Command Palette
Search for a command to run...
OpenComputer:面向 Computer-Use Agent 的可验证软件世界
OpenComputer:面向 Computer-Use Agent 的可验证软件世界
Jinbiao Wei Qianran Ma Yilun Zhao Xiao Zhou Kangqi Ni Guo Gan Arman Cohan
摘要
标题:无摘要:我们提出了 OpenComputer,这是一个基于验证器(verifier-grounded)的框架,用于为计算机使用智能体(computer-use agents)构建可验证的软件世界。OpenComputer 整合了四个组件:(1)应用特定的状态验证器,通过真实应用程序暴露结构化的检查端点;(2)自演化验证层,利用基于执行反馈的机制提升验证器的可靠性;(3)任务生成流水线,合成逼真的且可由机器检查的桌面任务;(4)评估工具包,记录完整的轨迹并计算可审计的部分得分奖励。目前,OpenComputer 涵盖了 33 款桌面应用程序和 1,000 个已确定的任务,涉及浏览器、办公工具、创意软件、开发环境、文件管理器和通信应用程序。实验表明,OpenComputer 的硬编码验证器比“大语言模型即裁判”(LLM-as-judge)评估更贴近人类裁决,尤其是在成功取决于细粒度应用状态的情况下。尽管取得了部分进展,前沿 agents 在端到端完成方面仍面临困难,而开源模型在 OSWorld-Verified 分数上出现显著下降,这暴露了稳健计算机自动化领域存在的持续差距。
一句话总结
OpenComputer 是一个基于验证器的框架,通过整合特定应用的状态验证器、自演化验证层、任务生成流水线以及跨 33 款桌面应用的评估工具包,为 agent 构建可验证的软件世界。该框架证明,其硬编码验证器比 LLM-as-judge 方法更贴近人工裁决,同时揭示了前沿模型和开源模型在端到端任务完成上存在持续失败,以及 OSWorld-Verified 分数下降的问题。
核心贡献
- OpenComputer 是一个基于验证器的框架,能够自动合成可执行的桌面任务、环境和机器可检查的成功标准,无需人工构建。通过强制将可检查的应用状态作为核心设计约束,该系统为 agent 生成真实的软件工作流。
- 硬编码验证器比 LLM-as-judge 评估更贴近人工裁决,尤其在成功标准依赖于细粒度应用状态时。自演化验证层进一步通过利用基于执行过程的反馈,自动识别并修复验证器失败问题,从而提升可靠性。
- 该框架建立了一个涵盖 33 款桌面应用和 1,000 个最终任务的大规模基准,用于评估前沿和开源 agent。实证结果表明,当前模型在可靠的端到端任务完成方面面临挑战,暴露出尽管频繁取得部分进展,但在稳健桌面自动化方面仍存在持续差距。
引言
agent 代表了向通用 AI 系统迈出的关键一步,这类系统能够与日常桌面软件进行交互,但其训练和评估的扩展性受到构建真实环境所需人工成本的阻碍。现有方法依赖繁琐的特定应用任务构建,并高度依赖 LLM-as-a-judge 评估,这引入了提示词敏感性、可审计性问题,以及倾向于忽视底层应用状态中关键错误的倾向。为解决这些瓶颈,该研究利用了一个名为 OpenComputer 的基于验证器的框架,该框架自动化了可执行桌面任务及其机器可检查成功标准的创建。该系统采用自演化验证流水线,持续优化程序化状态检查器,从而在 33 款应用中实现可复现的基准测试,并证明基于状态的检查比传统的基于截图或 LLM 的评估更贴近人类判断。
数据集
-
数据集构成与来源: OpenComputer 作为可扩展的基准基础设施发布,包含 33 款桌面应用和 1,000 个最终任务。每个环境均通过合成方式生成,并捆绑特定应用的验证器模块、详细任务规范、环境初始化脚本以及标准化执行工具包。
-
子集详情与过滤: 主基准测试恰好包含分布在 33 款应用中的 1,000 个任务。在合成阶段,发现 17 个任务依赖基于 LLM 的视觉判断而非硬编码的程序检查。这些案例在官方基准中被明确过滤,以维持可审计性和可复现性,但被保留在单独的诊断子集中,供未来的混合验证研究使用。
-
训练与评估用途: 数据集未强制规定固定的训练划分或混合比例,而是设计为用于评估和模型训练的灵活流水线。研究人员可收集 agent 轨迹,筛选成功或部分成功的运行记录,并组装监督微调数据集。机器可验证的奖励也设计用于支持强化学习和拒绝采样工作流。
-
处理与验证策略: 每个最终任务均与可执行的验证标准配对,这些标准检查应用状态、文件元数据和持久化副作用,而非依赖视觉代理或 LLM 判断。环境预先植入特定的初始文件和路径,任务在基于 Docker 的沙箱或云端部署中执行。通过严格强制执行程序化检查器并排除基于视觉的标准,确保成功指标在不同 agent 实现中保持完全可复现。
方法
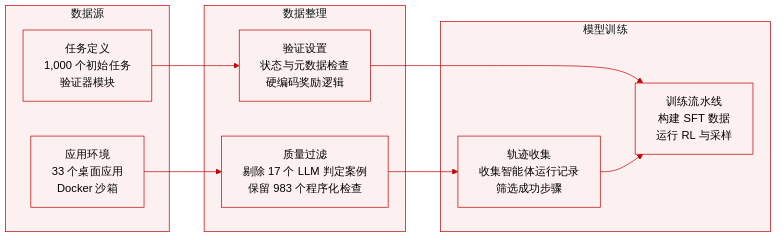
OpenComputer 框架围绕一个四阶段流水线构建,旨在合成可在真实桌面环境中运行的可验证 agent 任务,同时确保环境真实性和可靠的成功验证。整体架构整合了特定应用验证器、自演化验证层、任务生成流水线以及计算可审计奖励的评估工具包。每个阶段紧密耦合,以确保任务可执行、可检查且基于软件的实际状态。
第一阶段:验证器生成。该阶段为每个支持的应用构建特定应用的验证器。这些验证器实现为 Python 模块,提供带有 JSON 输出的 CLI 子命令,从而在应用状态上提供结构化的检查和检查端点。系统识别每种应用可用的最可靠检查通道,例如浏览器调试协议 (CDP)、D-Bus、LibreOffice UNO、基于 SQLite 的配置文件数据库或辅助功能 API。验证器开发遵循固定流水线:首先枚举并映射可检查的状态表面到具体的验证通道;然后实现并记录查询和检查端点(在特定应用的 README 中)。每个验证器需经过严格的测试协议,包括单元测试和集成测试,重点关注真实测试用例、JSON 有效性和失败模式处理。失败的端点将经过调试和重测,直至达到可靠性要求。 
第二阶段:自演化验证。该阶段利用基于执行过程的反馈优化初始验证器。对于每种应用,生成约 15 个简单到中等难度的校准任务集,并在持久化桌面沙箱中执行。生成的轨迹将被冻结,并作为固定参考执行记录用于整个优化过程。LLM 评估器检查完整轨迹和最终状态以生成参考判定,而程序化验证器独立检查同一状态。比较器逐标准对齐两种判定,识别分歧。归因于验证器端错误(如脆弱的模式假设或不完整的端点覆盖)的分歧将作为优化反馈。验证器演化步骤限定在验证栈内:仅允许修改检查器代码、端点实现或文档,不得修改轨迹或任务目标。修订后的验证器将在相同的缓存状态上重新执行,该过程迭代进行,直至达成一致或耗尽固定预算。此循环使系统能够检测并修复仅靠合成测试无法暴露的验证器问题。 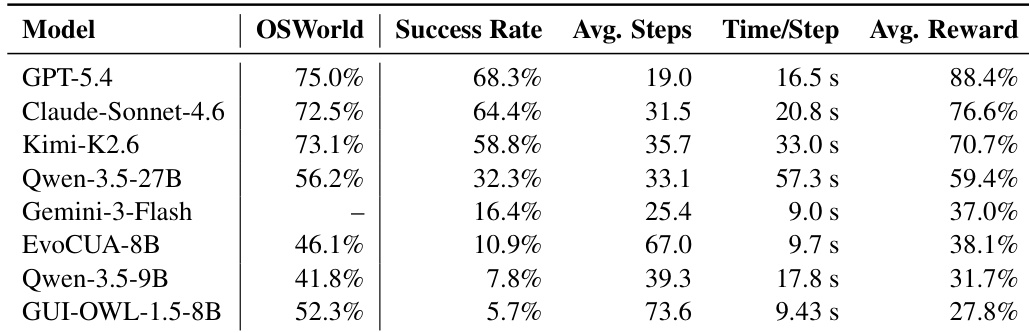
第三阶段:任务生成流水线。该流水线首先从用户视角提出候选目标,避免直接依赖可用端点进行条件设定,以维持基准测试的多样性。这些提案经过复杂度和数据生成可行性的过滤,优先处理多步工作流,并拒绝琐碎或过于线性的任务。接受的提案随后在验证栈中落地:如果结果已通过现有端点可检查,则保留该任务;否则,使用相同的生成过程通过新端点扩展验证器。系统随后通过生成所需的输入工件(文件、文件夹、配置或配置文件)将每个任务具体化,并将其打包为最终任务实例 τ=(x,e,c),其中 x 是面向用户的指令,e 是环境初始化程序,c 指定机器可检查的成功标准。任务扩展工作流会定期审查应用任务集,以识别差距并优先处理新的候选任务。 
第四阶段:评估工具包。该工具包在从任务环境设置初始化的沙箱环境中执行 agent。agent 通过截图和 GUI 操作与系统交互,完整轨迹将被记录。运行结束时,验证器使用结构化端点检查最终应用状态,生成机器判定。系统根据 agent 输出与成功标准的一致性计算奖励。此过程确保奖励基于实际软件状态,而非启发式或视觉解释。评估工具包还支持在验证器调试期间使用 LLM-as-judge 作为参考信号,但最终评分完全依赖硬编码验证器,以确保可复现性、可审计性以及对细粒度成功条件的敏感性。 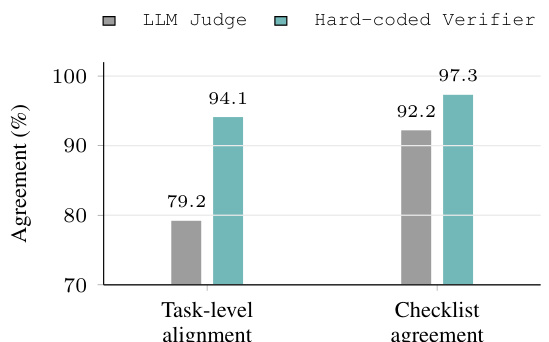
实验
评估设置将 agent 隔离在新鲜沙箱中,通过截图-操作循环与实时桌面应用交互,采用硬编码检查器衡量整个任务套件中的精确完成度和部分进展。实验验证了尽管当前前沿模型取得了显著的部分成功,但可靠的端到端任务完成仍然具有挑战性,表现最佳的模型通过操作整合和简化的推理脱颖而出。对比分析表明,程序化验证在贴近人类判断方面显著优于基于 LLM 的评判,特别是在视觉线索可能产生误导的密集或终端密集型环境中。最后,研究证实图形界面通过更优的视觉定位实现了更高的任务完成率,而命令行方法提供了显著的执行效率,自演化验证层通过自动纠正检查器错误有效提升了评估器的可靠性。
研究分析了自演化验证过程的有效性,该过程通过识别和修复验证逻辑中的错误来提升任务检查器的可靠性。该过程更新检查器查询以更好地匹配预期标准,例如更改标签存在性的数据库源并改进图像-标签分配的连接条件。这提高了人工评估与自动检查器之间的一致性,表明验证准确性得到提升。自演化验证过程通过更新验证任务所使用的逻辑来修复检查器端错误。检查器查询被修改为使用更准确的数据源和连接条件,从而提高验证精度。该过程增加了人工评估与自动评估之间的一致性,表明验证可靠性得到提升。
研究在基准测试上评估了多种 agent,该基准测试检验其在不同桌面应用中完成任务的能力,并使用基于验证器的奖励系统来衡量完全成功和部分进展。结果表明,最强的模型实现了较高的平均奖励,但仍未能完成相当比例的任务,各模型间的性能差异显著,交互步骤和单步耗时方面存在效率差异。GPT-5.4 在评估模型中取得了最高的成功率和平均奖励,但仍未能完成近三分之一的任务。各模型性能差异显著,开源模型的成功率远低于前沿模型。最强大的模型在交互步骤方面也是最有效的,以比其他模型更少的步骤完成任务。
研究通过衡量自演化验证程序在基准测试中识别和修复检查器端错误的能力,评估了其有效性。结果表明,该程序在有限次迭代内成功修复了大多数错误,显著提高了验证器与人类判断之间的一致性。该过程在最小计算开销下展现出解决高问题的高效性。自演化验证程序在单次迭代内修复了大多数检查器端错误。该方法显著提高了自动验证与人类判断之间的一致性。大多数错误得以快速解决,仅有一小部分需要完整的修复预算。
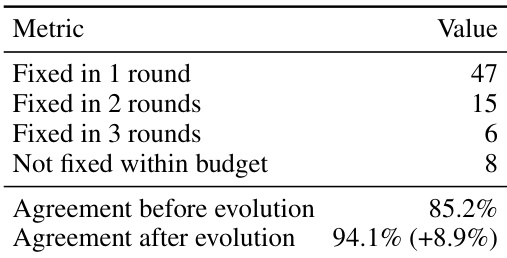
研究通过测量自演化验证过程修复任务验证中检查器端错误的频率,评估了其有效性。该过程应用于校准任务集,结果显示程序化检查器与参考评估之间的大部分差异在一到两次迭代后得到解决。演化后,验证器与人类判断的一致性更高,表明可靠性得到提升。自演化验证过程在几次迭代内修复了大多数检查器端错误。程序化验证器在演化后与人类判断实现更高的一致性。程序化检查器与参考评估之间的大部分差异通过自演化得到解决。

研究在 OpenComputer 基准测试的共享任务子集上比较了 GUI 和 CLI agent 的性能。结果显示,GUI agent 的成功率高于 CLI agent,表明视觉交互为桌面工作流提供了有用的定位参考。然而,CLI agent 在执行时间方面显著更快,反映了命令行执行相对于截图-操作循环的效率优势。GUI agent 在共享任务子集上取得了比 CLI agent 更高的成功率。CLI agent 完成任务的速度远快于 GUI agent,展示了命令行执行的效率优势。尽管成功率较低,CLI agent 的表现表明,即使缺乏视觉定位,通过程序化接口仍可实现任务完成。

实验在桌面任务基准测试上评估 agent,以检验其任务完成能力和效率,同时引入自演化验证过程以验证和修复程序化检查器错误。验证程序在一到两次迭代内成功解决了大部分验证差异,在最小计算开销下显著提高了自动评分与人类判断之间的一致性。agent 评估表明,尽管表现最佳的模型实现了高成功率和效率,但仍难以完成相当比例的任务,前沿模型始终优于开源替代方案。最后,交互模态的比较表明,基于 GUI 的 agent 通过视觉定位实现了更高的完成率,而基于 CLI 的 agent 执行任务的速度显著更快。