Command Palette
Search for a command to run...
精神科诊断的自动化ICD分类:从经典NLP到大语言模型
精神科诊断的自动化ICD分类:从经典NLP到大语言模型
Fernando Ortega Raúl Lara-Cabrera Jorge Dueñas-Lerín Alejandro de la Torre-Luque Mercé Salvador Robert Enrique Baca-García
摘要
心理健康已成为全球优先事项,导致临床诊断编码工作面临巨大的行政负担。本研究提出利用自然语言处理(NLP)和机器学习(ML)技术,将自由文本描述映射至《国际疾病分类》(ICD),从而实现精神科诊断分析的自动化。研究利用包含145,513条西班牙语精神科描述的专用数据集,评估了多种文本表示范式,从传统的基于频率的模型(如词袋模型 BoW、TF-IDF)到最先进的Large Language Models (LLMs),例如 e5_large、BioLORD 和 Llama-3-8B。结果表明,基于 Transformer 的嵌入表示在捕捉隐含语义线索和细微的医学术语方面表现优异,其性能始终优于传统方法。通过端到端微调,e5_large 模型取得了最佳性能,其 F1micro 得分为 0.866。本研究证明,针对特定临床术语体系对 LLMs 进行适配,对于克服“长尾”标签分布挑战以及精神科话语中固有的歧义性问题至关重要。
一句话总结
通过对145,513份西班牙精神科病历描述的分析,本研究证实,对e5_large模型进行端到端微调可在自动化ICD分类中达到0.866的F1_micro得分,该模型通过捕捉细微的临床语义以应对长尾标签分布与诊断歧义,其表现持续优于传统自然语言处理方法。
核心贡献
- 本研究在包含145,513份西班牙精神科描述的专业数据集上,评估了多种文本表示范式,涵盖从传统基于频率的模型到最新的大型语言模型。
- 基于Transformer的嵌入表示通过捕捉隐含语义线索与细微的医学术语,持续优于传统方法,其中端到端微调的e5_large模型取得了0.866的F1_micro得分。
- 研究结果表明,将大型语言模型适配至特定临床命名体系,可有效解决长尾标签分布问题以及精神科诊断文本固有的歧义性。
引言
自动化临床编码将自由文本形式精神科笔记转化为标准化的ICD诊断,这是医疗数据分析与研究中的关键工作流,目前该流程仍依赖易产生不一致性的高人力成本人工操作。先前的计算方法(涵盖传统基于频率的模型至早期神经网络架构)难以应对心理健康文档的主观性、临床编码极端的多元标签结构,以及现成语言模型容易产生幻觉或遗漏罕见诊断的倾向。为克服上述局限,本研究在大型西班牙精神科语料库上评估了广泛的文本表示技术,证实基于Transformer的嵌入表示能够持续捕捉准确分类所需的隐含语义线索。通过对e5_large模型进行端到端微调,研究实现了当前最优性能,并表明领域适配的大型语言模型对于管理长尾标签分布及精神科文本固有歧义至关重要。
数据集

- 数据集构成与来源: 研究采用了一个包含超过145,000份真实世界心理健康诊断描述的大型西班牙临床语料库。
- 子集详情: 该集合作为单一统一数据集使用,提供的文本中未包含明确的子集划分、预定义过滤规则或训练集/验证集/测试集拆分。所有条目均代表专注于精神科疾病的临床诊断文本。
- 数据使用与处理: 该数据集驱动了一个对比分类流水线,用于评估传统的词袋模型与TF-IDF基线同来自e5_large和BioLORD的Transformer嵌入表示之间的性能差异。研究将XGBoost指定为密集上下文向量的主要分类器,并部署多层感知机处理高维稀疏特征。通过大型语言模型的端到端微调达到峰值性能,最终取得0.866的Micro F1得分。
- 处理考量与挑战: 尽管未详细说明明确的裁剪或元数据构建步骤,但研究实施了应对极端类别不平衡的策略。该流水线专门针对低患病率的精神科疾病,表明语义深度必须与稳健的建模技术相结合,以应对长尾分布挑战。
方法
研究采用多阶段框架,用于评估将心理健康诊断描述自动分类为ICD代码的文本表示技术。流水线始于由145,513份西班牙语自由文本描述组成的原始输入数据,这些数据经历以文本增强与标准化为核心的预处理阶段。该阶段包括使用正则表达式识别并扩展缩写ICD代码,随后进行基于规则的规范化处理,以去除非信息性字符并统一格式。处理后的文本随后通过多种表示策略转换为数值特征,这些策略被归类为传统方法与基于嵌入的方法。
如图所示,传统方法包括词袋模型与词频-逆文档频率模型,它们基于词频将临床笔记表示为高维稀疏向量。随后是采用旨在捕捉更丰富语义信息的嵌入方法。潜在语义分析与潜在狄利克雷分配被用于提取潜在主题结构,在保留主题内容的同时降低维度。Doc2Vec通过在西班牙精神科笔记语料库上进行训练,生成稠密且固定长度的文档向量,以捕捉上下文依赖关系。此外,研究利用最新的大型语言模型获取深度上下文嵌入表示,其中临床文本通过Transformer架构传递以提取最终的隐藏状态表示,从而编码复杂的语义与句法关系。
生成的表示被输入至三种不同的分类模型中,每种模型均针对任务的多元标签特性进行设计。第一类为传统机器学习方法,具体包括随机森林与XGBoost,它们在从文本表示派生的各类特征集上进行训练。这些模型采用多输出配置运行,使其能够同时处理全部85个标签,并潜在地对诊断间的依赖关系进行建模。第二类采用深度学习,其中多层感知机被设计用于适应多样化的输入特征。该网络架构在超参数调优期间进行动态优化,其固定输出层包含85个神经元,采用Sigmoid激活函数与二元交叉熵损失,用于预测每个ICD代码的存在情况。最终方法涉及大型语言模型的端到端微调,即在Transformer主干网络后附加任务特定的分类头,并使用专业数据集更新模型权重。该策略使模型能够将其内部表示适配至临床命名体系与ICD代码的长尾分布,代表了该分类框架中最为复杂且计算密集的一层。
实验
本研究利用分层临床数据集,通过系统比较传统基于频率的文本表示、经典嵌入表示与现代大型语言模型嵌入表示,在多种分类器架构上评估自动化精神科编码性能。实验验证了基于Transformer的嵌入表示能够有效捕捉精神科文档的隐含语义细微差别,同时表明实现最优性能需要将特定的分类器架构与相应的特征类型相匹配。定性来看,研究结果强调语义深度在复杂诊断描述中显著优于显式关键词匹配,但严重的类别不平衡持续阻碍罕见病症的准确编码,且该问题不受模型复杂度的影响。最终,研究确立上下文嵌入的任务特定适配为临床编码系统提供了最稳健的基础,尽管未来工作必须优先解决数据稀缺问题并提升模型可解释性,以促进更广泛的临床采用。
研究对精神科诊断编码的文本表示与分类模型进行了对比分析,重点关注基于Transformer的嵌入表示与各类分类器的性能表现。结果显示,微调后的大型语言模型嵌入表示持续优于其他方法,其中XGBoost成为处理密集上下文特征的最有效分类器,而多层感知机在稀疏基于关键词的输入上表现更佳。研究强调了类别不平衡与数据稀缺的挑战,尤其是针对罕见诊断,并表明模型选择应与所使用的表示类型保持一致。微调的大型语言模型嵌入表示在所有配置下均取得最高性能。XGBoost是密集上下文嵌入的最有效分类器,而多层感知机擅长处理稀疏基于关键词的特征。Micro与Macro F1得分之间的性能差距凸显了因数据稀缺导致罕见诊断代码分类困难的问题。
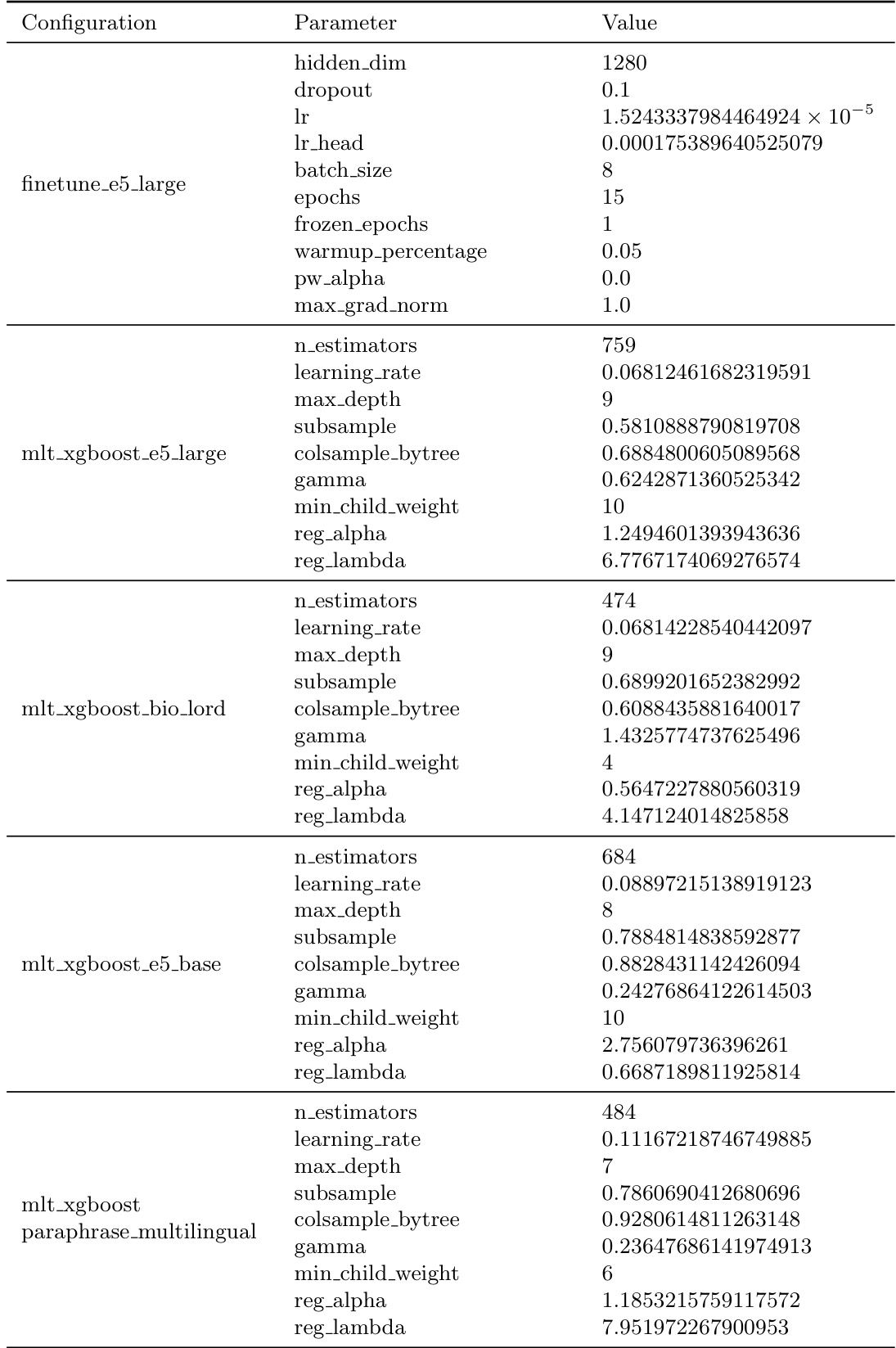
研究分析了精神科数据集中ICD-10代码的分布情况,揭示出长尾模式,即少数代码占据绝大多数出现频次,而绝大多数代码频率较低。该分布为分类模型带来了显著挑战,因为表现最佳的模型在不同类别上的性能差异较大,高频代码表现较好,而罕见代码表现较差。数据集中少数ICD-10代码占据绝大多数出现频次,而大部分代码频率极低。代码的长尾分布导致模型性能出现显著差异,高频类别结果较好,罕见类别结果较差。分类模型的性能高度依赖诊断代码的频率,高频代码取得更高的精确率与召回率。
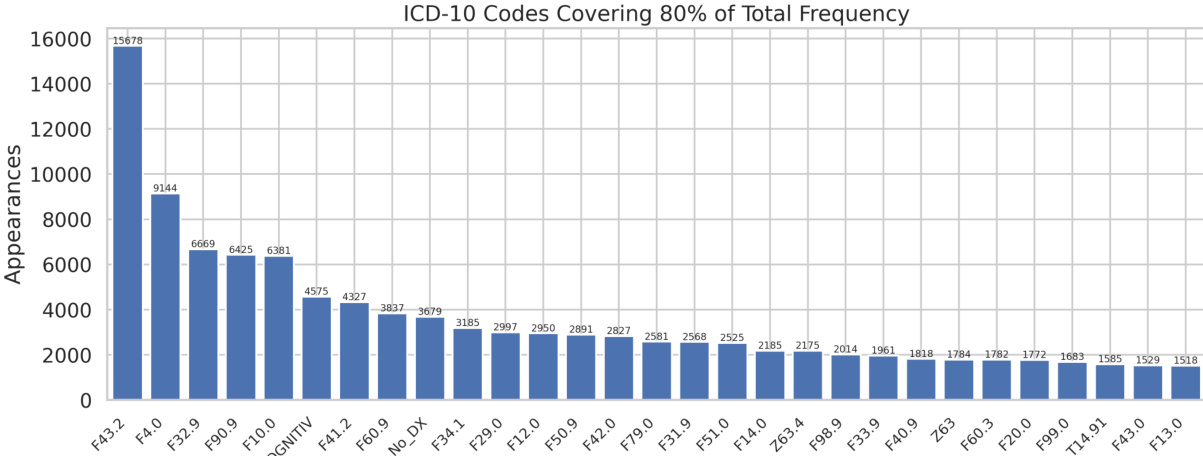
研究对比了精神科诊断编码的各种文本表示技术与分类模型,使用F1得分及其他指标评估其性能。结果显示,基于Transformer的嵌入表示持续优于传统方法,其中XGBoost成为密集嵌入的最佳分类器,而多层感知机在稀疏特征上表现更佳。对表现最佳的模型进行微调在测试数据上实现了最高的整体性能。基于Transformer的嵌入表示在所有分类模型中持续优于传统文本表示方法。XGBoost配合密集嵌入取得最高性能,而多层感知机在稀疏基于关键词的特征上表现更佳。对表现最佳的模型进行微调带来了最高的测试F1得分,表明通过任务特定适配提升了性能。
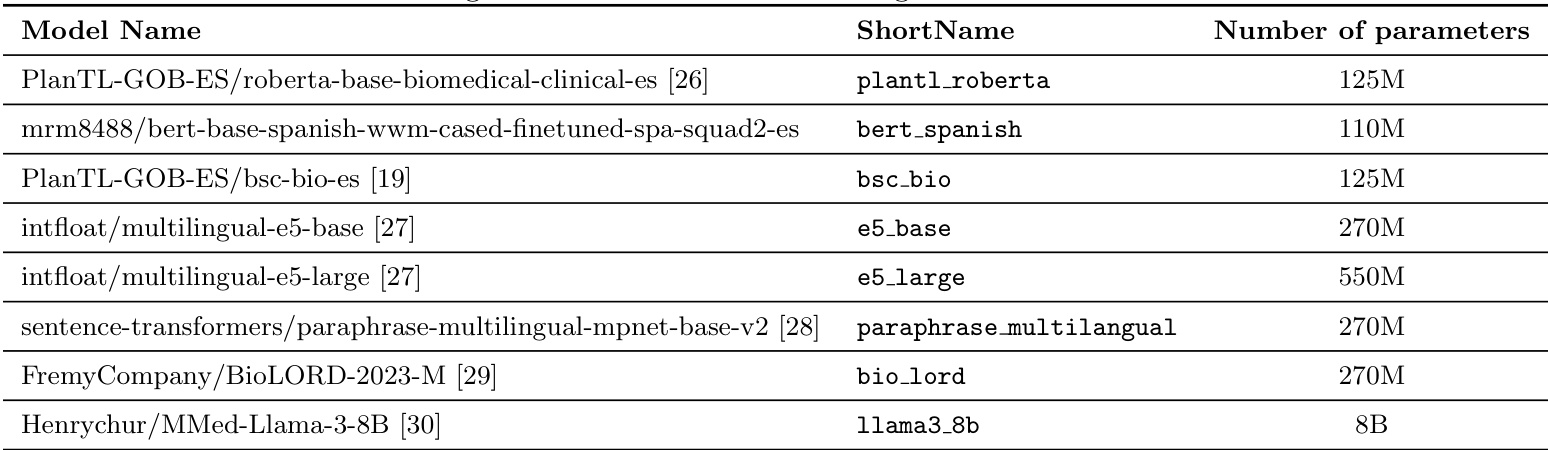
研究对比了精神科诊断编码的各种文本表示模型,重点关注其参数量及对临床语言的适用性。结果显示,参数量显著更大的大型语言模型持续优于较小模型与传统方法,表明模型规模是捕捉医学文本语义复杂性的关键因素。参数量超过2.7亿的大型语言模型持续优于较小模型与传统文本表示技术。参数量最高的模型取得最佳性能,表明规模对于捕捉复杂临床语义至关重要。参数量少于1亿的模型效果较差,突显了模型规模在该领域的重要性。
实验评估了精神科诊断编码的各种文本表示技术与分类算法,证实微调后的大型语言模型通过更精准地捕捉复杂临床语义,显著优于传统方法。分类器的有效性取决于嵌入密度,XGBoost在密集上下文特征上表现优异,而神经网络在稀疏基于关键词的输入上表现更佳。此外,分析表明诊断代码的长尾分布造成了显著的性能差异,突显数据稀缺是罕见病症面临的持续性挑战。最终,研究结果表明,优化诊断编码准确率需要将模型规模与表示类型同合适的分类器相匹配,同时充分考虑固有的类别不平衡问题。