Command Palette
Search for a command to run...
连续扩散模型在语言任务中与离散扩散模型具有相当的竞争力
连续扩散模型在语言任务中与离散扩散模型具有相当的竞争力
Zhihan Yang Wei Guo Shuibai Zhang Subham Sekhar Sahoo Yongxin Chen Arash Vahdat Morteza Mardani John Thickstun
摘要
尽管扩散模型(Diffusion)近期在语言建模领域备受关注,但连续扩散(continuous diffusion)往往被认为比离散方法的可扩展性较差。为了挑战这一观点,我们重新审视了基于似然的连续扩散语言模型(Continuous Diffusion Language Model, DLM)——Plaid,并通过将 Plaid 的架构与现代离散 DLM 对齐,构建了 RePlaid。在这一统一设置下,我们确立了首个可与离散 DLM 相媲美的连续 DLM 缩放定律(Scaling Law):与自回归(autoregressive)模型相比,RePlaid 的计算差距仅为 20 倍;在参数数量更少的情况下,其性能优于 Duo;在过度训练(over-trained)阶段,其性能优于 MDLM。我们在 OpenWebText 数据集上对 RePlaid 与近期的连续 DLM 进行了基准测试(Benchmark):RePlaid 在连续 DLM 中实现了新的最佳困惑度(PPL)下限 22.1,并展现出更优的生成质量。这些结果表明,当通过似然进行训练时,连续扩散是一种极具竞争力且可扩展的离散 DLM 替代方案。此外,我们提供了理论见解以理解基于似然训练的优势。研究表明,通过优化噪声调度(noise schedule)以最小化证据下界(ELBO)的方差,自然会在时间维度上产生线性的交叉熵(信息损失)。这种方法无需任何针对特定情况的参数重定义,即可均匀分布去噪难度。
一句话总结
作者构建了 RePlaid,这是一种基于似然性的连续扩散语言模型,通过将 Plaid 的架构与现代离散 DLM 对齐来挑战可扩展性假设,建立了第一个连续扩散的缩放定律,其表现可与离散方法相媲美,与自回归模型相比计算差距仅为 20 倍,并且在 OpenWebText 上实现了连续 DLM 中新的最先进困惑度边界 22.1,表明基于似然性的训练是一种具有竞争力且可扩展的替代方案。
核心贡献
- 这项工作通过将对基于似然性的连续扩散模型 Plaid 的架构与现代离散扩散语言模型对齐,构建了 RePlaid。由此产生的统一设置使得与离散方法的可扩展性比较更加严谨。
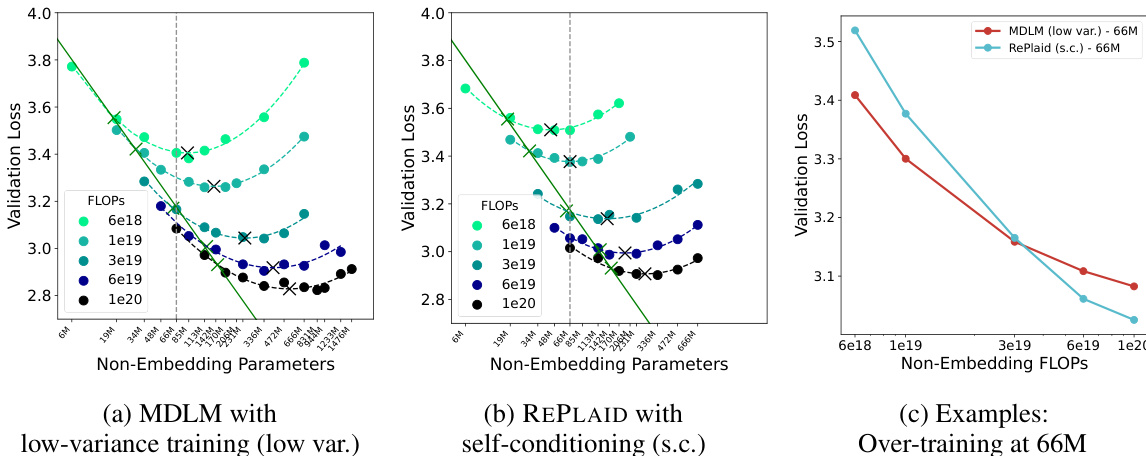
- 实验建立了连续扩散语言模型的第一个缩放定律,揭示了与自回归模型相比计算差距仅为 20 倍。RePlaid 在参数更少的情况下优于 Duo,并在过训练阶段超越 MDLM。
- OpenWebText 上的基准测试显示,RePlaid 在连续扩散语言模型中实现了 22.1 的新最先进困惑度边界。本文还提供了理论见解,证明优化噪声调度以最小化 ELBO 方差会产生随时间线性变化的交叉熵。
引言
连续扩散语言模型在可控性和采样效率方面提供独特优势,但由于巨大的计算开销,它们在可扩展性方面历史上表现不如离散扩散和自回归模型。为了挑战这一说法,作者引入了 RePlaid,这是一种现代化的基于似然性的模型,将连续扩散架构与既定的离散缩放协议对齐。他们的统一基准显示,连续扩散通过将计算差距减少到相对于自回归基线仅为 20× 的同时实现了最先进困惑度,从而具有竞争力地扩展。此外,该工作提供了理论见解,证明基于似然性的训练自然地优化噪声调度和嵌入几何以提高性能。
数据集
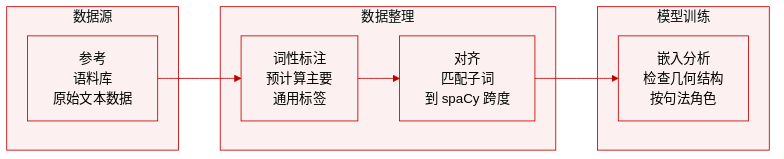
- 组成和来源:作者利用参考语料库为每个 GPT-2 子词 token 预计算一个主导的 Universal POS 标签。
- 处理和对齐:他们通过字符偏移将子词与 spaCy 词跨度对齐,以解决 GPT-2 BPE 分割与整词 POS 定义之间的不匹配。
- 用途:此数据有助于分析基于句法角色的嵌入几何。
方法
作者利用了一个变分扩散模型 (VDM) 框架,该框架经过调整用于文本生成,称为 Plaid。该方法包括一个稳健的数据处理管道以构建有效的输入序列,随后是在低维 token embeddings 上运行的连续扩散过程。
输入表示和数据处理
为了确保输入序列与嵌入空间对齐,作者实施了一个特定的分词和词性 (POS) 对齐管道。给定 token IDs 的语料库,文本被解码并处理以恢复每个子词的字符偏移。POS 标记器在单词级别分析解码后的文本,并且这些标签基于字符跨度重叠继承给子词。这种对齐确保句法信息在输入表示中得到保留。

快速 tokenizer 然后返回具有特定字符跨度的子词,这可能会将一个单词分割成多个 tokens。例如,像 purring 这样的动词可能会被分割成不同的子词单元。对齐过程将属于单个单词的所有子词归因于相同的 POS 标签。

为了促进这种对齐,字符到单词的映射被分配为整数数组。数组中的每个索引对应于文本中的字符位置,并填充覆盖该位置的 spaCy 单词的索引。对于每个子词,分析对应于其跨度的该映射切片,并将主要的 spaCy 索引分配为标签。

模型架构和扩散过程
一旦输入序列准备就绪,Plaid 识别长度为 L 的序列 x,其矩阵在 {0,1}L×V 中,其中 V 是词汇表大小。序列通过可学习的 token-embedding 矩阵 E∈RV×de 嵌入到连续空间中,产生嵌入序列 e:=xE∈RL×de。作者使用低维嵌入,其中 de=16,以降低与高维 one-hot 注入相比的计算成本。
前向过程 q 对嵌入 e 应用高斯加噪:
q(zt∣x)=N(αte,σt2I),t∈[0,1],其中 αt 和 σt 是满足方差保持约束 αt2+σt2=1 的平滑标量函数。反向过程由时间条件去噪模型 xθ 参数化,该模型输出词汇表上的分类分布。模型预测干净嵌入 eθ(zt,t):=xθ(zt,t)E。
训练过程和损失
训练最小化负证据下界 (NELBO),其中包括三项:先验损失、重建损失和扩散损失。先验损失正则化 t=1 处的潜在分布。重建损失专注于 t=0 处的干净数据,而扩散损失优化中间时间步的去噪轨迹。
在训练期间,批次被自适应地划分为重建子批次和扩散子批次。重建子批次精确采样时间 t=0,而扩散子批次从 [0,1] 上的低差异分布中采样 t。先验损失利用整个批次。此外,采用自条件,其中对于批次的部分,初始无梯度前向传递估计干净数据以条件后续预测。
噪声调度是可学习的,参数化为 γ(t)=γ0+(γ1−γ0)γ~(t)。端点 γ0 和 γ1 直接最小化扩散损失,而内部形状 γ~(t) 更新以最小化损失估计器的方差。此学习过程确保每时间步扩散损失保持恒定,有效地将去噪难度均匀分布在整个时间中。
整体训练步骤涉及计算 NELBO 项,通过损失反向传播,并更新优化器。调度参数和去噪器权重联合更新,以最大化模型下数据的可能性。
实验
评估利用 SlimPajama 上的统一缩放基准和 OpenWebText 及 LM1B 上的生成测试,以将 RePlaid 与离散和连续扩散语言模型进行比较。IsoFLOP 分析显示,RePlaid 与自回归基线相比具有竞争力地扩展,同时表现出更优越的参数效率,并在过训练阶段超越 MDLM。此外,似然和采样评估确认 RePlaid 在考虑的模型中实现了最佳困惑度边界,并生成与离散对应物相当的高质量文本,突出了优化真实变分边界的好处。
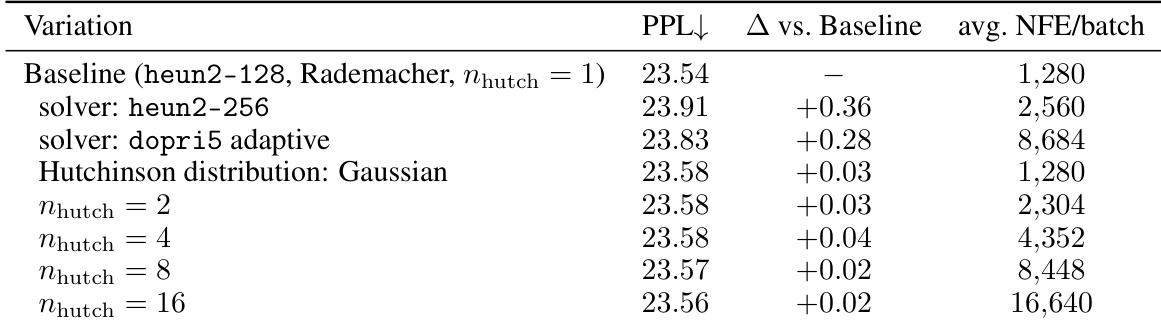
实验通过改变求解器设置和散度估计参数来评估基于 ODE 的似然估计器的稳定性。结果显示,平均 Perplexity 在不同配置下保持一致,表明基线求解器已充分收敛且估计器无偏。增加计算复杂性,例如使用更多 Hutchinson 样本,不会产生显著的性能提升。求解器变化,包括更高的步数计数和自适应方法,导致似然估计的变化可忽略不计。散度估计器无论使用 Rademacher 还是高斯分布都保持一致的性能。提高 Hutchinson 样本计数会大幅增加计算成本,而对最终 Perplexity 分数影响甚微。
作者调查了链式法则项对 RePlaid 和 LangFlow 基于 ODE 的似然估计的影响。他们发现省略该项会显著降低 PPL 分数,造成重大偏差,而包含该项确保估计作为负对数似然的有效上界。在修正协议下,RePlaid 始终表现出优于 LangFlow 的似然性能。排除链式法则项会在两个模型的 PPL 估计中造成重大的向下偏差。当正确应用链式法则修正时,RePlaid 实现的困惑度低于 LangFlow。修正的估计方法产生与 VDM NELBO 基线一致的结果,而不修正的版本产生不可信的分数。

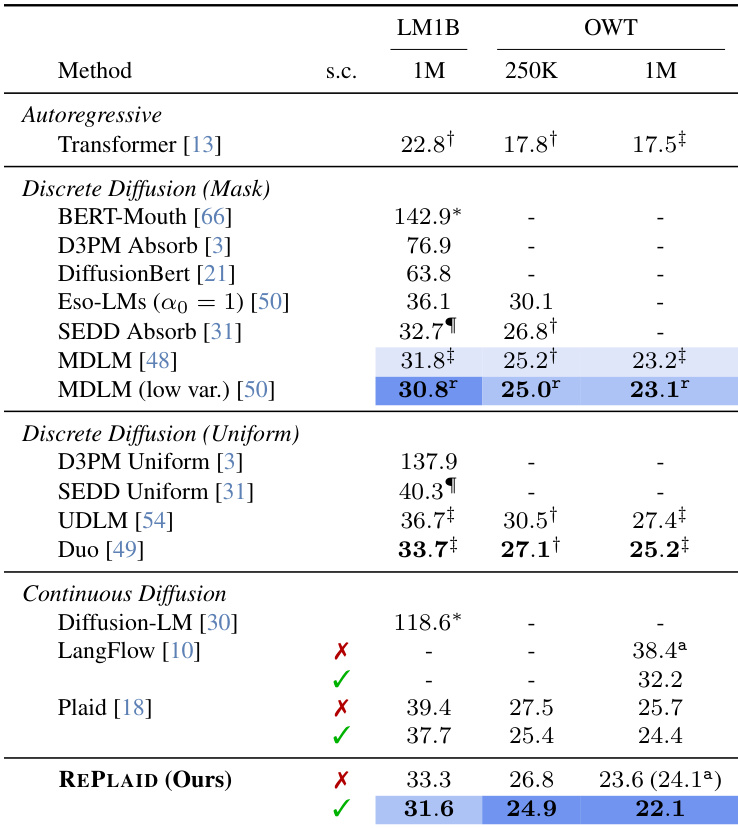
该表比较了 LM1B 和 OpenWebText 数据集上自回归、离散扩散和连续扩散语言模型的测试困惑度。结果显示,带有自条件的 RePlaid 在扩散模型中实现了最佳性能,在 OpenWebText 上优于强大的离散基线如 MDLM 和 Duo。即使没有自条件,RePlaid 也表现出优于其他连续扩散方法和 Duo 基线的性能。带有自条件的 RePlaid 在 OpenWebText 上的扩散模型中实现了最低困惑度。在 LM1B 上,带有自条件的 RePlaid 优于 Duo 但落后于 MDLM。没有自条件的 RePlaid 在 OpenWebText 上优于 Duo 和 LangFlow。
该表呈现了一项消融研究,评估特定架构组件对 RePlaid 模型困惑度性能的贡献。带有自条件的完整配置实现了最佳结果,而移除可学习嵌入导致模型质量最严重的退化。其他组件,包括可学习噪声调度和输出先验,也证明对最终性能指标有积极贡献。带有自条件的完整 RePlaid 模型在所有测试配置中实现了最低困惑度。移除可学习嵌入导致最大的性能下降,显著恶化困惑度分数。可学习噪声调度和自条件组件相对于其各自的消融版本提供了实质性增益。

实验评估了基于 ODE 的似然估计器的稳定性,表明基线求解器设置产生一致的结果,而无需增加计算复杂性。进一步分析验证了链式法则修正的必要性,以防止有偏的困惑度分数,确认当估计正确校准后 RePlaid 优于 LangFlow。比较和消融研究揭示,带有自条件的 RePlaid 在各种扩散和离散基线中实现了优越的性能,可学习嵌入被确定为最关键的架构组件。