Command Palette
Search for a command to run...
一键部署 PyTorch Grad-CAM:面向计算机视觉可解释 AI 的教程
摘要
一句话总结
结合用户访谈与当代研究,作者提出了一项面向无障碍可解释AI的研究议程。该议程旨在解决视障与低视力用户面临的模态鸿沟,通过倡导多模态、具备归责意识的对话式解释以及参与式开发,以减轻自我归责现象,并促进对自主多步Agent系统的信任。
核心贡献
- 本文通过整合定性访谈数据与当代无障碍研究,构建了面向视障与低视力用户的可解释AI需求框架。
- 分析指出了当前系统存在的模态鸿沟,并记录了用户如何通过非视觉验证与对话交互模式来应对环境感知与决策支持任务。
- 实证研究发现用户倾向于对话式解释,并在AI失效时出现“自我归责”现象,这直接为Agent系统中多模态界面与具备归责意识的解释设计指明了研究议程。
引言
随着自主系统从单查询工具向执行复杂长周期任务的多步Agent工作流演进,作者探讨了无障碍可解释AI的迫切需求。这一背景至关重要,因为当解释界面仅依赖视觉时,视障与低视力用户在独立使用技术方面正面临根本性障碍。以往研究主要依赖热力图等视觉归因方法,未能揭示Agent流水线背后的推理痕迹。这迫使使用者依赖低效的人工替代方案,并在系统产生幻觉或出错时频繁引发不当的自我归责。为弥合这一差距,作者综合用户访谈与当代研究,绘制了视障与低视力(BLV)群体特有的信任校准机制与模态偏好图谱。他们提出了一项结构化的研究议程,倡导采用多模态界面、具备归责意识的解释框架以及参与式设计,以确保未来的Agent AI系统保持透明、可问责且完全无障碍。
数据集
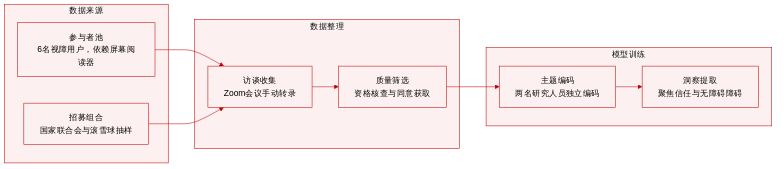
-
数据集构成与来源:作者整理了一份定性数据集,包含从六名视障与低视力参与者处收集的结构化半访谈转录稿。招募工作通过美国盲人全国联合会进行,并通过滚雪球抽样法补充了额外参与者。
-
核心子集详情与筛选规则:该数据集包含一个由六名用户组成的独立队列。入选条件包括:美国居民、年满18岁、主要依赖屏幕阅读器、英语流利,以及曾使用生成式AI工具的经验。最终群体包括五名女性和一名男性,年龄跨度为18岁至60岁及以上。
-
数据使用与处理:作者将这些转录稿应用于可解释AI、用户信任及无障碍障碍的定性研究。传统的数据训练划分与混合比例不适用于此数据集。相反,数据经过反思性主题分析,由两名研究人员独立对访谈内容进行编码,并每周召开会议以对齐新兴主题并解决编码差异。
-
额外处理与元数据详情:所有会话均通过Zoom远程进行,在获得知情同意后进行视频录制,并转换为文本转录稿。参与者获得了30美元亚马逊礼品卡作为补偿。本研究未采用裁剪策略或自动化元数据构建,而是依赖人工转录与迭代式主题编码,以提取关于对话式界面与渐进式信息披露的见解。
方法
作者采用以用户为中心的方法,分析非视觉AI系统中的验证策略。在此类系统中,用户无法直接通过视觉验证模型输出。在此类环境中,参与者会发展出代理策略,通过间接手段推断真相,依赖确定性数据源或冗余输入来弥补计算机视觉模型的概率性特征。如下图所示,其中一种策略涉及使用可信锚点(例如条形码)来交叉验证AI的描述。例如,用户可能首先扫描条形码,然后将系统的文本输出与条形码内容进行比对,将一致性作为建立信任的基础。该方法将硬编码的可靠数据点转化为验证机制,使用户无需视觉确认即可审计模型的预测结果。
观察到的另一种方法是多示例策略,用户手动生成多个输入(例如从不同角度拍摄多张照片),以在预测结果中达成共识。该行为类似于集成方法,重复的观察结果能够降低单次错误预测的影响。尽管在降低风险方面有效,但该过程给用户带来了显著的认知与时间负担,凸显了系统在自主提供充分置信度保证方面的能力缺口。在高利害关系场景(例如读取货币或文件)中,当AI输出仍不明确或不一致时,这些人工替代方案被证明是不足的。在此类情况下,用户会诉诸人工回退机制,完全放弃自动化系统以寻求外部验证。这种依赖凸显了当前可解释性方法的局限性,即未能提供独立的、可解释的证据,使用户无法独立消除不确定性。
分析进一步表明,视觉真实标签的缺失将可解释AI(XAI)的核心挑战从模型架构理解转移至结果验证。用户常表现出自我归责偏差,将系统故障归因于自身的输入质量,而非模型的不确定性。为解决这一问题,作者主张XAI设计应向具备归责意识的界面转变,明确提示输入质量问题并支持功能可申诉性。参与者表现出对对话式、来回交互的强烈偏好,在此类交互中他们可以质疑AI的置信度并要求重新评估。这种交互模态使用户能够要求非视觉证据并质疑系统逻辑,从而降低对人工回退的需求。在Agent系统中,决策可能导致不可逆的操作,此类交互变得至关重要。执行步骤级归因(在每一阶段区分输入质量故障与模型错误)以及在执行前要求明确用户确认的能力,能够带来更安全、更透明的Agent行为。该对话框架允许Agent解释其推理过程并接受后续质疑,直接支持了非视觉场景下对问责与控制的需求。
实验
针对视障与低视力参与者的定性研究揭示了用户如何在不同任务场景中与AI交互并评估其可靠性。实验验证了信任作为一种风险校准的滑动标尺在运行,但常因自我归责偏差而受损,用户将算法故障内化为个人执行错误,而非系统局限性。最终,研究证实对话式、非视觉解释对于解决不确定性及缓解由幻觉引发的不信任至关重要,随着AI系统承担更多自主功能,交互设计的需求显得尤为关键。