Command Palette
Search for a command to run...
SMoA:用于参数高效微调的频谱调制适配器
SMoA:用于参数高效微调的频谱调制适配器
Yongkang Liu Xing Li Mengjie Zhao Shanru Zhang Zijing Wang Qian Li Shi Feng Feiliang Ren Daling Wang Hinrich Schütze
摘要
随着模型参数数量的增加,参数高效微调(PEFT)已成为定制预训练大型语言模型的首选方案。低秩自适应(LoRA)采用低秩更新方法来模拟全参数微调,被广泛用于降低资源需求。然而,降低秩会面临表征能力受限的挑战。理论表明,秩为 r 的 LoRA 微调收敛于预训练权重矩阵的前 r 个奇异值。随着秩的增加,更多的主奇异方向得以保留,这通常会提升模型性能。然而,较大的秩也会引入更多的可训练参数,从而导致更高的计算成本。为了克服这一困境,我们提出了 SMoA,一种Spectrum Modulation Adapter(谱调制适配器),它在更小的参数预算下扩大了可访问的谱感知更新家族。SMoA 将层划分为多个对齐的谱块,并对每个对角块应用一个块内 Hadamard 调制的低秩分支,从而实现对预训练谱方向更广泛的覆盖。我们提供了理论分析以及在多个任务上的实证结果。实验表明,在当前较低预算设置下,SMoA 的平均性能优于 LoRA 及具有竞争力的 LoRA 风格基线方法。
一句话总结
作者提出了 SMoA(Spectrum Modulation Adapter,谱调制适配器),该方法将网络层划分为多个对齐的谱块,并在每个对角块上应用一个块内 Hadamard 调制的低秩分支,从而在更小的参数预算下实现对预训练谱方向更广泛的覆盖,进而提升多任务平均性能,使其优于 LoRA 并在低预算设置下达到具有竞争力的 LoRA 风格基线水平。
核心贡献
- SMoA 通过在缩减的参数预算下扩展可访问的谱感知更新家族,解决了参数高效微调中表征能力与计算成本之间的权衡问题。
- 该方法将神经网络层划分为多个对齐的谱块,并在每个对角块上应用块内 Hadamard 调制的低秩分支。此设计实现了结构化的秩累积,并扩大了预训练谱方向的覆盖范围。
- 理论分析与跨多任务的实证评估表明,SMoA 在低预算设置下的平均性能优于标准 LoRA 及具有竞争力的 LoRA 风格基线。
引言
微调大语言模型对于适配专业应用至关重要,但全参数更新在计算上代价高昂。参数高效微调通过将训练限制在少量参数子集上解决了这一问题,从而实现可扩展且成本效益高的模型定制。低秩自适应(LoRA)因其极低的内存开销和零推理延迟已成为标准方法。然而,标准方法将权重更新限制为单个全局低秩矩阵,使自适应过程局限于狭窄的谱方向集合。由于预训练 Transformer 权重在其谱尾部包含功能相关的信息,这种秩约束会导致有价值的信号未被建模,并限制复杂推理任务的性能。作者通过引入谱调制适配器(Spectrum Modulation Adapter)利用谱感知设计突破这一瓶颈。SMoA 将输入和输出维度划分为对齐的谱块,并在每个对角块上应用 Hadamard 调制的低秩更新,将参数预算分配到多个局部子空间。该结构产生的秩上限严格高于标准低秩自适应,并在严格参数约束下于多样化基准测试中展现出优越性能。
数据集
数据集构成与来源 作者构建了一个涵盖常识推理、对话生成和数学推理的多任务评估套件。所有子集均源自成熟的学术基准和公开语料库。
子集详情
- BoolQ:维基百科段落与自然生成的是非问题配对,用于衡量语义理解能力。
- PIQA:通过目标导向型问题,聚焦物理交互与日常物体知识。
- SIQA:评估日常场景中的社交互动理解与人类意图预测。
- ARC-c 与 ARC-e:分别需要非平凡推理和较简单事实知识的中小学科学问题。
- OBQA:结合开放书籍事实与常识推理的选择题科学问题。
- HellaSwag:测试在日常语境中预测合理后续事件的能力。
- WinoGrande:依赖上下文与常识线索的大规模代词消解任务。
- ConvAI2:基于人设的开放域对话数据集,用于生成连贯且引人入胜的回复。
- GSM8K:数学推理评估的标准基准。
- MetaMath:专门用于数学任务训练的数据源。 注:具体数据集规模与精确统计信息详见原论文表 8,摘要中未提供。
训练与评估策略 作者利用这些数据集对模型在三大目标领域的性能进行基准测试。针对数学推理任务,遵循标准协议:在 MetaMath 上进行训练,在 GSM8K 上进行评估。其余基准测试集直接用于评估,未指定混合比例或自定义划分。
处理与准备 提供的摘要未说明自定义裁剪策略、元数据构建或高级过滤规则。作者依赖各基准测试集固有的标准格式与预处理规范。详细的准备步骤与数据集统计信息请参见原表 8。
方法
作者提出了 SMoA,这是一种参数高效微调方法,旨在受限参数预算下提升低秩自适应技术的表征能力。其核心动机源于以下观察:预训练 Transformer 权重矩阵呈现出长尾奇异值谱,表明信息丰富的方向延伸至谱尾部,而非仅局限于少数主导奇异值。这表明,将更新限制在低秩子空间(如标准 LoRA)可能导致任务相关信息建模不足。
SMoA 架构通过将冻结的权重矩阵划分为多个对齐的谱块,并对每个块应用局部 Hadamard 调制的低秩更新来运行。该框架主要包含三个步骤,如下图所示。首先,根据谱结构对冻结权重矩阵 W0 的坐标进行一次重排。具体做法是计算奇异值分解 W0=UΣV⊤,并利用得到的奇异向量定义排列矩阵 Pout 和 Pin,分别重排输出和输入维度。此重排操作将具有相似谱角色的坐标组合成连续区间,从而得到重排后的矩阵 W0=PoutW0Pin⊤。

第二步是从重排矩阵中识别出 K 个对齐的对角块,称为块锚点 Mk。这些锚点在微调期间保持固定且不更新。第三步将总秩预算 r 分配到这 K 个块上,为每个块定义局部秩 ρ=r/K。为每个锚点 Mk 附加可学习的低秩分解 Ak∈Rρ×din/K 和 Bk∈Rdout/K×ρ,局部更新构建为 ΔMk=(BkAk)⊙Mk,其中 ⊙ 表示 Hadamard 乘积。这些局部更新被组装成块对角矩阵 ΔW,随后通过逆排列散射回原始坐标系,得到最终更新 ΔW=Pout⊤ΔWPin。因此,可训练参数为所有 K 个块的 Ak 和 Bk 因子。
重排坐标系下的块对角结构是 SMoA 理论优势的基础。与标准秩-r LoRA 层相比,SMoA 仅使用 1/K 的可训练参数,却实现了严格更大的解析秩上限。这是因为每个块 k 上更新的秩受限于 min(sk,ρ⋅rank(Mk)),其中 sk 为块大小,而完整更新的总秩为这些块秩之和。该和 U 经证明大于标准 LoRA 可达到的最大秩 r。这种结构分离意味着 SMoA 能够表示某些超出标准 LoRA 表达能力的块对齐目标更新,对此类目标可实现零近似误差,而 LoRA 则会产生非零的谱尾部残差误差。
实验
评估涵盖 Llama-2 与 Llama-3 模型在常识推理、对话生成及数学推理任务上的表现,并将 SMoA 与成熟的参数高效微调方法进行基准对比。性能测试表明,SMoA 在保持极高参数效率的同时,始终取得优越或具竞争力的结果,显示出其对多样化任务复杂性的鲁棒性。谱分析与消融实验揭示,该方法的成功源于选择性地放大未充分利用的尾部奇异方向,而非均匀更新主导的预训练权重;秩与块配置研究进一步证实,战略性谱重分配能够提升模型表达能力。综上所述,这些发现验证了 SMoA 作为一种结构化自适应方法,能有效平衡计算效率与强大的泛化能力。
作者在包括常识推理、对话生成和数学推理在内的多个任务族上开展实验,将 SMoA 与多种 PEFT 方法进行比较。结果表明,SMoA 在不同任务和模型规模下均取得具竞争力或更优的性能,尤其在受益于结构化适配的任务中表现突出,并在准确率与参数效率之间保持良好平衡。该方法在对话生成和数学推理方面展现出一致的性能提升,性能增益归因于其对未充分利用谱方向的适配能力。SMoA 在保持参数效率的同时,于多样化任务和模型规模下取得竞争性表现。与基线方法相比,SMoA 在对话生成和数学推理方面表现出一贯的改进。SMoA 的有效性归因于其适配未充分利用谱方向的能力,从而以更少的可训练参数实现更佳性能。
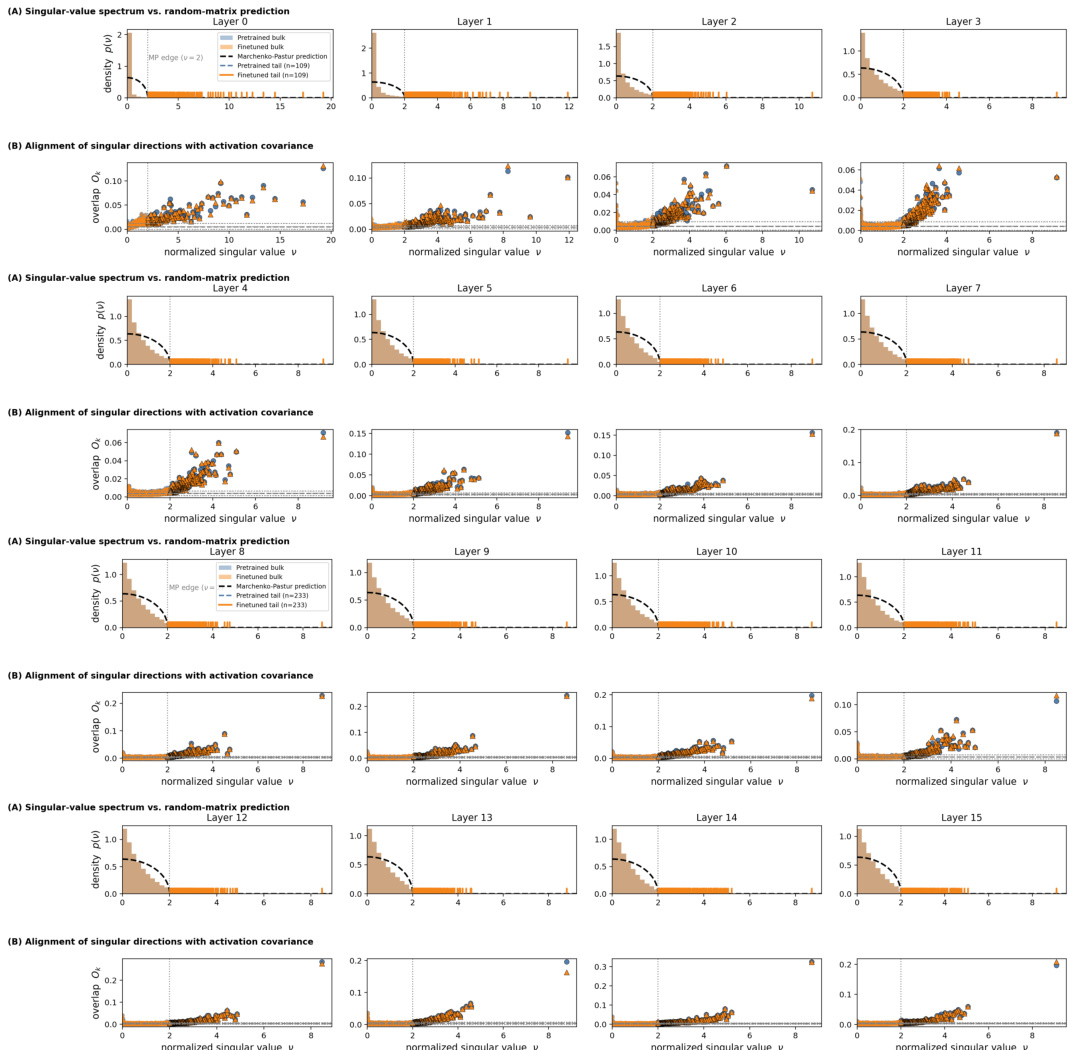
作者分析了使用 SMoA 微调后预训练语言模型的谱变化,重点关注奇异值谱及其与激活协方差的对齐方式如何随不同层演变。结果表明,谱整体向更高奇异值方向移动,且奇异方向与任务诱导的激活结构对齐程度增加,尤其在尾部区域。这表明 SMoA 选择性地适配未充分利用的方向,而非扰动主导方向。该结构化适配机制在多个层中均被观察到,印证了 SMoA 在实现参数高效微调方面的有效性。SMoA 微调使奇异值谱产生右尾偏移,表明其对未充分利用方向进行选择性适配,而非对预训练模型进行均匀扰动。微调后,奇异方向与激活协方差特征向量之间的对齐程度在中间和尾部区域增加,说明 SMoA 适配了与任务功能相关的方向。谱与对齐模式在各层中保持一致,较深层显示出更明显的微调信号局部化特征,进一步支持了结构化且逐层适配的机制。
作者跨多个任务(包括常识推理、对话生成和数学推理)将 SMoA 与多种 PEFT 方法进行评估对比。结果表明,SMoA 在大多数基准测试上取得最高平均性能,尤其在对话生成和常识推理方面,同时保持准确率与参数效率的良好平衡。分析强调,SMoA 的有效性源于其适配未充分利用的尾部谱方向的能力,这些方向分布于注意力投影中,对特定任务性能贡献显著。与其他 PEFT 方法相比,SMoA 在大多数任务上取得最高平均性能,尤其在对话生成和常识推理方面。SMoA 的性能归因于其适配尾部谱方向的能力,这些方向分布于注意力投影中,对特定任务性能贡献显著。SMoA 在准确率与参数效率之间保持良好平衡,优于具有相似或更高参数预算的方法。
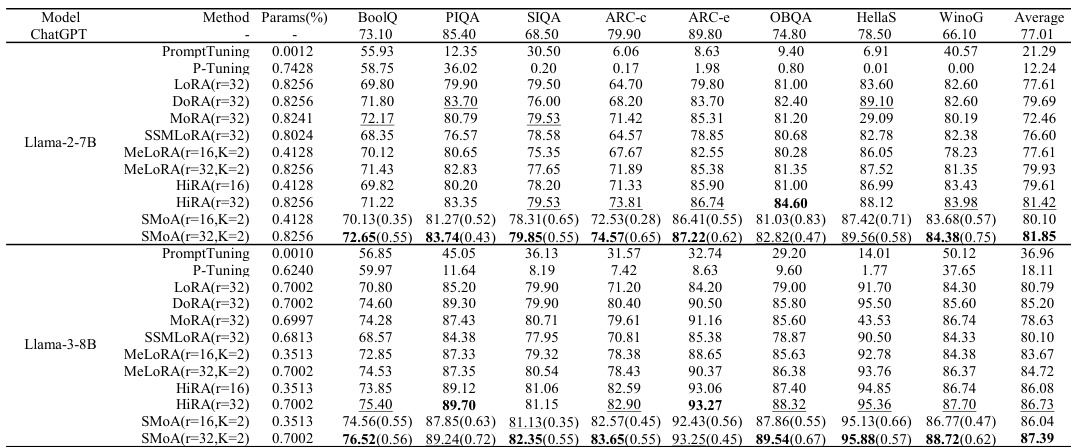
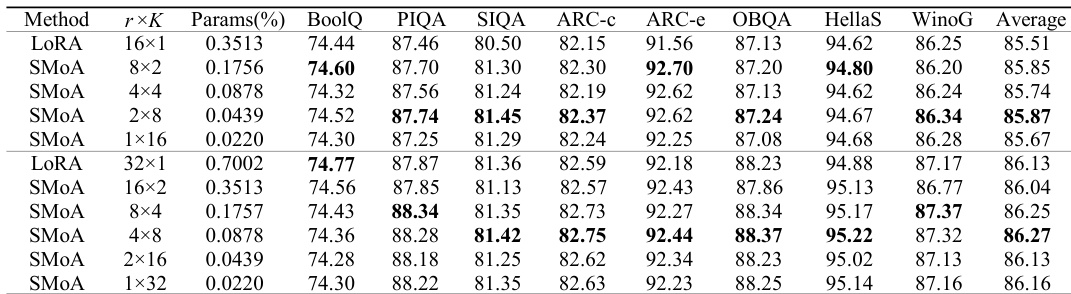
作者跨多个任务(包括常识推理、对话生成和数学推理)将 SMoA 与多种 PEFT 方法进行比较。结果表明,SMoA 在大多数基准测试上取得最高平均性能(尤其在特定配置下),并展现出相对于基线的一致改进。该方法在参数高效设置下依然有效,并维持性能与参数效率的良好平衡。SMoA 的成功归因于其适配信息丰富的尾部谱方向的能力,这些方向在微调期间被选择性激活。与其他 PEFT 方法相比,SMoA 在大多数基准测试上取得最高平均性能。SMoA 在不同任务和模型规模下均展现出相对于基线的一致改进。该方法在较小参数预算下依然有效,维持良好的准确率-效率权衡。
作者在 CONVAI2 数据集上将 SMoA 与多种 PEFT 方法进行比较,并使用多项自动指标评估性能。结果表明,SMoA 取得最高平均分,在大多数指标上超越基线,印证了其在对话生成任务中的有效性。该提升在不同参数预算和模型规模下均保持一致。SMoA 在 CONVAI2 数据集上取得最高平均分,优于所有对比的 PEFT 方法。SMoA 在 BLEU、METEOR 和 ROUGE-L 等多项自动评估指标上一贯优于基线。SMoA 的性能优势在不同参数预算和不同模型规模下均被观察到。
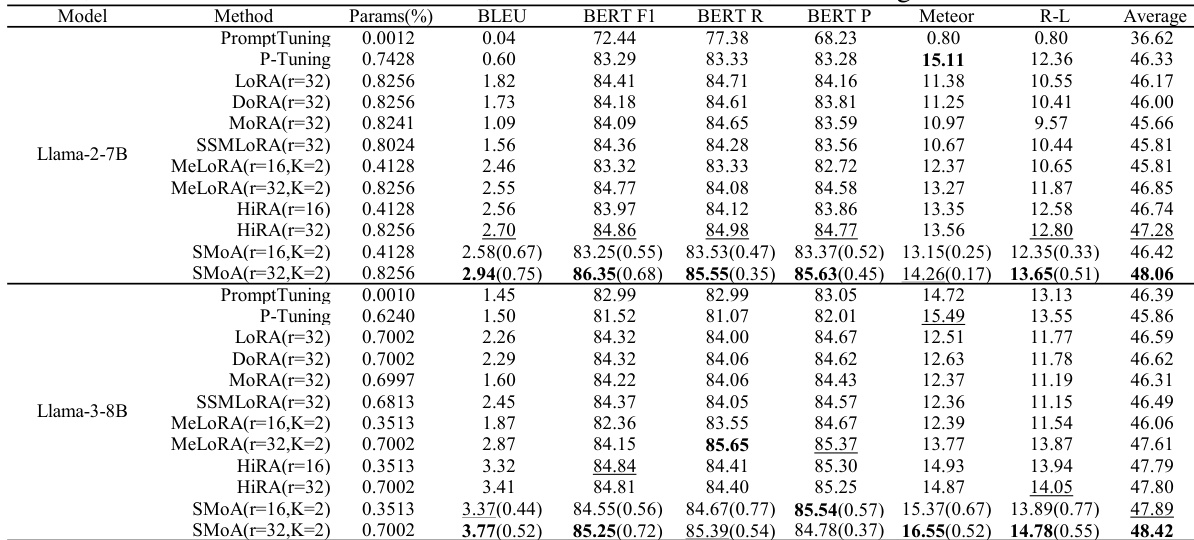
该评估跨多样化任务族(包括常识推理、对话生成和数学推理)将 SMoA 与多种参数高效微调基线进行对比,同时变化模型规模与参数预算。专门的谱分析进一步验证了该方法如何通过追踪网络层中的奇异值偏移与激活对齐来修改预训练表示。综合来看,这些实验表明 SMoA 始终以良好的准确率-效率权衡,持续交付优越或高度竞争的性能。定性而言,该方法通过结构化适配机制实现这些增益,选择性调整未充分利用的尾部谱方向,在保留核心预训练知识的同时有效捕获任务特定信号。