Command Palette
Search for a command to run...
FlashAttention-4:面向非对称硬件扩展的算法与内核流水协同设计
FlashAttention-4:面向非对称硬件扩展的算法与内核流水协同设计
Ted Zadouri Markus Hoehnerbach Jay Shah Timmy Liu Vijay Thakkar Tri Dao
摘要
注意力机制作为普遍存在的 Transformer 架构的核心组件,已成为大语言模型(LLM)和长上下文应用的性能瓶颈。虽然 FlashAttention-3 通过异步执行和 Warp 专精(warp specialization)技术针对 Hopper GPU 优化了注意力机制,但其主要面向 H100 架构。当前,人工智能行业正迅速转向部署基于 Blackwell 的系统(如 B200 和 GB200),由于硬件扩展的非对称性,这些系统展现出截然不同的性能特征:张量核心(Tensor Core)吞吐量翻倍,而其他功能单元(如共享内存带宽、指数运算单元)的扩展较慢或保持不变。为解决 Blackwell GPU 上这些动态变化的瓶颈,我们开发了一系列技术:(1)重新设计计算流水线,以充分利用完全异步的 MMA(矩阵乘法与累加)操作和更大的 Tile 尺寸;(2)采用软件模拟的指数运算和条件 Softmax 重缩放(rescaling),从而减少非矩阵乘法操作的开销;(3)利用张量内存和 2-CTA MMA 模式,以减少反向传播过程中的共享内存流量和原子加法(atomic adds)操作。实验表明,我们的方法 FlashAttention-4 在 B200 GPU 上(使用 BF16 精度)相比 cuDNN 9.13 最高提速 1.3 倍,相比 Triton 最高提速 2.7 倍,峰值性能达到 1613 TFLOPs/s(利用率高达 71%)。
一句话总结
FlashAttention-4 是针对 Blackwell GPU 非对称硬件扩展的算法与内核流水线协同设计,它采用了更大分块尺寸的全异步 MMA 操作、软件模拟的指数函数和条件 softmax 重新缩放,以及张量内存与 2-CTA MMA 模式来减少共享内存流量和原子加法,在 B200 GPU 上使用 BF16 时,比 cuDNN 9.13 快 1.3 倍,比 Triton 快 2.7 倍,达到 1613 TFLOPs/s(71% 利用率)。
核心贡献
- 重新设计的流水线利用全异步 MMA 操作和更大的分块尺寸,应对 Blackwell GPU 的非对称扩展(张量核心吞吐量翻倍,而其他功能单元扩展较慢)。
- 软件模拟的指数函数和条件 softmax 重新缩放减少了非矩阵乘法操作,缓解了由较慢的指数功能单元带来的瓶颈。
- 反向传播利用张量内存和 2-CTA MMA 模式来减少共享内存流量和原子加法;这些创新共同使 FLASHATTENTION-4 达到 1613 TFLOPs/s(71% 利用率),在 B200 上使用 BF16 时,比 cuDNN 9.13 快 1.3 倍,比 Triton 快 2.7 倍。
引言
注意力机制是大型语言模型和长上下文 Transformer 的关键性能瓶颈。先前的工作 FlashAttention-3 引入了异步执行和 warp 特化来优化 Hopper (H100) GPU 上的注意力,但这些技术无法直接应对新的 Blackwell 架构。在 B200 和 GB200 等 Blackwell GPU 中,张量核心吞吐量翻倍,而共享内存带宽和指数单元的扩展速度要慢得多,从而造成非对称硬件瓶颈,使早期算法停滞。作者引入了 FlashAttention-4,它针对这种新平衡协同设计算法和内核流水线。他们提出了重新设计的流水线,利用全异步矩阵乘累加操作和更大的分块尺寸,软件模拟指数和条件 softmax 重新缩放以减少非矩阵乘法工作,并在反向传播中使用张量内存与 2-CTA MMA 模式来减少共享内存流量和原子加法,在 B200 上实现了比 cuDNN 高 1.3 倍、比 Triton 高 2.7 倍的加速。
方法
作者提出了 FlashAttention-4,一种专为 NVIDIA Blackwell 架构(B200 和 GB200)协同设计的算法与内核实现。与前几代不同,之前的瓶颈是矩阵乘法单元,而 Blackwell 呈现出非对称扩展:张量核心吞吐量相比 Hopper 翻倍,而共享内存带宽和指数单元吞吐量基本保持不变。因此,softmax 等非矩阵乘法操作和共享内存流量成为主要瓶颈。FlashAttention-4 通过重新设计的流水线、软件模拟的指数函数和新颖的内存管理策略来应对这些变化。
作者首先对注意力前向传播进行了 roofline 分析,发现对于典型的分块配置,共享内存流量和指数运算占据了主要执行时间。为了缓解这一问题,他们引入了一种新的流水线,最大化张量核心操作与 softmax 计算的重叠。
如下图所示:
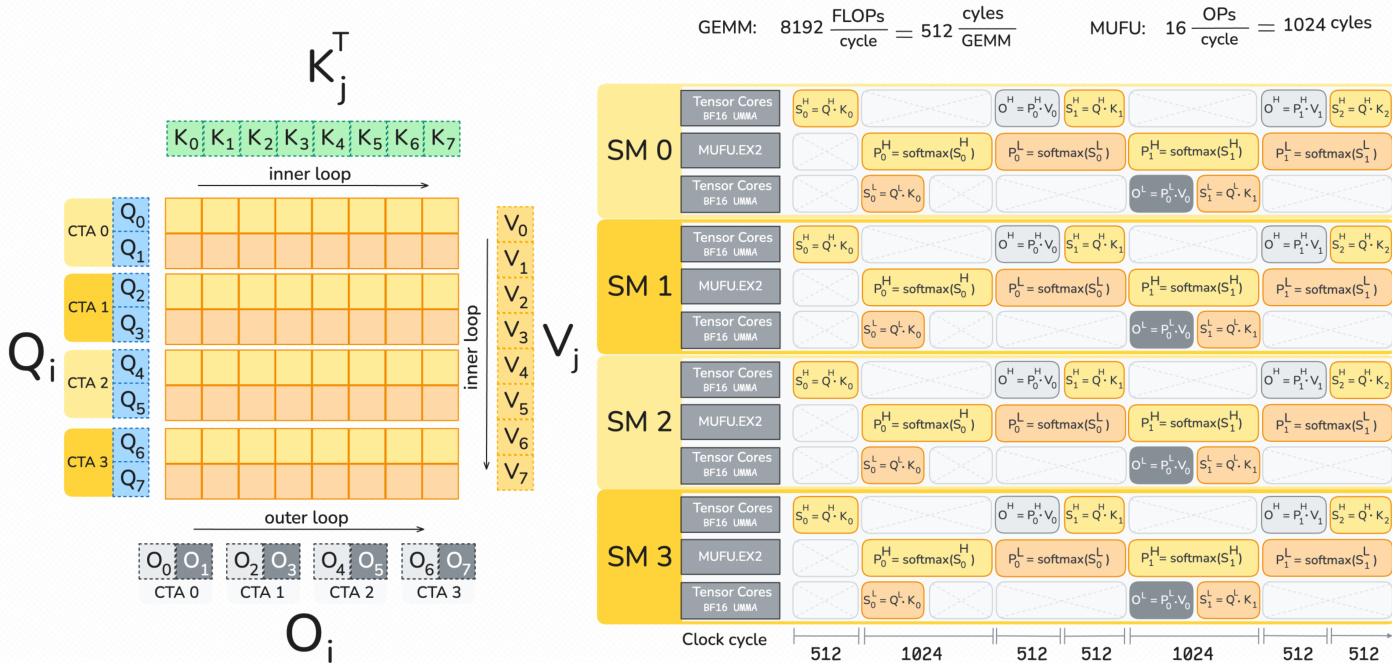
作者利用了一种乒乓调度,每个线程块计算两个输出分块。当一个分块进行张量核心操作时,另一个分块计算 softmax。与 Hopper 不同,Hopper 中累加器保存在寄存器中,而 Blackwell 的张量核心直接将输出写入张量内存(TMEM)。这使得作者可以将输出的重新缩放解耦到一个单独的修正 warpgroup,将其从关键路径中移出。该流水线使用两个 warpgroup 进行 softmax 计算,并显式同步以避免在指数计算阶段发生重叠。
为了进一步解决指数单元瓶颈,作者使用浮点 FMA 单元实现了指数函数的软件模拟。由于多功能单元(MUFU)的吞吐量明显低于张量核心,这种模拟分散了工作负载。他们使用多项式逼近来处理指数的分数部分,并使用位操作处理整数部分。为了平衡吞吐量和寄存器压力,这种模拟仅应用于每个 softmax 行中的一部分元素,其余部分通过硬件 MUFU 计算。
此外,作者引入了条件 softmax 重新缩放。在标准的 FlashAttention 中,每当找到新的最大值时,中间输出就会被重新缩放。如果当前最大值与之前最大值之差低于阈值 τ,FlashAttention-4 就跳过这一重新缩放步骤。这减少了不必要的向量乘法,同时通过最终归一化步骤保持数值精度。
对于反向传播,roofline 分析表明共享内存流量是主要瓶颈,超过了 MMA 计算时间。反向传播涉及五个矩阵乘累加(MMA)操作。
如下图所示:
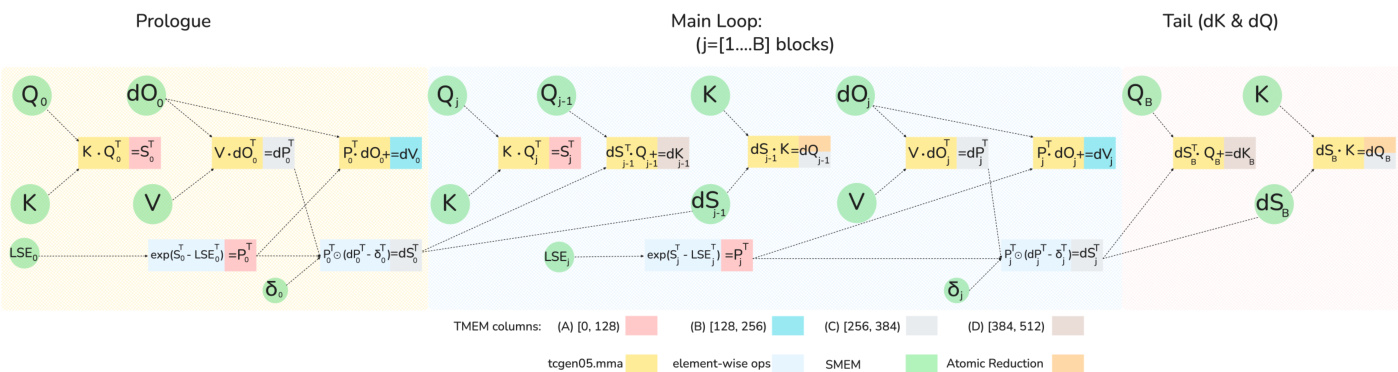
作者设计了一种新的软件流水线,使这些 MMA 操作与逐元素计算重叠。通过利用 TMEM 存储中间结果,可以隐藏 softmax 计算的延迟。具体来说,前一次迭代的 dQ 和 dK MMA 操作与当前迭代的计算重叠。
为了进一步减少共享内存流量,作者利用了 Blackwell 的 2-CTA MMA 模式。在该模式下,一对协作线程阵列(CTA)协同执行单个 MMA,从而可以划分累加器和操作数。
如下图所示:
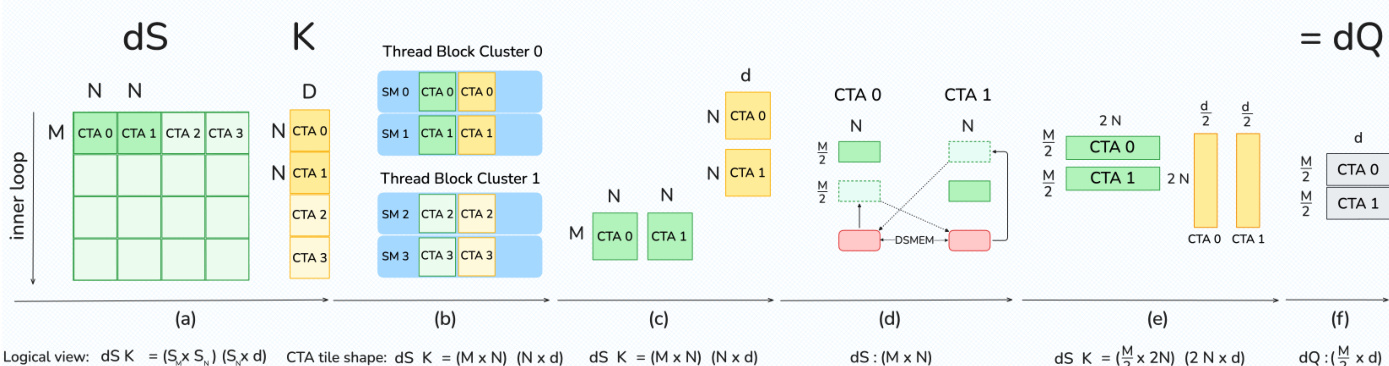
对于 dQ 步骤,CTA 对使用分布式共享内存(DSMEM)交换一半的 dS 分块。这允许每个 CTA 形成更大的操作数,并运行具有双倍归约维度的 CTA 对 UMMA。这种重构不仅将操作数 B 的共享内存流量减半,还将所需的全局原子归约次数减半,因为每个 CTA 只写入分块的一半。
为了确保强化学习应用的可复现性,作者还提供了确定性执行模式。该模式使用信号量锁将全局归约串行化,确保 CTA 按预先定义的顺序写入公共的 dQ 分块。他们采用最短处理时间优先调度和 CTA swizzling 来最小化这种串行化导致的停滞。
作者实现了最长处理时间优先(LPT)调度,以处理因果掩码和可变序列长度情况下的负载不平衡。对于因果掩码,他们将批次作为最外层维度进行处理,并在头上进行 swizzle 以优化 L2 缓存使用。对于可变序列长度,预处理内核根据最大执行时间对批次进行排序,以实施 LPT 顺序。
最后,FlashAttention-4 完全用嵌入 Python 的 CuTe-DSL 实现。这种方法提供了与 C++ 模板相当的完整表达能力,同时通过即时编译(JIT)实现了更快的编译时间,降低了研究人员原型化新注意力变体的门槛。
实验
该评估在 NVIDIA B200 GPU 上使用 BF16 输入,在多种序列长度和头维度下对 FLASHATTENTION-4 进行基准测试,并与 cuDNN、Triton 等库进行比较。前向传播始终优于所有基线,因果掩码场景下的提升尤其显著,这得益于最长处理时间优先调度器,而反向传播(包括确定性变体)也提供了显著的加速。FLASHATTENTION-4 达到了 GPU 理论峰值吞吐量的很大一部分,并且其许多优化已被集成到更新的 cuDNN 版本中。
作者通过分析与 FP64 基线相比的相对误差,比较了各种近似技术和数据类型的数值精度。对于 BF16 精度,所有方法的误差率一致,表明精度格式是限制因素,而非近似算法。对于 FP32 精度,更高阶的多项式逼近能显著降低误差,最终匹配硬件实现的精度。BF16 比较显示所有方法的误差率一致,与理想转换极限对齐。更高的多项式阶数能大幅降低 FP32 输入的相对误差。硬件特殊函数单元和 5 阶逼近在 FP32 上实现了相当的高精度。

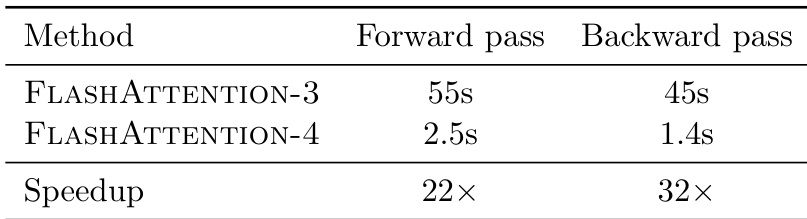
作者比较了 FlashAttention-4 与 FlashAttention-3 的运行时间,以评估效率提升。结果表明,新版本大幅减少了前向和后向传播的执行时间,相比前身实现了巨大的加速。FlashAttention-4 在前向传播中显著优于 FlashAttention-3,仅需原来时间的一小部分。后向传播显示出更大的相对加速,表明梯度计算非常高效。与先前版本相比,所提出的方法在两个计算阶段都提供了显著的性能提升。
作者在 B200 GPU 上将 FlashAttention-4 与 cuDNN、Triton 等基线进行基准测试,证明在中等和长序列上有一致的加速效果。资源分析表明,随着配置规模的增加,对 MMA 计算、共享内存和指数单元的需求成比例增加。FlashAttention-4 优于 cuDNN 和 Triton 基线,在因果掩码场景下增益更大。MMA 计算、共享内存和指数单元的资源使用量随配置规模线性增长。优化的后向传播设计在长序列长度上提供了一致的加速。

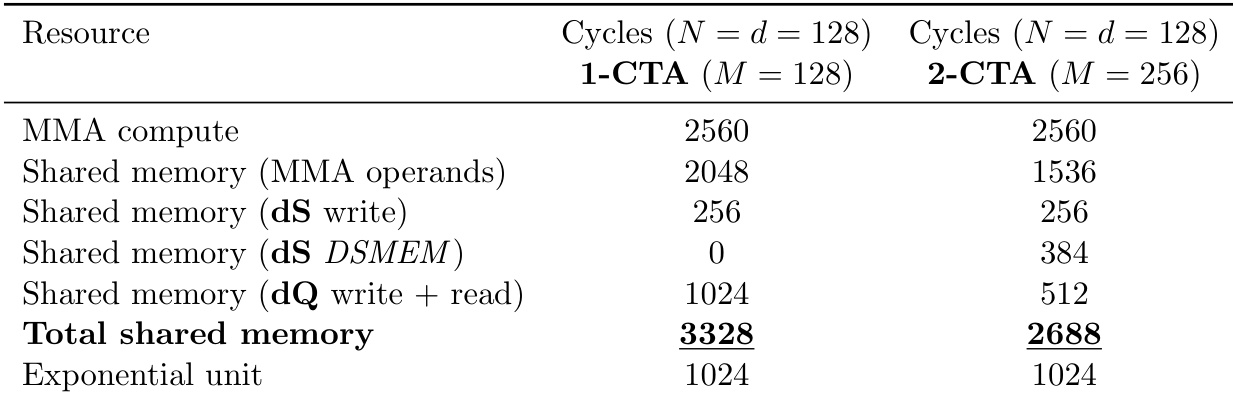
作者比较了 1-CTA 和 2-CTA 配置的资源周期,以展示其后向传播实现的效率。结果表明,2-CTA 方法减少了所需的总共享内存周期,主要是通过降低 MMA 操作数和 dQ 操作所需的周期。虽然 2-CTA 方法为 DSMEM 引入了一些开销,但总体共享内存成本更低,而计算周期保持不变。2-CTA 配置的总共享内存周期数低于 1-CTA 基线。两种配置中 MMA 和指数单元的计算周期保持不变。MMA 操作数和 dQ 操作周期的减少抵消了 2-CTA 设置中新增的 DSMEM 周期。
数值精度实验表明,BF16 精度在所有方法上一致地限制了近似误差,而 FP32 受益于更高阶多项式,达到与硬件特殊函数相当的精度。性能基准测试表明,FlashAttention-4 相比 FlashAttention-3 实现了显著加速,并在 B200 GPU 上优于 cuDNN 和 Triton,在因果掩码场景下增益尤为显著。资源分析揭示,2-CTA 后向传播配置通过降低 MMA 操作数和 dQ 操作成本减少了共享内存周期,而计算周期保持不变。