Command Palette
Search for a command to run...
当视觉为声音代言
当视觉为声音代言
Xiaofei Wen Wenjie Jacky Mo Xingyu Fu Rui Cai Tinghui Zhu Wendi Li Yanan Xie Muhao Chen Peng Qi
摘要
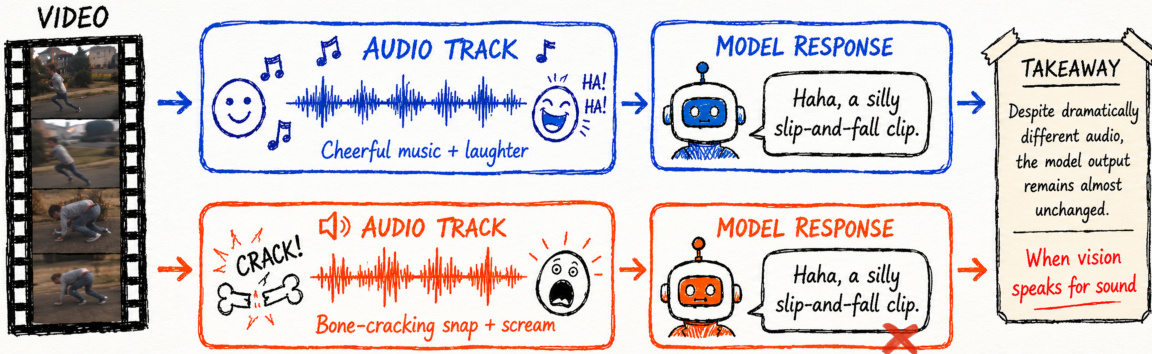
尽管具备视频处理能力的多模态大语言模型(MLLMs)取得了快速进展,但我们发现,其在视频中表现出的音频理解能力往往是由视觉驱动的:模型依赖视觉线索来推断或幻觉出声学信息,而非对音频流进行验证。这一问题在最新的开源全模态模型以及来自 Google 和 OpenAI 等厂商的主流闭源模型中普遍存在。我们将这种失效模式表征为“视听 Clever Hans 效应”,即模型看似(错误地)以音频为基础,但实际上是利用视听相关性,而未验证音频流与视频流是否真正对齐。为了系统地研究这一行为,我们引入了 Thud,这是一个基于三种反事实音频编辑的干预驱动探测框架:Shift(移位),用于测试时间同步性;Mute(静音),用于测试声音的存在性;以及 Swap(交换),用于测试视听一致性。除了诊断之外,我们还进一步研究了一种两阶段对齐方案:由干预生成的偏好对用于教授音频验证,而事件级的通用视频偏好则用于正则化模型,防止其过度特化。我们最佳的包含 1 万个样本的对齐方案使三个干预维度的平均性能提升了 28 个百分点,同时在通用视频和视听问答基准测试上的性能也略有提升。
一句话总结
作者提出了 THUD,这是一种基于干预的检测框架,通过采用 Shift(偏移)、Mute(静音)和 Swap(替换)三种反事实音频编辑,结合两阶段对齐策略来强制进行真实的声学验证,从而诊断并缓解视频多模态大语言模型(Video MLLMs)中的音频-视觉“聪明汉斯”效应。该方法在干预维度上的平均性能提升了 28 个百分点,同时对通用视频和音视频问答基准测试略有提升。
核心贡献
- 提出 THUD,一种基于干预的检测框架,通过三种反事实音频编辑(Shift 用于时间同步、Mute 用于声音存在性、Swap 用于音视频一致性)来评估音视频定位能力。该框架系统性地诊断了具备视频处理能力的多模态模型如何依赖视觉-语义捷径,而非验证实际的声学流。
- 开发了一种两阶段偏好对齐策略,将基于干预的音频验证信号与事件级的通用视频偏好相结合,以防止模型过度特化。该方法显式地训练模型在视觉-声学关联断裂的情况下交叉验证音频的存在性与对齐情况。
- 证明应用此包含 1 万样本的对齐策略后,模型在三个干预维度上的平均性能提升了 28 个百分点,同时在标准视频和音视频问答基准测试中取得了小幅提升。
引言
具备视频处理能力的多模态大语言模型正在快速发展,使得音视频理解成为从辅助技术到安全关键型监控等各类应用中的核心能力。尽管基准测试分数表现强劲,但作者发现这些模型经常表现出“聪明汉斯”效应,即依赖视觉-语义捷径来幻觉化生成声学信息,而非真正验证音频流。标准评估协议通过保留自然的跨模态相关性掩盖了这一局限性,导致在可靠的音视频定位方面存在显著空白。为应对这一挑战,作者引入了 THUD,这是一种基于干预的诊断框架,利用反事实音频编辑来系统性地审查时间同步性、音频存在性以及跨模态一致性。作者进一步证明,将此类反事实干预与通用视频数据相结合的目标偏好对齐策略,在保持强大通用视频理解能力的同时,显著提升了真实的音频验证效果。
数据集
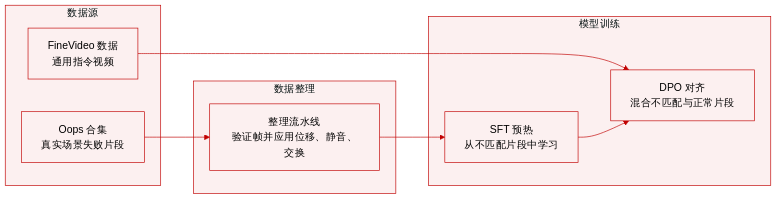
-
数据集构成与来源: 作者构建了一个包含两部分的专用数据集,用于音视频定位评估与模型对齐。核心干预数据集源自 Oops 集合,该集合收录了自然场景下人类无意行为与失败案例的视频。为提供更广泛的上下文训练,作者补充了来自 FineVideo 的通用视频指令数据。
-
子集详情与过滤规则: 干预子集对原始视频片段应用三种受控修改:Shift(通过时间偏移平移音频)、Mute(将音频替换为静音)和 Swap(将音频替换为来自不同视频的音轨)。具体样本数量未明确说明,但作者实施了严格的质量过滤。视觉时间戳需在 Gemini、GPT 和 Claude 之间对齐至 0.8 秒以内,而声学时间戳需经人工验证至 0.5 秒以内。事件 onset 不明确、音频微弱或被掩盖,或替换后音轨过于相同或完全无关的片段均被剔除。通用视频子集通过 Gemini 重新标注与人工验证进行扩充,最终生成四种指令类型:描述、定位、归因以及音频依赖型问答。
-
训练用途与混合策略: 本文采用两阶段对齐流程。在监督微调(SFT)预热阶段,模型仅使用基于干预生成的偏好对进行训练,以建立音频感知的响应模式。在随后的直接偏好优化阶段,作者将干预偏好对与通用视频指令数据混合。这种混合策略可防止模型过度特化于反事实案例,同时鼓励模型验证音频证据而非依赖视觉捷径。
-
处理、裁剪与元数据构建: 为实现精确的时间验证,作者将视频转换为按时间排序的帧单元,具体方法是将每个片段划分为不重叠的窗口,并为每个单元采样代表性帧。初始标注通过 Gemini 生成,使用结构化 JSON 提示词捕获事件描述、精确时间戳和置信度。这些标注随后通过帧单元格式进行交叉验证。验证完成后,应用三种干预操作符生成最终的偏好对,其中被选中的响应反映准确的音视频定位,而被拒绝的响应则突出显示视觉合理但错误的假设。生成的资源将与干预元数据配对,专门用于诊断评估与对齐研究。
方法
作者利用两阶段后训练流程,通过将基于干预的数据与通用视频指令数据相结合,使多模态模型摆脱对视觉捷径的依赖。整体框架旨在检测并纠正模型对视觉-语义相关性的依赖,同时保留广泛的视频理解能力。
该流程始于干预数据的构建,通过三种物理干预(Shift、Mute 和 Swap)刻意打破自然的音视频相关性。如下图所示,这些干预操作会调整音频与视觉信号的时间对齐、存在性或一致性。具体而言,Shift 通过相对于视频平移音频轨道来引入时间位移,Mute 完全移除音频流,Swap 则将原始音频替换为不匹配的音轨。这些干预应用于具有显著声学后果的源视频,确保生成的数据能够暴露模型在反事实条件下的行为。
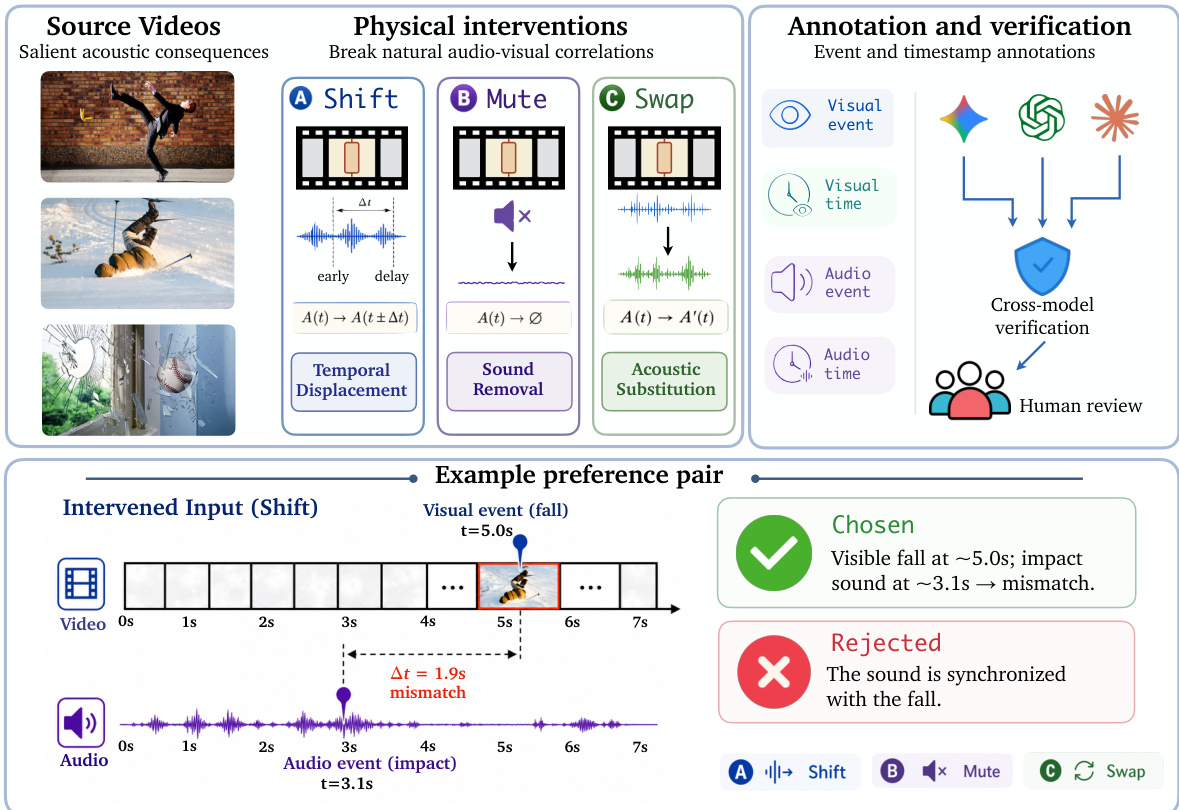
干预完成后,数据进入标注与验证阶段。视觉与音频事件均被分配事件时间标签,偏好对通过比较基于跨模型验证和人工审查的被选与拒绝响应来构建。该流程生成标注示例,要求模型拒绝视觉合理但音频错误的解释,从而强化正确的音视频定位。
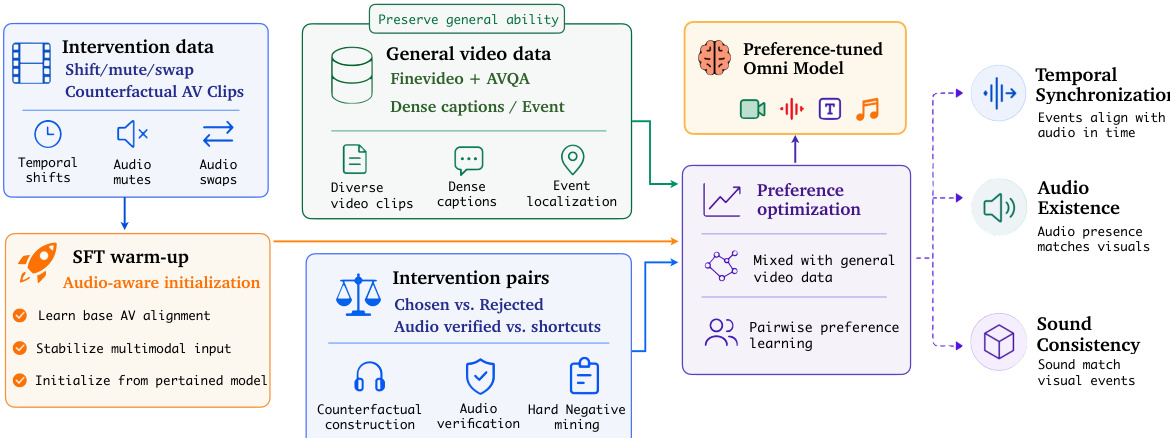
训练过程包含两个独立阶段。第一阶段在干预数据上进行监督微调(SFT)预热,以建立基础的音频感知模式。该阶段使模型初始化以识别并恰当响应音视频不匹配情况。第二阶段,模型使用干预偏好对与通用视频数据的混合体进行偏好优化。干预对引导模型拒绝视觉合理但音频不一致的输出,而通用视频数据则作为正则化项以保留广泛的多模态理解能力。这一双重目标确保模型学会验证音频信号,而非依赖视觉先验。
实验
该评估在自然与反事实条件下针对时间同步性、声音存在性及跨模态一致性进行音视频定位测试,验证了当前模型严重依赖视觉先验与默认同步假设,而非进行真实的音频验证。后续实验验证了目标偏好对齐能否在不产生对齐代价的前提下纠正这些缺陷,结果表明,反事实时间数据与通用视频数据显著增强了稳健的时间定位与偏移检测能力,同时保留了通用的多模态能力。最后,将训练扩展至音频存在性与源一致性后,所有干预下的性能崩溃进一步减少,证实了有意识的跨模态监督能有效缓解捷径依赖并培养可靠的音视频理解能力。
作者分析了多模态模型在音视频定位任务中对视觉捷径的依赖程度,并使用热力图展示不同模型与干预条件下的失败率。结果表明,大多数模型表现出强烈的音频幻觉与时间错位现象,在反事实干预下性能显著下降,这表明模型依赖视觉先验而非真实的音视频对齐。分析凸显了模型对同步预测的系统性偏见,以及对时间偏移检测能力的不足,尤其是在未能验证音频存在性与时间戳的模型中。大多数模型在音频幻觉和时间错位方面表现出高失败率,表明其依赖视觉捷径而非真正的音视频定位。模型始终偏好同步预测,导致高误报同步警报,且对音频偏移的检测能力较差,尤其是在微小时间偏移下。热力图揭示了错误模式中的系统性偏见,模型极少否认真实音频或正确识别时间不匹配的方向。
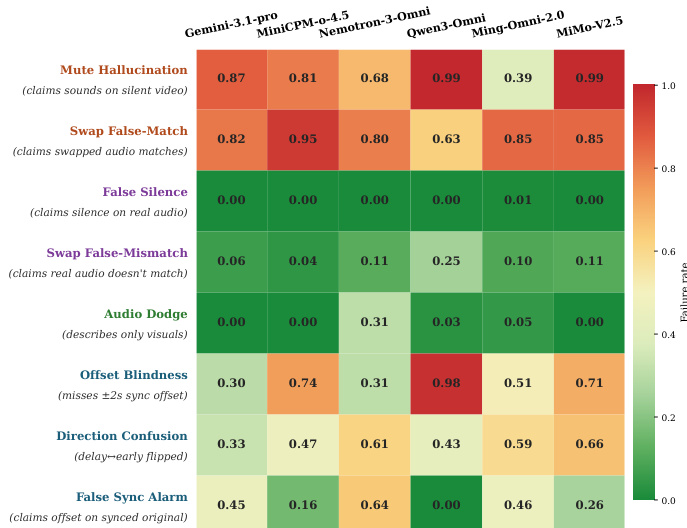
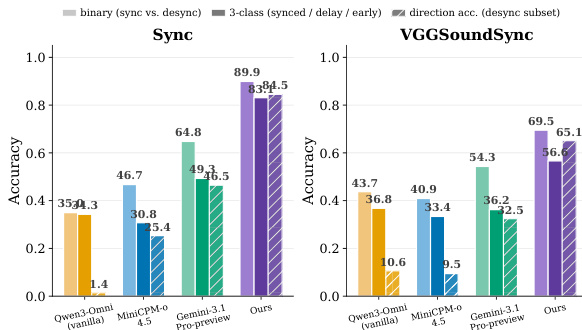
作者考察了多模态模型中的音视频定位能力,重点关注其对视觉捷径的依赖及目标对齐训练的有效性。结果表明,大多数模型在反事实干预下表现出强烈的性能崩溃,表明其依赖视觉-语义先验而非真实的音视频对齐。目标对齐方法在保留通用能力的同时提升了时间同步性,最佳模型在二分类与细粒度时间任务中均取得了显著更高的准确率。大多数模型在反事实干预下出现大幅性能下降,表明其依赖视觉捷径而非真正的音视频定位。目标对齐训练在不损害通用视频理解的前提下改善了时间同步性,在二分类与细粒度时间任务中实现了更好的准确率。最佳模型在不同时间偏移幅度下均保持稳健性能,并在检测与定位去同步现象方面优于基线模型。
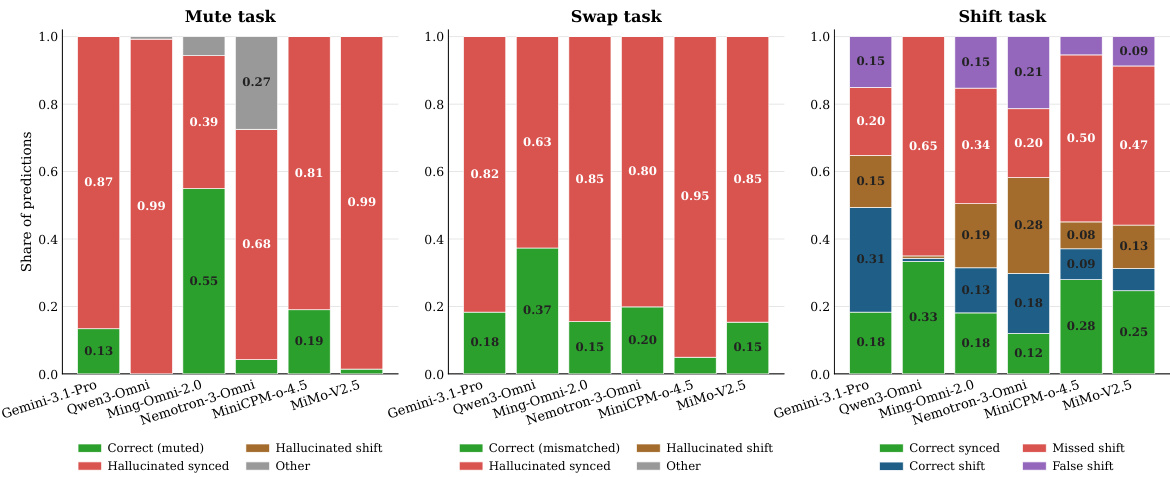
作者使用堆叠条形图分析了模型在 Mute、Swap 和 Shift 三项音视频干预任务中的表现,以展示预测分布。结果表明,大多数模型强烈依赖视觉捷径,尤其在幻觉音频存在性或同步性方面表现突出,而对音频缺失或时间错位的正确检测率极低。表现最佳的模型在识别去同步音视频对方面准确率有所提升,尤其是在 Shift 任务中,这表明目标训练可在不削弱通用能力的情况下增强时间定位能力。模型经常幻觉音频存在性或同步性,极少能正确检测音频缺失或时间错位。在反事实干预下性能显著下降,表明模型强烈依赖视觉捷径而非真实的音视频对齐。目标训练改善了时间定位能力,使模型在检测与定位音视频去同步方面表现出更强的准确率。
作者分析了多款多模态模型在音视频定位任务上的表现,重点关注其对视觉捷径的依赖及检测音视频不一致的能力。结果表明,大多数模型在反事实干预下出现大幅性能下降,表明其强烈依赖视觉先验而非真实的音视频对齐。目标对齐训练在不削弱通用能力的同时改善了时间定位,表现最佳的模型展现出对时间偏移的鲁棒性,并能准确定位音视频错位。大多数模型在反事实干预下性能显著下降,表明其依赖视觉捷径而非验证音频的存在性、时间与一致性。目标对齐训练在不损害通用视频理解的前提下提升了时间同步性,表明模型有效学习了跨模态对齐。表现最佳的模型对时间偏移具有鲁棒性,能够准确定位音视频错位的方向与幅度,超越了简单的去同步检测。
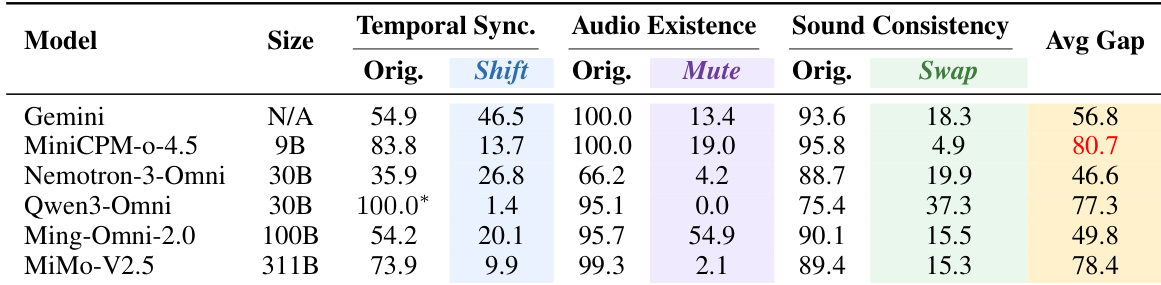
作者对比了各模型在包含音视频干预与原始条件的综合准确率任务上的表现。结果表明,其模型在 Mute 和 Swap 干预设置中均优于其他模型,表明对齐效果得到改善且对视觉捷径的依赖降低。与其他模型相比,所提模型在 Mute 和 Swap 干预场景中均取得了最高的综合准确率。不同模型均观察到性能提升,其中所提模型在 Mute 和 Swap 任务中展现出显著优势。结果表明,该模型在处理音视频干预时更为有效,且不会退化为依赖视觉先验。
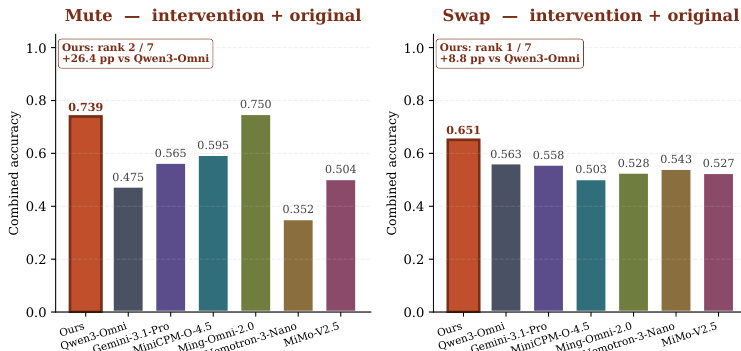
该评估通过应用静音、替换与偏移音频等反事实干预,测试多模态模型的音视频定位能力,以验证其是依赖视觉捷径还是实现真实的跨模态对齐。结果表明,大多数模型严重依赖视觉先验,经常幻觉音频存在性或同步性,并在条件受扰时无法检测时间错位。目标对齐训练通过改善时间同步性与去同步定位,有效弥补了这一缺陷,且未损害通用视频理解能力。最终,实验证明显式的跨模态训练使模型能够超越表层的视觉依赖,实现稳健的音视频定位。