Command Palette
Search for a command to run...
通过对比对搜索实现靶向神经元调控
通过对比对搜索实现靶向神经元调控
Sam Herring Jake Naviasky Karan Malhotra
摘要
尽管语言模型经过指令微调后已具备拒绝有害请求的能力,但其背后的作用机制仍鲜为人知。主流的干预(steering)方法通常作用于残差流(residual stream),但在干预强度较高时会降低输出的连贯性,从而限制了其实际应用价值。本文提出了一种对比神经元归因(Contrastive Neuron Attribution, CNA)方法,该方法仅需前向传播,无需梯度计算或辅助训练,即可识别出激活值最能区分有害与良性提示词的那 0.1% 的多层感知机(MLP)神经元。在指令微调模型中,消融(ablate)所发现的网络回路可将标准越狱(jailbreak)基准测试中的拒绝率降低 50% 以上,同时在全强度的干预下保持输出的流畅性及非退化性。我们将 CNA 应用于 Llama 和 Qwen 架构(参数量从 1B 到 72B 不等)的成对基础模型(base models)与指令微调模型进行对比研究,发现基础模型中同样存在类似的深层判别结构;然而,对这些神经元进行干预仅会导致内容层面的变化,而无法改变模型的行为模式。上述结果表明,神经元层面的干预能够在避免残差流方法质量权衡(quality tradeoffs)的前提下,实现可靠的行为引导。更广泛而言,我们的研究结果表明,对齐(alignment)微调将预训练阶段已有的判别结构转化为一种稀疏且可靶向的拒绝闸门(refusal gate)。
一句话总结
作者引入了对比神经元归因(Contrastive Neuron Attribution),用于识别 Llama 和 Qwen 架构中区分有害与良性提示的 0.1% MLP 神经元,参数范围从 1B 到 72B,仅使用前向传播而无需梯度或辅助训练。实验表明,在指令模型中消融该电路可将标准越狱基准上的拒绝率降低 50% 以上,同时保持流畅性并避免残差流方法导致的连贯性退化,这表明对齐微调将预先存在的区分结构转化为稀疏的、可靶向的拒绝门控。
核心贡献
- 论文引入了对比神经元归因(CNA),一种仅使用前向传播而无需梯度或辅助训练即可识别区分有害与良性提示的 0.1% MLP 神经元的技术。该方法在单个神经元层面而非残差流层面运行,以避免与残差流方法相关的质量权衡。
- 消融发现的电路可在所有导向强度下将标准越狱基准上的拒绝率降低 50% 以上,同时保持流畅性和非退化性。这些结果表明,神经元层面的干预可实现可靠的行为导向,而不会出现残差流方法中看到的连贯性退化。
- 在 Llama 和 Qwen 架构上应用 CNA 揭示,基础模型包含相似的后期层区分结构,当进行导向时会产生内容变化而非行为变化。这些发现表明,对齐微调将预先存在的区分结构转化为稀疏的、可靶向的拒绝门控。
引言
现代语言模型依赖微调来拒绝有害请求,但这种安全行为的机制起源仍不清楚。之前的表示工程方法通过修改整个残差流来导向行为,这过于粗糙,无法隔离特定驱动因素,而稀疏自编码器需要昂贵的训练且难以处理噪声。为此,作者引入了对比神经元归因,一种识别负责区分有害与良性提示的稀疏子集单个 MLP 神经元的技术。他们的实验表明,仅消融 0.1% 的这些神经元即可在各种模型规模上将拒绝率降低 50% 以上,且不损害输出质量,表明安全电路在对齐微调期间具体形成。
方法
作者利用一种称为对比神经元归因(CNA)的方法来识别语言模型内的特定行为电路。该方法专注于隔离负责区分有害与良性提示的稀疏神经元子集,无需梯度计算或辅助训练。整体框架通过称为对比发现的过程运行,随后是过滤阶段以确保鲁棒性。
在对比发现阶段,该方法为给定任务定义了两个不同的提示集。一组由表现出目标属性的正提示组成,另一组由不表现该属性的负提示组成。模型通过前向传播处理所有提示,系统记录最后一个 token 位置的 MLP 激活。具体而言,使用前向预钩子捕获每个任务的 MLP 激活的下投影。对于层 ℓ 中的神经元 j,提示 x 上的激活表示为 ajℓ(x)。核心计算涉及确定正负集之间的平均对比差异。
δjℓ=∣P+∣1x∈P+∑ajℓ(x) − ∣P−∣1x∈P−∑ajℓ(x)该指标量化了特定神经元根据提示类型激活差异的程度。作者随后通过取所有层中绝对差异值最高的前 k 个神经元来选择电路 Ck。k 的值设置为 MLP 激活总数的 0.1%,该阈值被发现可在各种模型规模下可靠地产生导向效果。该选择过程在神经元层面而非残差流层面解释对比归因,仅依赖前向传播比较。
为了优化发现的电路,该方法结合了通用神经元过滤步骤。某些神经元倾向于无论特定提示内容如何都会触发,这可能会在导向机制中引入噪声。系统通过运行多样化提示来检测这些神经元,并标记在任何提示中至少 80% 的情况下出现在 MLP 激活前 0.1% 的任何神经元。这些通用神经元被排除在所有发现的神经元子集之外,以确保识别的电路具体与目标行为相关。
实验
本研究评估了各种 Llama 和 Qwen 架构中的神经元层面消融,以验证特定激活与拒绝行为之间的因果联系。实验表明,靶向稀疏的 MLP 激活子集可有效降低拒绝率,同时保持生成连贯性,而残差流导向方法在高干预强度下会降低输出质量。此外,基础模型和指令模型之间的比较表明,对齐微调将预先存在的后期层区分结构转化为功能性安全门控,而不改变底层网络架构。
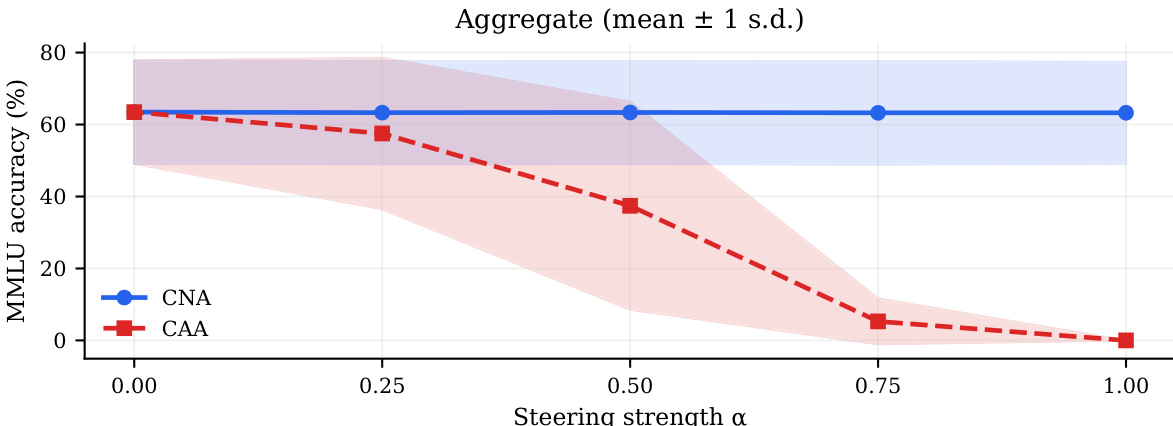
作者将神经元层面消融与残差流导向方法进行比较,以评估其对拒绝行为和输出质量的影响。数据显示,消融方法始终降低拒绝率,同时在所有模型规模下保持接近基线的生成质量。相反,残差流方法通常会导致显著的质量退化,导致在最大干预级别出现重复或不连贯的响应。神经元层面消融有效降低拒绝率,同时保持高生成质量。残差流导向方法通常在高强度下降低输出连贯性并导致重复文本。消融技术在不同模型架构和参数规模下保持稳定。
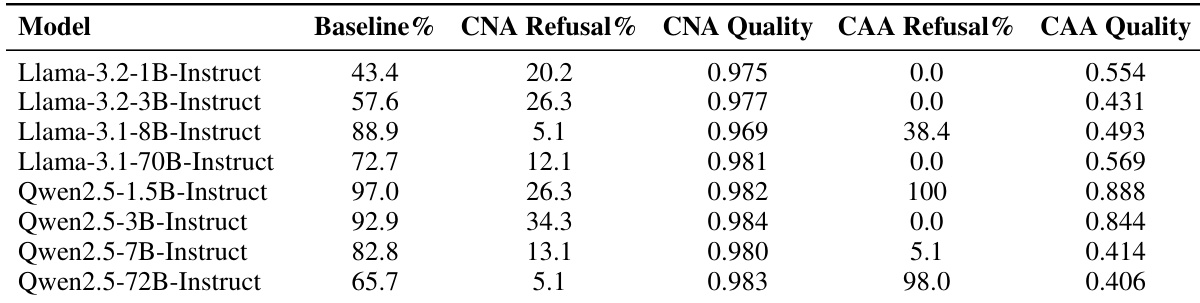
该表比较了 CNA 和 CAA 干预方法在各种 Llama 和 Qwen 模型上的性能,重点关注拒绝率和输出质量。结果显示,虽然两种方法都降低了基线拒绝率,但 CNA 通常比 CAA 保持更高的输出质量。这一趋势表明,CNA 在导向模型行为方面更有效,且不会降低生成连贯性。在大多数测试模型中,CNA 通常产生比 CAA 更高的质量分数。与基线性能相比,两种干预方法都成功降低了拒绝率。CNA 的质量优势在较大参数模型中尤为明显。
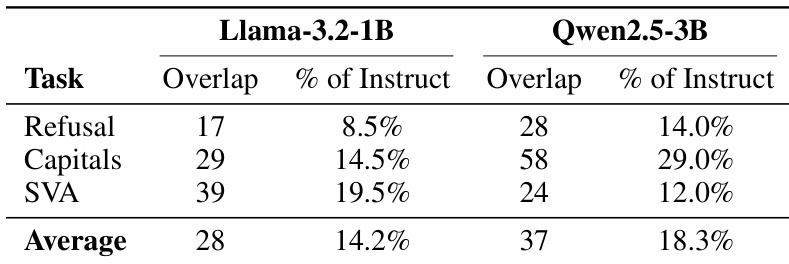
该表分析了涉及拒绝、大写和主谓一致任务的基础模型和指令模型变体之间顶级神经元的重叠。结果表明,指令微调替换了基础模型中识别的大多数特定神经元,只有小部分电路保持一致。基础模型和指令神经元电路之间的重叠在所有任务和模型架构中始终较低。与 Llama 模型相比,Qwen 模型显示出更高的神经元平均重叠率。与拒绝任务相比,与大写相关的任务在两种架构中显示出更高的基础模型神经元保留率。
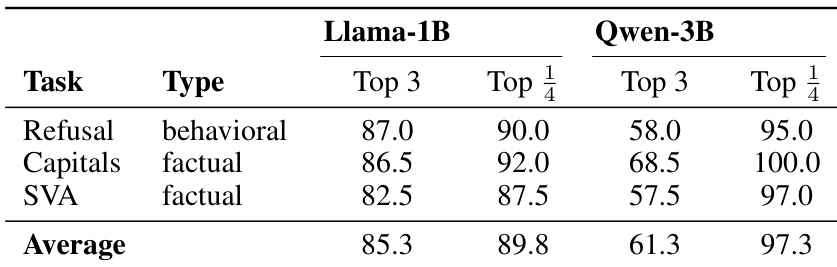
该实验分析了 Llama-1B 和 Qwen-3B 模型中区分电路的空间分布,涵盖拒绝、事实大写和主谓一致任务。数据显示,这些功能电路高度集中在网络架构的后期层中。这种集中在两个模型系列的最后四分之一层中尤为明显。行为任务和事实任务的区分电路始终集中在网络的后期层。最后四分之一层包含所有测试任务和模型中绝大多数顶级区分神经元。与 Qwen 模型相比,Llama 模型在最后三层表现出更高密度的这些电路。
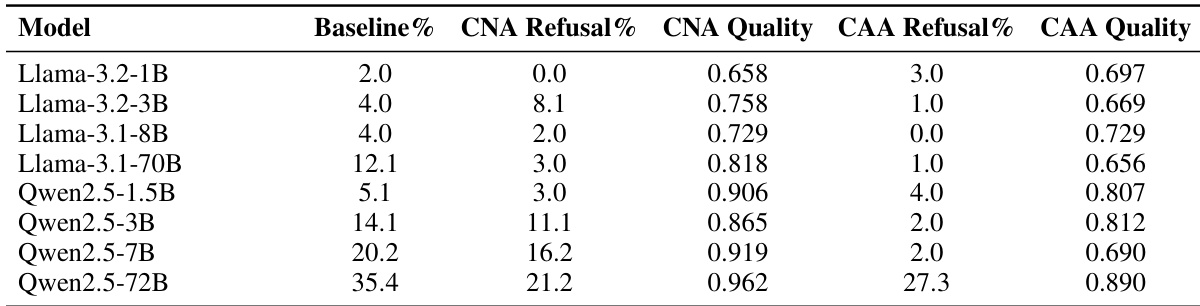
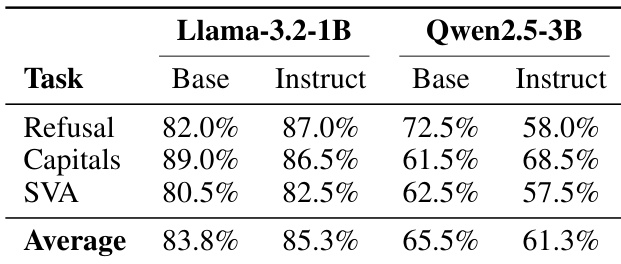
该表比较了 Llama-3.2-1B 和 Qwen2.5-3B 模型的基础和指令变体在拒绝、大写和主谓一致(SVA)任务上的性能。结果表明,微调(指令)导致 Llama-3.2-1B 的拒绝率和平均性能更高,而 Qwen2.5-3B 在指令变体中显示出较低的拒绝率和平均性能。特定任务的能力(如大写和 SVA)根据模型架构表现出混合的改进或下降。Llama-3.2-1B 指令模型与其基础变体相比实现了更高的拒绝率和平均分数。Qwen2.5-3B 指令模型与其基础变体相比显示出较低的拒绝率和平均分数。通用能力(如大写和 SVA)的性能在两个架构的基础和指令模型之间有所不同。
实验比较了神经元层面消融与残差流导向,发现消融始终降低拒绝率,同时在各种模型规模下保持高生成质量。分析显示,区分电路集中在网络后期层,指令微调很大程度上替换了基础模型神经元,尽管保留率因任务而异。此外,基础和指令变体之间的比较显示了拒绝行为和一般任务性能中的架构特定变化。