Command Palette
Search for a command to run...
交互评估需要一种设计科学
交互评估需要一种设计科学
摘要
AI 评估正在经历结构性变革大型语言模型(LLMs)正日益被部署为能够通过工具、环境、用户及其他 Agent 随时间推移执行动作的系统。然而,许多现有的评估实践仍沿袭了以响应为中心(response-centered)基准测试的假设:即固定的输入、孤立的输出,以及仅基于单次响应做出的判断。尽管互动式基准测试(interactive benchmarks)已应运而生,但整体格局依然碎片化:不同基准测试在接纳的交互产物(interaction artifacts)、轨迹(trajectories)的评分方式以及结果所能支持的论断方面存在显著差异。本文指出,互动式评估应被视为一种原则性的评估范式,而不仅仅是一类新的 Agent 基准测试。简单沿用以往的评估范式已不足以应对当前的挑战。我们将评估定义为从证据到判断的自主映射过程,并指出互动式评估改变了这一映射的两个方面:证据转变为交互生成的轨迹,而评估过程则必须评估过程性、可恢复性(recoverability)、协调性、鲁棒性以及系统级性能。基于这一定义,我们提出了一个双轴分类法(two-axis taxonomy),推导出了设计原则与报告标准,考察了具有代表性的应用场景,并分析了长期存在的评估挑战如何在轨迹层面上重新显现。
一句话总结
这篇立场论文认为,交互式评估需要一种设计科学,而不仅仅是依赖孤立输出的零散基准。它将评估定义为从证据到判断的自主映射,其中交互生成的轨迹取代了固定输入,并通过提出的双轴分类法、设计原则和报告标准,利用程序评估过程、可恢复性、协调性、鲁棒性和系统级性能。
核心贡献
- 该论文确立了评估的正式定义,即从证据到判断的自主映射,其中证据从孤立输出转变为交互生成的轨迹。此框架要求评估程序评估过程、可恢复性、协调性和系统级性能,而非单一响应。
- 引入了一种双轴分类法来组织交互式评估,推导出基准构建的具体设计原则和报告标准。这些标准解决了可重放的轨迹日志、环境版本控制和透明评分机制等需求。
- 考察了包括 coding agents 在内的代表性场景,以分析长期存在的评估挑战如何在轨迹层面重现。此分析强调需要轨迹级指标而非最终解决标签,以区分真正的调试能力与基准利用。
引言
大型语言模型越来越多地作为随时间通过工具和环境进行操作的系统部署,而非独立生成器。当前的评估实践通常继承了以响应为中心的假设,将孤立输出视为充分证据,这无法捕捉交互式设置中的过程质量或系统级鲁棒性。此外,交互式基准的格局仍然碎片化,存在不同的工件和评分程序,模糊了结果支持的哪些主张。作者认为交互式评估应被视为一种原则性的设计科学,以解决这种碎片化问题。他们将评估定义为从交互生成的轨迹到判断的自主映射,并提出双轴分类法及设计原则,使基准主张可解释且可比。
数据集

- 数据集构成与来源: 作者构建了一个基准语料库来分析交互式评估的时间趋势。他们结合了一个手动策划的代表性列表和两个半自动检索渠道,包括基于引用的雪球采样和涵盖 2020 年至 2026 年的 Semantic Scholar 搜索。
- 关键细节与过滤: 团队使用 arXiv ID 或标准化标题对条目进行去重。如果论文出现在顶级会议中、达到至少 1.5 的引用速度或积累了 50 个或更多 GitHub stars,则保留在最终集合中。
- 分类与子集: 基于标题和摘要,一个基于 LLM 的分类器将语料库分为三个路线图类别。被分类为 Not Relevant 的论文被排除在趋势分析之外。在手动锚定集上的验证确认在全面应用之前与人类标签的同意率超过 90%。
- 用途与元数据: 该集合作为描述广泛时间趋势的描述性证据,而非模型训练数据。不适用训练集或混合比例。记录引用次数和 GitHub stars 等元数据作为影响力的近似指标,同时注意关于仓库年龄的局限性。
方法
作者提出了一个用于 Interactive Evaluation 的方法论框架,重新定义了标准评估映射 E:X→Y。这种方法将重点从静态答案验证转移到对动态交互过程的评估。
该框架的演变在下面的时间线中说明,将基准分为四个不同的阶段。
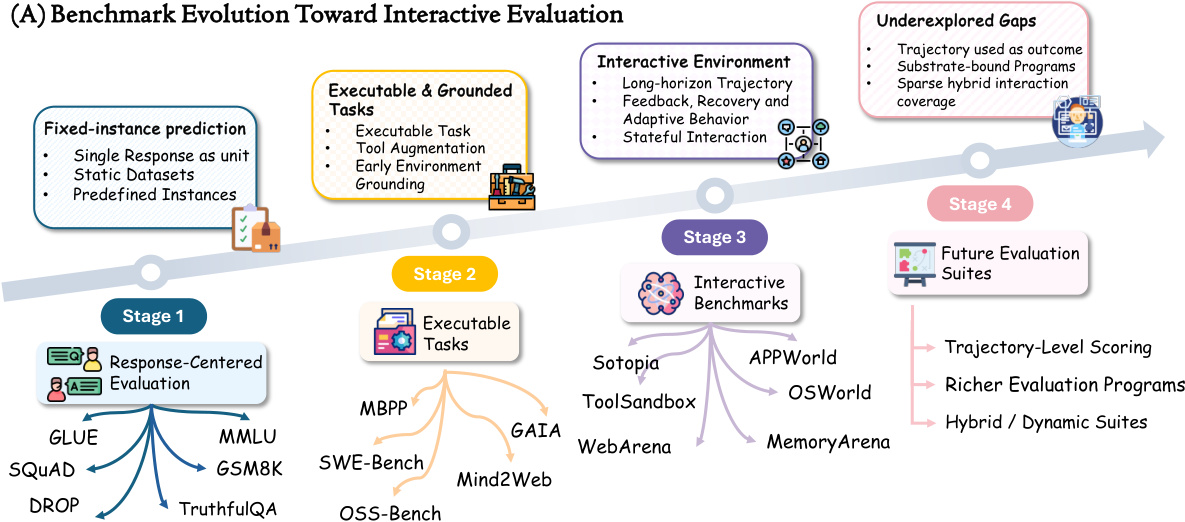
阶段 1 代表传统的 Response-Centered Evaluation,依赖固定实例预测和静态数据集如 GLUE 或 MMLU。阶段 2 引入 Executable & Grounded Tasks,结合工具增强和早期环境 grounding。阶段 3 标志着向 Interactive Benchmarks 的过渡,特点是长视野轨迹、反馈循环和有状态交互。最后,阶段 4 概述了 Future Evaluation Suites,旨在实现轨迹级评分和混合动态套件,解决未探索的差距,如 substrate-bound programs 和稀疏交互覆盖。
传统评估与交互式评估之间的核心区别由评估映射的组件定义。参考下面的比较图以详细了解这些组件。
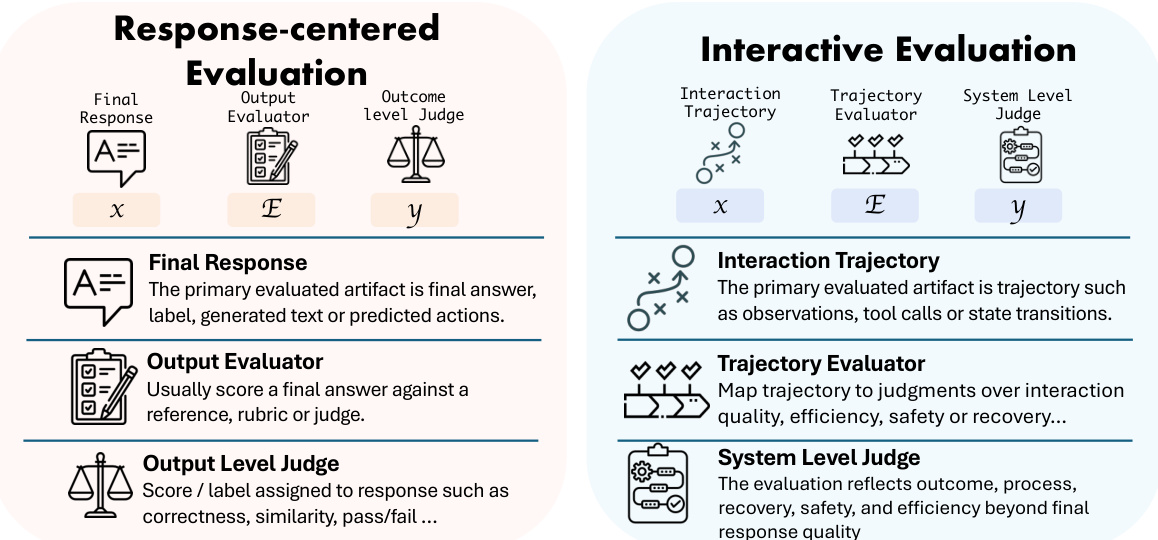
在 Response-Centered Evaluation 范式中,主要工件是最终响应 x。评估器 E 充当输出评估器,通常根据参考或评分标准对最终答案进行评分。生成的判断 y 是结果级评估,例如正确性或通过/失败状态。
相比之下,Interactive Evaluation 从根本上将输入工件 x 更改为 Interaction Trajectory。该轨迹包括观察、工具调用、状态转换以及在重要交互过程中生成的中间工件。因此,评估器 E 变为 Trajectory Evaluator。该模块不再仅仅检查最终答案,而是将轨迹映射到关于交互质量、效率、安全性和恢复性的判断。最终输出 y 是 System Level Judge,反映系统超出最终答案的结果、过程和弹性。
该框架利用这种双轴视图,根据哪些交互生成的工件进入 X 以及程序 E 如何将那些工件映射到判断来对评估进行分类。此设计允许评估复杂属性,如错误后的可恢复性、合作行为以及中断下的鲁棒性,这些在基于静态响应的基准中是不可见的。
实验
保真度、控制和模拟器工件。交互式评估必须决定重现多少部署内容以及抽象掉多少内容。高保真环境可以提供关于情境行为的更丰富证据,但它们昂贵、嘈杂且更难控制。受控模拟器提高了可重复性和可比性,但可能会奖励利用模拟器工件而非真正交互能力的策略。在现实性和控制之间没有通用的最优解。基准应说明哪些部署条件它们忠实建模,哪些故意抽象掉,以及哪些主张其保真度级别可以或不能支持。
评估器和对应物依赖。随着用户模拟器、模型评估器、人类专家和 counterpart agents 成为标准化的评估基础设施,它们开始塑造什么算作成功的交互。分数可能会奖励对特定评估器或对应物策略的适应,而不是预期的能力。这造成了构造效度风险:系统可能在一个评估器、模拟器或专家组下表现良好,但在合理的替代方案下失败。未来的基准应测试结论在评估器和对应物变体之间是否保持稳定。
- 替代观点 6:交互式评估混淆了模型能力与系统工程。
进一步的反对意见是,交互式基准通常评估的不仅仅是基础模型。工具包装器、记忆、检索系统、规划器、沙盒、界面功能、编排策略和提示策略可能主导性能。如果是这样,交互式评估可能使得难以知道进步是来自于更好的模型还是更好的系统工程。
回应。论文同意交互式评估通常评估系统而非孤立模型。这不是范式的缺陷;它是激励该范式的部署设置的属性。当 AI 系统通过工具、环境、用户、记忆或其他 agents 行动时,相关的评估对象通常是组装好的系统。忽略包装器、权限、状态、编排或工具接口的基准可能提供更清晰的模型级比较,但可能不支持关于部署交互式行为的主张。
这意味着基准报告必须区分模型级和系统级主张。如果目标是比较基础模型,则周围的脚手架应受控并报告。如果目标是比较完整的 agents 或部署的助手,则脚手架是评估对象的一部分,应如此记录。因此,交互式评估提高了报告标准:仅模型身份是不够的。评估应指定工具、记忆、检索、提示、编排、沙盒权限、环境版本和日志记录协议,以便读者可以解释分数实际上是关于什么的证据。
- C.3 行业与学术比较。
图的 (c) 面板比较了最近的前沿行业报告与 2024-2026 年学术基准论文之间的评估阶段构成。行业样本包含 43 个不同的基准系列,提取自 OpenAI、Anthropic、Google DeepMind 和 Alibaba/Qwen 的最新公开模型卡片或技术报告,每个基准系列在源文档中只计算一次,无论变体或子任务如何。学术样本是上述基准集合的 2024-2026 子集,包含 360 篇基准论文。条形图报告每组内的百分比份额,因此每组总和为 100%。皮尔逊 χ2 检验给出 χ2(2)=7.09, p=0.029,表明阶段分布存在统计学显著差异。论文将此比较解释为描述性证据,表明向任务驱动和交互式评估的转变在评估生态系统中是不平衡的,而不是对任一社区的详尽普查。