Command Palette
Search for a command to run...
MEMO:记忆即模型
MEMO:记忆即模型
Ryan Wei Heng Quek Sanghyuk Lee Alfred Wei Lun Leong Arun Verma Alok Prakash Nancy F. Chen Bryan Kian Hsiang Low Daniela Rus Armando Solar-Lezama
摘要
大型语言模型(LLMs)在广泛的任务中展现出卓越的性能,但其参数在预训练完成后即被冻结,直到后续更新发生。许多现实世界的应用场景需要及时获取特定领域的最新信息,这促使人们探索能够高效融入新知识的机制。在本文中,我们介绍了 MEMO(Memory as a Model,以记忆为模型),这是一种模块化框架,能够在保持 LLM 参数不变的情况下,将新知识编码到一个专用的 MEMORY 模型中。与现有方法相比,MEMO 具有以下几项显著优势:(a) 能够捕捉复杂的跨文档关系;(b) 对检索噪声具有鲁棒性;(c) 避免了 LLM 出现灾难性遗忘(catastrophic forgetting);(d) 无需访问 LLM 的权重或输出 logits,从而实现与开源及专有闭源 LLMs 的即插即用集成;(e) 在推理阶段,其检索成本与语料库规模无关。我们在 BrowseComp-Plus、NarrativeQA 和 MuSiQue 三个基准测试(benchmark)上的实验结果表明,在不同设定下,MEMO 均取得了相较于现有方法的强劲性能。
一句话总结
本文介绍了 MEMO,一个模块化框架,它将新知识编码到专用的 MEMORY 模型中,同时保持大型语言模型参数不变,以避免灾难性遗忘,并实现与开源和专有闭源 LLM 的即插即用集成,无需权重访问,在 BrowseComp-Plus、NarrativeQA 和 MuSiQue 基准上展示了相较于现有方法的强大性能。
核心贡献
- 本文介绍了 MEMO,一个模块化框架,它将新知识编码到专用的 MEMORY 模型中,同时保持大型语言模型参数不变。
- 该方法通过在不访问模型权重或输出 logits 的情况下运行,实现了与开源和专有闭源 LLM 的即插即用集成。
- 在三个基准上的评估,包括 BrowseComp-Plus、NarrativeQA 和 MuSiQue,表明该系统在不同设置下相较于现有方法实现了强大的性能。
引言
大型语言模型通常依赖变得过时的静态知识,但通过微调更新它们可能导致灾难性遗忘或需要访问专有权重。现有检索方法通常在跨文档推理方面存在困难,遭受检索噪声影响,并随着知识库增长而产生高推理成本。为了解决这些挑战,作者引入了 MEMO,一个模块化框架,它将新知识编码到专用的 MEMORY 模型中,同时保持主 LLM 参数不变。该框架利用新颖的数据合成流程在组合表示上训练内存组件,并利用结构化多轮协议进行查询。这种方法实现了与开源和闭源模型的即插即用集成,同时保持检索成本与语料库大小无关。
数据集

-
数据集构成与来源
- 作者利用 Qwen2.5-32B-Instruct 生成模型驱动的五步合成流程,从目标语料库构建了 Reflection QA 数据集 (Qfinal)。
- 源材料由三个知识密集型基准组成:BrowseComp-Plus、NarrativeQA 和 MuSiQue。
- 该流程旨在捕获单文档事实和跨文档关系,而不嵌入文档标识符或水印。
-
各子集的关键细节
- BrowseComp-Plus 包含 300 个采样问题,配对的 1,775 个证据和 1,766 个负面文档,过滤非英文实例后总计 3,541 个文档。
- NarrativeQA 包含 293 个问题,分布在约 100,000 个长文档中,如书籍和电影剧本,没有负面文档。
- MuSiQue 包含 1,000 个问题,需要跨维基百科段落进行多步推理,利用 2,648 个证据和 2,648 个负面文档,总计 5,296 个文档。
-
数据使用与训练
- MEMORY 模型从 Qwen2.5-14B-Instruct 初始化,并在合成的 QA 对上训练 3 个 epoch。
- 合成过程生成验证过的自包含对、实体浮现对和跨文档合成对,以提供多样化的训练信号。
- 对于持续集成实验,NarrativeQA 被划分为两个不相交子集,每个包含约 640k QA 对,以测试模型合并方法。
-
处理和分块策略
- NarrativeQA 文档经历滑动窗口分块,窗口大小为 6,400 词,重叠 640 词,以处理长上下文,产生的块主要在 4,097 到 16,384 tokens 之间。
- MuSiQue 和 BrowseComp-Plus 文档被视为单个块,因为大多数分别低于 512 tokens 或 32,768 tokens。
- QA 对经过验证以确保自包含性,重写任何存在未解决代词或隐式引用的实例,同时丢弃模糊对。
- 负面文档数量按问题封顶,以管理跨文档合成步骤二次缩放产生的计算成本。
方法
作者介绍了 MEMO(Memory as a Model),一个旨在将领域特定知识集成到大型语言模型中的模块化框架,而不修改主推理引擎的参数。该架构通过采用冻结的 Executive 模型进行推理,以及专用的可训练 MEMORY 模型从目标语料库编码知识,将知识存储与推理解耦。整体框架通过两个不同阶段运行:构建 MEMORY 模型的训练阶段,以及 Executive 模型查询此内存的推理阶段。
请参阅框架图以了解训练和推理流程的视觉分解。
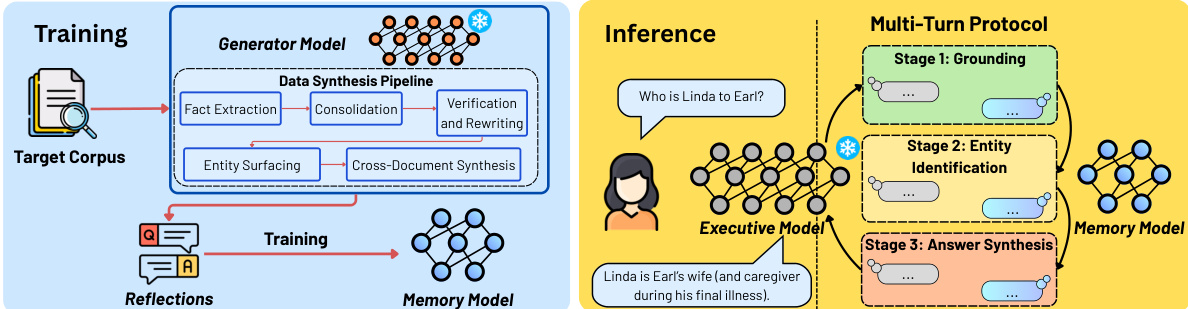
训练阶段始于目标语料库,通过数据合成流程由生成模型处理。该流程首先执行事实提取,随后进行整合、验证与重写以确保准确性。同时,系统进行实体浮现和跨文档合成,以捕获语料库中的复杂关系。该过程的输出是一组 Reflections,作为 Reflection QA 数据集。MEMORY 模型随后从小型预训练语言模型初始化,并通过监督微调在这些 Reflections 上进行训练。关键的是,该模型被优化为直接将问题映射到答案,而在推理时无需访问源文档。这迫使 MEMORY 模型以参数化方式内部化知识,而不是依赖检索。训练目标仅最小化答案 tokens 上的下一个 token 预测损失:
L(φ)=−(qi,ai)∈Qfinal∑t=1∑∣ai∣logMφ(ai(t)qi,ai(1:t−1)).在推理阶段,冻结的 Executive 模型通过结构化多轮协议与 MEMORY 模型交互。该协议旨在通过三个连续阶段逐步提高产生正确答案的可能性。在阶段 1(基础定位)中,Executive 模型将用户查询分解为原子、线索探测子问题。MEMORY 模型独立回答这些问题以提供上下文基础。在阶段 2(实体识别)中,Executive 模型利用基础响应通过针对性后续查询迭代缩小候选实体集,直到识别出单个实体。最后,在阶段 3(答案合成)中,Executive 模型查询 MEMORY 模型以获取关于已识别实体的支持事实。一旦收集到足够的证据,Executive 模型将累积响应合成为最终答案。此过程确保交互保持紧凑且独立于语料库大小,允许系统即使在黑盒 Executive 模型下也能有效运行。
实验
MEMO 在长上下文和多跳推理基准上始终优于基于检索的基线,同时在其他方法退化的情况下保持对检索噪声的鲁棒性。该框架支持灵活的即插即用集成,与多样化的 EXECUTIVE 和 MEMORY 模型结合,表明结构化多轮评估和特定数据合成步骤对最大化性能至关重要。此外,通过模型合并进行持续集成相比完全重新训练提供了显著的计算节省,同时未牺牲相对于标准检索方法的质量优势。
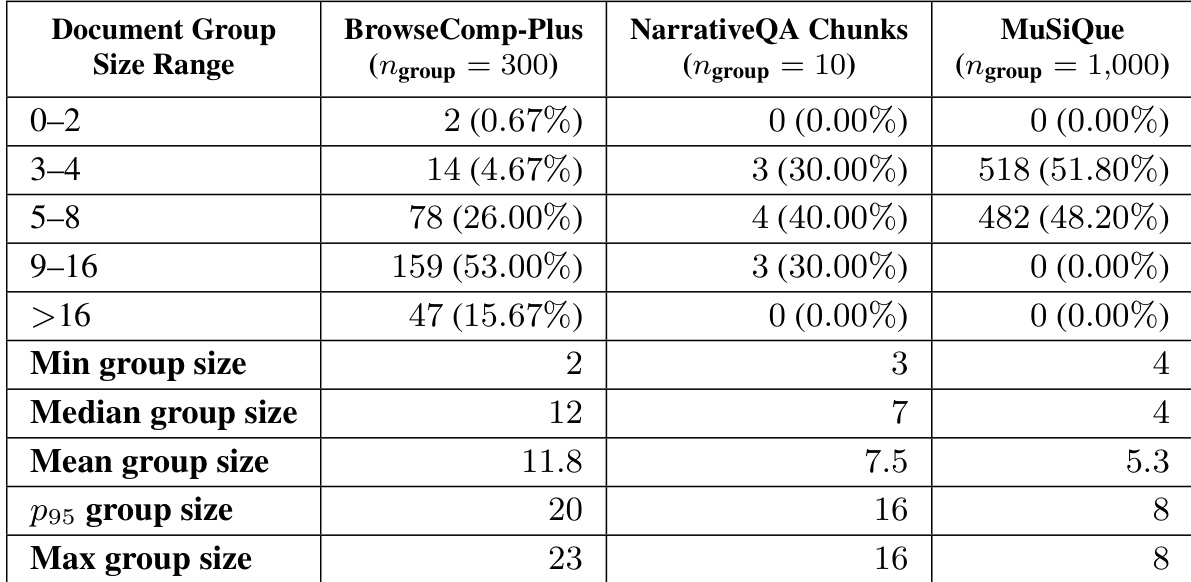
该表展示了三个基准上文档组大小的分布:BrowseComp-Plus、NarrativeQA Chunks 和 MuSiQue。BrowseComp-Plus 表现出最大的组大小,表明与其他数据集相比,对多文档合成的需求更高。相反,MuSiQue 的特点是组大小较小,而 NarrativeQA Chunks 处于中间位置。BrowseComp-Plus 表现出最大的文档组大小,大多数样本落在上限范围内。MuSiQue 表现出最小的组大小,最大组大小明显低于其他数据集。NarrativeQA Chunks 显示中等分布,样本最高集中在中等大小范围内。
作者评估了各种模型合并策略以促进持续集成,比较了线性、SLERP、TIES 和 DARE 等家族。结果表明,采用稀疏化和符号冲突解决的合并方法通常优于简单的线性平均或插值,其中 TIES 表现出最强的性能。TIES 在测试的合并配置中显示出最高准确率。较低的稀疏密度结合符号冲突解决比高密度产生更稳健的结果。SLERP 插值产生的准确率低于其他合并方法。

该实验评估了基于检索的基线 NV-Embed-V2 和 HippoRAG2 对不同程度检索噪声的鲁棒性。两种方法对干扰文档表现出明显的敏感性,随着噪声水平从零增加到证据数量的两倍,准确率一致下降。这种退化证实了标准检索系统在现实语料库条件下难以有效过滤无关信息。NV-Embed-V2 和 HippoRAG2 在两个数据集上都显示出随着噪声水平从零增加到证据数量两倍的持续性能下降。即使每个证据项只有一个干扰文档,准确率也会立即下降,表明对噪声的高度脆弱性。当噪声水平翻倍时,HippoRAG2 在 BrowseComp-Plus 上的准确率下降幅度大于 MuSiQue。

作者评估了模型合并作为在 NarrativeQA 数据集上进行持续集成的具有成本效益的替代方案,替代完全重新训练。结果表明,合并大幅降低了计算成本,同时保持了超过基于检索方法的性能,尽管与重新训练基线相比存在精度权衡。合并在不相交子集上训练的模型显著减少了与在组合数据集上完全重新训练相比的累积计算需求。与完全重新训练相比,合并方法在两个测试的 Executive 模型上均产生可测量的精度损失。尽管存在性能差距,合并模型仍保持优于标准基于检索基线的性能。

作者评估了无上下文与完美检索的模型性能,以评估数据集适用性。结果显示所有基准都存在显著差异,证实模型严重依赖证据文档来正确回答问题。BrowseComp-Plus 表现出最大差距,表明答案不存在于参数化知识中,而 MuSiQue 在没有上下文的情况下显示出更高的基线性能。无上下文与完美检索之间的巨大性能差距证实所有基准都需要外部证据。BrowseComp-Plus 显示出最宽的差距,表明答案不存在于模型的参数化知识中。MuSiQue 在没有上下文的情况下产生最高分数,表明其基于维基百科的问题与预训练知识一致。

该评估分析了包括 BrowseComp-Plus 和 MuSiQue 在内的数据集的基准特征、模型合并策略和检索鲁棒性。结果表明 BrowseComp-Plus 需要显著的多文档合成,且标准检索基线表现出对噪声的高度敏感性。此外,像 TIES 这样的合并技术提供了完全重新训练的具有成本效益的替代方案,超越了检索方法,而无上下文与完美检索之间的性能显著差异证实模型严重依赖外部证据。