Command Palette
Search for a command to run...
从激活到因果:人类大脑中因果视觉表征的发现
从激活到因果:人类大脑中因果视觉表征的发现
Yuval Golbari Navve Wasserman Matias Cosarinsky Roman Beliy Aude Oliva Antonio Torralba Michal Irani Tamar Rott Shaham
摘要
确定人脑中哪些脑区表征视觉概念是神经科学的核心挑战之一。现有方法通过激活最大化技术定位了粗略的功能区域(例如面孔、地点),识别出相对于其他概念对目标概念激活较强的脑区。然而,仅凭强激活并不能确立该脑区表征的是概念本身,因为神经反应可能实际上是由相关的视觉或语义线索驱动的。我们提出了BrainCause,这是一个自动化框架,它结合生成模型与脑模型来合成受控刺激,并通过定向因果测试验证神经表征。给定一个指定感兴趣概念的查询,我们的框架构建包含概念图像、在保留其他图像内容的同时移除目标概念的反事实编辑图像,以及包含候选相关干扰项图像的定向刺激集。随后,该框架使用图像到fMRI的编码模型预测脑反应,并搜索相对于相关替代选项专门对目标概念产生响应的表征。BrainCause返回经过验证的候选表征,并提出后续的fMRI实验以进一步测试或扩展其发现。我们的方法成功恢复了已知的功能定位,并在数十个概念上识别出新的候选表征,这些结果在预测的和实测的fMRI数据上均得到了验证。关键在于,我们表明若无因果验证,大量定位结果将是假阳性,这证实了仅凭激活不足以作为表征的证据。
一句话总结
作者提出了 BrainCause,这是一个自动化框架,结合了生成模型与脑模型,用于合成反事实刺激,并利用图像到 fMRI 的编码模型进行针对性因果测试,从而分离出概念特异性的神经表征,并引导超出传统基于激活定位的后续 fMRI 验证。
核心贡献
- 本文介绍了 BrainCause,这是一个自动化框架,将生成式图像模型与图像到 fMRI 的编码模型相结合,以区分 fMRI 数据中的真实概念表征与相关的视觉或语义线索。
- 该方法采用针对性的因果测试流程,生成反事实图像编辑和相关干扰项,以预测体素级神经响应,并分离出专门对目标概念产生响应的脑区。
- 该框架输出特定概念的经验证候选表征,并提出针对性的后续 fMRI 实验建议,以进一步测试或扩展已发现的神经模式。
引言
理解人脑如何编码视觉概念是神经科学的基础目标,然而传统 fMRI 研究一直难以突破相关性激活模式的局限。先前的方法通常利用激活最大化来识别对目标概念表现出强响应的脑区,但这些方法无法区分真实的概念表征与由背景、颜色或姿态等相关视觉或语义线索驱动的响应。这经常导致假阳性结果,并使研究人员缺乏明确的实验验证指导。作者利用生成式视觉模型、大语言模型和图像到 fMRI 编码网络,推出了 BrainCause。这是一个自动化框架,通过构建包含反事实编辑和语义干扰项的受控刺激集来进行针对性因果测试。通过将目标概念与共现特征隔离开来,该框架验证了真实的神经表征,过滤了虚假激活,并自动提出信息丰富的后续实验建议,从而在计算发现与实证验证之间形成闭环。
数据集
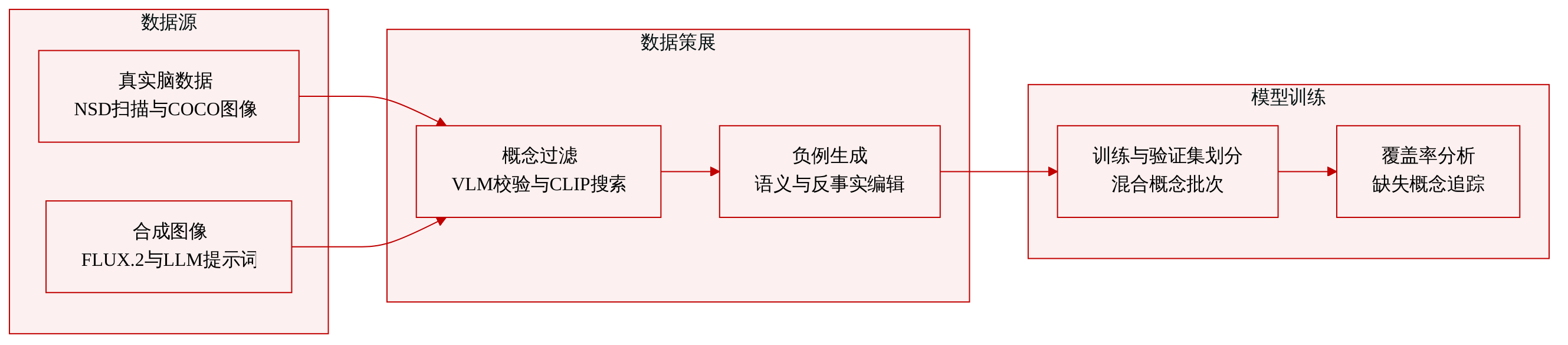
-
数据集构成与来源: 作者结合真实数据与合成数据,构建了一个以概念为目标的图像-fMRI 数据集。真实神经响应取自预处理后的自然场景数据集(NSD),该数据集包含 8 名受试者观看的约 10,000 张来自 COCO 的自然图像所对应的 7T fMRI 记录。团队还使用 120,000 张未标注的 COCO 图像构建了一个大型预测 fMRI 池。
-
子集详情:
- 正样本图像:作者使用 Gemma-3-27B-IT 生成的提示词和 FLUX.2 文生图模型,为每个概念生成 200 张训练图像和 100 张验证图像。额外的正样本直接从 NSD 中检索。
- 语义负样本图像:流程为每个目标提出 10 个反概念,为每个反概念生成 10 条提示词,并使用 FLUX.2 合成图像。经过视觉语言模型过滤后,生成约 80 至 100 张训练和验证负样本。测量的负样本也通过两阶段 CLIP 搜索获取。
- 反事实负样本图像:作者将大语言模型生成的编辑指令应用于 50 张训练和 20 张验证正样本图像,经过基于模型的验证后,生成约 400 至 500 张反事实负样本。
-
数据使用与处理: 作者将生成的刺激物划分为明确的训练集和验证集。所有合成图像均通过图像到 fMRI 编码器传递,以生成每个受试者的预测脑响应。作者在固定混合数据上进行训练,包含每个概念 200 张正样本、约 80 至 100 张语义负样本和 400 至 500 张反事实负样本。检索到的真实图像与预测配对数据用于验证已发现的神经表征,并与 MindSimulator 等基线方法进行对比。
-
额外处理与元数据: 团队预先计算了 NSD 和 120,000 张外部图像的 CLIP 嵌入,以实现快速的概念检索。Qwen3-VL-8B 视觉语言模型用于验证生成图像和检索图像中目标概念的存在与否。测量的 fMRI 响应通过将所有图像中每个体素的值标准化为零均值和单位标准差进行处理,确保激活值反映相对神经响应。每个样本均附带概念标签与验证标记,以跟踪训练集划分、检索成功率和覆盖缺口。
方法
BrainCause 框架主要包含三个阶段:因果数据集生成、概念选择性表征搜索,以及包含后续实验设计的验证。该流程以目标概念和受试者的图像-fMRI 数据集为起点,最终输出候选体素集以及该概念神经表征的置信度估计。
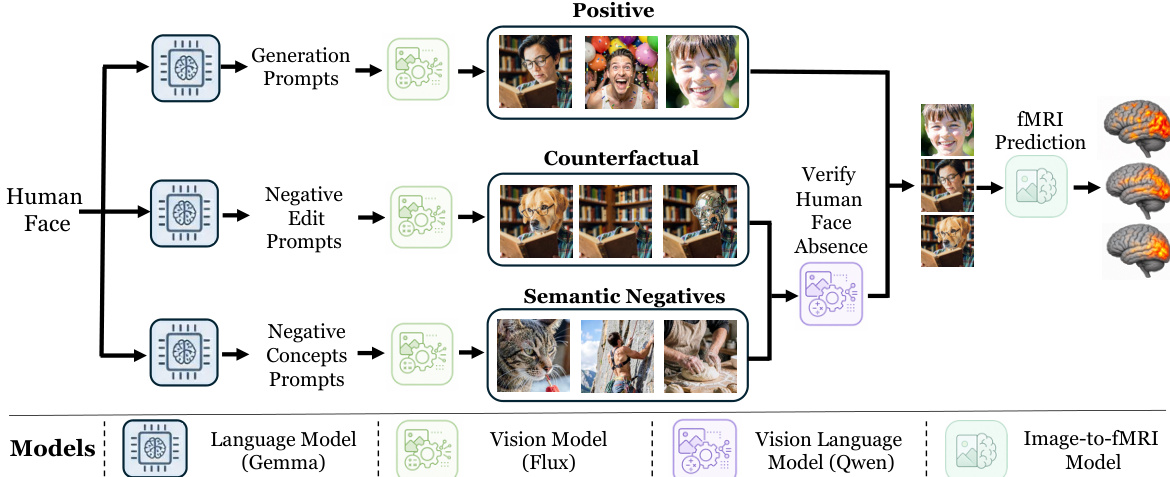
框架示意图展示了因果数据集生成的整体流程。给定一个目标概念,BrainCause 会构建包含三类刺激的数据集:正样本图像、反事实图像和语义负样本。正样本图像用于表征目标概念。反事实图像通过从原图中移除目标概念并尽可能保留背景来创建,从而隔离该概念的视觉贡献。语义负样本描绘相关但不同的概念,旨在捕捉混淆性语义因素。语言模型为每种刺激类型生成提示词,文生图模型利用这些提示词合成图像。视觉语言模型用于验证每张生成图像中目标概念的存在与否。所有图像随后通过图像到 fMRI 模型,以获取预测的神经响应。
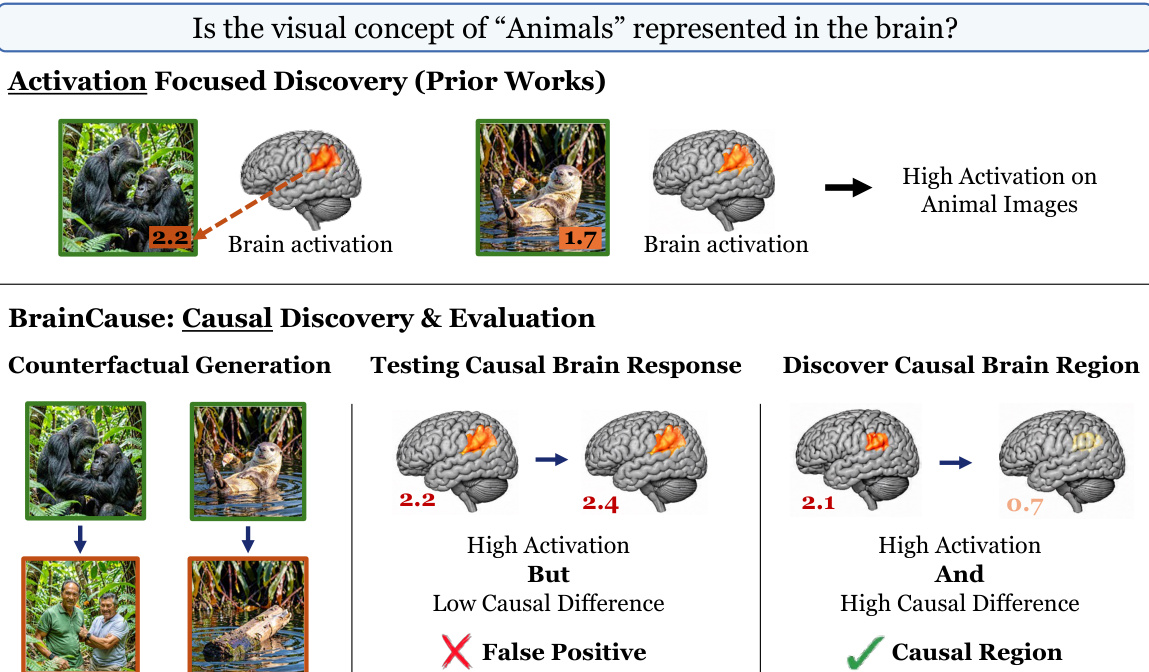
如图所示,概念选择性表征搜索阶段为每个体素分配三个分数。激活分数衡量体素对正样本图像的平均响应。语义负样本分数通过将正样本图像上的激活与最能激活该体素的前 10 张语义负样本图像上的平均激活进行对比,来评估特异性。反事实分数通过将每张正样本图像上的激活与其最难编辑的对应版本上的激活进行对比,来评估特异性,其中最难编辑的版本是指对该体素产生最高激活的编辑版本。体素的因果分数是语义负样本分数与反事实分数的平均值。候选表征由所有因果分数为正的体素集合或预定义数量的排名前几位体素构成。该体素集即作为表征概念的目标区域。
最终结论由两个主要指标决定。首先是已发现候选表征的因果证据,通过其在生成评估数据集和实测数据评估中的因果分数来衡量。两项指标的高分表明该体素集更有可能专门针对目标概念而非相关替代概念产生响应。其次是实测数据中的概念覆盖率,通过分析在实测图像-fMRI 数据集中能够成功检索并验证的目标正样本与语义负样本图像比例来估算。这反映了实测数据对验证的信息价值。基于因果证据与概念覆盖率,框架返回最终结论、候选表征,并在必要时提供一组用于后续实验的信息性图像。
实验
在包含四个受试者的自然场景数据集上对 BrainCause 进行评估,并与基于激活的方法和仿真驱动方法进行基准测试,以验证因果区域发现、功能对齐及跨受试者一致性。结果表明,因果排序通过过滤由相关视觉因素驱动的脑区,有效消除了虚假定位,同时分离出与已知功能脑网络相对应的空间精确区域。此外,该方法成功捕捉了相关概念间的细粒度差异,并展示了跨个体的可重复皮层映射,证实了结合多种因果信号能够生成稳健且符合生物学特性的神经表征。
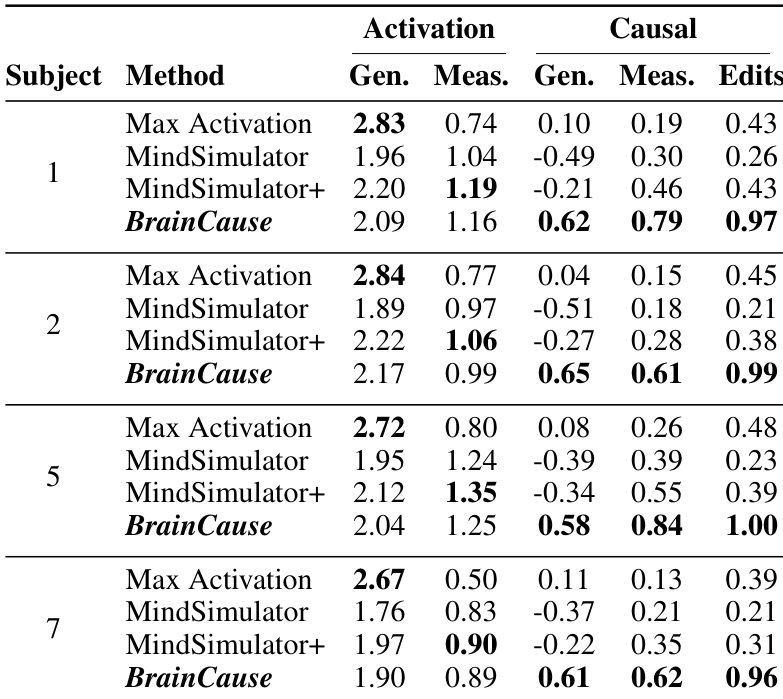
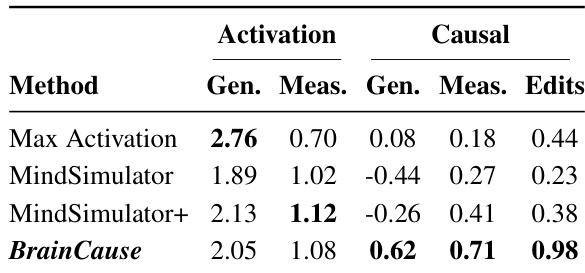
作者在 fMRI 数据上对比了多种区域发现方法,重点关注不同受试者的激活与因果分数。结果表明,BrainCause 在保持强激活的同时实现了更高的因果分数,优于那些经常产生高激活但低因果性的基于激活的方法。该方法在不同受试者中持续提升了因果验证效果,并在识别概念特异性脑区方面表现出鲁棒性。与基于激活的方法相比,BrainCause 在保持强激活的同时获得了更高的因果分数。基于激活的方法表现出高激活但低因果性,表明存在大量假阳性。BrainCause 在不同受试者的因果验证中持续优于其他方法,展现出稳健性与可靠性。
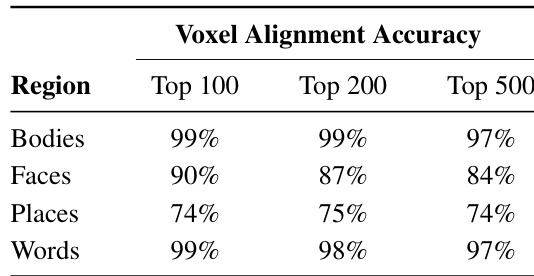
作者评估了因果发现的脑区与四个类别(身体、面孔、地点、文字)已知功能区之间的对齐情况。表格显示,对于前 100 个体素,BrainCause 发现的区域与已知功能区域高度对齐,在身体、面孔和文字类别上准确率较高。即使考虑更大范围的区域,对齐效果依然显著,尽管在体素数量增加时,地点类别的对齐度略有下降。结果表明,因果发现的区域具有空间局部性,且与已知的功能组织结构一致。BrainCause 发现的区域与已知功能区高度对齐,尤其在身体、面孔和文字类别中表现突出。不同区域尺寸下的对齐准确率均保持在较高水平,地点类别在较大体素数量时略有下降。因果发现的区域具有空间局部性,且跨类别与已知功能组织结构保持一致。
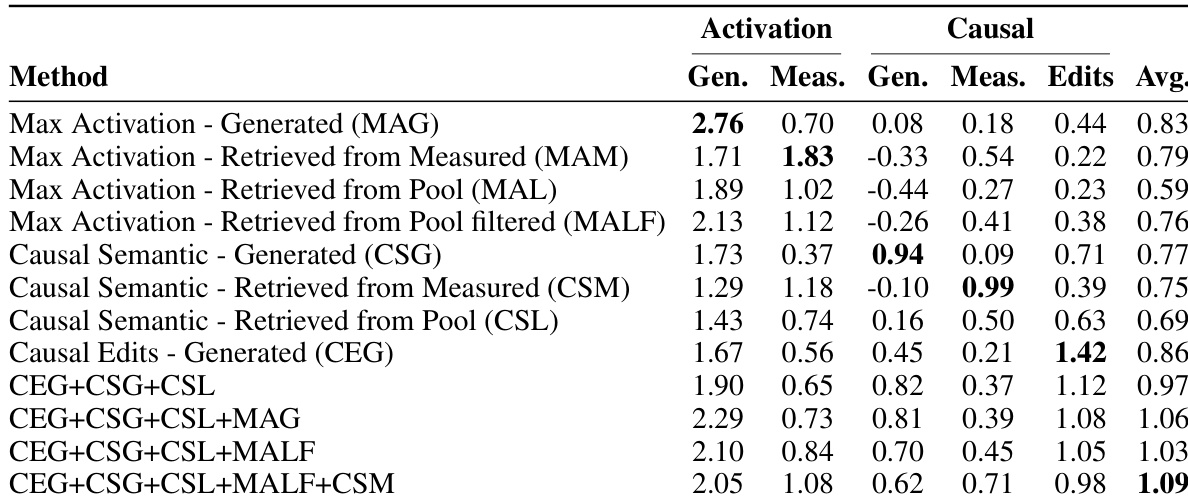
作者对比了多种用于发现与视觉概念相关脑区的方法,重点关注激活与因果性。结果表明,基于激活的方法能达到较高的激活分数,但在因果评估中表现不佳;而提出的方法结合了激活与因果信号,在保持高激活的同时,显著提升了不同评估标准下的因果分数。多种互补信号的整合促成了更具选择性和忠实度的区域发现。基于激活的方法虽获得高激活分数,但因果特异性较低,表明存在大量假阳性。提出的方法通过整合多种排序信号,在保持相当激活水平的同时大幅提高了因果分数。与仅使用激活信号相比,结合激活与因果信号能够带来更具选择性和可靠性的区域发现。
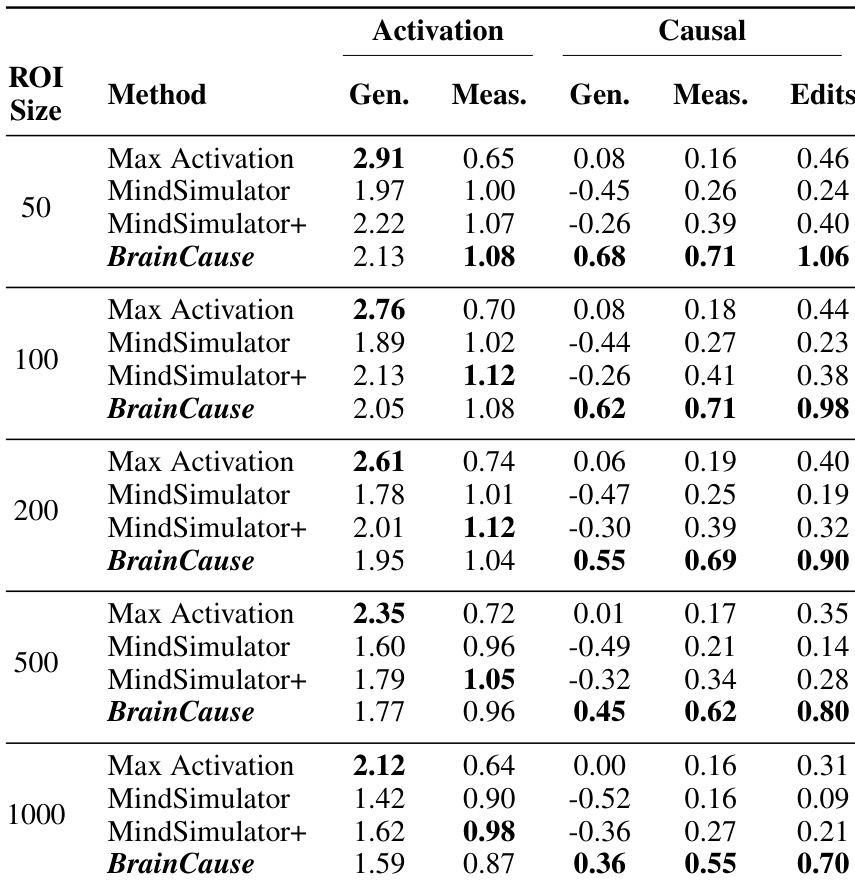
作者对比了多种发现视觉概念相关脑区的方法,重点关注不同区域尺寸下的激活与因果分数。结果表明,BrainCause 在保持具有竞争力的激活水平的同时实现了更高的因果分数,尤其在生成数据与实测数据的语义负样本及反事实编辑上表现显著提升。该方法在所有测试的区域尺寸和受试者中,因果评估效果均持续优于其他方法。与基于激活的方法相比,BrainCause 在保持强激活性能的同时获得了更高的因果分数。BrainCause 提升了生成数据与实测数据上的因果验证效果,尤其在语义负样本和反事实编辑方面。BrainCause 在因果发现方面的优势在不同区域尺寸和受试者中保持一致。
作者在 fMRI 数据上对比了多种区域发现方法,评估其识别既受目标概念强烈激活又对其具有因果特异性的脑区的能力。结果表明,BrainCause 结合了激活与因果信号,与基于激活的方法相比,在保持具有竞争力的激活水平的同时实现了更高的因果分数。该方法生成了更具选择性和空间局部性的区域,与已知功能区对齐,并在不同受试者中展现出一致的性能。与基于激活的方法相比,BrainCause 在多项评估标准下均实现了更高的因果分数,同时保持了强激活水平。该方法生成了更具选择性和空间局部性的区域,减少了假阳性,并与已知功能脑区对齐。BrainCause 在不同受试者和区域尺寸下的因果验证中持续优于其他方法。
实验在 fMRI 数据上将 BrainCause 与传统基于激活的方法进行对比,以评估其识别概念特异性脑区的能力。通过整合激活与因果信号,该方法在多样化的受试者、区域尺寸和概念类别中验证了其卓越的因果特异性与空间定位能力。定性来看,该方法在保持强激活水平的同时显著降低了假阳性,并持续将发现的区域与视觉概念的已知功能区对齐。这些发现表明,与仅依赖激活信号相比,结合互补信号能够生成更具选择性和可靠性的神经解剖学映射。