Command Palette
Search for a command to run...
接近最优的学习率调度形状是什么样的?
接近最优的学习率调度形状是什么样的?
Hiroki Naganuma Atish Agarwala Priya Kasimbeg George E. Dahl
摘要
神经网络训练中一个尚未解答的基本问题是:对于给定的工作负载,最佳的学习率调度形状是什么?学习率调度的选择是训练过程成败的关键因素,但除了需要某种预热和衰减外,对于什么构成良好的调度形状尚无共识。为了回答这个问题,我们设计了一种搜索过程,以在参数化调度族中找到最佳形状。我们的方法将调度形状与基础学习率分离,否则基础学习率会主导跨调度比较。我们将搜索过程应用于三种工作负载上的多种调度族:线性回归、CIFAR-10上的图像分类以及Wikitext103上的小规模语言建模。我们表明,我们的搜索过程确实普遍找到了接近最优的调度。我们发现预热和衰减是良好调度的稳健特征,而常用的调度族在这些工作负载上并非最优。最后,我们探讨了形状搜索的输出如何依赖于其他优化超参数,并发现权重衰减对最优调度形状有显著影响。据我们所知,我们的结果代表了迄今为止关于深度神经网络训练中接近最优调度形状的最全面成果。
一句话总结
通过提出一种将学习率调度形状与基础学习率解耦的形状搜索流程,来自 Mila、蒙特利尔大学和 Google DeepMind 的研究人员在线性回归、CIFAR-10 图像分类和 Wikitext103 语言建模上证明,预热和衰减是鲁棒的近似最优特征,常用的调度族是次优的,并且权重衰减强烈影响最优调度形状。
核心贡献
- 提出了一种搜索流程,将基础学习率分离出来以隔离调度形状,从而能够在不同调度族之间进行公平比较。
- 将该流程应用于线性回归、CIFAR-10 和 WikiText-103,搜索找到了近似最优的调度,揭示预热和衰减是鲁棒的特征,而常见的调度族是次优的。
- 最优调度形状强烈依赖于权重衰减,表明学习率调度优化不能与正则化超参数的选择解耦。
引言
学习率调度深刻影响神经网络训练速度和最终性能,然而实践者通常选择一个固定的函数形式,如线性或余弦衰减,并仅调整峰值和阶段持续时间等少数几个参数。对于调度形状应如何适应给定工作负载,缺乏系统性的理解。作者通过定义几个参数化的调度族来解决这一空白,包括可以模仿和扩展标准形状的灵活样条曲线,并通过在计算量轻的代理任务上开发搜索方法来发现近似最优的调度。实验表明,即使调度族未强制要求,最佳调度也会自然地包含预热和逐步衰减,并且权重衰减等超参数显著改变了理想形状,为面向工作负载的调度设计迈出了具体的一步。
方法
作者将学习率调度定义为一个函数 s(t)=α⋅ϕ(t/T),其中 α 是基础学习率,T 是训练时长,ϕ 是调度形状。为了约束搜索空间,他们参数化了多种调度形状族,包括 CONSTANT、COSINE、GENERALIZED COSINE、SQUARE-ROOT DECAY、GENERALIZED REX、TWO-POINT SPLINE、TWO-POINT LINEAR 和 SMOOTH NON-MONOTONIC。这些族中的大多数都包含线性预热,而 SMOOTH NON-MONOTONIC 族则允许完全通用的双控制点样条,不保证单调衰减。
为了在这些族中找到近似最优的调度,作者采用了一个两步搜索流程。他们将参数化形状 ϕθ 和基础学习率 α 的最优训练损失定义为: J(θ,α):=r∼Rmedian[min0≤t≤TLtrain(r)(θ,α,t)] 其中中位数取自随机性分布 R(例如,权重初始化)。最优形状参数 θ⋆ 通过同时最小化 θ 和 α 上的目标来找到。
搜索步骤将调度参数与基础学习率解耦。随机采样调度参数,对于每种设置,作者在对数间隔的网格上扫描 16 个基础学习率。使用多个 PRNG 种子生成并评分数千个形状。在初始搜索之后,评估步骤使用 100 个种子重新训练前 k 个调度,以计算鲁棒的中位数分数和置信区间。
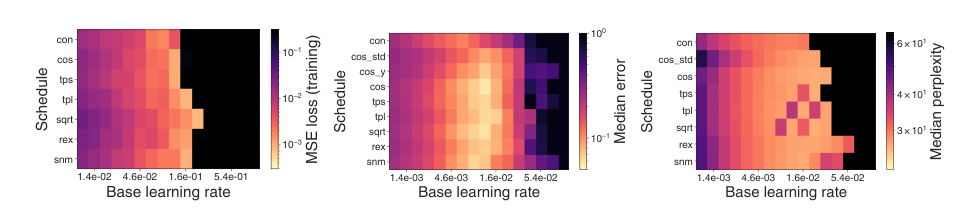
实验结果表明,基础学习率是实现良好性能的最关键因素。一旦调度同时包含预热和衰减,调整基础学习率比调整具体的调度形状超参数能带来更大的收益。此外,搜索一致揭示,预热和单调衰减是深度学习中有效学习率调度的基本特征,即使使用像 SMOOTH NON-MONOTONIC 这样在设计上不强制这些特性的灵活族也是如此。
实验
评估在三个小规模、优化受限的工作负载上比较了学习率调度族:合成线性回归、CIFAR-10 图像分类和 WikiText-103 语言建模,使用随机搜索找到近似最优形状。线性回归测试针对一个无预热、平坦轮廓且在后期急剧衰减的真实最优解验证了搜索方法,而深度学习工作负载一致要求预热后跟随单调衰减,其中基础学习率是最关键的超参数。更灵活的调度族比标准余弦衰减产生了适度但有意义的改进,尽管 Smooth Non-Monotonic 族被证明难以优化。工作负载变化实验表明,权重衰减强度有意义地改变了最优衰减时机,而改变训练时长则导致更平缓的衰减。总体而言,该研究确认预热和衰减是根本上有效的,证明任务最优调度在凸和非凸设置之间存在显著差异,并为实际的调度调整和搜索提供了指导。
该研究评估了学习率调度族,发现在神经网络工作负载(CIFAR-10、WIKITEXT-103)上,具有预热和灵活衰减形状的调度比恒定或标准余弦衰减产生了微小但显著的改进。最优调度形状随工作负载变化,凸优化(线性回归)的原理并未迁移到深度学习,在深度学习中预热被证明是有益的。在灵活选项中,广义余弦捕获了显著增益,而两点样条和线性族提供了足够的灵活性来近似近似最优调度。在 CIFAR-10 和 WIKITEXT-103 上,学习率预热在不同族和工作负载变化中都是有益的,这与预热无用的线性回归形成对比。具有可调指数的广义余弦衰减在 CIFAR-10 上比标准余弦取得了显著增益,并优于具有非零最终学习率的余弦变体。像两点线性和两点样条这样的灵活族可以捕获非常接近最优的调度,但即使更灵活族中顶级成员之间的差异也很小,表明进一步增加复杂性带来的回报递减。改变衰减形状的能力在训练和测试指标上都带来了微小但显著的改进,鼓励在调整资源可用时考虑超越流行的余弦衰减的调度。

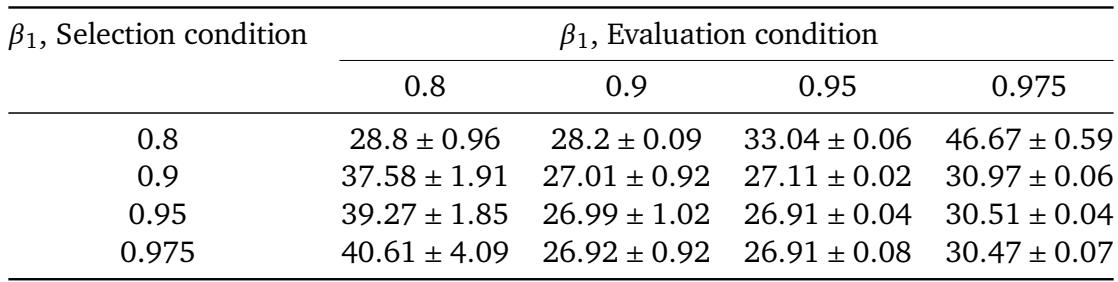
在 CIFAR-10 上使用 AdamW 搜索学习率调度时,搜索阶段使用较高的动量 (β₁) 通常会产生更好的调度。然而,在找到调度后,评估时使用较低的动量可以进一步降低训练误差,表明搜索后降低动量能提升性能。在调度选择阶段使用较大的 β₁,在相同 β₁ 下评估时,一致降低训练误差。对于固定的选择 β₁,评估时降低 β₁ 通常会产生更低的误差,最佳组合是在 β₁=0.95 找到的调度并在 β₁=0.8 评估。
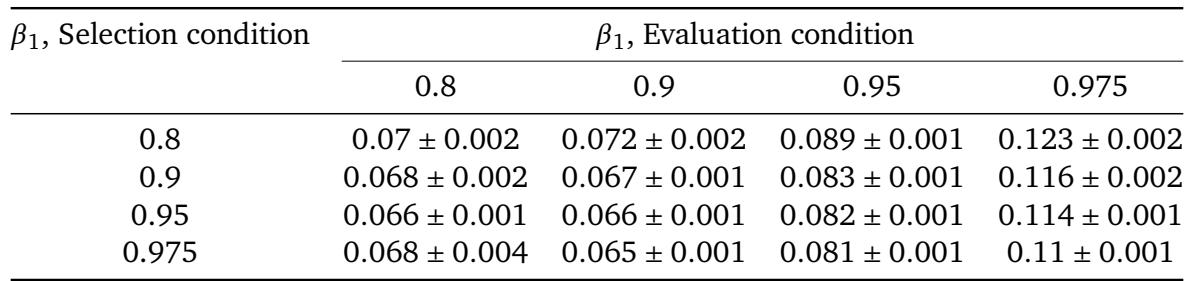
在调度搜索和评估期间动量参数 β1 的选择显著影响 WIKITEXT-103 的困惑度。使用较高 β1 值发现的调度在训练运行也使用类似高 β1 时往往表现良好,但在低动量评估下性能急剧恶化,尤其是在 β1=0.8 时。当调度在 β1=0.95 搜索和评估时,达到最低困惑度。使用较高 β1 值选择的调度在 β1 为 0.9、0.95 或 0.975 评估时通常产生较低的困惑度,但这一趋势在评估 β1=0.8 时反转,此时较高的选择 β1 导致更差的性能。在 β1=0.8 评估调度产生了最宽的困惑度范围和最大的标准差,表明低动量训练运行中存在高不确定性。
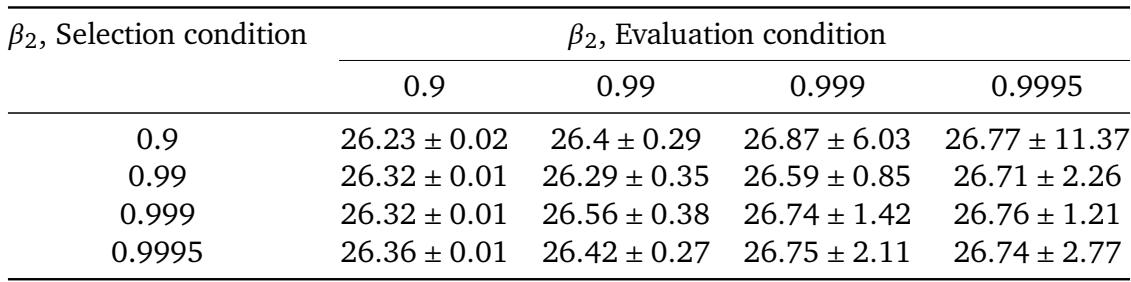
在选择学习率调度时,调度选择期间使用的动量参数 β2 强烈影响最终性能。使用高 β2 (0.9995) 选择调度并使用低 β2 (0.9) 评估,在 CIFAR-10 上产生了最低的中位训练误差,优于所有匹配的选择-评估对。在所有评估 β2 值下,较高的选择 β2 一致降低误差,表明使用更高动量调整调度可以发现即使在部署时使用较低动量也能良好泛化的调度。最佳组合使用选择 β2=0.9995 和评估 β2=0.9,实现了比任何选择和评估 β2 匹配的设置都更低的误差。对于每个固定的评估 β2,增加选择 β2 会降低中位训练误差,其中从 β2=0.9 移动到 β2=0.9995 时降幅最大。当使用低 β2 选择调度时,误差随着评估 β2 增加而急剧上升,而使用高 β2 选择则使误差在所有评估条件下保持相对较低。
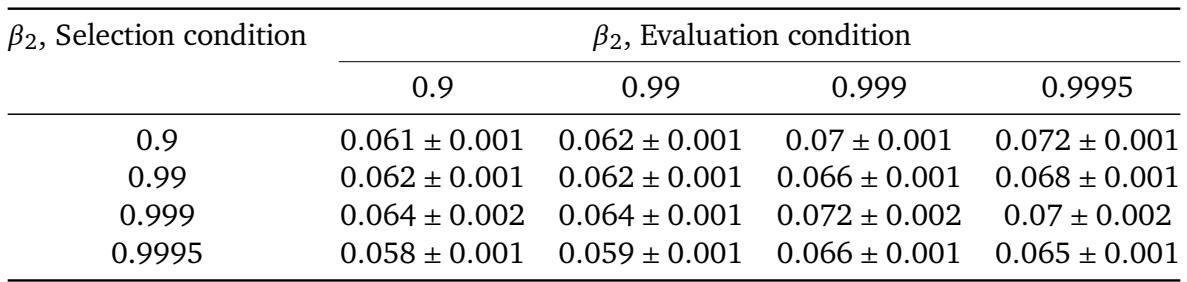
在调整学习率调度时,调度选择期间 Adam 的 β₂ 选择会影响所得困惑度的质量和稳定性。使用较高的 β₂ 选择调度降低了中位困惑度,但最佳整体性能是通过采用以 β₂=0.9995 优化的调度并以 β₂=0.9 评估来实现的。在选择期间使用低 β₂ 会引入大量噪声,如评估 β₂ 下困惑度值的广泛分布所示。使用较高 β₂ 的调度选择降低了中位困惑度,而在 β₂=0.9 选择则产生了最宽的变异和较大的标准差,确认了调整期间低 β₂ 会增加噪声。最佳困惑度结果出现在使用 β₂=0.9995 选择的调度以 β₂=0.9 评估时,突显了不匹配的选择和评估设置的好处。
在 CIFAR-10 和 WIKITEXT-103 上使用 AdamW,该研究评估了学习率调度族以及调度搜索期间动量参数的影响。包含预热和可调衰减形状的灵活调度(例如,广义余弦、两点样条)比恒定或标准余弦产生了微小但显著的改进,最优形状随工作负载变化。关于动量的实验表明,使用较高的 β1 和 β2 值选择调度,然后在较低动量下评估(β1=0.8, β2=0.9),可实现最佳性能,并且高 β2 选择提供了对抗低动量噪声的鲁棒性。总体而言,调整调度形状和利用动量不匹配提供了实际收益,鼓励在资源允许时探索超越标准余弦调度的方案。