Command Palette
Search for a command to run...
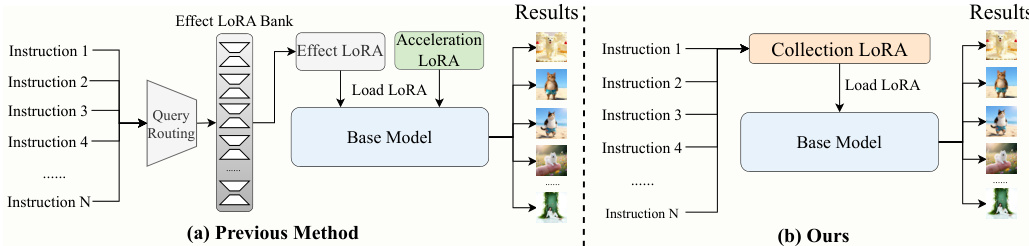
CollectionLoRA:通过多教师在线策略蒸馏在1个LoRA中收集50种效果
CollectionLoRA:通过多教师在线策略蒸馏在1个LoRA中收集50种效果
Fangtai Wu Hailong Guo Shijie Huang Jiayi Song Yubo Huang Mushui Liu Zhao Wang Yunlong Yu Jiaming Liu Ruihua Huang
摘要
定制化图像编辑旨在利用有限的配对数据,通常通过低秩自适应(LoRA),为预训练扩散模型赋予特定的视觉效果。随着所需效果数量的增加,存储并动态加载大量此类效果LoRA会显著增加部署开销。此外,现有流水线通常将这些效果LoRA与加速模块级联以实现快速生成,这会引发严重的参数干扰,导致概念串扰与风格退化。我们提出了CollectionLoRA,这是一种多教师在线策略蒸馏框架,能够将多达50种不同效果LoRA的概念以及少步生成能力蒸馏至单个LoRA中。这从根本上解决了特征干扰问题,并显著降低了部署成本。具体而言,该方法引入了(i)概率双流路由机制,使模型在训练期间能够在数据源之间随机切换,有效增强了其在未见场景中的泛化能力;(ii)非对称正交提示策略,以实现提示空间内的概念隔离;(iii)由粗到细的蒸馏目标,以缓解教师模型与学生模型之间的分布差异。大量评估表明,CollectionLoRA将所有定制化效果和少步生成蒸馏至单个LoRA中,在降低部署开销的同时,实现了与独立训练的教师模型相当或更优的概念保真度。
一句话总结
CollectionLoRA 是一个多教师同策略蒸馏框架,通过整合概率双流路由、非对称正交提示以及由粗到细的蒸馏目标,将多达五十种定制化视觉效果与少步生成能力整合至单个低秩自适应(Low-Rank Adaptation)模块中。该框架有效解决了特征干扰问题,在降低部署开销的同时,保持了与独立训练模型相当或更优的概念保真度。
核心贡献
- CollectionLoRA 是一个多教师同策略蒸馏框架,将多达 50 种定制化视觉效果与少步生成能力整合至单个低秩自适应(LoRA)模块中。该架构消除了级联多个适配器时固有的参数干扰,并将部署开销降低至传统流程的 0.5%。
- 该框架整合了概率双流路由机制、非对称正交提示策略以及由粗到细的蒸馏目标,以稳定多源训练过程。这些组件在提示空间中强制执行严格的概念隔离,并弥合教师模型与学生模型之间的分布差异,从而防止特征崩溃。
- 在 EffectBench 基准上的广泛评估表明,蒸馏模型在扩展至 180 种不同效果时,其概念保真度达到或超越了独立训练的教师模型。统一架构进一步支持在推理阶段进行零样本效果组合,且无需额外训练或架构修改。
引言
扩散模型通过任务特定的低秩自适应(LoRA)模块实现了精确且高质量的内容修改,从而彻底改变了定制化图像编辑领域。然而,在加速层旁部署多个专用 LoRA 会引发显著瓶颈,包括沉重的存储开销、动态路由延迟以及导致概念串扰和风格退化的参数冲突。为解决这些部署挑战,研究人员利用多教师同策略蒸馏技术提出了 CollectionLoRA 框架,该框架将多样化的视觉效果与少步生成能力整合至单一统一模块中。通过概率双流路由、非对称正交提示以及由粗到细的蒸馏目标,训练过程得以稳定,这些技术共同保留了泛化能力,隔离了冲突概念,并弥合了分布差异。该架构成功将数十种视觉效果压缩至单个 LoRA 中,在大幅降低部署成本的同时,实现了不牺牲保真度的零样本效果组合。
方法
研究人员利用多教师同策略蒸馏框架 CollectionLoRA,将多达 50 种多样化的视觉效果与少步生成能力整合至单个低秩自适应(LoRA)模块中,从而消除了传统多 LoRA 系统相关的部署开销与参数干扰。该框架通过训练学生生成器来逼近多个预训练的效果专用教师 LoRA 的输出分布,使得统一模型能够在推理过程中无需动态加载或组合即可生成多样化效果。
参见框架示意图,该图展示了 CollectionLoRA 的整体架构。该方法基于分布匹配蒸馏(DMD)原理,其中学生生成器被训练以匹配教师模型的数据分布。为确保与推理阶段使用的少步生成过程保持一致,框架采用反向模拟来生成训练目标,以模拟多步推理的累积采样轨迹。此过程涉及从纯噪声开始迭代去噪与重新加噪,直至达到特定时间步,从而生成捕获所需生成特征的模拟清晰图像。随后,生成器被训练以对模拟样本的噪声版本进行去噪,其目标在于匹配真实分布与生成分布的得分函数。
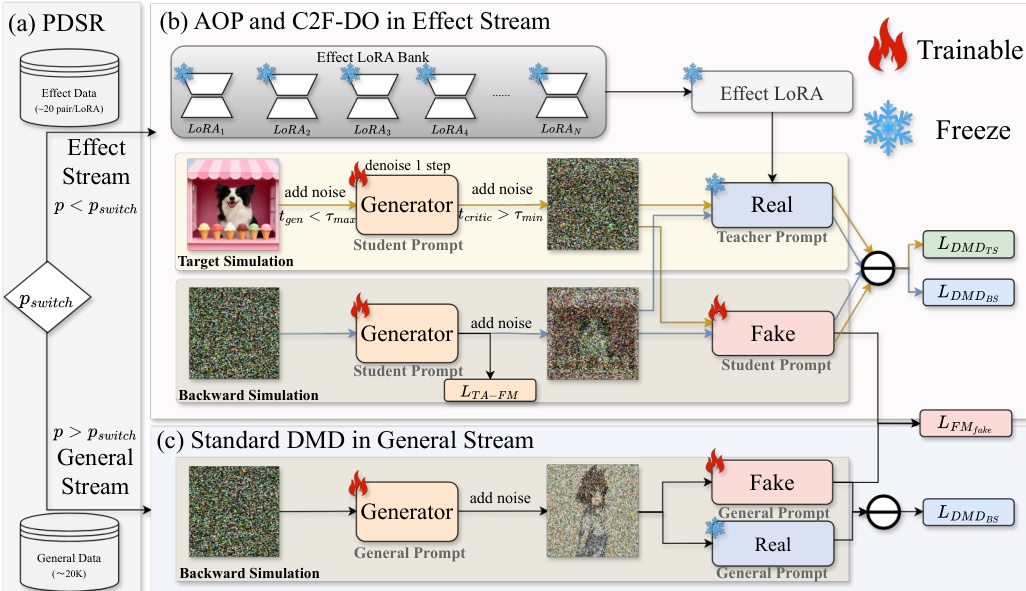
如图所示,该框架围绕概率双流路由机制构建,该机制根据切换概率动态将训练批次分配至两个流之一。在通用流中,模型使用冻结的基础模型作为教师,在无标签的通用领域数据上进行训练,并通过反向模拟应用标准 DMD 损失,以维持基础泛化能力并防止灾难性遗忘。在效果流中,模型专注于整合特定视觉效果。该流利用效果库中的冻结效果 LoRA 作为教师,学生生成器被训练以学习目标分布与去噪轨迹。效果流中的训练过程进一步引入了由粗到细的蒸馏目标,以解决训练初期学生模型与教师模型之间显著的分布差异。
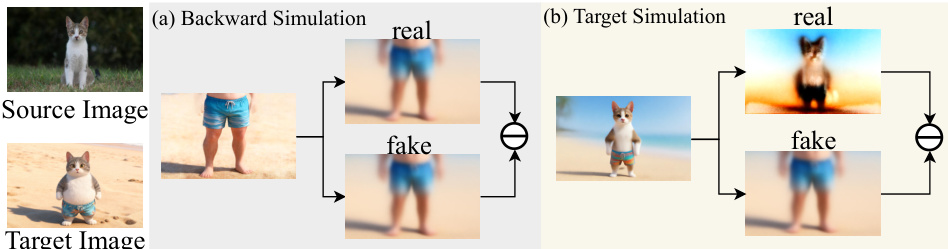
为减轻特征干扰并确保共享参数空间内的概念隔离,研究人员引入了非对称正交提示策略。该方法为教师模型与学生模型使用不同的提示词。教师模型使用其原始训练提示词,而学生模型则使用一个独特的正交触发词,并结合由视觉语言模型生成的描述性标题,从而确保概念的清晰分离。由粗到细的蒸馏目标结合了基于流匹配的轨迹锚定以稳定早期训练,以及目标模拟分布匹配以恢复高频细节。最终的整体目标是通用流与效果流损失的加权和,该权重由每次迭代的路由决策确定,从而确保学生模型以统一的方式同时获取通用知识与特定效果能力。
实验
在涵盖动物与肖像类别的多样化基准上进行的评估表明,实验设置将所提框架与单效果、加速及统一多任务基线方法进行对比,以验证生成保真度、结构一致性与部署效率。定性与定量分析证明,联合蒸馏策略有效消除了纹理丢失、风格串扰与泛化崩溃,同时在重度概念压缩下保持了稳健的主体保持能力。进一步的消融与扩展实验证实,各架构模块均针对特定的优化瓶颈发挥作用,实现了无缝的增量扩展、稳定的训练动态,并涌现出无需额外微调的零样本组合能力。
研究人员在 50 合 1 的并发蒸馏设置下开展了消融研究,以评估方法中不同组件的影响。结果表明,包含所有提出组件的完整配置在多项指标上均取得最佳性能,特别是在风格对齐、主体一致性与指令遵循质量方面,同时显著降低了失败率。研究证明,每个组件均对特定改进有所贡献,其组合实现了稳定训练与更优的整体结果。与消融版本相比,完整模型配置在 CLIP、DreamSim、VSA、EditReward 指标上得分最高,且坏例率(Bad Case Rate)最低。所有组件的整合带来了稳定的训练动态与改善的收敛性,优于仅包含部分组件的配置。每个组件均贡献于特定改进,例如减少概念串扰、恢复高频纹理以及增强结构一致性。

研究人员将所提方法与结合基础模型与加速 LoRA 的基线方法进行对比,评估了在不同 LoRA 数量下的性能。结果表明,所提方法在所有测试配置中均持续获得高于基线方法的分数,且随着 LoRA 数量增加,性能波动极小。所提方法在所有测试的 LoRA 数量下均优于基线方法。随着 LoRA 数量增加,所提方法的性能保持稳定。在所有评估设置中,基线方法的得分均低于所提方法。

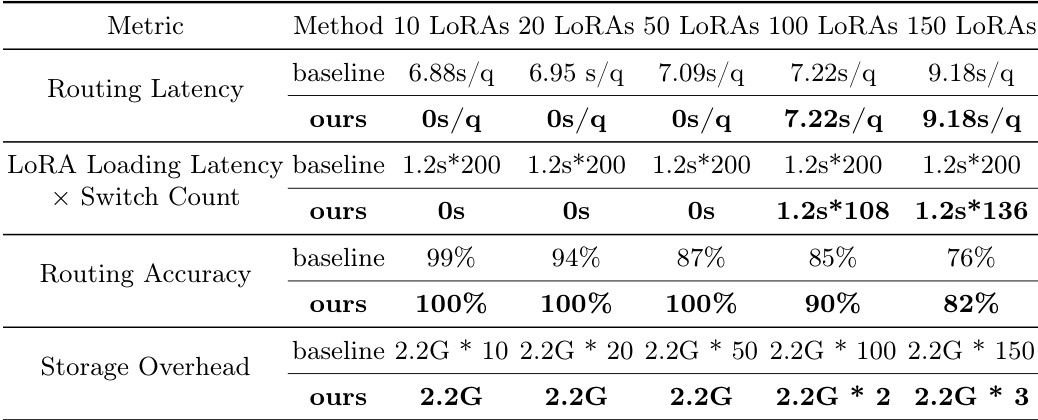
研究人员从部署效率角度将所提方法与基线方法进行对比,重点关注不同 LoRA 数量下的延迟、准确率与存储开销。结果表明,所提方法实现了零路由延迟,保持 100% 的路由准确率,且存储开销恒定,优于随着 LoRA 数量增长而延迟增加、准确率下降的基线方法。该方法在不同 LoRA 数量下均表现出一致的性能,证明了其鲁棒性与可扩展性。所提方法在所有 LoRA 配置下均实现零路由延迟与 100% 路由准确率,优于延迟递增且准确率递减的基线方法。与基线方法的线性增长不同,所提方法的存储开销始终保持在 2.2GB。即使 LoRA 数量增加,该方法仍能保持性能稳定且退化极小,充分展现了其可扩展性与高效性。
研究人员对用于多效果图像生成的统一模型进行了评估,在不同 LoRA 数量下将其与基线方法进行对比。结果表明,所提方法在不同规模下均保持了具有竞争力的性能,在特定设置中优于其他替代方案,并展现出对复杂度增加的鲁棒性。所提方法在不同 LoRA 数量下均取得具有竞争力的性能,在某些配置中优于基线方法。随着 LoRA 数量增加,模型性能保持稳定,显示出对可扩展性挑战的适应能力。该方法在特定场景中始终优于基线方法,表明其能有效处理多概念融合。

研究人员在针对多效果图像生成的基准上开展了定量评估,将所提方法与基线方法进行对比。结果表明,所提方法在风格对齐与整体质量方面表现更优,同时显著降低了失败率,优于单效果与多任务基线方法。该方法在极端概念压缩与扩展条件下仍保持强劲的主体一致性与鲁棒性。所提方法在风格对齐与整体图像质量上超越基线方法,并实现了大幅降低的失败率。尽管传统指标略有下降,该方法在极端概念压缩下仍能维持强劲的主体一致性与结构保真度。该方法能有效扩展至大量效果,并支持增量扩展而无需担忧灾难性遗忘。

并发蒸馏设置下的消融研究证实,每个提出的组件均针对特定局限性发挥作用,其完整整合带来了稳定训练,并显著提升了风格对齐、主体一致性与结构保真度。随着适配器数量增加的对比评估表明,该方法保持了稳定的生成质量与部署效率,避免了基线方法典型的延迟飙升与准确率下降问题。针对多效果图像生成的额外基准测试进一步验证了模型对概念压缩的鲁棒性与可扩展性,表明其能够在不引发灾难性遗忘的情况下有效融合多种风格,同时提供卓越的整体质量。