Command Palette
Search for a command to run...
世界动作模型:具身智能的下一前沿
世界动作模型:具身智能的下一前沿
摘要
视觉-语言-动作(Vision-Language-Action, VLA)模型在具身策略学习中展现出强大的语义泛化能力,但其本质上是学习从观测到动作的反应式映射,并未显式建模在干预下物理世界的演化过程。越来越多的研究致力于通过将世界模型(即对环境动态的预测模型)整合到动作生成管线中,以弥补这一局限。我们将这种新兴范式称为世界动作模型(World Action Models, WAMs):这是一种具身基础模型,它将预测性状态建模与动作生成相统一,旨在预测未来状态与动作的联合分布,而非仅预测动作。然而,现有文献在架构、学习目标和应用场景方面仍较为分散,缺乏统一的概念框架。本文正式定义了 WAMs,厘清了其与相关概念的界限,并梳理了促成这一范式的 VLA 与世界模型研究的起源及早期融合。我们将现有方法组织为结构化的分类体系,将其划分为级联式(Cascaded)与联合式(Joint)WAMs,并进一步依据生成模态、条件机制以及动作解码策略进行细分。
一句话总结
本工作正式定义了 World Action Models,将其定义为具身基础模型,统一了预测状态建模与动作生成,旨在针对未来状态和动作的联合分布,解决了反应式 Vision-Language-Action 框架的局限性,并将现有方法组织为级联和联合 WAMs 的结构化分类。
核心贡献
- 本综述正式定义了 World Action Models,并建立了一个概念框架,将其与具身 AI 中的相关方法区分开来。它追溯了视觉 - 语言 - 动作研究和世界模型集成的基础,以统一预测状态建模与动作生成。
- 现有方法根据生成模式、条件机制和动作解码策略,被组织为级联和联合范式的结构化分类。这种分类将架构设计空间映射到该领域内的术语边界。
- 该综述综合了可扩展训练数据集的努力,并总结了涵盖视觉保真度、物理常识和动作合理性的新兴评估协议。概述了关键的开放挑战和未来轨迹,以指导下一阶段的发展。
引言
Vision-Language-Action 模型目前通过利用语义泛化驱动具身 AI,但它们作为反应式系统运行,直接将观测映射到动作,而不建模物理动力学。这种预测推理的缺失限制了 agent 在跨新颖环境中泛化的能力,其中预测状态变化至关重要。虽然最近的工作集成了世界模型以提供物理预见,但该领域仍然分散在不同的架构和学习目标中。作者通过正式定义 World Action Models 为统一预测状态建模与动作生成的具身基础模型来解决这一差距。他们提出了对该领域的首次系统调查,将方法分类为级联和联合范式,同时综合数据生态系统和评估协议以指导未来研究。
数据集
-
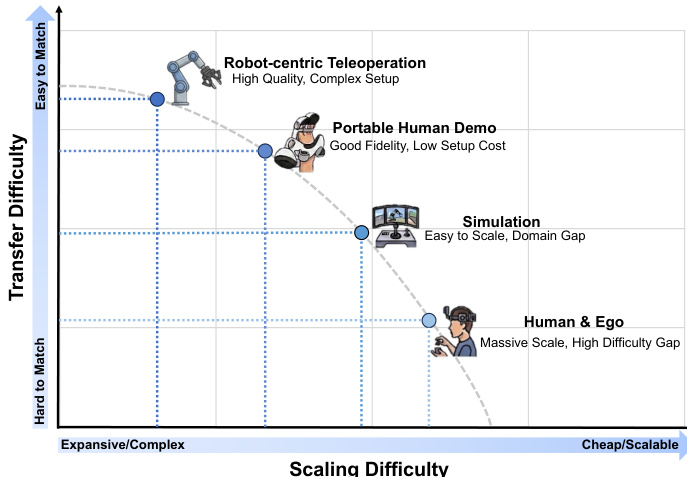
数据集组成和来源 作者将训练景观分类为四个主导范式,以平衡精确的物理定位与广泛的泛化。这些包括高保真以机器人为中心的遥操作、敏捷的便携式人类演示、可扩展的仿真数据,以及广泛的人类和第一人称数据。
-
每个子集的关键细节
- 以机器人为中心的遥操作: 来源包括 Open-X Embodiment 和 DROID。数据由严格对齐的高频动作 - 状态对组成,包含多模态信号,如 RGB、本体感觉、深度、音频和触觉反馈。
- 便携式人类演示: 利用 UMI 风格的硬件,如手持夹爪和可穿戴相机进行野外收集。数据集包括 FastUMI 和 RealOmin,在多样化的环境中提供厘米级的动作约束。
- 仿真数据: 通过 MuJoCo 和 Isaac Sim 等物理引擎生成。示例包括 SynGrasp-1B,拥有数百万条轨迹。该子集提供特权空间监督,如完美的深度和精确的 6D 物体姿态。
- 人类和第一人称数据: 源自互联网规模视频,如 Ego4D 和 HowTo100M。这些提供被动世界动力学或通过 3D 手部姿态和运动跟踪提取的主动动力学。
-
数据使用和训练策略 该框架采用联合训练策略来摄入配对 (ot,at,ot+1) 三元组和无配对无动作序列。这种混合允许模型将内部表示与大规模无约束观测耦合以进行视觉物理。作者指出,这种方法弥合了低级机器人控制与开放世界泛化之间的差距。
-
处理和元数据构建
- 增强: 使用自动和生成增强来扩展数据,超出手动收集的限制。
- 对齐: 人类动作通过基于视觉的跟踪重定向到可执行的机器人动作。
- 空间定位: 仿真数据在纹理和照明上进行域随机化,以减少仿真到现实的差距。
- 姿态估计: 第一人称视频通过姿态估计和 3D 手 - 物体网格对齐进行处理,以弥合被动数据中的动作差距。
方法
World Action Models (WAMs) 代表一类具身基础模型,将环境动力学建模与运动控制统一起来。与学习直接观测到动作映射的标准 Vision-Language-Action (VLA) 模型,或仅预测状态演变的世界模型 (WMs) 不同,WAMs 预测物理环境的未来演变以及运动命令。如下面的图所示,WAM 架构通过联合处理当前观测和语言以输出下一个观测和动作,与 VLA 和 WM 形成对比。
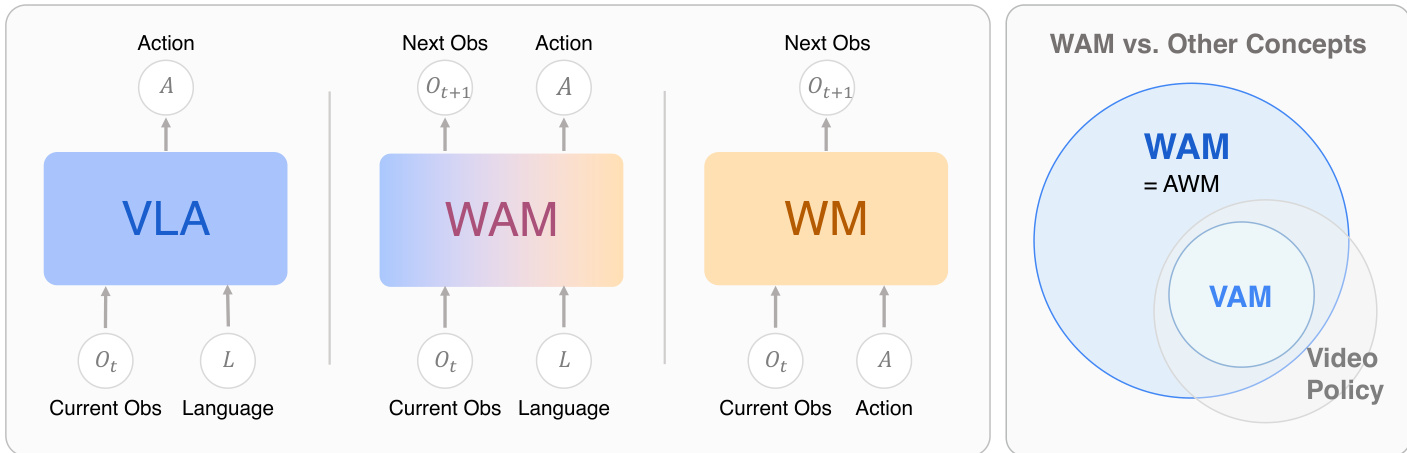
形式上,WAM 寻求在统一框架内表征未来状态和动作的联合分布: LWAM=E(o,l,o′,a)∼D[−logp(o′,a∣o,l)].
文献被系统地分类为核心维度,包括架构和训练数据。参考框架图以获取本综述中审查的世界动作模型的综合分类。
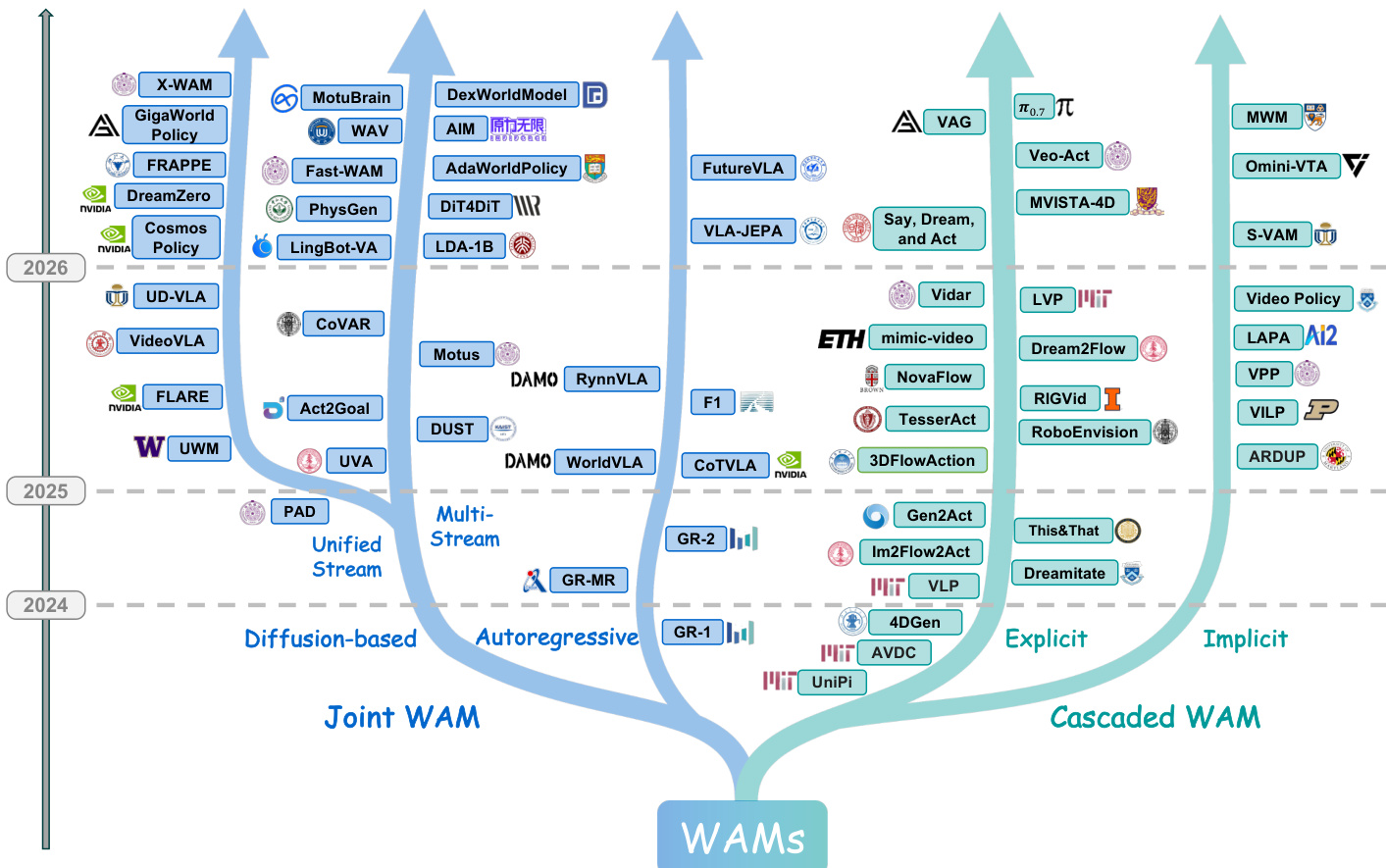
最近的进展已转向将世界建模直接集成到策略架构中。该论文将这些架构分类为两个主要范式:级联 WAMs 和联合 WAMs。
级联世界动作模型通过顺序两阶段管道实现世界动作映射。世界模型首先合成代表预期未来的视觉计划,然后单独的动作模型从该计划解码可执行的机器人命令。这种分解提供了一种自然的归纳偏置,其中世界模型无需推理机器人运动学,而动作模型无需解决长视野场景预测。基于中间规划载体的类型,级联 WAMs 被分类为通过像素空间表示的显式规划和通过潜在表示的隐式规划。下面的示意图提供了这些级联模式的概述。
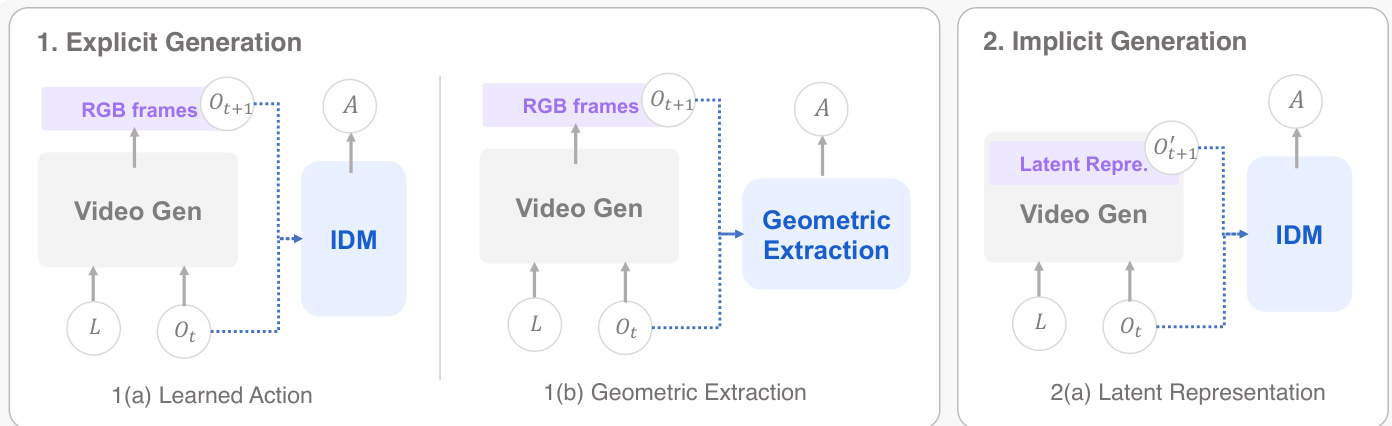
显式规划使用原始像素帧作为中间表示。该领域的工作根据如何从合成的视频中提取动作进行划分,要么通过学习的逆动力学,要么通过封闭形式的几何计算。隐式规划受到以下观察的启发:在扩散过程中形成的中间潜在表示已经编码了规划所需的动力学信息。规划载体被替换为始终保持在压缩表示空间中的潜在特征序列。下面的表格提供了级联世界动作模型方法的比较。
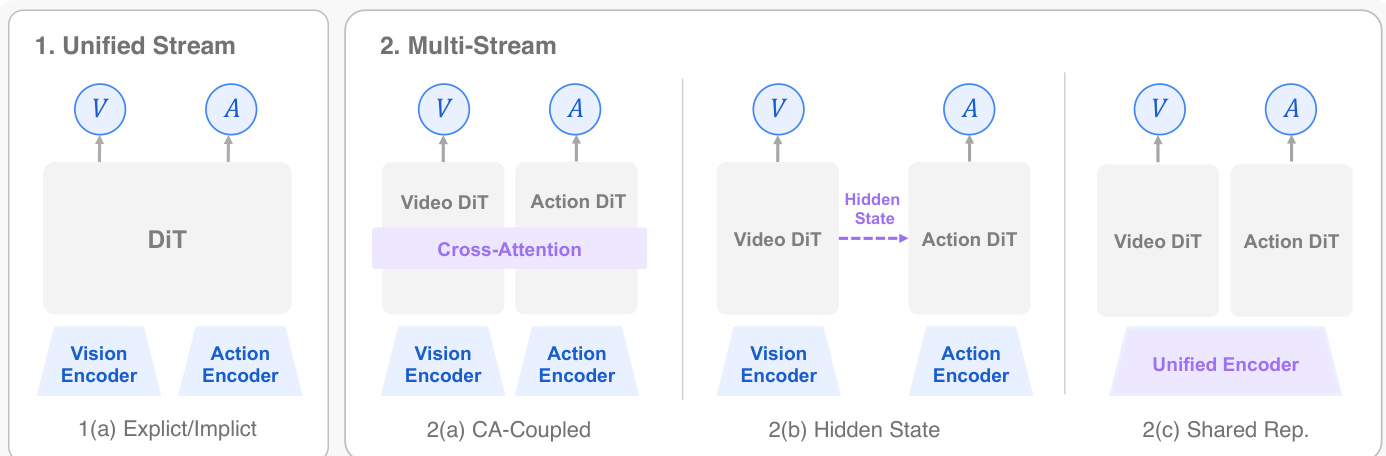
联合世界动作模型表示一个架构族,其中未来世界状态和动作在单个统一模型内预测。在这个统一定义下,现有的联合世界动作模型被组织为两个广泛的生成路线。自回归生成依赖于因果、从左到右的顺序解码来参数化未来状态和控制信号。在这些架构中,异构变量被序列化为统一的时间序列,其中世界和动作的联合分布被顺序分解。表 2 呈现了自回归生成论文的分类导向总结。
基于扩散的生成构成了一个重要的技术路线,其特征在于多步生成过程以捕获未来状态的复杂分布。这些架构在多步视野上并发生成未来世界状态和动作序列。这种方法从根本上克服了自回归建模的顺序瓶颈,实现了闭环控制所需的高频执行。
实验
评估框架通过三个维度评估世界建模能力:视觉保真度、物理常识和动作合理性,以及动作策略生成的特定基准。虽然视觉指标确保感知一致性,但动作合理性测试强调了一个关键差距,即视觉上令人信服的模式往往无法支持可执行的机器人行为。此外,动作策略评估按机器人形态对基准进行分类,以验证模型在各种操作场景中生成稳健控制信号的能力。
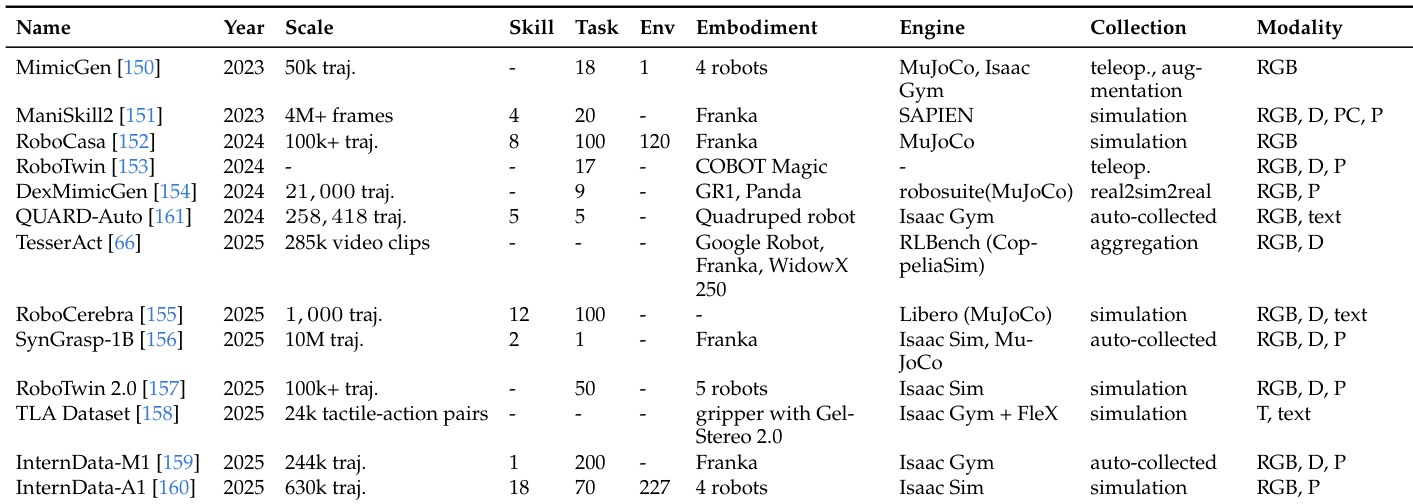
该表呈现了用于评估机器人动作策略和世界模型的数据集和基准的系统审查。它详细说明了各种条目,按规模、任务复杂度、仿真引擎和传感器模态进行分类。数据突出了向更大规模数据集和多样化具身设置的趋势,包括仿真和现实世界收集方法。数据规模差异很大,从小规模轨迹集到包含数百万帧的大型集合。传感器模态扩展到标准 RGB 之外,在许多条目中包含深度、点云、文本和触觉数据。数据收集方法多种多样,利用遥操作、仿真、自动收集和聚合策略。
该表根据中间表示对动作策略评估方法进行分类,区分像素空间方法和那些利用潜在特征的方法。像素空间方法进一步分为采用学习动作提取与几何提取管道的方法。评估列展示了在各种仿真环境和现实世界机器人硬件设置上的广泛测试。方法分为三大类:像素空间学习提取、像素空间几何提取和通过潜在表示的隐式规划。评估环境包括各种仿真平台和现实世界机器人,如 Franka、WidowX 和 Aloha。虽然大多数方法在训练期间利用动作标签,但几何提取方法的一个子集支持 zero-shot 评估。
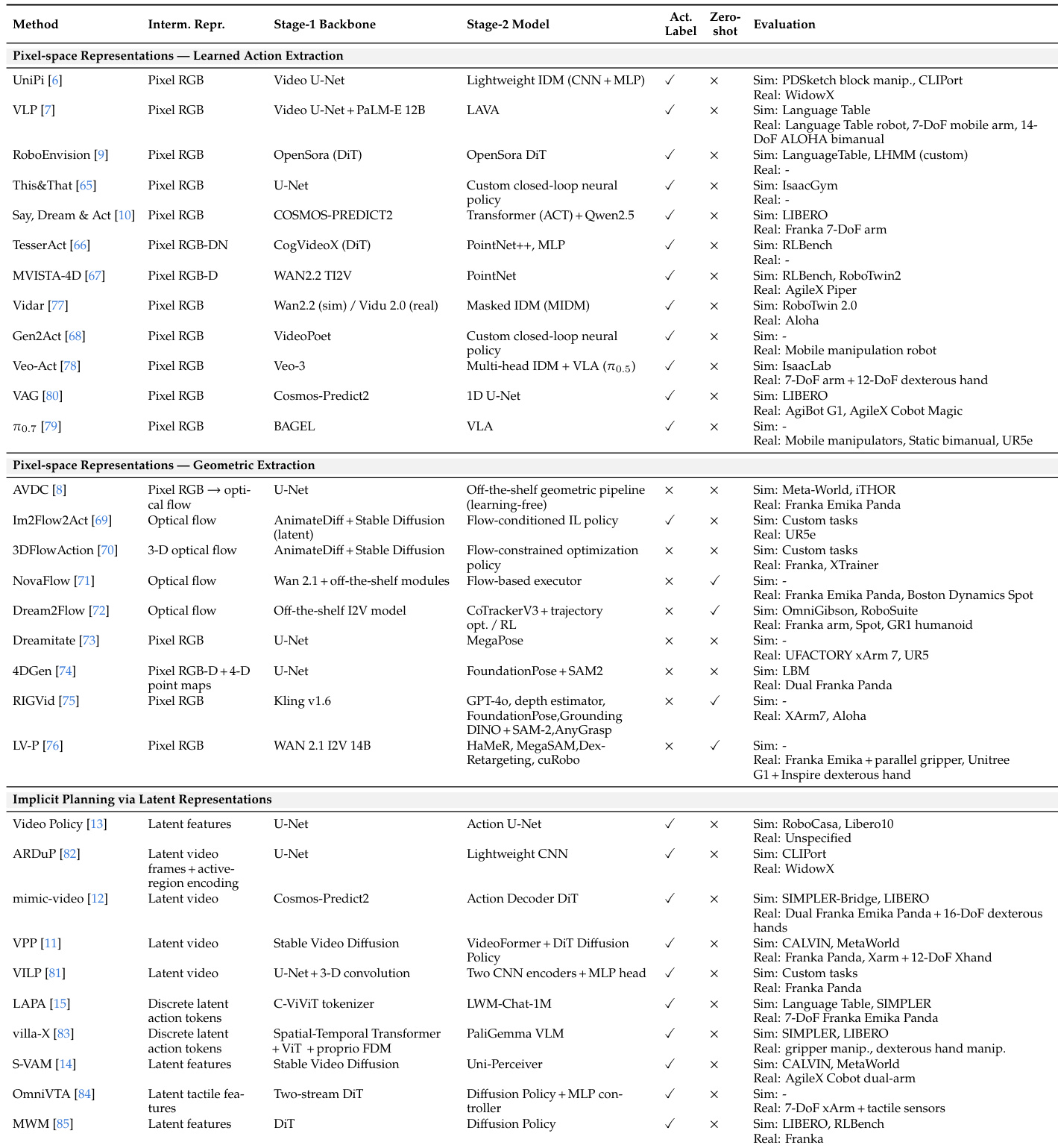
评估框架系统地审查了机器人数据集和基准,突出了向更大规模集合的趋势,具有从 RGB 到触觉数据的多样化传感器模态。动作策略评估按中间表示进行分类,区分像素空间方法和那些在各种仿真和现实世界硬件设置中利用潜在特征的方法。虽然大多数方法在训练期间依赖动作标签,但分析揭示了数据收集策略的显著多样性,并指出 zero-shot 评估由特定的几何提取管道支持。