Command Palette
Search for a command to run...
KVPO:基于KV语义探索的自回归视频对齐的ODE原生GRPO
KVPO:基于KV语义探索的自回归视频对齐的ODE原生GRPO
Ruicheng Zhang Kaixi Cong Jun Zhou Zhizhou Zhong Zunnan Xu Shuiyang Mao Wei Liu Xiu Li
摘要
将流式自回归(AR)视频生成器与人类偏好对齐是一项具有挑战性的任务。现有的强化学习方法主要依赖于基于噪声的探索以及基于随机微分方程(SDE)的代理策略,这些策略与蒸馏后的AR模型确定的常微分方程(ODE)动力学不匹配,并且倾向于扰动低级外观特征,而非对长时程连贯性至关重要的高级语义叙事进展。为了解决这些局限性,我们提出了KVPO,这是一种用于对齐流式视频生成器的、原生支持ODE的在线组相对策略优化(GRPO)框架。在多样性探索方面,KVPO引入了一种因果语义探索范式,将变化的来源从随机噪声转移到历史KV缓存。通过对历史KV条目进行随机路由,它构建了在数据流形上保持严格一致的语义多样化生成分支。在策略建模方面,KVPO引入了一种基于轨迹速度能量(TVE)的速度场代理策略,该策略在流匹配速度空间中量化分支似然,并产生一个与原生ODE公式完全一致的奖励加权对比目标。在多个蒸馏AR视频生成器上的实验表明,在单提示短视频和多提示长视频设置中,视觉质量、运动质量和文本-视频对齐方面均取得了持续的提升。
一句话总结
本文提出KVPO,一种原生ODE在线组相对策略优化框架,该方法通过将基于噪声的探索替换为历史KV缓存条目的因果语义路由,以及基于轨迹速度能量(Trajectory Velocity Energy)的速度场代理策略,对流式自回归视频生成器进行对齐。在单提示词短视频和多提示词长视频设置下,该方法均在视觉质量、运动质量和文本-视频对齐方面实现了稳定提升。
核心贡献
- 本文提出KVPO,一种原生ODE在线组相对策略优化框架,通过在流匹配速度场空间内直接进行偏好优化,实现对流式自回归视频生成器的对齐。
- 该方法以因果语义探索机制取代随机噪声扰动,通过随机路由历史键值缓存条目构建语义多样的生成分支,同时严格保持流形内轨迹的一致性。
- 基于轨迹速度能量的速度场代理策略生成奖励加权对比目标,将偏好优化嵌入原生ODE动力学中。在蒸馏自回归视频生成器上的实证评估表明,该方法在单提示词短视频和多提示词长视频设置下,均在视觉质量、运动保真度和文本-视频对齐方面实现了稳定提升。
引言
实时交互式视频生成需要低延迟的流式合成,同时保持长程连贯性与语义演进,但将蒸馏自回归视频模型与人类偏好对齐仍面临巨大挑战。现有对齐方法存在局限:奖励加权蒸馏缺乏主动探索能力,而随机噪声注入会破坏原生确定性流场,扰动底层外观特征,并使生成结果偏离数据流形。即便是近期基于几何距离的方法,也因假设不切实际的潜在空间而无法捕捉内在的偏好结构。为突破这些限制,本文提出KVPO,一种原生ODE在线策略优化框架,该框架用结构化路由取代无序噪声,通过对历史键值缓存条目进行策略性路由,直接在流匹配速度场空间内运行,实现因果语义探索,并利用轨迹速度能量构建代理策略,从而在维持流形连贯性与叙事多样性的同时,将偏好对齐有效嵌入模型的原生动力学中。
方法
本文提出KVPO,一种专为对齐流式自回归视频生成器与人类偏好而设计的原生ODE在线组相对策略优化框架。整体架构包含三个主要阶段:因果语义探索、速度场代理策略建模与策略优化,具体流程如框架图所示。
框架首先进行因果语义探索,该过程通过因果历史路由(Causal History Routing, CHR)机制实现。该方法将多样性探索的重心从随机噪声转移至历史键值(KV)缓存,并专门针对可控窗口内的局部缓存进行操作。局部缓存采用固定的9槽位布局:最后三个槽位存储最新帧,前六个槽位则从较旧的历史帧中随机填充。针对每个生成分支,从历史较旧帧中采样一组索引以填充这六个槽位,从而生成语义多样的生成轨迹。存储最早帧的起始KV缓存保持不变,以维持长程连贯性。该过程从共享的初始噪声生成多个候选分支,使模型能够在不破坏底层数据流形的前提下探索不同的叙事路径。

如图下方所示,这种因果语义探索能够产生高度保持高层结构一致性的多样化分支。相比之下,噪声空间探索往往导致偏离流形的畸变与底层结构失效。
探索阶段结束后,框架进入用于策略建模的重放阶段。探索窗口内扰动块的中间隐状态将在原始未扰动的部署时上下文中进行重放。这使得模型能够评估自身对每个候选分支的生成倾向。代理策略的核心是轨迹速度能量(TVE),其定义为缓存 rollout 速度目标与重放期间模型预测速度之间的聚合平方残差。该能量指标量化了当前策略在未扰动上下文下生成特定分支的可能性。
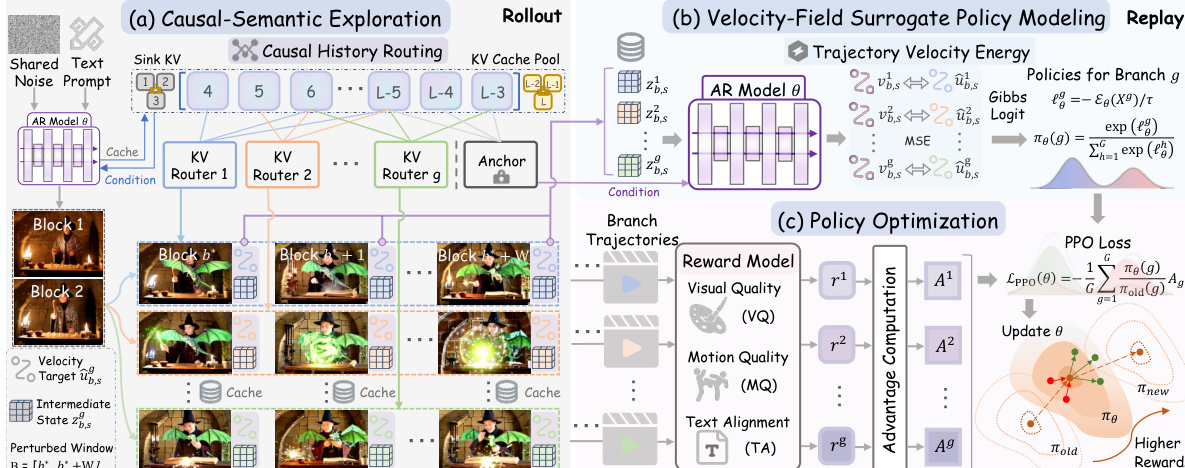
随后,TVE值通过Gibbs参数化转换为归一化的分支分布,形成代理策略。分支的策略概率与其TVE值成反比,确保能量较低(即在当前策略下可能性更高)的分支获得更高概率。该策略具备可微性,且仅依赖于相对能量评分,因此适用于基于梯度的优化。
最后阶段为策略优化,框架利用计算出的代理策略更新自回归模型。框架为每个分支及锚点轨迹计算奖励,随后计算每个分支的归一化优势值。接着优化PPO目标,其中重要性比率源自代理策略概率。为防止策略过度偏离预训练分布,框架引入了KL散度惩罚项。总训练目标由PPO损失与该KL正则化项组合而成。

实验
KVPO在最新的自回归视频生成器上进行了评估,涵盖单提示词短视频与多提示词长视频生成任务,性能与成熟的训练后基线方法进行了基准对比。综合评估表明,该方法在保持复杂提示词转换期间主体身份一致性的同时,持续提升了语义连贯性、视觉保真度与跨片段一致性。人类偏好研究进一步验证了这一发现,并将性能提升归因于因果语义探索与速度场代理策略。消融分析证实,精确调整因果历史路由与基于速度场的优化对训练稳定性至关重要,确立了KVPO作为对齐视频生成器与复杂叙事偏好的稳健框架的地位。
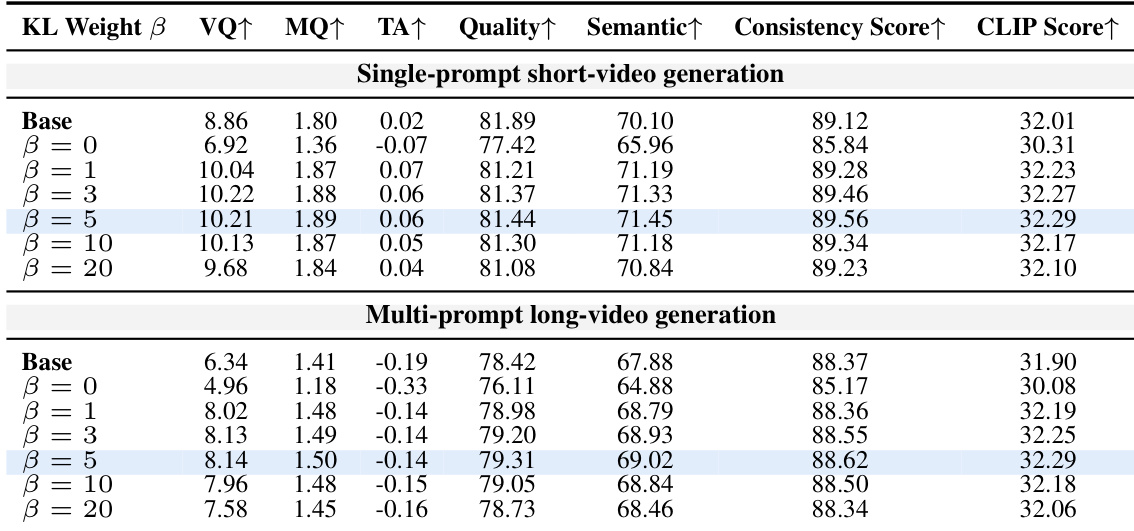
本文在自回归视频生成模型上评估了KVPO,对比了单提示词短视频与多提示词长视频设置下的性能。结果表明,使用KVPO时各项指标均实现稳定提升,最优配置在特定超参数设置下取得,尤其在长视频生成任务中表现突出。KVPO在短视频与长视频生成任务的所有评估指标上均实现性能提升。最优性能在特定超参数设置下取得,较高数值则带来收益递减或性能下降。KVPO在基线方法上展现出持续优势,尤其在长视频生成中,表明其更能处理复杂的多提示词场景。
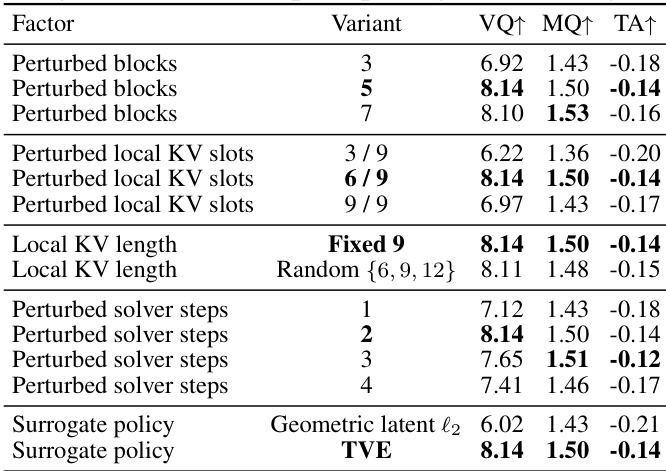
本文对KVPO的核心组件进行了消融研究,重点关注因果历史路由机制与代理策略设计中不同超参数的影响。结果表明,特定配置(如扰动特定数量的块与求解器步数)能在多项指标上实现最优性能,而替代策略设计则显著降低结果。研究证实,扰动策略与策略类型的选择对维持性能与稳定性至关重要。扰动特定数量的块与局部KV槽位能在性能与内存效率间取得最佳平衡。固定局部KV长度并扰动前两个求解器步数可获得最优性能。基于速度场的代理策略优于几何潜在空间策略,凸显了与模型内在动力学对齐的重要性。
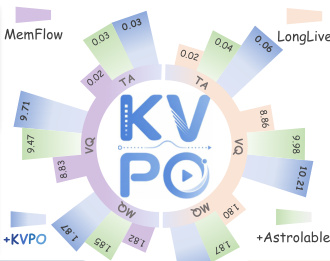
本文在LongLive与MemFlow两款自回归视频生成器上评估了KVPO,并在单提示词短视频与多提示词长视频生成设置下将其与Astrolabe进行对比。结果表明,各项指标均实现稳定提升,KVPO在两种设置下均优于基线方法,并获得更高的人类偏好评分。该方法展现出增强的语义连贯性、运动连续性与提示词贴合度,这归功于因果语义探索与速度场代理策略。KVPO在短视频与长视频生成设置的所有评估指标上均稳定超越基线。KVPO在两种设置下均优于Astrolabe,且性能差距在多提示词长视频生成中进一步扩大。消融研究证实了因果历史路由与速度场代理策略对实现最优性能的重要性。
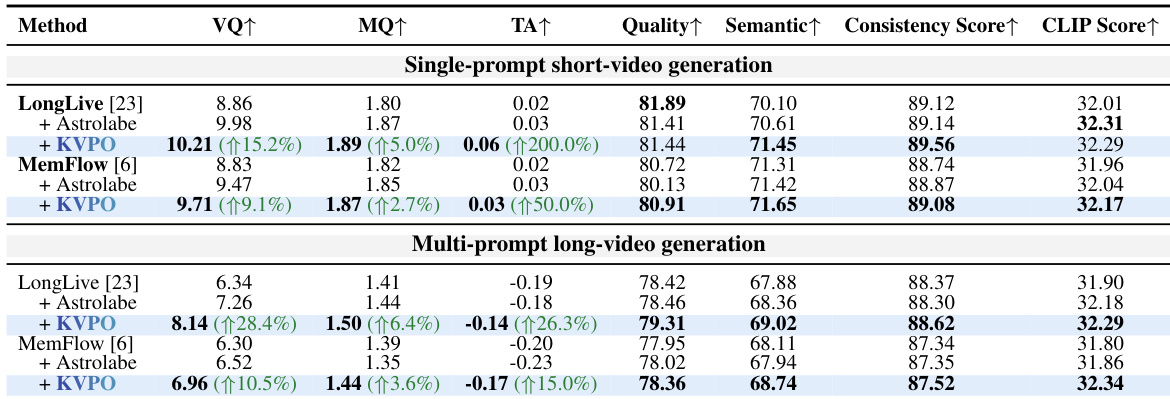
本文在单提示词短视频与多提示词长视频设置下,对自回归视频生成模型评估了KVPO,主要实验验证了其在提升语义连贯性、运动连续性与提示词贴合度方面相较于标准基线的整体能力。随后开展的专项消融研究验证了该方法的核心架构选择,证实了定向因果历史路由与速度场代理策略对于平衡生成质量与内存效率的必要性。综合结果表明,KVPO能够可靠地提升视频合成效果,且其性能优势在复杂的多提示词长视频场景中愈发显著。