Command Palette
Search for a command to run...
TACK:针对新型靶向嵌合体知识数据集(TArgeting Chimeras Knowledge)的降解活性统计评估
TACK:针对新型靶向嵌合体知识数据集(TArgeting Chimeras Knowledge)的降解活性统计评估
Stefano Ribes Nils Dunlop Rocío Mercado
摘要
蛋白水解嵌合体(PROTACs)代表了一种极具前景的治疗手段,其通过劫持泛素-蛋白酶体系统来实现靶向蛋白质降解。然而,由于分子结构、靶蛋白、E3连接酶以及细胞微环境之间复杂的相互作用,理性设计 PROTAC 仍面临巨大挑战。在此,我们提出了 TACK,这是一种基于新型 TArgeting Chimeras Knowledge 数据集的统计评估方法。该数据集包含来自三大主要存储库的 3,514 个 PROTAC 及其 6,561 个降解终点数据,并采用了标准化的分子表示、蛋白质注释及实验条件。通过基于骨架的 5×5 交叉验证,我们对三种机器学习方法进行了严格的统计比较,以预测 PROTAC 的降解活性,涵盖三项任务:DC50 和 Dmax 回归,以及二元活性分类。特征消融实验表明,细胞微环境特征和简单的蛋白质表示能够与复杂的 ESM 蛋白质嵌入相媲美,这突显了特征工程的重要性超越架构的复杂性。使用表现最佳的特征训练模型显示,效力(pDC50,R² = 0.66)的可预测性显著高于最大降解程度(Dmax,R² = 0.36)。
一句话总结
TACK 是对新型 TArgeting Chimeras Knowledge 数据集上的降解活性进行的统计评估,该数据集聚合了来自三个主要存储库的 3,514 个 PROTACs 和 6,561 个降解终点,利用基于骨架的 5×5 交叉验证来比较三种机器学习方法在 DC50、Dmax 和二元分类任务上的表现,其中特征消融表明细胞环境特征可与复杂的 ESM 蛋白嵌入相媲美,强调了特征工程相对于架构复杂性的重要性。
核心贡献
- 本文介绍了 TACK,这是一个新颖的数据集,包含来自三个主要存储库的 3,514 个 PROTACs 和 6,561 个降解终点,具有标准化的分子表示。配套的开源集成模型作为一个快速预测器,支持分类和回归任务。
- 使用基于骨架的 5×5 交叉验证对三种机器学习方法进行了严格的统计比较,以预测回归和分类任务中的降解活性。实验结果表明,效力比最大降解更具可预测性,pDC50 的 R2 为 0.66,而 Dmax 为 0.36。
- 特征消融表明,细胞环境特征和简单的蛋白表示在预测性能上可与复杂的 ESM 蛋白嵌入相媲美。这一发现强调了在预测 PROTAC 降解活性时,特征工程比架构复杂性更重要。
引言
蛋白水解靶向嵌合体 (PROTACs) 通过降解疾病相关蛋白质为药物发现提供了一种变革性方法,但由于复杂的分子相互作用和碎片化的数据,合理设计仍然困难。先前的机器学习工作受到存储库中活动指标不一致以及评估协议经常高估新颖化学结构性能的限制。作者介绍了 TACK,这是一个包含 3,514 个 PROTACs 的标准化数据集,具有协调的注释,以便进行严格的基准测试。他们的分析表明,当在细胞环境特征上训练时,经典机器学习方法显著优于专门的图神经网络,而集成方法为实验优先级提供了不确定性估计。
数据集
-
数据集组成和来源
- 作者聚合了来自三个开放存储库的数据:PROTAC-DB 3.0、PROTACpedia 和 TPDdb。
- 初始原始数据超过 29,000 条,但严格的筛选将其减少到 3,514 个独特的 PROTACs。
- 最终集合包含 6,561 个实验终点,分为效力 (DC50) 和疗效 (Dmax) 测量。
-
筛选和标准化规则
- 分子使用 RDKit 进行 SMILES 规范化,而蛋白质名称映射到 UniProt 标识符。
- 浓度值转换为纳摩尔单位,不等式运算符单独存储以便在评估期间筛选。
- 类别活动等级和包含多个目标的行被排除,以确保数据一致性。
- 细胞系针对 Cellosaurus 数据库进行验证,测定描述标准化为通用格式。
-
数据划分和模型使用
- 保留测试集代表约 10% 的数据,通过结构不相似度分数选择。
- 剩余数据使用基于骨架的聚类与 Murko 骨架进行交叉验证,以防止化学结构泄露。
- 回归任务应用仅在训练集上拟合的分位数变换。
- 二元分类将化合物标记为活性,如果 Dmax 超过 80% 且 DC50 保持在 100 nM 以下。
-
特征工程和元数据处理
- 蛋白质特征源自氨基酸序列,而 PROTAC 特征使用分子指纹。
- 实验条件通过文本嵌入对细胞系进行编码,并使用 OneHot 编码对测定类型进行编码。
- 缺失的治疗时间用训练集均值填补,缺失的细胞系嵌入为未知字符串。
- 精选数据集和筛选管道可通过 HuggingFace 和 GitHub 公开获取。
方法
所提出的框架整合了数据筛选、特征提取、模型训练和严格评估,以预测 PROTAC 降解活性。请参阅下图以获取流程的视觉概述。
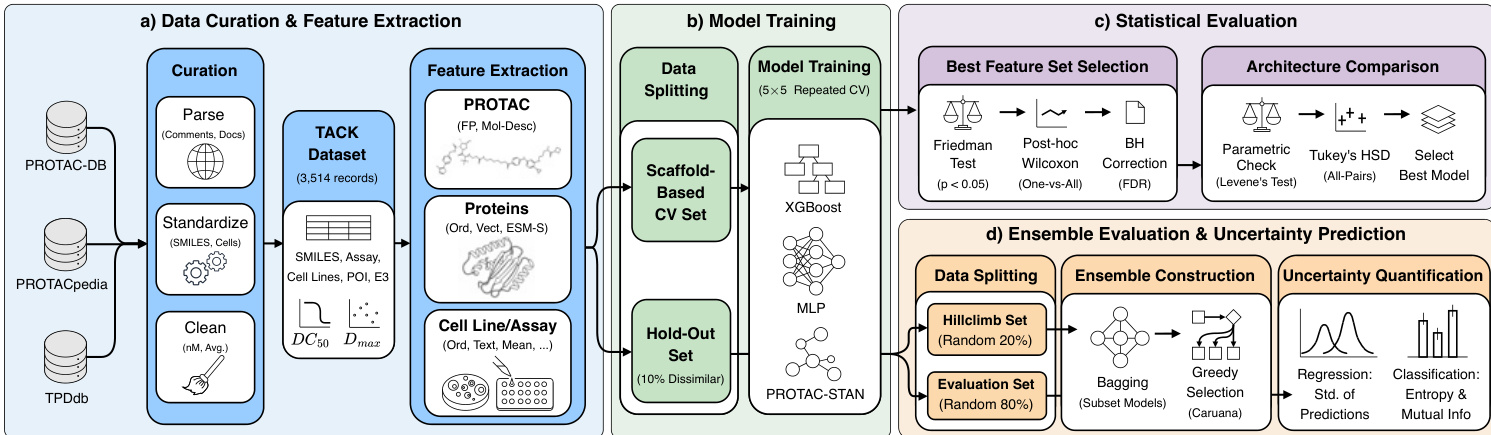
该过程从多个来源(包括 PROTAC-DB 和 PROTACpedia)的数据筛选开始,以构建 TACK 数据集。特征提取在三种模态上进行:PROTAC 分子使用指纹和分子描述符表示,蛋白质通过 ESM-S 嵌入编码,细胞系或测定数据处理为序数、文本或均值。
对于模型训练,数据被划分为基于骨架的交叉验证集和包含 10% 不相似化合物的保留集。作者利用三种不同的架构:XGBoost、自定义多层感知机 (MLP) 和 PROTAC-STAN。MLP 架构设计具有灵活的深度和宽度,利用隐藏层,维度采样自诸如 [256] 或 [512,256] 的配置。每个隐藏层结合可选的归一化和 dropout 正则化,后跟具有可配置深度的回归头。权重使用 Kaiming 初始化进行初始化,以考虑 ReLU 非线性,训练利用梯度裁剪和混合精度训练。PROTAC-STAN 是一个图神经网络,使用两层边缘感知图卷积网络对 PROTAC 分子进行编码,并通过全连接适配器对蛋白质序列进行编码。专门的三元注意力网络 (TAN) 层通过张量外积模拟感兴趣蛋白质、PROTAC 和 E3 连接酶之间的复杂三方相互作用。
为了确保稳健的预测,作者实施了集成策略和不确定性量化模块。集成使用 Caruana 的贪婪前向选择算法构建,该算法通过在专用选择子集上最大化性能来迭代构建模型集。应用 Bagging 以减少对选择集变异的敏感性。不确定性估计源自集成内模型间的不一致。对于回归任务,计算成员预测之间的标准差 σ。对于分类,计算预测熵并分解以隔离互信息作为认知不确定性的度量。校准通过测量不确定性与回归绝对预测误差之间的 Spearman 相关性进行评估,并通过报告期望和最大校准误差进行分类。最后,统计评估涉及 Friedman 检验和 Tukey 的 HSD,以选择最佳特征集并比较模型架构。
实验
该研究利用 TACK 数据集上的严格重复 5x5 交叉验证方案来验证特征组合,并比较 XGBoost、MLP 和 PROTAC-STAN 架构以进行 PROTAC 活性预测。统计测试表明,基于树的模型始终优于深度学习方法,简单的特征编码通常与复杂嵌入的性能相匹配,同时提供更高的计算效率。此外,结果表明,虽然效力预测很好地泛化到保留集,但由于当前分子表示未捕捉到的生物因素,最大降解疗效仍然难以准确量化,尽管集成方法未提高预测精度,但提供了校准的不确定性估计。
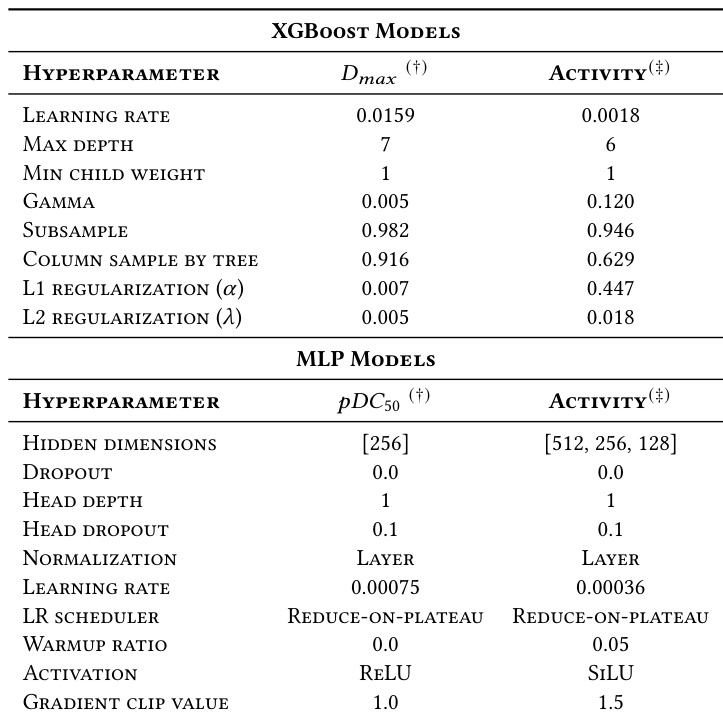
作者针对特定预测任务(包括 Dmax、pDC50 和二元 Activity)介绍了最佳性能的 XGBoost 和 MLP 模型的优化超参数。配置揭示了不同的架构选择,例如 XGBoost 中回归任务的更深树结构和 MLP 中不同的隐藏层深度以适应不同的目标变量。用于 Dmax 预测的 XGBoost 模型使用比二元 Activity 分类模型更高的学习率和更大的最大深度。用于 pDC50 回归的 MLP 模型采用具有 ReLU 激活的单隐藏层,而 Activity 模型使用具有 SiLU 激活的更深多层架构。MLP 训练对两个任务都利用非常低的学习率,与 pDC50 配置相比,Activity 模型结合了预热比和更高的梯度裁剪值。
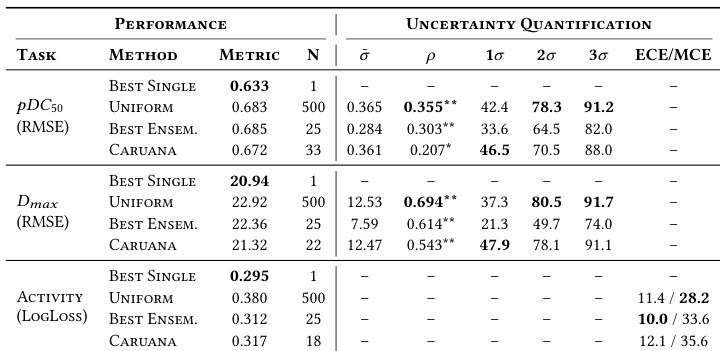
作者在保留测试集上将集成策略与单个最佳模型进行比较,发现单个模型在回归和分类任务中始终实现最低的预测误差。虽然集成通常在准确性上表现不如单个最佳模型,但它们提供了与预测误差相关的不确定性估计,其中均匀平均方法在回归任务中显示出最强的相关性。该研究强调了集成提供更好不确定性量化但相比最优单一配置预测性能略有降低的权衡。单个最佳模型在所有任务中始终实现最低误差指标,优于均匀和加权集成方法。均匀平均在回归任务中产生了估计不确定性与实际预测误差之间的最强相关性。集成方法对二元分类表现出适度校准,最佳集成显示出最低校准误差。
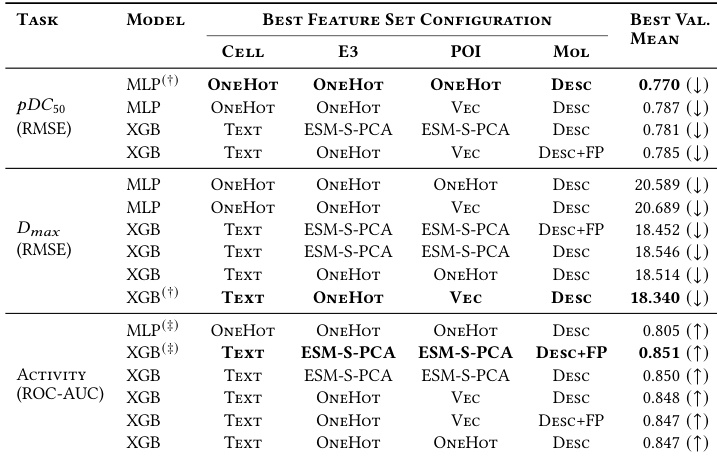
作者比较了 XGBoost 和 MLP 模型在三个预测任务上的表现,发现 XGBoost 通常在最大降解和活性分类方面实现更好的性能。相比之下,MLP 模型在使用更简单特征表示的效力预测方面表现出稍好的结果。XGBoost 在 Dmax 回归和 Activity 分类任务中实现了最佳性能。MLP 在使用简单 OneHot 编码的 pDC50 回归任务上优于 XGBoost。XGBoost 配置经常结合 ESM-S-PCA 嵌入,而 MLP 配置始终依赖 OneHot 编码。
作者评估了多个预测任务上优化的 XGBoost 和 MLP 配置,注意到需要不同的架构选择来有效地处理回归和分类目标。比较分析表明,虽然单个模型始终实现最低的预测误差,但集成策略提供了与实际误差相关的优越不确定性量化。此外,性能因任务类型而异,XGBoost 在最大降解和活性分类方面表现出色,而 MLP 在使用更简单特征编码的效力预测方面表现出更好的结果。