将结果差异归因于特定决策。他们提出了两种算法,Random-Reset Policy Optimization (RRPO) 和 Self-Reset Policy Optimization (SRPO),并在保守策略迭代 (CPI) 框架内对其进行分析。他们的主要贡献是证明,针对可改进状态的信用分配预言机相比随机重置具有可证明的改进,并且 SRPO 使用模型本身在没有外部监督的情况下定位错误,在不同模型和推理基准上始终优于标准的 GRPO 和 RRPO。
方法
作者提出了一种后训练 RLVR 方法,将重置构建为信用分配原语。他们在思维粒度上进行操作,将生成过程形式化为一个思维 MDP,其中每个动作都是一个由停止模式分隔的语义连贯的推理步骤(一个“思维”)。这种抽象允许模型在生成过程中自我确定边界,使每个思维都成为信用分配的原子、自包含单元,无需追溯解析。
为了构建训练 rollout,作者构建了一个缓冲区,结合了来自提示 x0 的 G 个独立同分布 rollout 的基础组(标准 GRPO)和来自重置状态 x∗ 的 G 个 rollout 的共享前缀组。如下图所示,可以利用这些组的不同配置,从标准的 GRPO 基线到各种 SRPO 分割,例如 1x4、2x4 和 1x8。
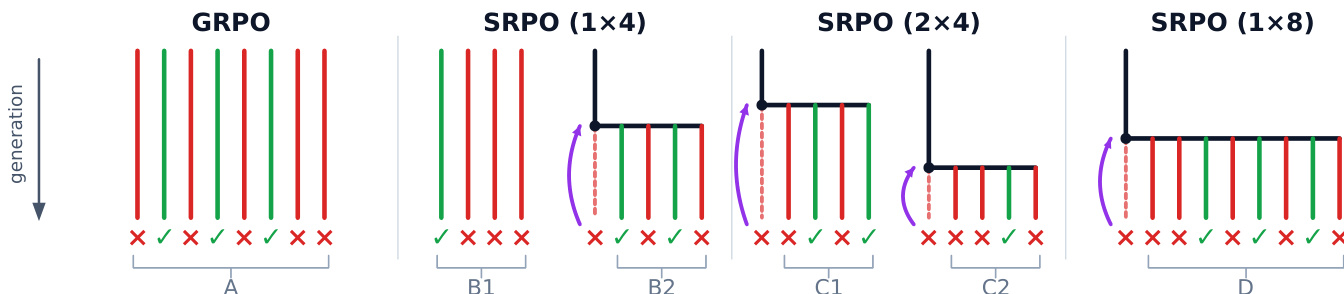 共享前缀组的生成方式是首先抽取 rollout 直到找到一个不正确的“种子”。这些方法的不同之处在于如何选择重置索引 h∗ 以形成重置状态 x∗=(x0,y~1:h∗−1)。在 Random Reset Policy Optimization (RRPO) 中,h∗ 是均匀抽取的,实现了均匀重置。在 Self-Reset Policy Optimization (SRPO) 中,模型执行显式的自我定位,以识别种子中第一个错误思维的索引。生成种子的同一个策略被提示分析其自身的推理轨迹,有效地充当信用分配预言机,以找到错误之前的已验证正确前缀。
共享前缀组的生成方式是首先抽取 rollout 直到找到一个不正确的“种子”。这些方法的不同之处在于如何选择重置索引 h∗ 以形成重置状态 x∗=(x0,y~1:h∗−1)。在 Random Reset Policy Optimization (RRPO) 中,h∗ 是均匀抽取的,实现了均匀重置。在 Self-Reset Policy Optimization (SRPO) 中,模型执行显式的自我定位,以识别种子中第一个错误思维的索引。生成种子的同一个策略被提示分析其自身的推理轨迹,有效地充当信用分配预言机,以找到错误之前的已验证正确前缀。
有关 SRPO 过程的详细视图,请参考框架图。在初始迭代中,模型生成一个思维序列。在验证准确性后,定位步骤识别出第一个错误思维(例如,y~4)。然后,该过程重置到已验证正确的前缀(保留 y~1:3),并采样多个替代后缀(后缀 1 到后缀 4)。共享前缀的梯度被屏蔽,确保仅根据最终结果将信用分配给重新采样的后缀。
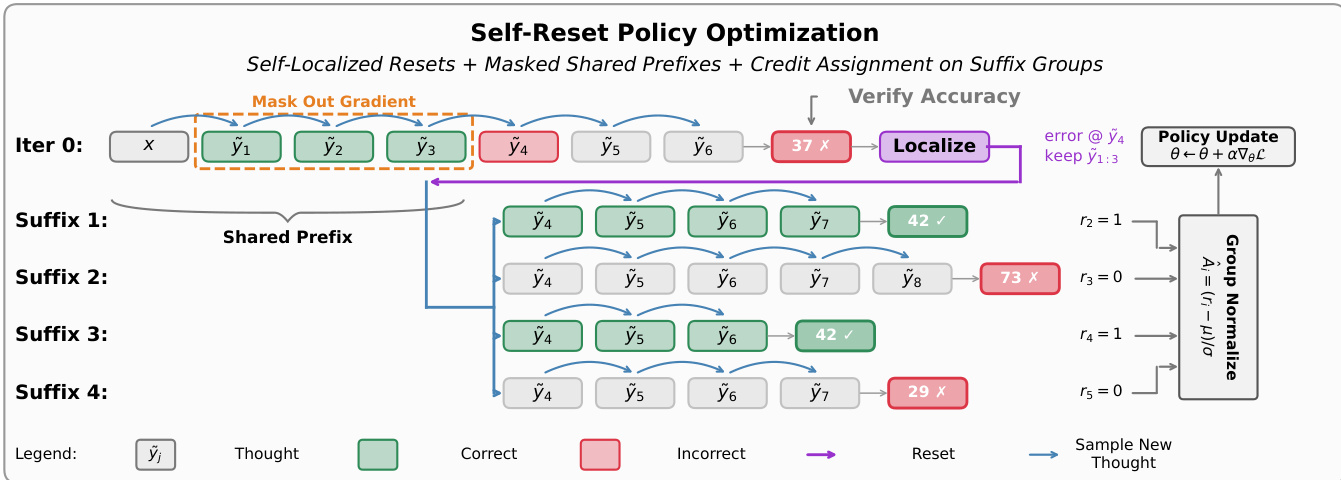
最后,作者使用组相对优势来强化这些 rollout。对于每个组,优势基于该组的经验均值和标准差进行自我归一化,衡量每个 rollout 相对于其组内其余部分的结果。对于共享前缀组,损失仅将此优势应用于后缀 token,屏蔽共享前缀。这种前缀屏蔽充当了重置状态上理论策略更新的参数化类比,确保信用信号存在于思维而非 token 上。策略通过组合缓冲区上的单次同策略梯度步骤进行更新,无需 PPO 裁剪或 KL 正则化。
实验
重置会重新进入先前访问过的状态以重新采样延续,将信用归因于从该状态做出的决策,并且当重置状态具有显著的改进潜力时最为有用。这项工作引入了两种基于重置的 RL 后训练方法——RRPO,它均匀随机地选择重置状态,以及 SRPO,它使用模型自身对第一个错误步骤的自我定位——并表明 SRPO 在数学、科学、策略、常识和编程基准上始终优于随机重置和无重置基线,同时学习速度更快。自我定位充当了信用分配预言机的不完美但有效的代理,正确前缀的纠正频率几乎是错误前缀的两倍,这使得定位质量成为主要瓶颈,并激励了进一步改进它的工作。这些方法依赖于可验证奖励和多步推理结构,理论分析确定了仅在可改进状态重置所带来的样本复杂度增益。
作者在固定的 rollout 预算下比较了 GRPO、RRPO 和 SRPO 的计算效率和资源使用情况。结果表明,虽然像 RRPO 和 SRPO 这样的基于重置的方法比 GRPO 需要更多的总训练时间,但 SRPO 在总时间和 token 消耗方面比 RRPO 更高效。此外,与标准的 GRPO 基线相比,基于重置的策略表现出更慢的生成速度和更长的响应长度。SRPO 需要的总训练和验证时间比 RRPO 少,使其成为更高效的基于重置的方法。RRPO 消耗的 token 最多,生成的响应最长,而 SRPO 保持适度的资源使用。GRPO 实现了最高的生成速度,而基于重置的方法由于其采样开销而经历较慢的 token 生成。

作者在十个推理基准上,在固定计算预算下评估了 SRPO 的不同基于重置的采样策略。1x4 分割平衡了基础策略覆盖与共享前缀深度,在两个评估模型的大多数任务上取得了最佳性能。因此,此配置被采纳为剩余实验的默认 SRPO 设置。对于 Qwen2.5-14B-Instruct 和 OLMo-3-7B-Instruct,1x4 采样策略在大多数基准上优于 2x4 和 1x8 分割。与平衡的 1x4 分割相比,将后缀深度增加到 1x8 或将前缀多样性增加到 2x4 通常会产生较低的性能。采用 2x4 分割的 RRPO 偶尔在特定任务上获得最高分,但通常被 1x4 SRPO 配置所超越。
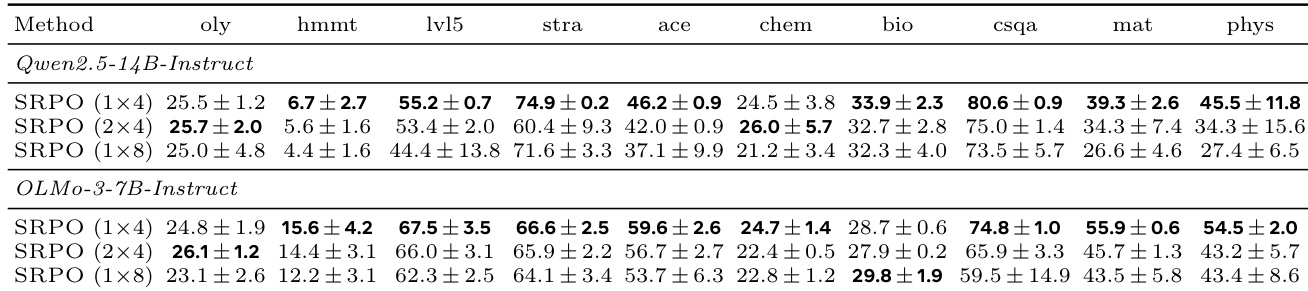
作者在固定计算预算下评估了 Self-Reset Policy Optimization 的不同采样策略,以确定基础策略覆盖和共享前缀深度之间的最佳平衡。结果表明,1x4 分割结合了独立的基础 rollout 和来自单个自我定位前缀的重新采样后缀,在大多数推理基准上取得了最佳性能。因此,此配置被采纳为后续实验的默认设置。1x4 采样策略通过有效平衡基础 rollout 和共享前缀深度,在大多数基准上优于 2x4 和 1x8 等替代方案。与平衡的 1x4 方法相比,增加前缀多样性或最大化后缀深度通常会导致较低的性能。1x4 配置在策略、数学和科学推理等任务中取得了最高分,证明了其在不同领域的鲁棒性。

作者使用两个语言模型在十个推理基准上比较了 SRPO 和 RRPO 与 GRPO 及相关基线。SRPO 成为最强的方法,在两个模型的大多数任务上都取得了最佳结果,而 RRPO 的性能与 GRPO 相当。这些在不同基准上的增益表明,仅从数学问题进行训练就具有强大的分布外泛化能力。对于 Qwen2.5-14B-Instruct 和 OLMo-3-7B-Instruct,SRPO 在大多数基准上优于所有其他评估方法。RRPO 在测试的推理任务上表现出与 GRPO 相似的性能水平。SRPO 的性能改进超越了训练领域,显示出对科学、策略和常识推理的有效泛化。
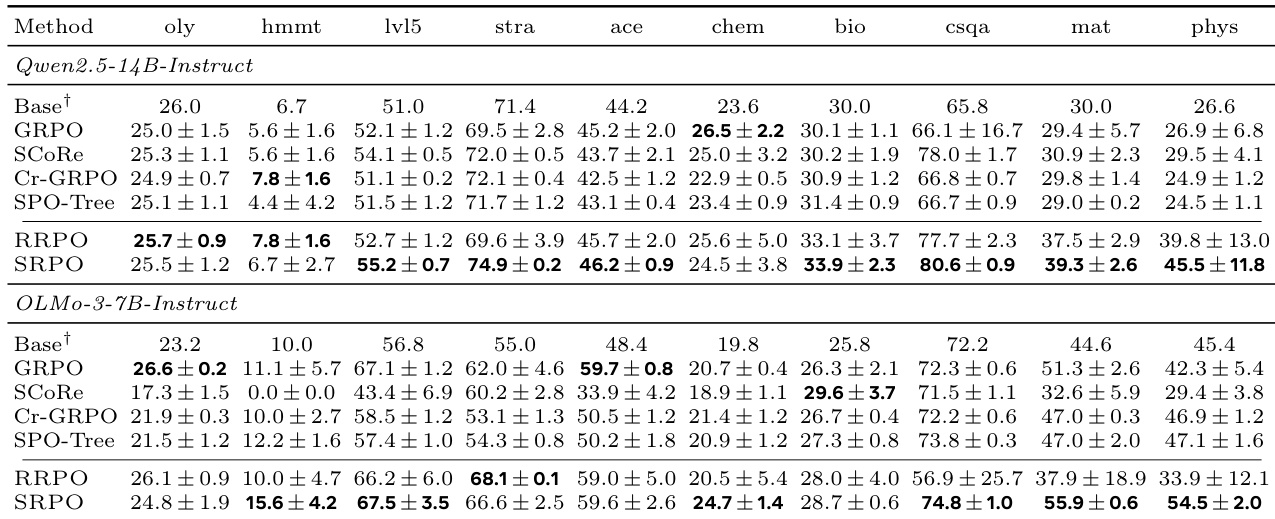
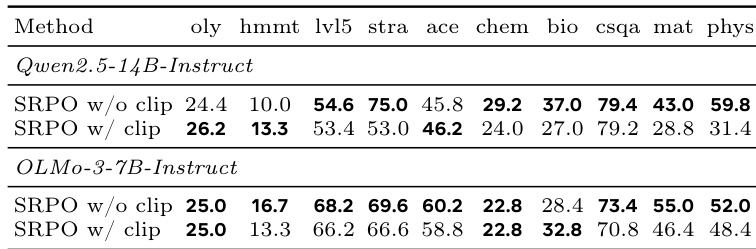
该表比较了 SRPO 变体的一般推理性能,特别分析了裁剪的影响,在两个语言模型上跨十个不同的基准进行。结果表明,与裁剪变体相比,无裁剪的 SRPO 配置在大多数数学、科学和策略任务上通常取得了更优的性能。对于 Qwen 和 OLMo 模型,无裁剪的 SRPO 变体在大多数基准上取得了最佳结果。裁剪似乎仅对少数特定任务有益,例如对于较大模型的奥林匹克数学和 HMMT。该方法在科学和常识领域表现出鲁棒的性能,反映了从以数学为重点的训练数据中的强泛化能力。
实验首先比较了 GRPO、RRPO 和 SRPO 的计算效率,发现虽然基于重置的方法会产生更高的训练时间和更慢的生成速度,但 SRPO 比 RRPO 更具资源效率。随后对采样策略的消融研究确立了 1x4 分割为 SRPO 的最佳选择,因为它平衡了基础策略覆盖和共享前缀深度,在大多数推理基准上取得了最佳性能。针对基线的更广泛评估表明,SRPO 在不同的推理任务上始终优于所有其他方法,展示了从仅数学训练中的强大分布外泛化能力,而 RRPO 的性能与 GRPO 相当。最后,对裁剪的分析表明,无裁剪的 SRPO 变体在大多数领域通常产生更优的结果。