Command Palette
Search for a command to run...
叙事织者:基于多模态条件控制的长程视觉一致性研究
叙事织者:基于多模态条件控制的长程视觉一致性研究
Zhengjian Yao Yongzhi Li Xinyuan Gao Quan Chen Peng Jiang Yanye Lu
摘要
我们提出了 Narrative Weaver,这是一种新颖的框架,旨在解决生成式人工智能中的一个根本性挑战:实现多模态可控、长程且一致的视频内容生成。尽管现有模型在生成高保真短片方面表现卓越,但在处理长序列时难以保持叙事连贯性和视觉一致性,这成为其在电影制作和电商广告等现实应用中面临的关键局限。Narrative Weaver 首次提出了一个整体解决方案,无缝整合了三项核心能力:细粒度控制、自动叙事规划以及长程一致性。在架构设计上,我们采用多模态大语言模型(MLLM)进行高层级叙事规划,并引入一种新颖的细粒度控制模块,该模块配备动态 Memory Bank(记忆库),以防止视觉漂移(visual drift)。为支持实际部署,我们开发了一种渐进式、多阶段训练策略,该策略高效利用现有的预训练模型,即使在训练数据有限的情况下也能达到最先进的性能。鉴于目前缺乏合适的评估基准,我们构建并发布了一个针对此类任务的综合性数据集——电商广告视频故事板数据集(E-commerce Advertising Video Storyboard Dataset, EAVSD)。该数据集包含超过 330K 张高质量图像,并附有丰富的叙事标注信息。
一句话总结
Narrative Weaver 解决了多模态可控、长程且一致的视觉内容生成挑战,它整合了用于叙事规划的多模态大型语言模型(Multimodal Large Language Model)与动态 Memory Bank 以防止视觉漂移,采用渐进式多阶段训练策略,并发布 E-commerce Advertising Video Storyboard Dataset 作为电影制作和电商广告的首个综合数据集。
核心贡献
- 本工作提出了 Narrative Weaver,这是一个旨在实现扩展序列中多模态可控且一致的视觉内容生成的框架。该架构结合了用于高层规划的多模态大型语言模型(MLLM)与动态 Memory Bank 模块以防止视觉漂移。
- 开发了一种渐进式多阶段训练策略,以有效利用现有的预训练模型进行实际部署。即使在训练数据有限的情况下,该方法也能实现最先进的性能。
- 为解决缺乏合适评估基准的问题,构建并发布了 E-commerce Advertising Video Storyboard Dataset (EAVSD),包含超过 330K 张高质量图像。该资源提供了丰富的叙事注释,专门设计用于条件图像到多帧生成任务。
引言
生成式 AI 模型目前擅长生成高保真短内容,但在扩展序列中难以保持叙事连贯性和视觉一致性,这是电影制作和电商广告等现实应用的关键局限。现有方法通常仅依赖文本条件,或未能将后续帧锚定在初始视觉输入上,导致角色和背景随时间漂移。为弥合这一差距,作者提出了 Narrative Weaver,这是一个整合了用于自动叙事规划的多模态大型语言模型与动态 Memory Bank 以确保长程视觉一致性的框架。此外,还引入了渐进式多阶段训练策略,并发布 E-commerce Advertising Video Storyboard Dataset,以解决可控多模态生成缺乏合适评估基准的稀缺问题。
数据集
作者利用三个主要数据集进行训练和评估,详情如下:
-
E-commerce Advertising Video Storyboard Dataset (EAVSD)
- 组成: 本专有数据集包含 36K 个样本,总计约 330K 张高质量图像,专为条件图像到多帧生成设计。
- 结构: 每个实例将初始条件(由产品图像和文本指令组成)与包含叙事计划和故事板图像的目标输出配对。
- 生成管道: 专有电商文本由 Qwen3-30B-A3B 处理以生成详细提示。参考图像使用 Qwen-Image 创建,随后通过 Flux.1-kontext 进行关键帧合成以确保跨帧一致性。
- 过滤: 自动化 Qwen2.5-VL-32B 模型过滤数据以移除 AI 伪影(如畸形肢体),并验证实体保留和风格一致性。
- 提示策略: 指令避免具体的服装或身份细节以保持主体一致性,转而关注动作、环境和相机角度。
-
CoMM Dataset
- 用途: 用于评估自主叙事生成能力。
- 选择: 作者选择了 Instructables 和 WikiHow 子集以解决原始汇编中的数据不平衡问题。
- 处理: 样本限制为 16 张图像和 12 个步骤元素。训练数据通过随机截断序列创建,产生约 170K 个延续样本和 150K 个基于问题的样本。
- 分辨率: 所有图像重缩放至 512×512 像素以与原始基准保持一致。
-
CI-VID Dataset
- 用途: 用于视频叙事生成任务。
- 处理: 从每个视频片段中选择第五帧作为锚点。
- 输入: 第一帧使用剪辑标题,后续帧依赖剪辑间过渡描述。
- 分辨率: 数据以 480p (480×854) 处理,保留原始宽高比。
方法
作者提出了 Narrative Weaver,这是一个混合框架,整合了自回归(AR)规划与基于扩散的视觉生成以创建连贯的视觉叙事。如下面的框架概述所示:
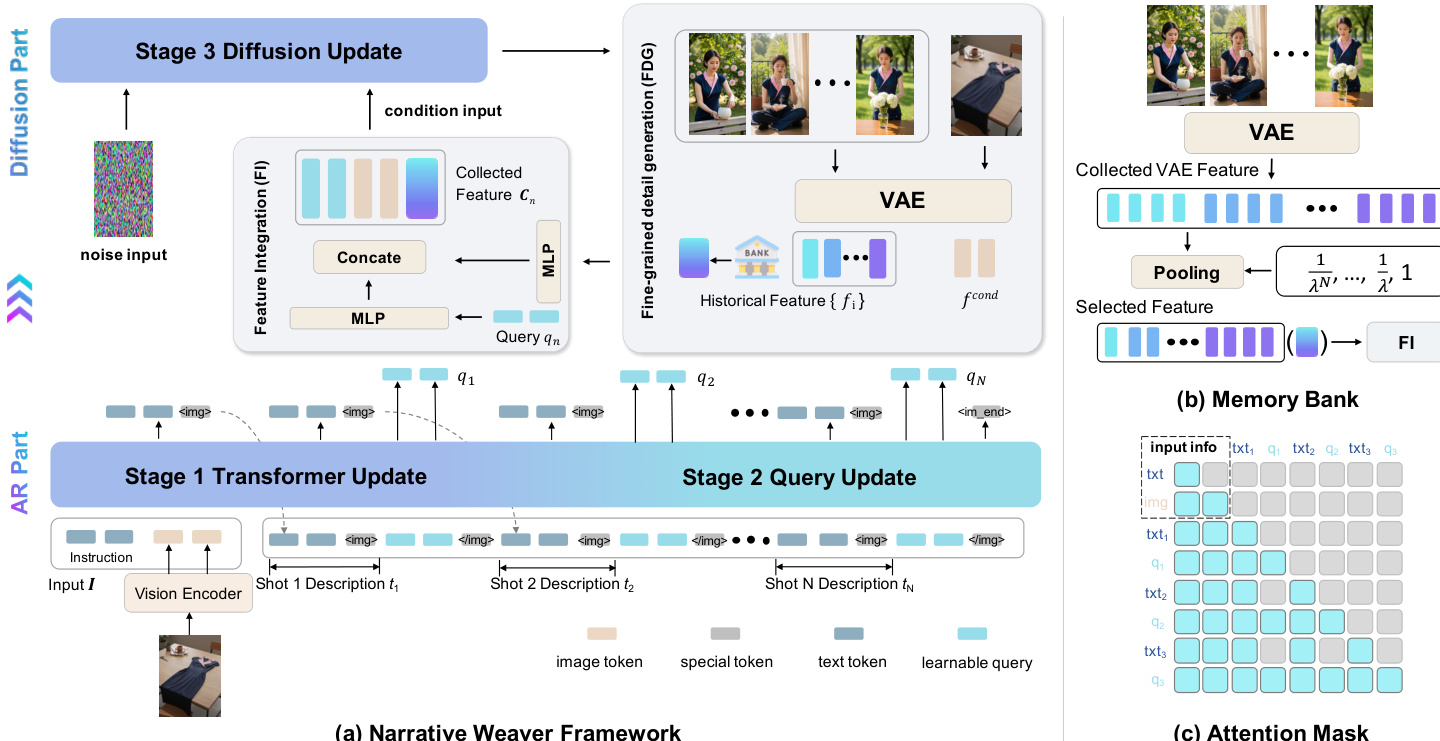
系统分为 AR 部分和扩散部分。AR 组件基于多模态大型语言模型(MLLM),处理输入 I(条件图像和指令)以显式规划文本形式的叙事逻辑 T,并将历史多模态信息压缩为可学习查询 Q。这些查询作为扩散模型的紧凑高层表示。为确保生成序列的时间稳定性,框架采用 Memory Bank。该模块缓存先前生成图像的 VAE 特征。为管理计算成本并强调近期历史,特征通过带有衰减因子 λ 的平均池化进行系列衰减。这种几何衰减确保聚合记忆特征的总序列长度有界。第 n 个关键帧的综合条件信号 Cn 由当前可学习查询 qn、输入条件图像的 VAE 特征 fcond 以及来自 Memory Bank 的池化特征连接而成。
对于多模态交互,作者提出了一种动态因果注意力掩码。在此配置中,每个可学习查询 qn 可访问完整多模态上下文(输入 I、叙事文本和先前查询),确保视觉连贯性。相比之下,文本 tokens 受因果机制约束以促进稳健的叙事规划。特殊 tokens <img> 和 </img> 括起查询序列,使模型能够学习视觉输出的时机。
训练过程遵循渐进式多阶段策略,旨在解耦叙事规划与视觉生成。
- 阶段 1(叙事规划): 训练 MLLM 制定叙事计划,而 ViT 编码器保持冻结。目标是最小化真实文本 tokens 的负对数似然。
- 阶段 2(语义连贯视觉生成): 此阶段训练可学习查询以及连接 MLLM 与扩散模型的投影器。涉及在大规模文本 - 图像对上预训练,随后在高分辨率样本上微调,以使查询与扩散模型的语义空间对齐。
- 阶段 3(细粒度对齐): 完全训练扩散模型以实现细粒度视觉间一致性。条件信号通过来自 VAE 分支和 Memory Bank 的低级视觉特征进行增强。
为支持此框架,作者利用结构化的数据构建管道,涉及特定提示模板以生成高质量训练数据。参考下面的提示模板:

该模板指导生成具有强故事性和营销吸引力的广告镜头描述,确保生成内容突出产品并符合特定风格要求,如电影级照明和详细场景描述。系统设计用于处理长程图像和视频生成,利用 MLLM 中介的效率,将计算复杂度从与图像数量的二次增长降低为线性增长。
实验
评估系统地评估了 Narrative Weaver 在长程视觉一致性、自主叙事规划以及电商场景实用方面的表现。定性和定量结果表明,该模型在保持稳健的角色身份和风格连贯性的同时,有效利用交叉剪辑和反向镜头等电影惯例。此外,用户研究和消融分析证实,该框架通过平衡语义对齐与细粒度控制实现了卓越性能,为连贯视觉叙事提供了可扩展的解决方案。
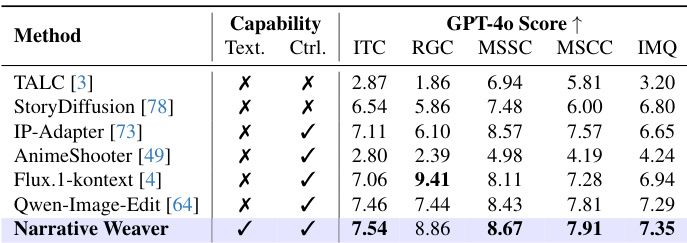
作者使用 GPT-4o 评分在视觉生成的五个关键维度上评估 Narrative Weaver 与多种基线方法。结果表明,所提方法在大多数类别中实现了最先进的性能,特别是在维持多镜头的风格和内容一致性方面表现出色。虽然专用编辑模型显示出更高的参考保真度,但 Narrative Weaver 在文本 - 图像对齐和图像质量方面展现出更优的整体平衡。Narrative Weaver 在图像 - 文本一致性、多镜头风格一致性、多镜头内容一致性和图像质量方面得分最高。所提方法支持文本生成和控制能力,而大多数基线方法缺乏其中一个或两个功能。专用编辑模型在参考保真度方面优于所提方法,但在维持多镜头风格和内容一致性方面不足。
该表比较了所提方法与普通基线在不同生成关键帧数量下的计算成本。结果表明,虽然基线方法随着序列长度增长面临计算需求的急剧增加,但所提方法保持了更平坦且更高效的增长曲线。所提方法展现出显著更好的可扩展性,即使在关键帧数量较高时也能保持较低的计算成本。相比之下,普通实现在帧数增加时显示出资源使用的快速增长。对于更长的序列,效率优势尤为明显,此时基线成本远高于所提方法。

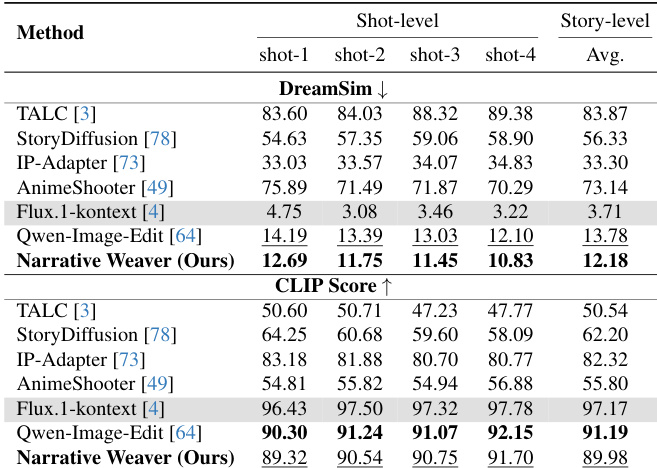
该表使用 DreamSim 和 CLIP Score 指标评估跨多个镜头级别的一致性关键帧生成。Narrative Weaver 优于 TALC 和 StoryDiffusion 等视频生成基线,显示出一致性与动态叙事之间的优越平衡。虽然专用编辑模型实现了更高的指标分数,但它们通常遭受静态伪影的影响,而所提方法成功保持了序列间的一致性。Narrative Weaver 在一致性和文本 - 图像对齐指标方面均超越了多场景视频生成基线。专用编辑模型实现了更高的数值分数,但往往产生缺乏动态叙事进展的静态结果。所提方法在连续镜头中保持了强劲性能,展示了有效的长程一致性保留。
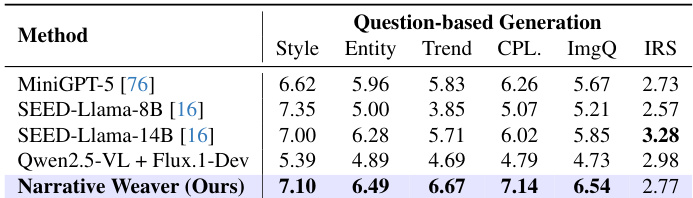
作者通过基于问题的生成任务评估自主叙事规划能力,将方法与各种开源基线进行比较。所提方法在大多数评估维度上表现出卓越性能,特别是在一致性指标和叙事完整性方面。所提方法在风格、实体和趋势一致性方面得分最高。在叙事完整性和图像质量评估中观察到卓越性能。该模型有效地在多个维度上平衡了叙事规划与视觉保真度。
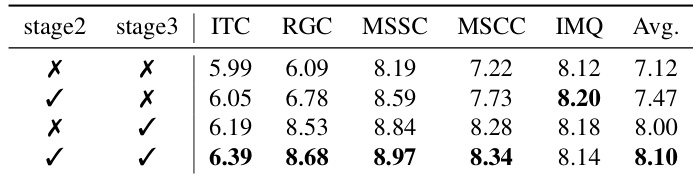
消融研究评估了阶段 2 和阶段 3 训练对模型整体性能的具体贡献。结果表明,包含这两个阶段的完整配置在所有测量维度上均产生卓越性能。排除任一阶段都会导致分数下降,证实了语义连贯性和视觉一致性训练对于方法的有效性至关重要。结合阶段 2 和阶段 3 的完整模型实现了最高平均分和大多数一致性指标的最高结果。与没有阶段 3 的变体相比,包含阶段 3 显著提高了多镜头风格和内容一致性。缺少任一训练阶段都会导致整体性能降低,验证了完整多阶段管道的必要性。
作者使用 GPT-4o 评分和一致性指标评估 Narrative Weaver 与多种基线,以评估视觉生成和自主叙事规划。结果表明,所提方法在风格和内容一致性方面实现了最先进的性能,并具有卓越的可扩展性,同时通过维持动态叙事进展优于专用编辑模型。消融研究证实,多阶段训练管道对于平衡语义连贯性与视觉保真度是必要的。