Command Palette
Search for a command to run...
vLLM Hook v0:用于在 vLLM 上编程模型内部结构的插件
vLLM Hook v0:用于在 vLLM 上编程模型内部结构的插件
Ching-Yun Ko Pin-Yu Chen
使用 vLLM 部署 Gemma-3-27B-IT
摘要
现代人工智能(AI)模型被部署在推理引擎上,以优化运行时效率和资源分配,特别是针对基于 Transformer 的大语言模型(LLMs)。vLLM 项目是一个重要的开源库,用于支持模型服务和推理。然而,当前 vLLM 的实现限制了已部署模型内部状态的可编程性。这阻碍了流行测试时模型对齐和增强方法的使用。例如,它阻止了基于注意力模式检测对抗性提示,或基于激活引导调整模型响应。为了弥补这一关键空白,我们提出了 vLLM Hook,这是一个开源插件,旨在实现对 vLLM 模型内部状态的可编程控制。基于指定要捕获哪些内部状态的配置文件,vLLM Hook 提供了与 vLLM 的无缝集成,并支持两个基本功能:被动编程和主动编程。对于被动编程,vLLM Hook 探测选定的内部状态以供后续分析,同时保持模型生成过程完整无损。对于主动编程,vLLM Hook 通过修改选定的内部状态,实现对模型生成的高效干预。
一句话总结
作者提出了 vLLM Hook,这是一个面向 vLLM 推理引擎的开源插件,能够通过被动探测和主动干预实现对模型内部状态的可配置编程,从而突破现有的可编程性限制,为大语言模型支持测试时对齐、对抗性提示词检测以及激活值引导。
核心贡献
- vLLM Hook 是一款开源插件,支持基于配置的 vLLM 推理引擎内部状态编程,直接解决了限制测试时模型对齐与增强方法的瓶颈。
- 该系统实现了两种核心编程模式:用于非侵入式状态探测且不影响生成的被动编程,以及通过修改选定内部状态实现实时干预的主动编程。
- 三项实际演示验证了该插件,展示了提示词注入检测、增强检索增强检索以及激活值引导,以验证其在运行时模型监控与调整中的实用性。
引言
现代大语言模型依赖 vLLM 等推理引擎来优化部署效率与资源分配。然而,当前 vLLM 的实现限制了推理过程中对模型内部状态的访问与修改,从而阻碍了诸如对抗性提示词检测和激活值引导等关键的测试时对齐技术。为了解决这一限制,作者开发了 vLLM Hook,这是一款通过简单配置文件实现内部状态精确编程的开源插件。该框架支持用于实时分析的被动探测以及用于直接修改模型输出的主动干预,有效解锁了增强检索增强生成与安全提示词监控等实际应用。
数据集
- 作者在提交的文本中未提供数据集描述。
- 数据集构成与来源:内容仅概述了 GitHub 贡献工作流并引用了仓库 URL。未包含任何数据来源或构成细节。
- 各子集的关键信息:文本未提供关于子集规模、来源或过滤标准的信息。
- 论文的数据使用方式:未描述训练集划分、混合比例或数据处理步骤。
- 裁剪策略、元数据构建或其他处理细节:所提供材料中均未提及。
方法
vLLM-Hook 框架被设计为一个模块化插件系统,支持在 vLLM 推理流水线中同时进行被动与主动编程。其核心通过两个主要抽象概念运行:worker 与 analyzer,二者由定义各组件行为的配置文件进行编排。worker 直接集成至 vLLM 运行时环境中,负责在推理过程中捕获模型内部状态(被动编程)或实时修改模型行为(主动编程)。该集成通过继承标准 vLLM GPU worker 并重写 load_model 方法来实现,从而在选定的模型模块上安装 PyTorch forward hooks。这些 hooks 按照配置指定应用于特定的注意力层与注意力头,允许在前向传播过程中进行针对性观察或干预。
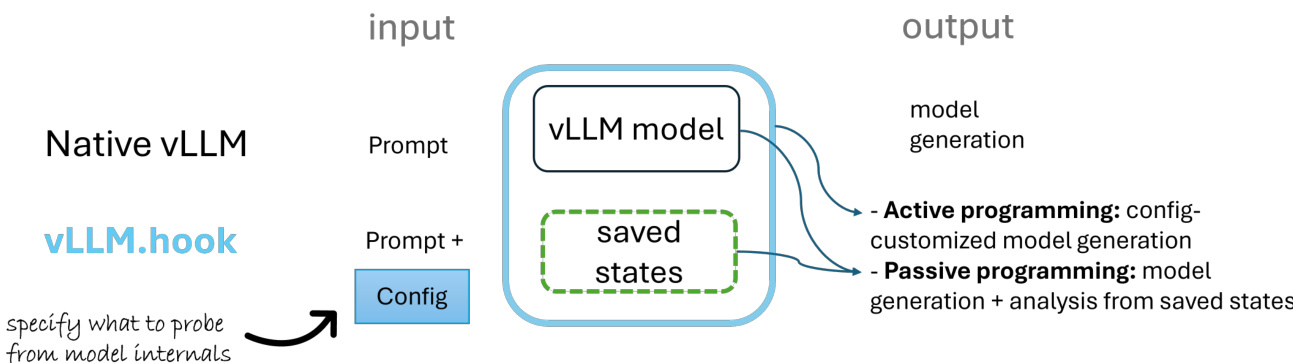
如图下方所示,该框架以接收输入提示词的原生 vLLM 系统为起点。用户通过配置文件指定需要探测的组件,该文件随后用于引导 vLLM-Hook 系统。系统在推理过程中捕获内部状态,这些状态可保存以供后续分析,或用于启用主动编程(例如模型引导或定制化生成)。配置文件定义了模型标识、关键层与注意力头,以及信号捕获模式(例如是收集所有 token 的数据还是仅收集最后一个 token 的数据)。这些配置通过轻量级注册表与 HookLLM 包装类进行管理,后者负责初始化 LLM 实例并与核心 vLLM 引擎进行交互。
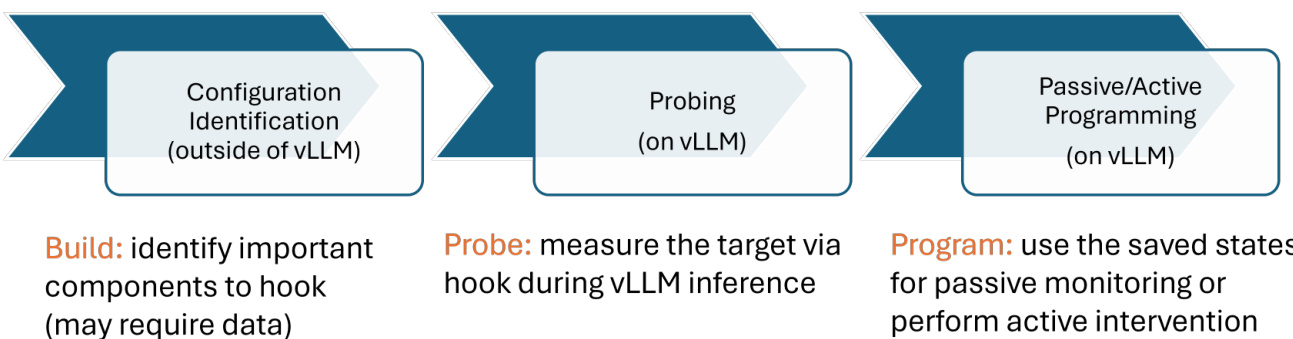
工作流程分为三个阶段:配置识别、探测与编程。在配置阶段,用户确定需要探测的组件,必要时可借助外部数据。在探测阶段,worker 通过 hooks 在推理过程中测量目标模型内部状态,捕获相关的激活值或注意力权重。最终阶段涉及编程,保存的状态被用于被动监控(例如评估提示词注入风险)或主动干预(例如引导模型行为)。该流程在框架图中得到展示,其中 vLLM-Hook 插件包裹 vLLM 系统,并与 LLMEngine 进行交互,后者负责管理输入处理、调度、模型执行与输出处理。
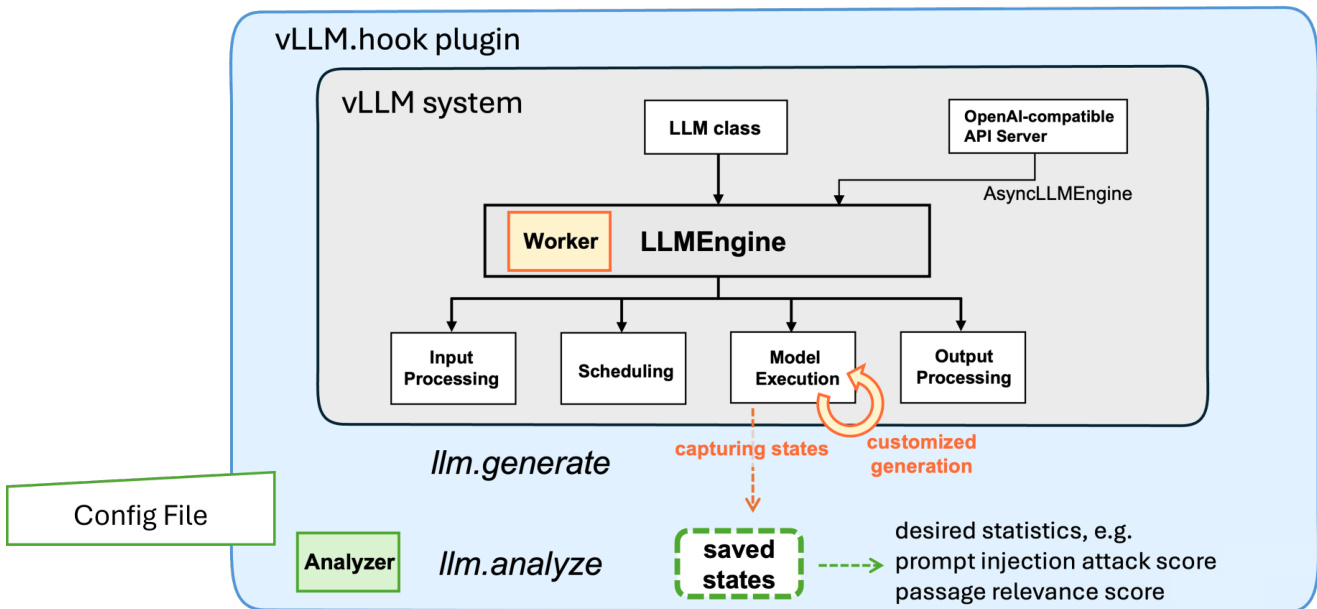
analyzer 组件在推理完成后对保存的状态进行操作。它通过唯一的运行标识符检索缓存数据,并重新组合所需的统计信息(如注意力权重),以计算提示词注入攻击得分或文档相关性得分等指标。该功能通过模块化的 analyzer 类实现,该类接收 hook 目录与层到注意力头的映射关系作为输入,并处理缓存数据以计算特定指标。用户可通过 llm.analyze 方法触发 analyzer,从而在不修改核心模型或运行时的情况下执行推理后分析。这种模块化设计使框架能够在同一编排系统中组合不同的 worker 与 analyzer,从而支持包括安全监控、模型引导与选择性检索在内的广泛应用。