Command Palette
Search for a command to run...
学习与快慢思维:迈向具备持续适应能力的 LLM
学习与快慢思维:迈向具备持续适应能力的 LLM
Rishabh Tiwari Kusha Sareen Lakshya A Agrawal Joseph E. Gonzalez Matei Zaharia Kurt Keutzer Inderjit S Dhillon Rishabh Agarwal Devvrit Khatri
摘要
大语言模型(LLMs)通常通过更新其参数(例如通过强化学习 RL)来针对下游任务进行训练。然而,参数更新迫使模型吸收特定于任务的信息,这可能导致灾难性遗忘(catastrophic forgetting)以及可塑性(plasticity)的丧失。相比之下,在保持 LLM 参数固定的情况下,通过上下文学习(in-context learning)可以低成本且快速地适应特定任务需求(例如提示优化 prompt optimization),但其自身通常无法达到通过更新 LLM 参数所能获得的性能提升。没有理由将学习局限于上下文学习或权重更新(in-weights)。此外,人类的学习过程很可能发生在不同的时间尺度上(例如系统 1 与系统 2 的区别)。为此,我们提出了一种面向 LLM 的快慢学习框架(fast-slow learning framework),将模型参数视为“慢”权重(slow weights),将优化的上下文视为“快”权重(fast weights)。这些“快”权重能够从文本反馈中学习以吸收特定于任务的信息,同时允许“慢”权重更接近基础模型,从而保留通用的推理行为。在推理任务中,快慢训练(Fast-Slow Training, FST)相比仅使用慢学习(RL)在样本效率上提升了高达 3 倍,并且能够始终达到更高的性能渐近线。此外,经过 FST 训练的模型更接近基础 LLM(KL 散度降低了多达 70%),因此相比 RL 训练,其灾难性遗忘现象更少。这种减少了的漂移(drift)也保留了好塑性:在单一任务上训练后,FST 训练出的模型比仅通过参数训练的模型更有效地适应后续任务。在任务领域动态变化的持续学习(continual learning)场景中,FST 能够持续习得每个新任务,而仅基于参数的 RL 则会停滞不前。
一句话总结
作者提出了快速 - 慢速训练 (Fast-Slow Training),这是一个将优化后的上下文视为快速权重、将模型参数视为慢速权重的框架,用于大型语言模型的持续适应。该方法在强化学习的基础上实现了高达 3 倍的样本效率提升,同时通过保持与基础模型高达 70% 更低的 KL 散度,减少了灾难性遗忘,并在不断变化的任务领域中保持了可塑性。
核心贡献
- 为大型语言模型引入了一种快速 - 慢速学习框架,将模型参数视为慢速权重,将优化后的上下文视为快速权重。这种结构允许快速权重从文本反馈中吸收特定于任务的信息,同时保持慢速权重更接近基础模型。
- 快速 - 慢速训练 (FST) 在推理任务中,通过强化学习实现的样本效率比慢速学习高出 3 倍。与仅参数更新相比,该方法始终能达到更高的性能渐近线。
- FST 训练的模型与基础大型语言模型保持更近的距离,其 KL 散度比强化学习训练低高达 70%。这种减少的漂移保留了可塑性,使得在参数仅 RL 停滞的持续学习场景中,能够更有效地适应后续任务。
引言
大型语言模型通常通过强化学习等方法更新其参数来适应下游任务。然而,将所有特定于任务的信息强制纳入持久权重往往会导致灾难性遗忘,并丧失未来学习的可塑性。虽然固定参数的上下文学习提供了灵活性,但它通常无法匹配通过权重更新实现的性能提升。为了解决这些限制,作者引入了快速 - 慢速训练 (FST),这是一个将模型参数视为慢速权重、优化后的上下文视为快速权重的框架。这种方法允许系统共同演化这两个组件,使得特定于任务的信号被吸收进提示词中,而基础模型保持稳定。因此,FST 实现了更高的样本效率和性能,同时显著减少了与基础策略的漂移,并保留了适应新任务的能力。
数据集
-
数据集构成与来源
- 作者采用了 Prakash 和 Buvanesh 提出的星图搜索规划任务。
- 他们程序化地生成了训练集和测试集,而不是使用静态集合。
-
子集细节与构建
- 每个图实例由一个三元组 (d,p,n) 定义,分别代表源度、路径长度和节点池大小。
- 一条独特的黄金路径使用从池中采样的中间节点连接源节点和目标节点。
- 为了增加难度,未使用的节点被连接到源节点以形成诱饵分支,使它们不与黄金路径相交。
- 完整的边集被均匀随机打乱,并序列化为以逗号分隔的对的扁平空格分隔列表。
-
训练与评估划分
- 主要实验使用的参数设置为 (d,p,n)=(25,20,500)。
- 训练集包含 10,000 个示例,而测试集包含 200 个保留示例。
- 输入遵循逐字提示模板,要求逐步推理并在花括号内提供最终答案。
-
处理与评分
- 系统提示指示模型在确定分支之前检查源节点的邻居。
- 奖励函数从最后一个框部分提取内容,以针对黄金路径字符串进行精确匹配比较。
- 评分是二元的,精确匹配奖励为 1.0,任何偏差奖励为 0.0。
方法
作者提出了一种称为快速 - 慢速训练 (FST) 的双循环优化框架,同时优化模型参数和用于条件化模型的文本上下文。系统区分了慢速权重,记为 θ,代表可训练神经网络参数;以及快速权重,记为 ϕ,代表从离散文本空间 Σ∗ 中提取的文本支架或提示。整体架构及这些组件之间的交互如下图所示:
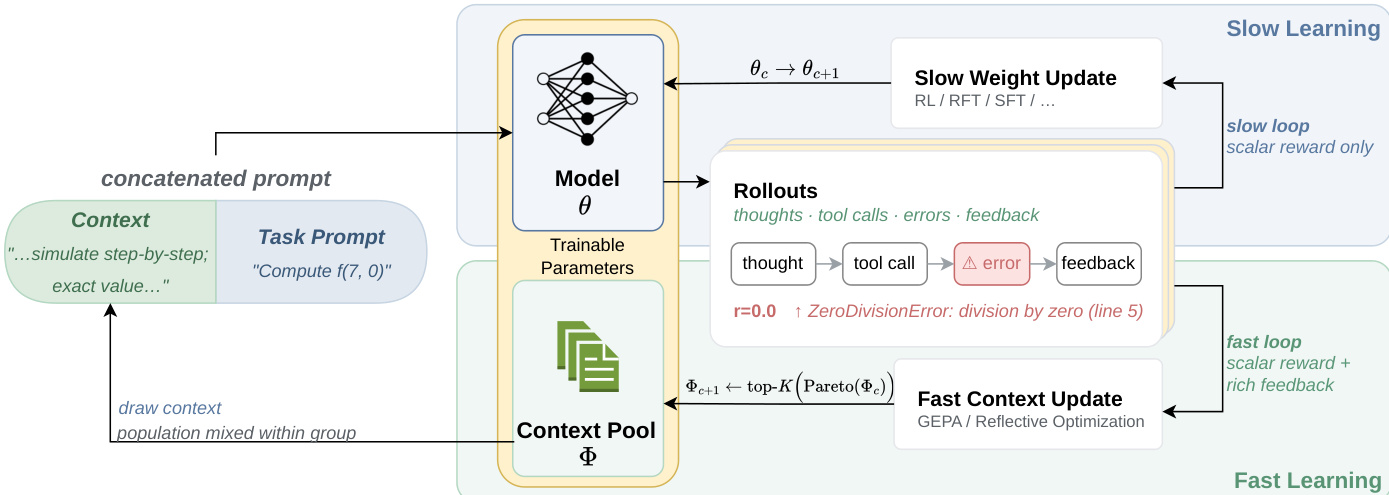
训练过程始于构建一个连接提示,该提示将选自上下文池 Φ 的动态上下文 ϕ 与静态任务提示相结合。此组合输入被送入模型 θ,该模型基于查询 x 和上下文 ϕ 生成响应 y。在生成阶段,模型产生可能包含中间想法、工具调用和错误信号的展开,最终产生响应和相关的反馈。
该框架通过两个不同的学习循环运行。慢速学习循环专注于更新模型参数 θ。此过程利用带有可验证奖励的强化学习 (RLVR)。对于每个查询,策略生成一组展开,并基于自动验证器提供的标量奖励计算组相对优势(例如,检查代码执行成功或数学正确性)。然后使用截断重要性采样 REINFORCE 目标,即 CISPO 损失,来更新模型参数,以最大化预期奖励同时保持稳定性。该循环更新权重 θc→θc+1,主要依赖标量奖励信号。
同时,快速学习循环使用反思进化提示优化,具体为 GEPA 算法,优化上下文池 Φ。该循环将文本提示视为可以快速适应的快速权重。GEPA 通过维护互补候选者的帕累托前沿来演化提示种群 Φ,而不是更新参数。它利用当前策略生成的展开,从冻结的反思语言模型中获取自然语言批评。这些批评指导文本变异的提出,以提高锚定任务集上的性能。此过程允许系统捕获特定于任务的改进和快速演变的行为,而无需重新训练神经网络权重的计算成本。
快速 - 慢速训练方法在循环中交错进行这两个过程。在每个循环开始时,系统预取一批前瞻数据并运行 GEPA,以基于当前策略 πθ 更新提示种群 Φ。对于循环中的后续步骤,模型参数 θ 通过使用新优化的提示种群的 RL 进行更新,而提示保持不变。这种分工允许快速权重处理快速适应和特定于任务的条件化,而慢速权重巩固持久的行为模式,从而提高数据效率和性能。
实验
实验使用 Qwen3-8B 基础模型,在代码、数学和事实验证任务上评估了快速 - 慢速训练与标准强化学习的表现。结果表明,FST 通过利用文本快速权重比仅参数更新更快地捕获任务信号,实现了更高的性能上限和更高的数据效率。此外,该方法保持与基础模型更接近的邻近性,以保留后续任务的可塑性,而消融研究证实,共同优化快速文本通道和慢速参数对于最大化性能是必要的。
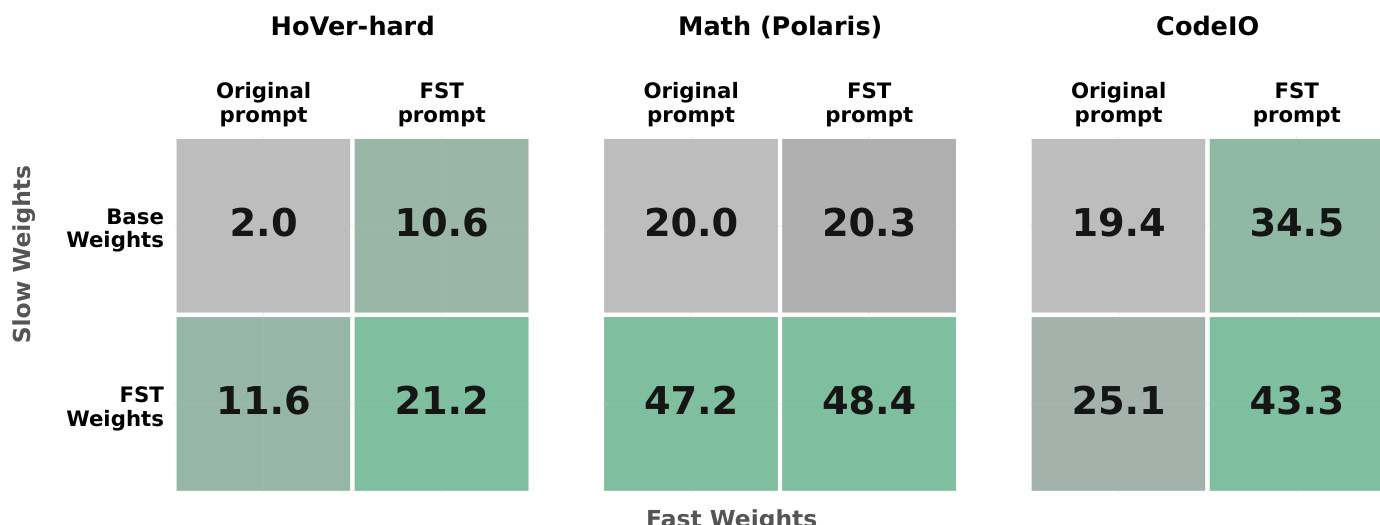
作者将性能提升分解为慢速权重(参数)和快速权重(提示)的贡献,以分析快速 - 慢速训练中的分工。结果表明,虽然慢速权重推动了数学任务的大部分增益,但两个通道对 HoVer-hard 和 CodeIO 的性能都有显著贡献。优化后的权重和优化后的提示的组合始终在所有领域达到最高的性能渐近线。将 FST 训练的权重与 FST 演变的提示结合,始终在所有任务中产生最高的性能。HoVer-hard 和 CodeIO 从慢速权重和快速提示通道中显著受益,当结合时效果叠加。在数学任务上,性能改进主要由慢速权重的更新驱动,快速提示通道提供的额外收益最小。
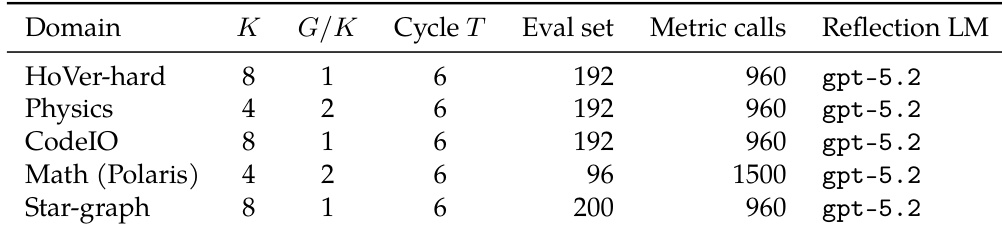
该表格详细说明了五个不同推理领域的快速 - 慢速训练实验的超参数配置。虽然循环长度和反思语言模型在所有设置中保持一致,但种群大小和评估预算针对每个任务的具体需求进行了调整。这种标准化且可适应的设置使作者能够证明,与标准强化学习基线相比,他们的方法实现了更高的性能上限和更好的数据效率。所有领域均使用统一的循环长度和反思模型,以保持一致的训练动态。评估预算和种群大小因领域而异,数学任务利用更高的指标调用限制。该配置支持多样化的推理任务,范围从代码生成到多跳事实验证。
该表格详细说明了五个推理领域的超参数配置,表明大多数任务采用标准设置,而数学和星图实验有特定偏差。虽然大多数领域在思考模式下使用 Qwen3-8B 模型并采用统一的批量设置,但数学任务采用具有增加批量容量的专用基础模型。相反,星图任务利用较小的模型变体而不具备思考能力,但所有配置均保持稳定的 GPU 利用率。三个领域共享相同的基础模型和批量配置,以确保一致的比较。数学任务需要专用的 SFT 基础模型和更大的批量大小来处理任务饱和。星图实验使用较小的模型大小并禁用思考模式,使其与主要的 8B 设置区分开来。

评估涵盖五个推理领域,具有定制的超参数和模型配置,主要利用 Qwen3-8B,并对数学和星图任务进行特定调整以确保一致比较。实验分解性能增益以分析慢速权重和快速提示之间的分工,揭示结合优化后的权重和提示始终在所有任务中达到最高的性能渐近线。虽然慢速权重主要推动数学任务的改进,但两个通道对 HoVer-hard 和 CodeIO 都有显著贡献,表明该方法实现了比标准强化学习基线更高的性能上限和更好的数据效率。