Command Palette
Search for a command to run...
Phi-4-reasoning-vision-15B 技术报告
Phi-4-reasoning-vision-15B 技术报告
Jyoti Aneja Michael Harrison Neel Joshi Tyler LaBonte John Langford Eduardo Salinas
摘要
我们推出了 Phi-4-reasoning-vision-15B,这是一款紧凑型的开放权重多模态推理模型,并分享了指导其研发的动机、设计选择、实验结果及经验总结。我们的目标是为研究社区提供构建更小、更高效的多模态推理模型的实用见解,并将这些经验的成果转化为一个开放权重模型;该模型在通用视觉与语言任务上表现优异,在科学与数学推理及用户界面理解方面尤为突出。我们的主要贡献在于证明:通过精心的架构选择与严格的数据筛选,较小规模的开放权重多模态模型能够在显著减少训练与推理阶段的计算资源及 token 消耗的情况下,实现具有竞争力的性能。最显著的改进源于系统性的数据过滤、错误修正与合成数据增强,这再次印证了数据质量仍是提升模型性能的首要杠杆。系统的消融实验表明,高分辨率与动态分辨率编码器能够带来一致的性能提升,因为准确的感知是实现高质量推理的前提。最后,通过混合推理与非推理数据,并引入显式的模式 token(mode tokens),单一模型得以在简单任务中快速给出直接答案,而在复杂问题上则执行链式思维(chain-of-thought)推理。
一句话总结
作者介绍了 Phi-4-reasoning-vision-15B,这是一款紧凑的开源权重多模态推理模型,通过涉及系统过滤、错误纠正和合成增强的严格数据策划,结合高分辨率和动态分辨率编码器,以及带有显式模式标记的推理与非推理数据的混合,实现了具有竞争力的性能,同时显著减少了训练和推理时的计算量及 token 消耗。该模型在科学和数学推理以及用户界面理解方面表现出色,能够针对简单任务提供快速直接答案,针对复杂问题提供思维链推理。
核心贡献
- 这项工作介绍了 Phi-4-reasoning-vision-15B,这是一款紧凑的开源权重多模态模型,在资源受限的环境中依然高效,同时擅长科学推理和理解用户界面。该模型在通用视觉语言任务上取得了具有竞争力的性能,无需依赖超大的训练数据集或过多的推理时 token 生成。
- 系统过滤、错误纠正和合成增强被强调为小型架构中模型性能的主要杠杆。系统消融实验进一步证明,高分辨率和动态分辨率编码器通过建立准确的感知作为高质量推理的前提,带来了持续的提升。
- 带有显式模式标记的推理与非推理数据的混合训练,使单一模型能够针对简单任务提供快速直接答案,同时针对复杂问题提供思维链推理。仅使用 2000 亿 token 进行训练,与需要超过 1 万亿 token 的模型相比,推动了精度与计算成本之间权衡的帕累托前沿。
引言
视觉语言模型正日益趋向于巨大的参数量,这推高了训练成本和推理延迟,限制了它们在交互式或资源受限环境中的可用性。现有方法通常需要过多的计算资源,并且难以平衡结构化推理的需求与简单感知任务所需的效率。作者介绍了 Phi-4-reasoning-vision-15B,这是一款紧凑的开源权重多模态模型,通过显著减少训练 token 和推理成本,实现了具有竞争力的性能。他们的工作表明,严格的数据策划以及带有显式模式标记的推理与非推理数据的混合,允许在不牺牲复杂科学或数学问题精度的情况下实现高效的任务感知推理。
数据集
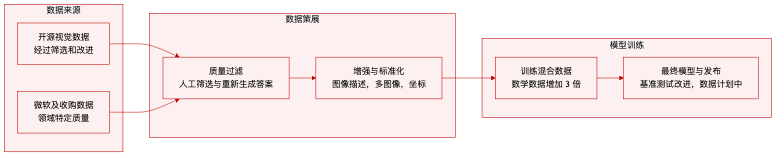
- 数据集构成: 作者主要利用了过滤后的开源视觉语言数据集,辅以来自微软团队的高质量领域特定数据和针对性获取的数据。
- 质量过滤: 样本经过人工筛选,将数据分类为优秀质量、问题正确但答案错误或低质量图像等类别。优秀数据在保留的同时进行了轻微格式修复,而答案错误的记录则使用 GPT-4o 和 o4-mini 结合验证管道重新生成。图像根本存在缺陷或错误率高的数据集被排除。
- 数据增强:
- 数学和科学图像除了原始问答对之外,还配上了详细的说明式描述。
- 指令遵循数据与领域特定的真实数据对合并,以服务于多个目的。
- 使用混乱的说明或匹配任务创建多图像记录,以提高图像注意力。
- 使用连续截图生成计算机使用和机器人场景的“发生了什么变化”数据。
- 过于复杂的提示被替换为人类提示,以增加模型的鲁棒性。
- 训练混合: 团队在训练期间调整了数据比例,发现将数学数据增加 3 倍同时保持计算机使用数据不变,提高了数学和计算机使用基准测试的性能。
- 坐标处理: 所有空间坐标都相对于图像尺寸归一化到 [0.0, 1.0] 范围内,以确保不同分辨率之间的一致性。
- 未来可用性: 团队计划在未来几个月内发布部分训练数据,同时发布模型权重和微调代码。
方法
作者采用中期融合架构以平衡表达力和效率,避免了早期融合相关的重型计算成本,同时保持了比晚期融合方法更强的跨模态基础。该系统集成了视觉编码器、跨模态投影器和大型语言模型骨干网络。
具体来说,该模型利用 SigLIP-2 视觉编码器将输入图像处理为视觉 token。这些 token 随后通过实现为多层感知机 (MLP) 的跨模态投影器映射到语言嵌入空间。同时,文本输入由 Phi-4-Reasoning 编码器处理。生成的视觉和文本嵌入被交错为语言对齐的 token 嵌入,然后输入到 Phi-4-Reasoning 语言模型中进行生成。
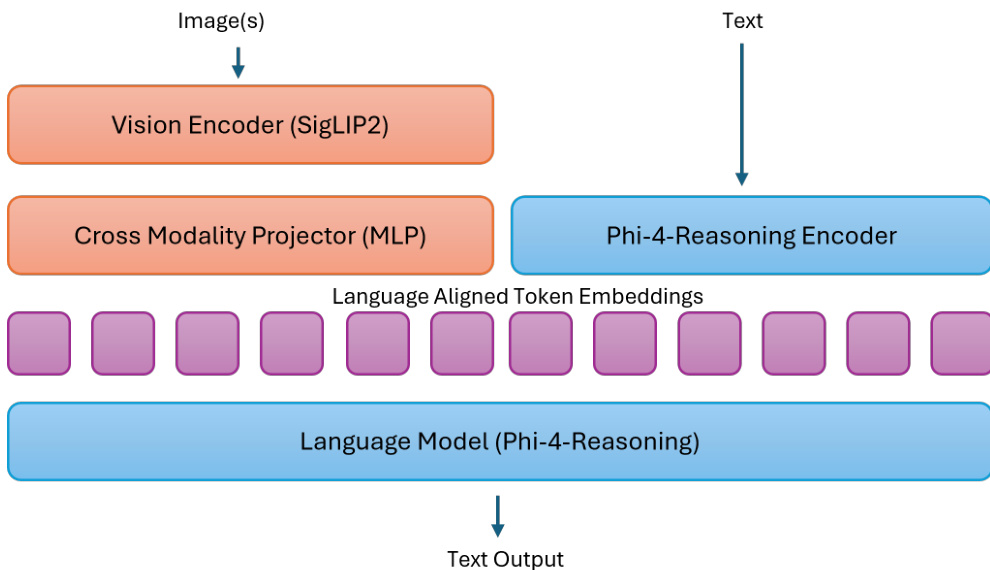
如框架图所示,该流程允许模型利用在万亿 token 上预训练的组件,保持推理成本可控。作者选择了动态分辨率视觉编码器配置,以最大化高分辨率任务的 grounding 性能,利用多达 3600 个视觉 token 来近似原生 HD 720p 分辨率。
训练过程遵循三阶段方案。第一阶段专注于 MLP 预训练,仅训练投影器以将 SigLIP-2 的视觉特征空间与语言模型的文本嵌入空间对齐,同时保持其他组件冻结。第二阶段涉及全指令微调,其中所有模型组件解冻,并在包含视觉问答和 OCR 等任务的大规模单图像视觉指令数据混合上进行训练。最后阶段专门针对长上下文理解、多图像推理和安全对齐进行模型专业化。
为了处理推理能力,模型采用混合推理和非推理方法。训练数据包括带有显式推理轨迹的样本,这些样本由 标记标记,用于数学和科学等复杂领域,以及带有 标记的直接响应样本,用于以感知为中心的任务。这种混合策略允许模型默认对简单查询进行直接推理,而在必要时调用结构化推理路径,从而平衡延迟和精度。
实验
使用开源框架在多个基准测试上的评估验证了该模型在保持数学和科学推理强大性能的同时,平衡精度和推理成本的能力。改变数据比例的实验表明,单一模型可以在推理领域实现统一的优越性,同时不损害数学或计算机使用任务的性能。安全评估进一步通过自动化红队测试确认了与负责任 AI 原则的一致性,尽管在最佳推理模式切换和与更大系统相比的细粒度视觉细节方面仍存在局限性。
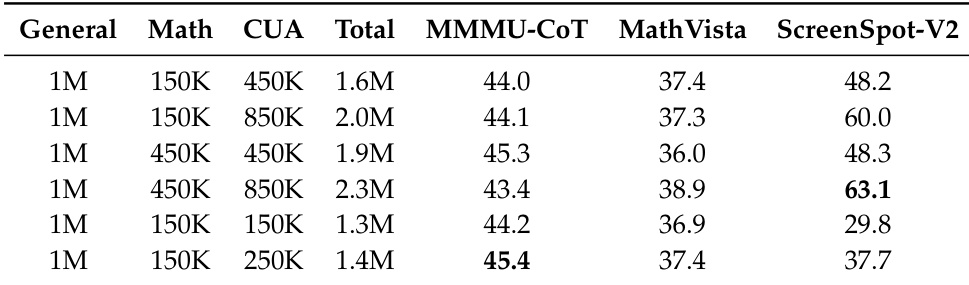
该研究调查了不同比例的数学和计算机使用数据如何影响模型在不同基准测试上的性能。结果表明,增加计算机使用数据显著提高了 ScreenSpot-V2 基准测试的性能,而数学性能保持稳定或略有提升。总体而言,数据表明单一模型可以在不同的推理领域实现强大且统一的表现,而无需显著权衡。ScreenSpot-V2 性能随计算机使用数据量的增加而显著提高。数学性能未因添加更多计算机使用数据而受到负面影响。更高的总数据量通常与改进的基准测试分数相关。
作者在包括数学和计算机使用在内的各种视觉语言基准测试上评估了该模型。结果表明,与其他开源权重模型相比,该模型表现强劲,在推理和直接响应模式之间具有平衡的能力。在图表和数学理解方面显著优于指令变体。在 MMMU 等复杂推理任务上取得了具有竞争力的结果。在计算机屏幕任务上展示了强大的 grounding 能力。
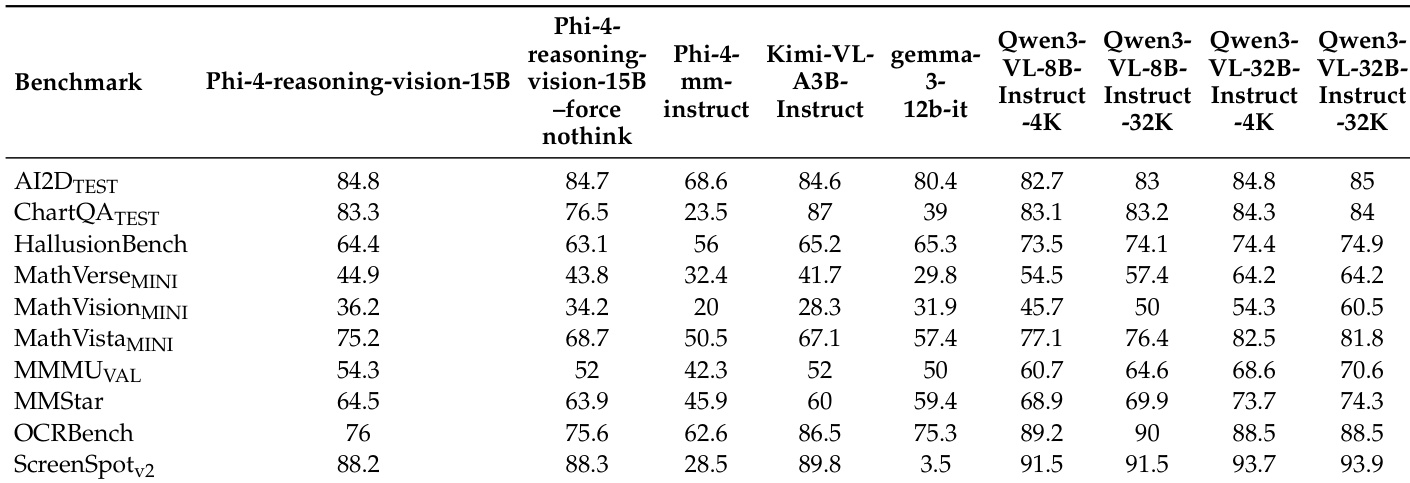
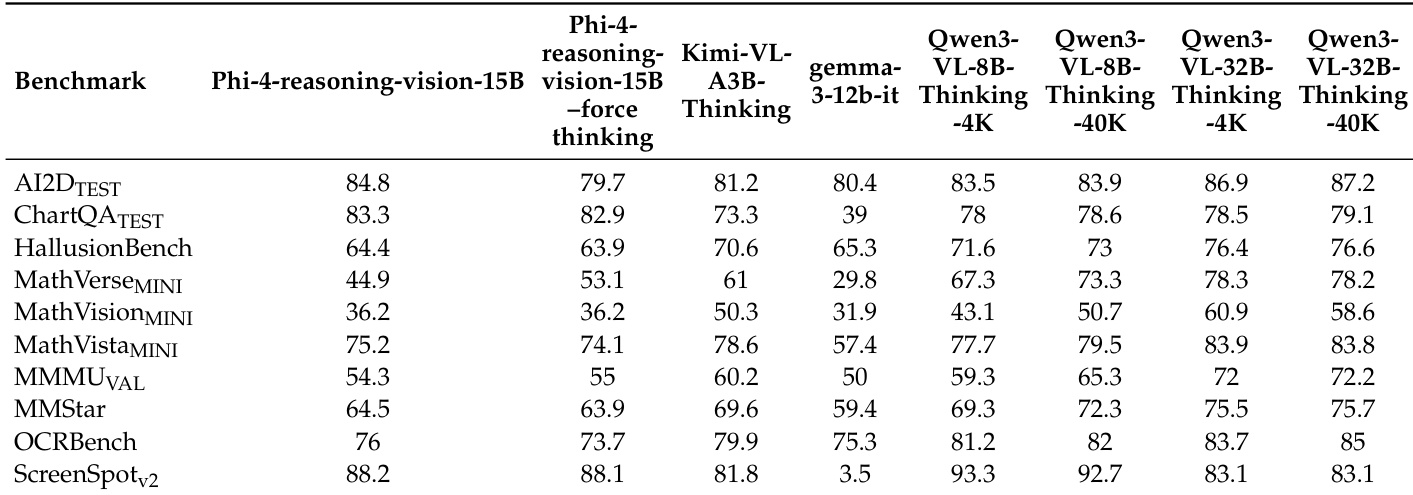
作者提出了 Phi-4-reasoning-vision-15B 与各种开源权重模型在不同基准测试上的比较评估。结果表明,该模型实现了具有竞争力的精度,特别是在屏幕交互和图表解释任务方面表现出色。数据表明,默认混合推理模式通常提供稳健的性能,往往优于强制思考配置。模型在屏幕定位和图表解释任务上表现出强大的性能。与强制思考相比,默认混合推理行为通常产生更好或相等的结果。在特定领域,精度与显著更大的参数模型相比仍具有竞争力。
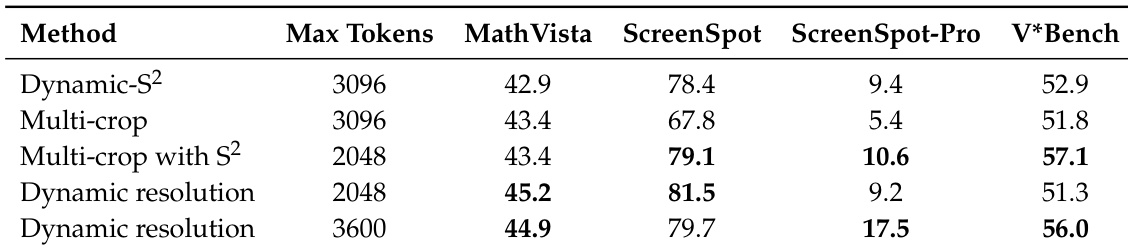
该研究比较了各种分辨率和 token 分配方法,以优化数学和计算机使用任务的性能。动态分辨率方法始终显示出强劲的结果,特别是在针对特定基准测试调整 token 限制时。增加动态分辨率的 token 预算显著提高了 grounding 性能,同时保持了具有竞争力的数学推理分数。动态分辨率方法通常在数学和屏幕交互基准测试上优于多裁剪策略。增加动态分辨率的最大 token 数量显著提升了 grounding 任务的性能。带有 S2 的特定裁剪策略即使在较低的 token 预算下也能实现具有竞争力的结果。
本研究评估了视觉语言模型在不同基准测试上的表现,以评估数据构成、推理模式和输入分辨率策略的影响。结果表明,增加计算机使用数据增强了屏幕交互性能,同时不损害数学推理,而动态分辨率方法进一步优化了 grounding 能力。与更大的开源权重对应模型相比,该模型表现出具有竞争力的精度,特别是在使用默认混合推理模式进行图表解释和屏幕任务方面表现出色,表明它在各个领域实现了强大的统一性能。