Command Palette
Search for a command to run...
MegaTrain:在单GPU上以全精度训练千亿参数级大语言模型
MegaTrain:在单GPU上以全精度训练千亿参数级大语言模型
Zhengqing Yuan Hanchi Sun Lichao Sun Yanfang Ye
摘要
我们提出MegaTrain,一个以内存为中心的系统,能够在单GPU上以全精度高效训练千亿参数级大语言模型。与传统以GPU为中心的系统不同,MegaTrain将参数和优化器状态存储在主机内存(CPU内存)中,并将GPU视为瞬态计算引擎。对每一层,我们流式传入参数并计算梯度传出,从而最小化持久化设备状态。为应对CPU-GPU带宽瓶颈,我们采用两项关键优化:1)引入流水线式双缓冲执行引擎,通过多个CUDA流重叠参数预取、计算和梯度卸载,实现GPU持续执行;2)用无状态层模板替代持久化自动微分图,在参数流式传入时动态绑定权重,消除持久化图元数据,同时提供调度灵活性。在配备1.5TB主机内存的单块H200 GPU上,MegaTrain可稳定训练高达120B参数的模型。在训练14B模型时,其训练吞吐量达到DeepSpeed ZeRO-3配合CPU卸载方案的1.84倍。MegaTrain还支持在单块GH200上以512k token上下文训练7B模型。
一句话总结
圣母大学和理海大学的研究人员提出 MegaTrain,一种以内存为中心的系统,通过在单块配备 1.5TB 主机内存的 H200 GPU 上将参数和优化器状态卸载到主机内存并流式传输层,采用流水线双缓冲执行引擎和无状态层模板来重叠计算与数据移动,在全精度下训练 100B+ 参数的大语言模型,对于 14B 模型实现了 DeepSpeed ZeRO-3 配合 CPU 卸载 1.84 倍的训练吞吐量,并在单个 GH200 上实现了 512k token 上下文的 7B 模型训练。
核心贡献
- MegaTrain 是一个以内存为中心的训练系统,将所有参数和优化器状态存储在主机 CPU 内存中,并将 GPU 视为瞬态计算引擎,从而在单块 H200 GPU 上实现高达 120B 参数的全精度训练。对于 14B 模型,它实现了 DeepSpeed ZeRO-3 配合 CPU 卸载 1.84 倍的训练吞吐量,并支持在单个 GH200 上进行 512k token 上下文的 7B 模型训练。
- 流水线双缓冲执行引擎在多个 CUDA 流上重叠参数预取、层计算和梯度卸载,隐藏了 CPU 与 GPU 之间的传输延迟,并在训练期间保持 GPU 持续被利用。
- 无状态层模板通过动态绑定流式传入的权重,取代了持久化的 autograd 图,消除了图元数据的内存开销,并将 GPU 内存使用降低到每层的内存占用量。
引言
随着大语言模型扩展到数千亿参数,创新的焦点从预训练转向了以内存为瓶颈的后训练工作负载,例如指令微调和对齐。这些任务在计算上足够轻量,可以在单个节点上运行,但它们仍然需要将完整的模型参数和优化器状态加载到 GPU 内存中,这使得大多数缺乏高内存 GPU 的从业者无法使用。现有的卸载系统(如 ZeRO-Offload)将主机内存用作临时溢出缓冲区,而 GPU 仍然是主要的参数宿主,这未能充分利用内存层次结构,并使持久化状态固定在设备内存中。
作者提出 MegaTrain,一个以内存为中心的训练系统,它颠倒了这种关系,使主机内存成为参数和优化器状态的权威存储,而 GPU 仅作为瞬态计算引擎。在前向和后向传递期间,参数按需流式传输到 GPU 缓冲区并立即释放,同时采用块状重计算策略保持激活内存有界。流水线双缓冲执行引擎将参数流式传输与计算重叠,无状态层模板消除了持久化 autograd 图的内存开销。这种设计将模型规模与 GPU 内存容量解耦,使得在单块 GPU 上以比现有卸载基线更高的吞吐量全精度训练 100B+ 参数的模型成为可能。
数据集
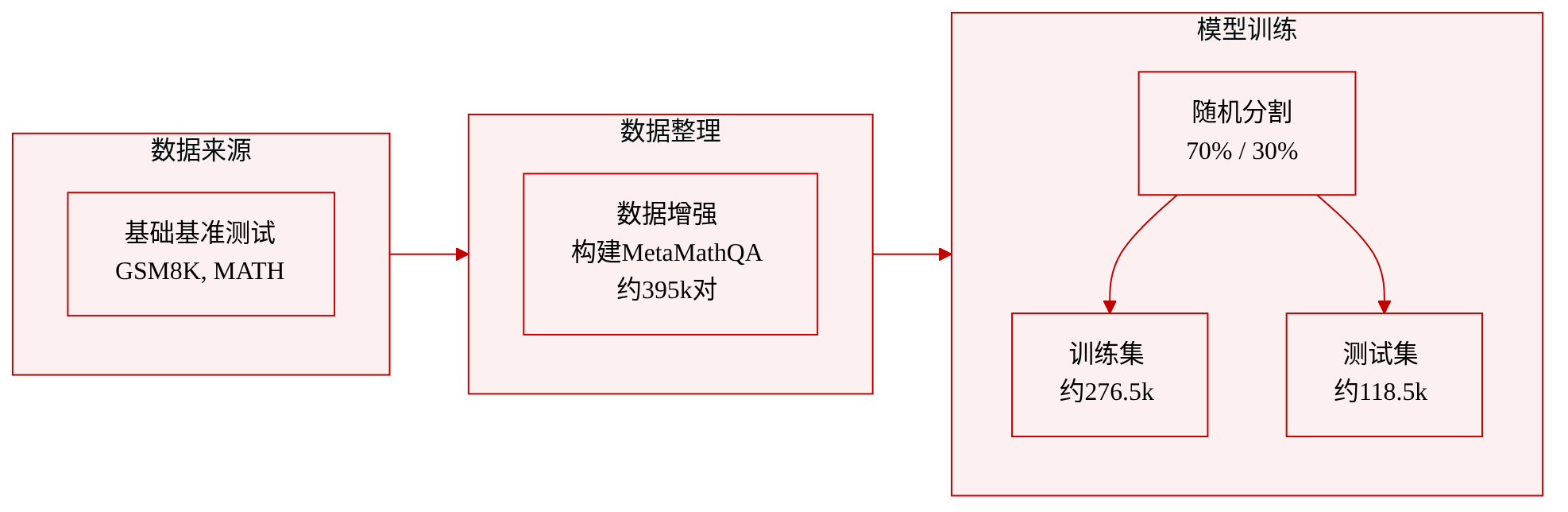
作者使用 MetaMathQA 基准来评估模型在数学推理上的准确性。该数据集包含大约 395,000 个英文数学问题-答案对,通过对 GSM8K 和 MATH 等基础基准应用数据增强构建而成。其结果是一个包含多样化、多步骤应用题且具有确定性真实答案的集合。
关于数据集及其使用的关键细节:
- 完整数据集被随机划分为 70% 的训练集(约 276,500 个样本)和 30% 的测试集(约 118,500 个样本)。
- 作者报告了精确匹配准确率:只有当模型的最终答案与参考答案完全匹配时,预测才被认为是正确的。
- 论文侧重于数据如何用于评估,而非额外的过滤或预处理步骤。除了训练/测试划分外,没有描述任何裁剪策略、元数据构建或混合比例。
方法
作者将 MegaTrain 设计为一个以内存为中心的训练系统,它颠倒了主机内存与设备内存之间的传统关系。主机内存作为所有持久化训练状态(包括模型参数、优化器状态和累积梯度)的主存储,而设备内存仅充当瞬态计算缓存。
在执行工作流中,系统在前向阶段逐层将参数从主机内存流式传输到设备内存中的权重缓冲区。激活值被周期性地设置检查点并保留在设备内存中。在流式后向阶段,系统以逆序块的方式进行。它从检查点开始,流式传输参数以重计算激活值,然后以逆序流式传输参数以计算后向传递,并立即将每一层的梯度卸载到主机内存。这种块状重计算以额外的正向计算换取有界的内存。最后,优化器更新阶段完全在 CPU 上执行。由于优化器更新是计算轻但 I/O 密集型的,在 CPU 上执行它们避免了将优化器状态流式传输到 GPU 再传回的昂贵往返,从而匹配或超过了 GPU 吞吐量,同时消除了大量的数据移动。
为了将数据移动延迟隐藏在计算之后,作者编排了三个并发的 CUDA 流:计算流 (Scomp)、权重传输流 (SH2D) 和梯度传输流 (SD2H)。
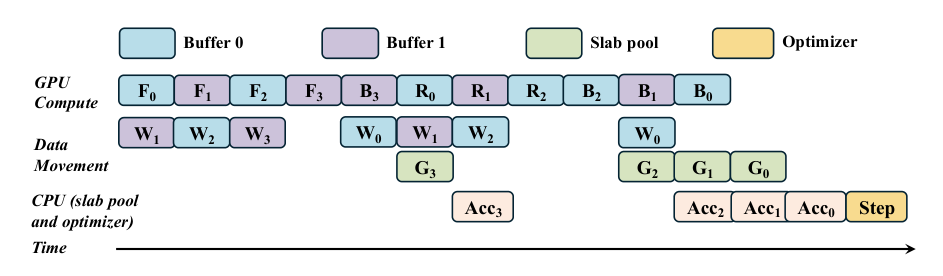
如框架图所示,系统采用双缓冲暂存以实现持续的 GPU 执行。它在 CPU 和 GPU 域中都维护两组暂存缓冲区,从而实现乒乓预取策略。计算流使用一个缓冲区执行一层,而权重传输流同时将下一层的权重打包并流式传输到另一个缓冲区。这种重叠确保了 GPU 计算单元永远不会因等待参数而停顿。相同的双缓冲机制也应用于后向传递。在梯度被移出的同时,下一层的参数已经在流式传入。将梯度传输流与计算流分离对于异步梯度移出至关重要,可防止设备到主机的延迟进入关键路径。这些流之间的协调由轻量级的 CUDA 事件管理,例如在权重传输完成后记录的 Weights-Ready 事件,计算流在绑定层之前会等待该事件。
为了最大化 PCIe 带宽,作者采用了层连续平铺技术。每一层的所有状态,包括 BF16 权重、BF16 梯度和 FP32 Adam 矩,都被打包到一个与 4KB 页面对齐的连续块中。这使得单次突发的 DMA 传输成为可能。系统不是固定整个模型(这会耗尽主机物理内存),而是分配一小部分固定的暂存缓冲区。一个专用的 CPU 工作线程执行即时打包,将数据从可分页的层存储区移动到固定的内存块中,DMA 传输从此处以全带宽进行。
最后,作者采用了一种将数学结构与物理数据解耦的无状态执行模型。标准的 autograd 图假设参数和激活值持久驻留在 GPU 上,这在逐层流式传输下不适用。相反,系统采用了一个无状态模板池,其中每个模板封装了用于计算的 CUDA 内核,但不持有持久的权重指针。在执行前,一个 Bind 原语将流式缓冲区中的视图动态映射到模板的输入槽。这种乒乓绑定允许一个层在一个模板上执行,而下一个层正在被绑定到另一个模板,从而消除了权重准备延迟。运行时保留了一条显式的调度路径,而不是依赖 CUDA graph 捕获,从而实现了动态缓冲区分配和精确的张量生命周期管理,这对于确定性的内存边界至关重要。
实验
评估使用 MetaMathQA 在 GH200 和 H200 系统上进行准确性测试,涵盖从 7B 到 120B 参数的模型。MegaTrain 表明,主机内存而非设备内存才是真正的扩展边界,它保持了平坦的内存增长曲线和高持续 TFLOPS,而竞争系统则表现出近乎指数的内存需求和吞吐量崩溃。消融研究证实,双缓冲和平衡的重计算粒度对性能至关重要,而深度和宽度可扩展性实验显示,MegaTrain 可以扩展到 180 层和 5 倍宽度,而基线系统则会耗尽内存。长上下文测试揭示了高达 512K 序列长度的稳定内存使用和提升的计算效率,并且在基于 PCIe 的 A100、RTX A6000 和 RTX 3090 系统上的验证证实了一致的加速比,以及在消费级硬件上训练大型模型的能力,而其他卸载方法则无法做到。
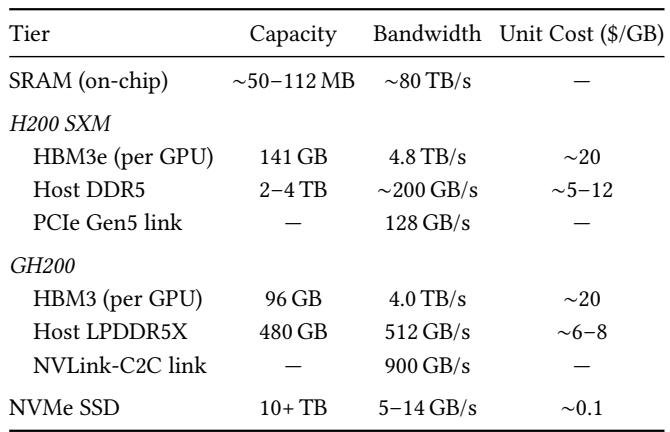
现代 GPU 服务器呈现出四级内存层次结构,其中更快的层级容量更小、成本更高,而 CPU 与 GPU 之间的互连是一个关键的区别因素。GH200 的 NVLink-C2C 提供的带宽大约是 H200 的 PCIe Gen5 链路的七倍,这从根本上改变了哪些数据卸载策略是可行的。MegaTrain 通过将主机内存视为主存储,将设备内存视为瞬态缓存来利用这一点,即使在内存受限的设备上也能实现高吞吐量。片上 SRAM 以大约 80 TB/s 的速度提供最高带宽,但容量限制在几十兆字节。HBM 设备内存提供每秒 TB 级的带宽和数百 GB 的容量,作为主要的计算内存。主机内存以每秒数百 GB 的速度提供 TB 级的容量,并且每字节成本大约是 HBM 的十分之一。GH200 共同封装了 480 GB 的 LPDDR5X,并通过 NVLink-C2C 以 900 GB/s 的速度连接,这比 H200 的 128 GB/s PCIe Gen5 具有大约七倍的互连优势。
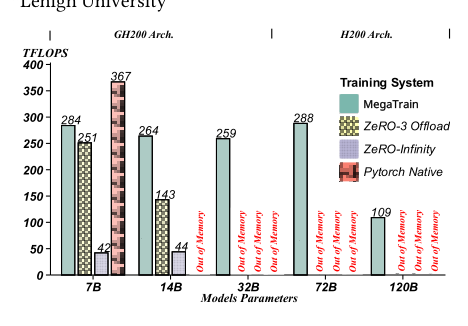
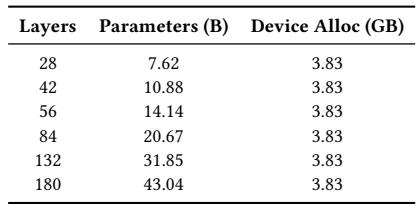
评估的模型配置涵盖了从 7B 到 72B 参数的密集架构以及一个 120B 的混合专家模型,隐藏层大小从 3584 到 8192,深度从 28 到 80 层。在数据中心和消费级 GPU 上,MegaTrain 均展示出相对于卸载基线的一贯吞吐量优势,并且它成功地在内存受限的设备上训练了更大的模型,而基线系统则因内存不足错误而失败。在 A100 系统上训练 14B 模型时,MegaTrain 实现的 TFLOPS 比 ZeRO-3 CPU 卸载高出多达 12.20 倍。在 24 GB 的 RTX 3090 上,MegaTrain 可扩展到 14B 参数训练,而 ZeRO-3 则因内存不足错误而失败。在 RTX A6000 上,MegaTrain 在 9 到 15 的批次大小范围内维持了超过 93% 的设备内存利用率。即使没有 NVLink 级别的互连,MegaTrain 也能在 A100 上训练 32B 模型,而 Gemini 和 ZeRO-3 都遇到了内存不足的失败。
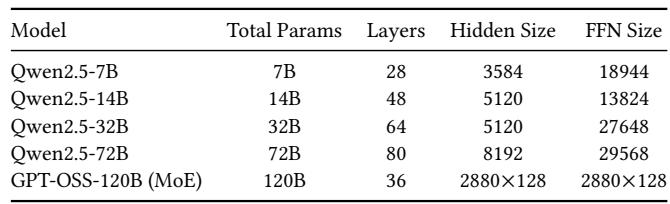
在 7B 和 14B 规模上,MegaTrain 提供的最终准确率与 ZeRO-3 Offload、ZeRO Infinity 和 PyTorch Native(在可用的情况下)几乎完全相同。可忽略不计的差异证实了该系统的内存和计算优化没有引入任何数值漂移或训练不稳定性,保持了标准的全 GPU 正确性。MegaTrain 的 7B 准确率与 ZeRO-3 Offload 和 ZeRO Infinity 的差距在 0.06% 以内,其 14B 准确率差距在 0.16% 以内,显示出几乎一致的收敛性。PyTorch Native 无法完成 14B 训练,而 MegaTrain 可以扩展到该规模,并且仍然匹配所有卸载基线的准确率。
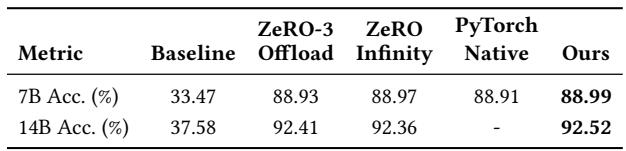
对 MegaTrain 的消融研究表明,通过双缓冲重叠参数预取、计算和梯度卸载对于实现高吞吐量至关重要,因为移除它会导致 TFLOPS 下降 31.3%。其他组件(如梯度内存块池)影响较小,而减少重计算粒度会增加内存压力并降低最大批次大小和吞吐量。移除双缓冲导致最大的吞吐量下降,将性能从 266.3 TFLOPS 降低到 182.9 TFLOPS。禁用梯度内存块池仅导致吞吐量小幅下降至 257.6 TFLOPS,表明它不是主要的性能驱动因素。将检查点间隔设置为 1 会将最大可行批次大小从 96 减少到 32,并由于激活内存压力增加而将吞吐量降低到 184.2 TFLOPS。
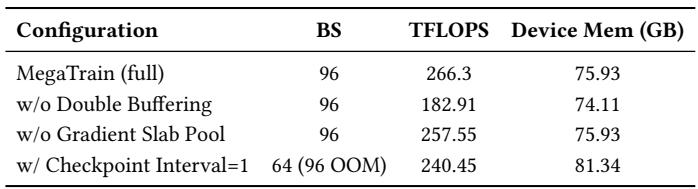
当模型深度增加而设备内存恒定时,MegaTrain 维持了高吞吐量,从 28 层到 180 层仅下降 20.1%,而卸载基线在超过 84 层后遭受严重的性能崩溃和内存不足故障。MegaTrain 在每个深度上使用的 host 内存也少得多,从而能够在单块 GPU 上仅用 3.83 GB 的设备内存训练超过 430 亿参数的模型。MegaTrain 的吞吐量从 28 层到 180 层仅下降 20.1%(从 284 到 227 TFLOPS),而 FSDP 的吞吐量在 56 层时降至 43 TFLOPS,ZeRO-3 在 84 层时降至 43 TFLOPS,之后两者均耗尽内存。在 84 层时,FSDP 的 host 内存达到 518 GB,是 MegaTrain 207 GB 的 2.50 倍;MegaTrain 继续扩展到 180 层,使用 418 GB。
评估考察了 MegaTrain 在四级 GPU 内存层次结构上的性能,其中 GH200 的 NVLink-C2C 互连提供了相对于 PCIe Gen5 七倍的带宽优势,从而能够有效利用主机内存作为主存储。MegaTrain 在 A100 上实现了比 ZeRO-3 卸载高出多达 12.20 倍的吞吐量,在 24 GB 的 RTX 3090 上扩展到 14B 参数训练(基线系统在此失败),并维持了超过 93% 的设备内存利用率,同时将最终准确率保持在卸载基线的 0.16% 以内。消融研究揭示,用于重叠预取、计算和卸载的双缓冲至关重要,因为移除它会导致 31.3% 的吞吐量下降,并且即使模型深度增加到 180 层,MegaTrain 仍能维持高吞吐量,而基线系统在超过 84 层后遇到内存不足故障。总的来说,MegaTrain 使得在设备内存有限的单块 GPU 上训练超过 430 亿参数的模型成为可能,展示了在不同硬件配置上稳健的可扩展性和效率。