Command Palette
Search for a command to run...
Poly-EPO:探索性推理模型的训练
Poly-EPO:探索性推理模型的训练
Ifdita Hasan Orney Jubayer Ibn Hamid Shreya S Ramanujam Shirley Wu Hengyuan Hu Noah Goodman Dorsa Sadigh Chelsea Finn
摘要
探索是经验学习的基础基石:它使智能体能够解决复杂问题、对新颖任务进行泛化,并通过测试时计算(test-time compute)实现性能的扩展。在本文中,我们提出了一种用于大型语言模型(LM)后训练(post-training)的框架,该框架显式地鼓励乐观探索(optimistic exploration),并促进探索与利用(exploitation)之间的协同效应。其核心思想是训练 LM 生成一组响应,这组响应在奖励函数(reward function)下整体上是准确的,且在推理策略上具有探索性。首先,我们开发了一种通用方法,用于在任意目标函数下通过集合强化学习(set RL)优化大型语言模型,展示了如何通过修改优势计算(advantage computation)将标准强化学习算法适应于这一设定。随后,我们提出了多色探索策略优化(Polychromatic Exploratory Policy Optimization, POLY-EPO),该算法通过一个显式协同探索与利用的目标函数来具体实现这一框架。在多种推理基准测试中,我们表明 POLY-EPO 提升了泛化能力(表现为更高的 pass@k 覆盖率),保持了模型生成结果的更高多样性,并有效地随测试时计算规模实现性能扩展。
一句话总结
This paper presents Polychromatic Exploratory Policy Optimization (POLY-EPO), a post-training framework for language models that explicitly encourages optimistic exploration and promotes synergy between exploration and exploitation via set reinforcement learning with modified advantage computation to generate diverse response sets, demonstrating improved generalization evidenced by higher pass@k coverage, greater generation diversity, and effective scaling with test-time compute across reasoning benchmarks.
核心贡献
- The paper develops a general recipe for optimizing language models with set reinforcement learning under arbitrary objective functions. This approach adapts standard reinforcement learning algorithms to the setting through a modification to the advantage computation.
- Polychromatic Exploratory Policy Optimization (POLY-EPO) instantiates this framework with an objective that explicitly synergizes exploration and exploitation. The method encodes this synergy directly in the advantage function by depending on the covariance between average reward and diversity across generations in a set.
- Experiments across a range of reasoning benchmarks show that POLY-EPO improves generalization as evidenced by higher pass@k coverage. The method also preserves greater diversity in model generations and effectively scales with test-time compute.
引言
Exploration is essential for language models to generalize to novel problems and scale performance with test-time compute, but standard reinforcement learning fine-tuning often collapses generation diversity onto narrow high-reward behaviors. Previous methods typically address this by adding exploration bonuses to the reward function, yet they treat exploration and exploitation as separate objectives that rely on careful hyperparameter tuning rather than explicit synergy. The authors leverage a scalable set reinforcement learning framework to introduce Polychromatic Exploratory Policy Optimization, which optimizes sets of responses based on both average reward and reasoning strategy diversity. By incorporating the covariance between reward and diversity into the advantage function, their approach encourages optimistic exploration of novel strategies while maintaining high task performance and improving generalization across reasoning benchmarks.
方法
The authors leverage a framework called Set Reinforcement Learning (Set RL) to optimize language models. Standard reinforcement learning assigns rewards to individual trajectories, whereas Set RL assigns rewards to sets of sampled actions. In the language model setting, this means evaluating a set of n generations sampled from the same prompt. The optimization goal is to maximize the expected set-level reward function f(x,y1:n), where x is the prompt and y1:n represents the set of generations. This formulation couples all generations in a set under a shared learning signal, distinguishing it from standard approaches where each generation receives an independent advantage.
To make this framework computationally feasible, the authors derive an unbiased gradient estimator. For a given prompt, the policy samples N independent generations where N>n. From these samples, K sets of size n are constructed without replacement. The set-level score for each constructed set is computed, and a baseline is defined as the average of these scores across all sets. The set advantage is then calculated as the difference between the set score and the baseline. To apply this within standard policy gradient algorithms, a marginal set advantage is defined for each individual generation. This value is the average of the set advantages for all sets that contain the specific generation. This marginal advantage replaces the standard advantage function in algorithms such as PPO or GRPO, enabling the use of existing optimization infrastructure.
The specific objective implemented in this work is the polychromatic objective. This function is designed to encourage both exploration and exploitation. It is defined as the product of the mean reward of the generations in a set and a diversity metric for that set. The mathematical form is given by:
fpoly(x,y1:n)=n1i=1∑nr(x,yi)⋅d(x,y1:n)where r(x,yi) is the reward for an individual generation and d(x,y1:n) measures the diversity of the set. Because the objective is a product, a set must achieve both high reward and high diversity to maximize the score. This structure allows an incorrect generation to receive a positive learning signal if it contributes to the diversity of a set that contains correct generations.
Diversity is quantified using a language model judge that clusters generations based on reasoning strategies. The judge groups responses according to their underlying semantic approach, ignoring superficial differences like tone or phrasing. Responses that exhibit degenerate behaviors, such as reward hacking or unintelligible text, are isolated into a dedicated cluster and excluded from diversity calculations. The diversity of a set is calculated as the number of distinct clusters represented in the set divided by the set size. This ensures that the diversity metric reflects genuine strategic variation rather than noise.
The final training algorithm, POLY-EPO, integrates these components into a standard on-policy loop. The process involves sampling generations, constructing sets, computing polychromatic scores, and deriving marginal set advantages. These advantages are then used to update the policy parameters. This design allows the method to scale efficiently while maintaining the benefits of set-level credit assignment. The resulting policy update internalizes the balance between exploration and exploitation, as the advantage assigned to a trajectory depends on its contribution to the synergy between reward and diversity across sets.
实验
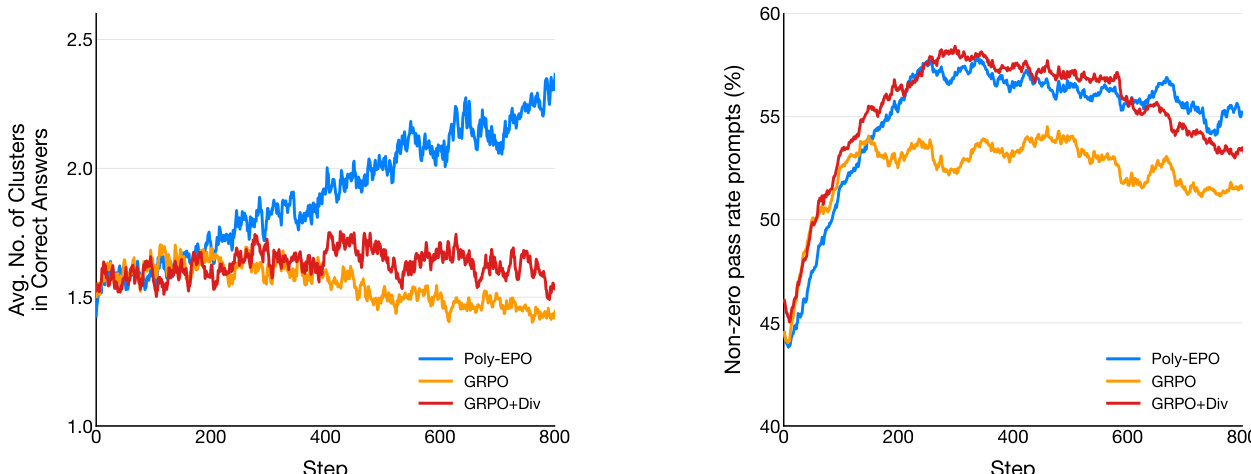
The study evaluates POLY-EPO on mathematical reasoning benchmarks and synthetic domains with infinitely many valid strategies, comparing it against GRPO and a diversity-augmented baseline. In mathematical reasoning tasks, POLY-EPO demonstrates superior exploration by maintaining diverse reasoning clusters throughout training and branching earlier during generation, which leads to improved generalization and effective use of test-time compute. Experiments in synthetic domains further reveal that while standard methods collapse to single strategies, POLY-EPO successfully uncovers a significantly broader repertoire of successful solutions, confirming the objective's ability to balance exploration and exploitation.