Command Palette
Search for a command to run...
基于点互信息的推理强化学习中的反自蒸馏
基于点互信息的推理强化学习中的反自蒸馏
Guobin Shen Xiang Cheng Chenxiao Zhao Lei Huang Jindong Li Dongcheng Zhao Xing Yu
摘要
基于策略的自蒸馏(On-policy self-distillation)中,学生模型被拉向其基于特权上下文(例如已验证的解答或反馈)的自身副本,这为在不依赖更强外部教师的情况下提升推理能力提供了一条有前景的途径。然而,在数学推理任务中,该方法带来的收益并不一致,即便它在其他领域取得了成功。通过点互信息(Pointwise Mutual Information, PMI)分析,我们发现失败根源在于特权上下文本身:它夸大了教师模型对已由解答所隐含的 token(如结构连接词、可验证声明)的置信度,同时降低了其对驱动多步搜索的 deliberation token(如“Wait”、“Let”、“Maybe”)的置信度。我们提出了反自蒸馏(Anti-Self-Distillation, AntiSD),其策略是上升而非下降学生与教师之间的分歧:该方法反转了每个 token 的符号,从而在单步内产生自然有界的优势。当教师模型的熵坍缩时,一个由熵触发的门控机制会禁用该项,从而实现对默认自蒸馏的即插即用替换。在涵盖 4B 至 30B 参数规模的五个模型上,针对数学推理基准测试,AntiSD 仅需 2 到 10 倍更少的训练步数即可达到 GRPO 基线的准确率,并将最终准确率提高了多达 11.5 个百分点。AntiSD 为可扩展的自我改进开辟了一条路径,使语言模型能够通过其训练信号引导自身推理能力的自举提升。
一句话总结
作者提出了反自我蒸馏(Anti-Self-Distillation, AntiSD),这是一种强化学习技术。该方法在自我蒸馏过程中反转每个 token 的符号,使 deliberation tokens 优先于 structural tokens,并将此机制与一个由熵触发的门控结合,在熵坍塌时禁用该信号项。这使得参数量在 4B 到 30B 之间的五个模型能够在比基线少 2 到 10 倍的训练步数内达到 GRPO 基线精度,同时将最终数学推理精度提升最高达 11.5 个点。
核心贡献
- 点互信息分析表明,标准在线自我蒸馏在数学推理任务上表现不佳,因为经过验证答案条件约束的教师模型会过度强化 structural tokens,同时抑制多步搜索所需的 deliberation tokens。
- 反自我蒸馏(AntiSD)反转了每个 token 的蒸馏梯度以保留探索性推理,并整合了一个熵触发门控,在教师模型置信度坍塌时停用该信号,可作为默认自我蒸馏的直接替换方案。
- 对五个参数量在 4B 到 30B 之间的模型进行的评估表明,AntiSD 能够在比基线少 2 到 10 倍的训练步数内达到 GRPO 基线精度,并在数学推理基准测试中将最终精度提升最高达 11.5 个点。
引言
基于可验证奖励的强化学习已成为训练后推理模型的标准方法,但稀疏的轨迹级信号使得难以将奖励归因于单个推理步骤。尽管以往工作依赖外部过程奖励模型或在线蒸馏,在线自我蒸馏提供了一种无需模型辅助的替代方案,即在特权上下文中将学生模型自身作为教师模型。作者指出,默认的自我蒸馏在复杂数学推理任务中常常失败,因为基于已验证答案对教师模型进行条件约束会生成一个“先知”模型,该模型会强化事后 tokens 同时抑制必要的 deliberation。为解决这一问题,作者采用了一种梯度反转策略,通过最大化散度而非最小化散度来更新参数,从而有效保留探索性推理步骤。结合熵触发门控机制,该反自我蒸馏框架可作为直接替换方案,加速训练收敛,并在多个模型规模上于具有挑战性的数学基准测试中带来显著的精度提升。
方法
作者提出了一种重新思考在线自我蒸馏在推理任务(尤其是数学问题求解)中基础梯度方向的框架。核心观点基于以下观察:标准自我蒸馏通过最小化在特权上下文条件下学生策略与教师策略之间的 Kullback-Leibler (KL) 散度,引入了破坏多步推理的结构化偏差。这种偏差的产生是因为每个 token 的信号源自教师与学生之间的对数概率差,该信号对应于下一个 token 与特权上下文之间的条件点互信息 (PMI)。如图所示,该信号会不成比例地奖励由特权上下文所隐含的 tokens(例如结构连接词和可验证声明),同时惩罚对探索替代解决方案路径至关重要的 deliberation tokens(例如“Wait”、“Let”或“Maybe”)。
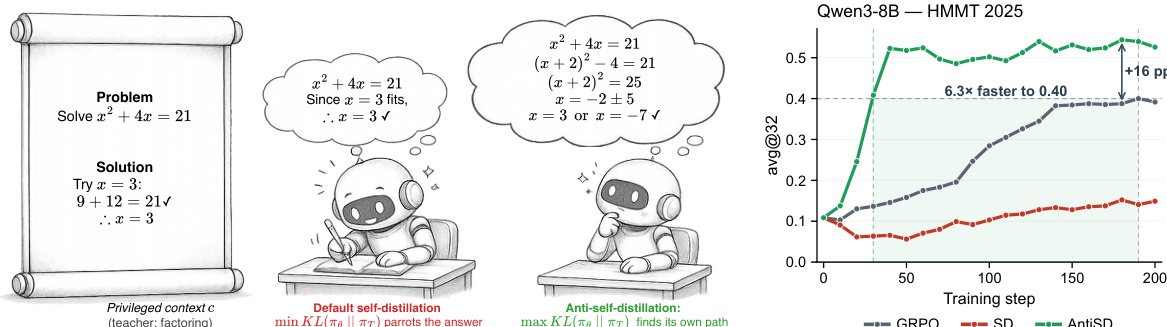
框架图示展示了这一现象:在默认自我蒸馏下,学生模型会被拉向教师模型的置信度,而教师模型对已被答案蕴含的 tokens 的置信度被高估,这实际上缩短了推理轨迹。相比之下,提出的反自我蒸馏(AntiSD)方法通过最大化学生与教师分布之间的 Jensen-Shannon (JS) 散度来反转该梯度方向。这种反转自然地将每个 token 奖励的符号取反,从而鼓励学生模型探索 deliberation tokens 并避免过早收敛到捷径解。JS 散度为梯度幅度提供了内在的上界,这稳定了训练过程并消除了手动缩放的需要。该方法的一个关键组件是熵触发门控,它在教师模型的每个 token 熵坍塌时动态禁用 AntiSD 项,确保该方法保持鲁棒性并作为标准自我蒸馏的直接替换方案运行。如图所示的性能曲线表明,该设计使得参数量在 4B 到 30B 之间的模型在数学推理基准测试中能够实现更快的收敛速度和更高的最终精度。
实验
该评估在数学和代码推理任务上训练了多个语言模型,以在不同规模下将 AntiSD 与标准 GRPO 和默认自我蒸馏进行对比。主要结果和消融研究验证了 AntiSD 的反转每个 token 奖励能够加速收敛、维持生成多样性,并防止传统自我蒸馏中固有的熵坍塌。补充实验进一步证实,自适应熵门控能够稳定训练动态,同时使该方法能够有效优化已经饱和的策略。最终,AntiSD 通过奖励 deliberative token 生成并在不同模型架构中提供稳健的优化稳定性,始终超越基线方法。
作者将 AntiSD(一种通过反转自我蒸馏梯度方向以避免捷径偏差的方法)与 GRPO 和默认自我蒸馏在多个语言模型上进行了对比。结果表明,AntiSD 能够在更少的训练步数内达到比 GRPO 更高的精度,并显著优于在大多数模型上无法收敛的默认自我蒸馏。该方法的有效性在不同模型规模和基准测试中保持一致,即使将其作为对饱和 GRPO 检查点的优化手段,其收益也能得到保持。AntiSD 在所有模型上均能以更少的训练步数取得比 GRPO 更高的精度,加速幅度在 2 倍到 10 倍之间。默认自我蒸馏在所有模型上的表现均劣于 GRPO,且经常无法收敛,而 AntiSD 则持续提升性能。AntiSD 的收益在各项基准测试中保持稳定,即使应用于饱和的 GRPO 模型作为优化手段依然有效。
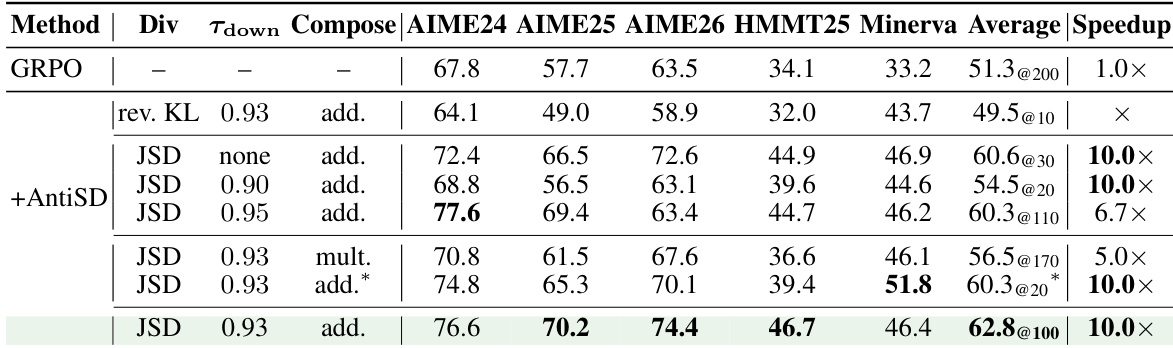
作者在多个语言模型上将 AntiSD 与 GRPO 和默认自我蒸馏进行对比,显示 AntiSD 能够在更少的训练步数内达到比 GRPO 更高的精度,并显著优于默认自我蒸馏。AntiSD 在不同的 rollout 数量下始终保持稳定的性能领先,表明其在不牺牲多样性的情况下维持了持续的问题解决能力。结果证明,AntiSD 的优势在不同模型规模下保持稳定,并可作为对现有 GRPO 检查点的优化手段使用。AntiSD 仅需极少的训练步数即可达到比 GRPO 更高的精度,并提升了所有模型的最终性能。AntiSD 在不同 rollout 数量下对 GRPO 的领先优势得以保持,表明其具备持续的问题解决能力且未损失多样性。AntiSD 的收益具有高度鲁棒性,可应用于已训练的 GRPO 模型作为进一步优化手段,从而进一步提升性能。
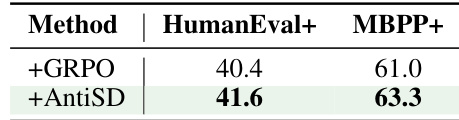
作者使用 HumanEval+ 和 MBPP+ 两个基准测试评估了 AntiSD 在代码推理任务上的性能,并将其与 GRPO 基线进行对比。结果表明,AntiSD 在这两个基准测试上均取得了比 GRPO 更高的精度,整体表现均有提升。虽然收益幅度小于数学推理任务,但提升方向保持一致,表明该方法可迁移至轨迹级奖励更密集的代码生成场景。AntiSD 在 HumanEval+ 和 MBPP+ 基准测试上均优于 GRPO 基线。代码推理任务的性能提升幅度小于数学推理任务,但方向一致。AntiSD 的优势延伸至代码生成领域,表明该方法具有超越数学问题求解的泛化能力。
{"summary": "作者对比了语言模型的多种训练方法,重点介绍 AntiSD。该变体采用符号反转的奖励信号和熵触发门控,以避免默认自我蒸馏的失效模式。结果表明,AntiSD 在所有模型上均取得了比 GRPO 和默认自我蒸馏更高的精度,能够在更少的训练步数内达到 GRPO 的性能水平,并且即使应用于饱和的 GRPO 检查点也能保持收益。该方法在保持 rollout 多样性的同时提升了训练速度和最终精度,其有效性得到了稳定训练动态和消融研究的支持,后者强调了特权上下文和门控机制的重要性。", "highlights": ["AntiSD 在所有模型上均取得比 GRPO 和默认自我蒸馏更高的精度,且能在更少的训练步数内达到 GRPO 的性能。", "AntiSD 保持了 rollout 多样性,多次尝试中 pass@k 收益的持续增加表明其具备真正的问题解决能力而非模式崩溃。", "该方法的成功依赖于特权上下文和熵触发门控,消融实验表明移除这些组件会导致训练失败或性能下降。"]}
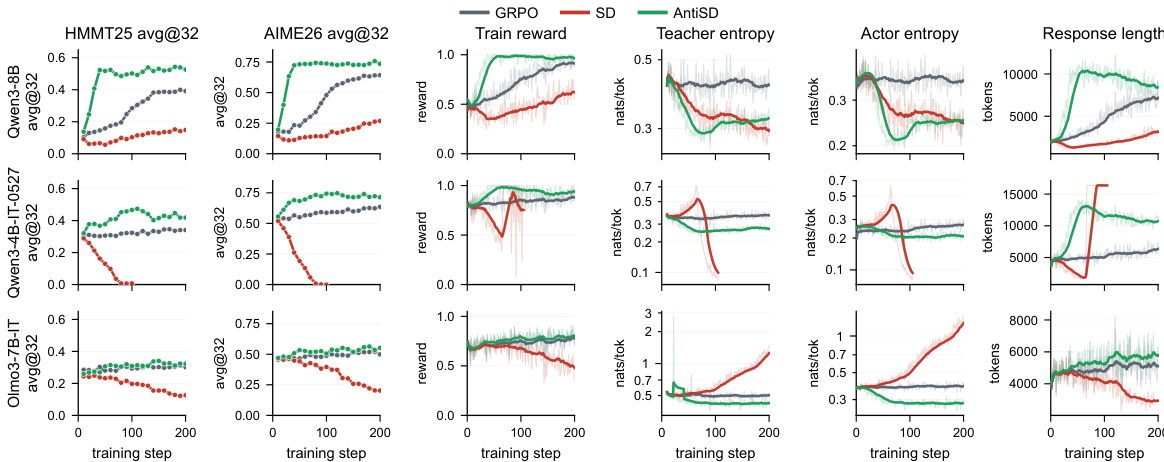
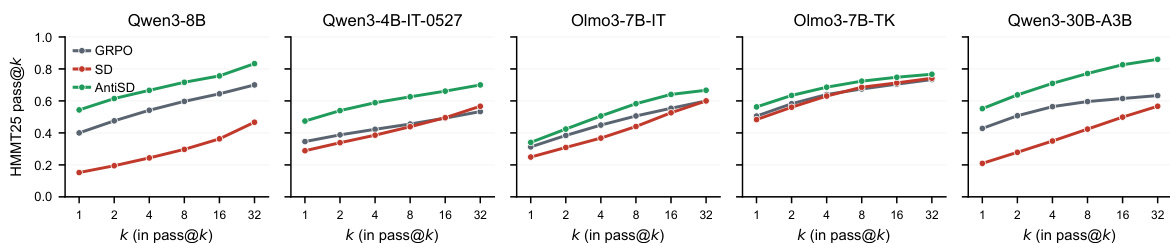
作者在多个语言模型上将 AntiSD 与 GRPO 和默认自我蒸馏进行对比,显示 AntiSD 能够实现更高的精度和更快的收敛速度。结果表明,AntiSD 能够在更少的步数内达到 GRPO 的最高性能,并在最终精度上持续优于 GRPO,其中较小规模模型的收益最为显著。默认自我蒸馏在所有模型上的表现均劣于 GRPO,这表明优化过程因偏差而失败。与 GRPO 相比,AntiSD 实现了更高的精度和更快的收敛速度,在较小规模模型上的加速比最高可达 10 倍。AntiSD 在所有模型上的最终精度均持续优于 GRPO,收益幅度在 2.1 到 11.5 个点之间。默认自我蒸馏在所有模型上均劣于 GRPO,凸显了因奖励信号偏差导致的优化失败问题。
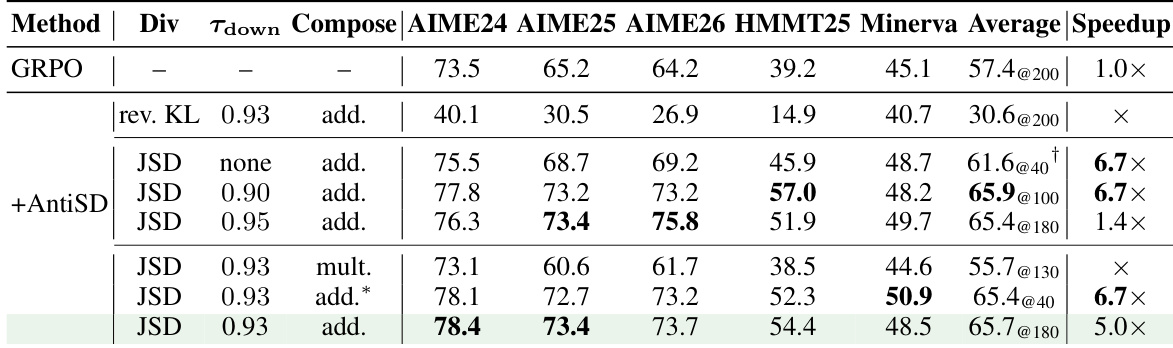
实验在多个语言模型和推理基准上评估了 AntiSD 与 GRPO 及默认自我蒸馏的对比,以验证训练效率、最终精度和跨任务泛化能力。结果表明,AntiSD 收敛速度显著更快,同时实现了更高的精度,成功规避了默认自我蒸馏中固有的捷径偏差和优化失败问题。该方法在不同模型规模、rollout 配置和代码生成任务中均保持了稳健的性能,证明其具备维持 rollout 多样性并作为现有检查点可靠优化手段的能力。消融研究进一步验证了这些改进依赖于特权上下文机制和熵触发门控,以确保稳定的学习动态。