Command Palette
Search for a command to run...
以智能体系统增强弱推理模型
以智能体系统增强弱推理模型
Varun Sunkaraneni Pierfrancesco Beneventano Riccardo Neumarker Tomer Galanti
摘要
弱推理模型调用的委员会能否达到更强模型的性能水平?本研究探讨了基于验证器的委员会搜索作为推理语言模型推理时(inference-time)性能增强的机制。该机制并非简单的“多智能体相助”:采样能够揭示潜在的正确答案,而评判器(critics)与比较器(comparators)则必须在无法访问隐藏验证器(hidden verifier)的情况下还原这些答案。我们通过区分提案覆盖率(proposal coverage)、局部可识别性(local identifiability)、进展(progress)和多样性(diversity)来形式化这一观点。我们证明,覆盖率可以通过重复采样得到放大,但仅靠自身无法生成有效的评判器或比较器;可靠的放大效果需要额外的局部一致性信号(local soundness signal),例如代码执行、证明检查、类型检查、测试或约束求解。我们给出了基于排名的界限,说明了何时局部选择误差能够累积为可靠的路径,并刻画了提案方(proposer-side)的性能上限:在理想情况下,最佳 k 选策略(oracle best-of-k)仅收敛于提案系统赋予非零有效概率的任务切片的质量总和。在 SWE-bench Verified 基准上的实验表明,单个 GPT-5.4 nano 提案模型即可解决 67.0% 的任务。使用相同的 nano 模型,我们的评判器-比较器编排策略在 k=8 个提案的情况下达到了 76.4% 的性能,与 Gemini 3 Pro 和 Claude Opus 4.5 Thinking 的独立运行性能相当,并接近 79.0% 的理想最佳 k 选(oracle best-of-8)理论上限。
一句话总结
作者提出了 verifier-backed committee search 作为弱推理模型的 inference-time boosting 机制,证明可靠的放大需要超出采样覆盖率的局部 soundness 信号,并展示了通过编排带有 GPT-5.4 nano 提案的 critic-comparator 系统,在 SWE-bench Verified 上以 k=8 提案实现了 76.4% 的准确率,与 Gemini 3 Pro 和 Claude Opus 4.5 Thinking 的独立性能相当。
核心贡献
- 这项工作通过分离提案覆盖率、局部可识别性、进展和多样性,形式化了 verifier-backed committee search,为 multi-agent 系统创建了诊断视角。理论分析证明覆盖率放大需要局部 soundness 信号,并提供了选择误差如何组合成可靠轨迹的基于秩的界限。
- 该方法采用 verifier-backed committee search 作为推理时增强,其中 critics 和 comparators 从样本中恢复潜在的正确答案,无需访问隐藏的 verifier。这种编排使弱推理模型能够通过重复采样和局部选择达到更强模型的性能。
- 在 SWE-bench Verified 上的实证评估表明,使用单个 GPT-5.4 nano 模型的 critic-comparator 编排在八个提案下达到了 76.4% 的任务解决率。该性能与 Gemini 3 Pro 和 Claude Opus 4.5 Thinking 的独立结果相匹配,同时接近 79.0% 的 oracle best-of-8 上限。
引言
verifier-backed 推理任务(如代码修复和定理证明)要求系统生成中间步骤并验证它们,而无法访问隐藏的 ground truth 标签。现有的推理时方法通常依赖重复采样或投票,但当模型共享盲点或缺乏区分正确部分解决方案与有缺陷方案的能力时,这些策略会陷入困境。作者将 agent 系统形式化为推理时增强,通过分离提案覆盖率和局部可识别性,并证明可靠的放大需要额外的 soundness 信号,如执行或类型检查。他们的理论界限刻画了共享盲点所施加的限制,而 SWE-bench Verified 上的实证结果表明,编排弱模型可以达到显著更强的独立系统的性能。
方法
作者将 verifier-backed agent 系统建模为部分对象上的有界深度搜索过程,例如中间证明状态或部分编写的程序。他们定义了一个有效状态系统,其中状态代表部分推理对象,秩函数 dx(s) 衡量“距离解的距离”。目标是从初始状态 s0(x) 转换到 verifier 接受解决方案的终端状态。此过程依赖于进展性 soundness 动作的存在,这些动作保持有效性并严格降低秩函数。
核心架构是 Committee Protocol Πk,m,r,它将生成与识别分离。在每个可达的非终端状态 s,协议执行一个三阶段循环来选择下一个动作。首先,proposer harness 采样 k 个候选动作。其次,对每个候选应用 m 次独立的 critic 调用来过滤局部可反驳的错误。第三,在幸存的候选者中,使用每对 r 个 comparator 投票选择 Copeland 获胜者。选定的动作将系统转换到下一个状态 st+1。该过程重复进行有限步数 L。
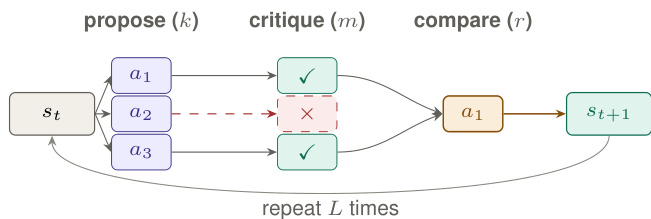
该架构的理论保证取决于两种不同的资源:提案覆盖率和局部可识别性。假设 1 提出存在一个 proposer 组合,使得进展性 soundness 动作可以以非零概率 α0 被采样。假设 2 确保高效的局部可识别性,意味着 critics 可以以至少 β0 的概率拒绝 unsound 动作,comparators 可以以至少 1/2+σ0 的概率偏好 sound 动作而非 unsound 动作。
作者推导了选择 unsound 动作或局部失败概率的局部误差分解。该误差 εloc(s) 受提案失败和识别失败之和的界限约束。具体而言,识别误差随 critic 调用次数 m 和 comparator 投票次数 r 呈指数下降,由 β 和 σ 支配。长度为 Lx 的轨迹上的全局失败概率受每一步局部误差之和的界限约束。
对提案项的进一步分析揭示了“盲点下限”。随着 k→∞,提案失败的概率收敛于值 Bs,代表提案系统对 sound 动作分配零概率的潜在子群体。增加 k 可以减少有限采样残差,但无法消除盲点下限。为了实现可靠的放大,系统需要多样化的 proposer 组合来覆盖搜索空间,以及 sound 验证信号来识别有效动作。在实验实例中,critic 被实现为二元补丁判断器,comparator 对代码补丁进行成对评估,以确定哪个更有可能解决问题而不破坏现有功能。
实验
实验在 SWE-bench Verified 上评估了推理时编排,使用固定的候选补丁池将选择质量与生成能力隔离开来。结果表明,虽然提案多样性暴露了潜在的正确答案,但需要结合 critics 和 comparators 的 harness 来恢复大部分潜力,其中 critics 过滤有缺陷的补丁,comparators 对合理的补丁进行排名。失败分解显示,剩余错误主要源于提案覆盖率限制而非选择失败,表明未来的收益需要更多样化的 proposers 以及稳健的选择机制。
作者评估了选择器消融,以确定聚合规则和 critic 阈值对解决率的影响。结果显示,所有成对聚合方法(如 Copeland 循环赛和严格优势)优于单淘汰赛制。此外,引入宽松的 critic 门控比单独使用 comparators 显著提高了性能,最佳结果出现在较低阈值处,随后性能随更严格的过滤而下降。所有成对聚合方法产生的结果优于单淘汰赛制。过滤掉零 critic 支持的补丁比不使用门控提高了性能。超过最佳水平的更严格 critic 阈值导致性能略有下降。
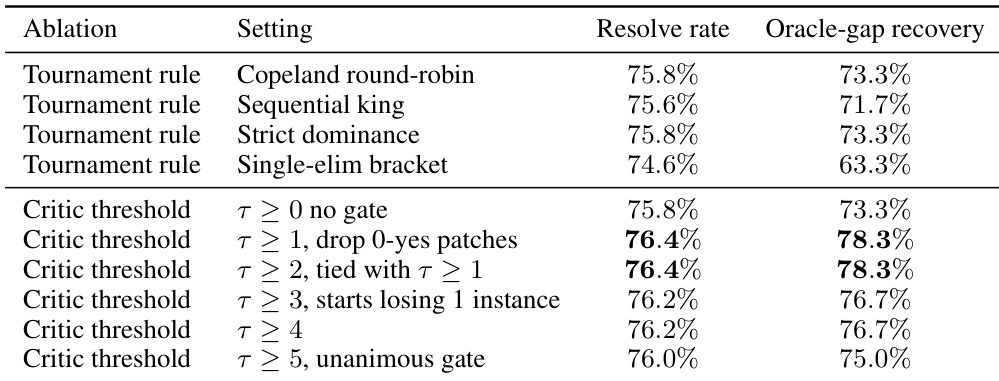
作者评估了选择器消融,以确定聚合规则和 critic 阈值对解决率的影响。结果显示,所有成对聚合方法(如 Copeland 循环赛和严格优势)优于单淘汰赛制。此外,引入宽松的 critic 门控比单独使用 comparators 显著提高了性能,最佳结果出现在较低阈值处,随后性能随更严格的过滤而下降。