Command Palette
Search for a command to run...
重新思考通用语音增强的训练目标、架构和数据质量
重新思考通用语音增强的训练目标、架构和数据质量
Szu-Wei Fu Rong Chao Xuesong Yang Sung-Feng Huang Ryandhimas E. Zezario Rauf Nasretdinov Ante Jukić Yu Tsao Yu-Chiang Frank Wang
摘要
通用语音增强(Universal Speech Enhancement, USE)旨在多样化退化条件下恢复语音质量,同时保持信号保真度。尽管近年来取得了一定进展,但在训练目标选择、失真-感知权衡(distortion-perception trade-off)以及数据策展(data curation)方面仍存在关键挑战,且尚未得到妥善解决。本文系统性地应对了上述三个被忽视的问题。首先,我们重新审视了将早期反射语音作为去混响目标的传统做法,并证明其可能导致感知质量及下游自动语音识别(ASR)性能下降。相反,我们展示了时移无混响干净语音(time-shifted anechoic clean speech)作为学习目标是更优的选择。其次,受失真-感知权衡理论的指导,我们提出了一种简单的两阶段框架,该框架能在给定感知质量水平下实现最小化失真。第三,我们分析了 USE 中训练数据规模与质量之间的权衡,揭示出在大型未策展语料库上进行训练会设定性能上限,因为模型难以消除细微的人工伪影。我们的方法在 URGENT 2025 非盲测数据集上取得了最先进(state-of-the-art)的性能,并展现出强大的语言无关泛化能力,使其成为提升文本转语音(TTS)训练数据质量的有效手段。模型权重可在以下链接下载:https://huggingface.co/nvidia/RE-USE。
一句话总结
NVIDIA、中央研究院与台湾大学共同推出 RE‑USE,一种通用语音增强方法,其采用时间偏移的无回声干净语音作为去混响目标,通过一个两阶段框架在给定感知质量水平下实现最小失真,并借助精选数据突破大规模未精选语料带来的性能天花板,在 URGENT 2025 非盲测试集上取得了当前最优结果,并且其语言无关的泛化能力可有效改善 TTS 训练数据。
核心贡献
- 对去混响学习目标的系统比较表明,时间偏移的无回声干净语音始终优于广泛使用的早期反射语音,在多种退化条件下同时提升了感知质量和下游 ASR 性能。
- 基于失真‑感知权衡理论,提出了一个两阶段框架:首先使用回归模型,然后利用残差生成式精炼器修正过度平滑的区域,且不产生幻觉,在 URGENT 2025 非盲测试集上取得当前最优结果。
- 对训练数据规模与质量的分析表明,大规模未精选语料会造成难以突破的性能天花板;而在最干净样本上进行严格筛选和微调,使模型能够去除细微伪影,并对未见过的真实场景具有更好的泛化能力。
引言
通用语音增强旨在恢复受多种退化(噪声、混响、削波、编解码伪影等)影响的语音,同时保持说话人身份和可懂度,这对鲁棒 ASR 和清理 TTS 训练数据等应用至关重要。此前的工作面临三个研究不充分的局限:使用早期反射语音作为去混响目标可能会损害感知质量;纯回归模型过度平滑而生成模型存在幻觉风险,由此导致持续的失真‑感知权衡;忽视训练数据质量,大规模未精选语料造成性能天花板并阻碍细微伪影的去除。作者针对这些瓶颈提出以下方案:证明时间偏移的无回声干净语音目标相比传统的早期反射目标能持续带来增益;提出一个具有理论支撑的两阶段框架,将回归模型与残差生成式精炼器相结合,在给定感知水平下实现最小失真;并证明严格的数据过滤和在精选干净子集上的微调是突破性能天花板的必要条件。该方法在 URGENT 2025 非盲测试集上取得了当前最优结果,并具有跨语言泛化能力,能够有效改善下游语音生成任务。
数据集
作者使用 URGENT 2025 挑战赛 Track 1 数据集,该数据集提供约 2500 小时的多条件语音、噪声样本和房间冲激响应。
-
组成与来源
- 语音来自 CommonVoice、DNS5、MLS、LibriTTS、VCTK、WSJ 和 EARS,涵盖五种语言(英语、德语、法语、西班牙语、中文)。
- 原始录音的采样率分布在 8 kHz 到 48 kHz 之间。
- 噪声和 RIR 素材也由挑战赛提供。
-
各子集的关键细节
- CommonVoice 是最大的子集(1300 小时),但因众包性质而质量最低。
- WSJ、EARS 和 VCTK 始终是三个最干净的语料库。
- 挑战赛组织者已使用语音活动检测和基于 DNSMOS 的过滤去除非语音和极嘈杂片段,但仍有许多样本存在可感知的背景噪声。
- 为进一步提高训练数据质量,作者对每条语音计算 VQScore。低于 VQScore 阈值的样本被丢弃;人工检查确认低分样本通常带有稳态背景噪声或非语音伪影。
- EARS 子集被保留为整体最干净的来源,尽管某些表现力强的录音(如耳语)获得了较低的 VQScore 评分,该子集后续用于专门的微调阶段。
-
数据在模型中的使用方式
- 经过质量过滤的语音与提供的噪声和 RIR 结合,模拟七种失真类型:加性噪声、混响、削波、带宽限制、编解码伪影、丢包和风噪。
- 训练混合信号遵循挑战赛的多条件数据仿真方案。
- 使用各语料库的官方验证分割,通过相同的仿真过程构建独立的验证集。
- 挑战赛的非盲测试集(1000 条语音,噪声和 RIR 来自未见过的来源)用于最终评估。
- 在多条件主训练之后,模型仅在高品质的 EARS 部分上进行微调。
-
裁剪、元数据及其他处理
- 除组织者的 VAD 预处理外,未提及额外的裁剪操作。
- 主要的质量控制步骤是基于 VQScore 的过滤,在单张 NVIDIA A100 GPU 上用不到八小时处理完全部 2500 小时数据。
- 对 VQScore 分布等元数据进行了分析,以确认不同来源之间的质量层次,但未描述进一步元数据的构建。
方法
作者提出了一种新颖的通用语音增强方法,以解决信号保真度和感知质量之间的根本性权衡。首先,他们明确了传统去混响目标的局限性。不同于使用早期反射语音或无偏移的无回声干净语音,作者提出使用时间偏移的无回声干净语音 s[n−n0] 作为学习目标。这一选择有效规避了因隐式估计直达波路径时间偏移 n0 所带来的对齐问题,从而在保真度和质量指标上均取得更优性能。
为解决保真度‑质量的困境,作者利用失真‑感知权衡理论,引入了一个精简的两阶段框架。如下图所示:
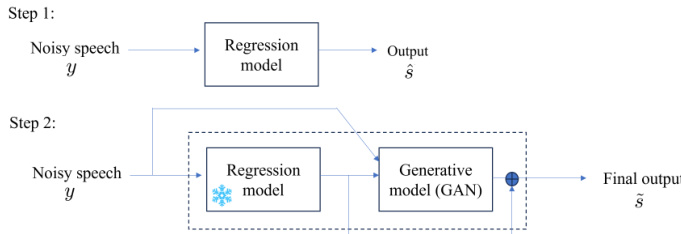
在第一步中,训练一个回归模型直至收敛,以估计后验均值,从而最大化保真度。训练完成后,冻结其权重。在第二步中,冻结的回归模型和带噪输入共同作为生成模型(具体为生成对抗网络)的条件输入。一个关键设计是回归模型输出与最终输出之间的残差连接。这迫使生成模型主要聚焦于修正那些与真实数据特性偏离的过度平滑区域,有效恢复感知细节,同时保留第一阶段所建立的语言内容和说话人身份。
在模型架构方面,作者采用与采样率无关的短时傅里叶变换,动态调整 FFT 窗口和跳跃大小,以确保在不同采样率下特征帧长保持一致。对于回归模型,采用 30 层的 USEMamba,该架构在频率和时间特征之间交替应用序列建模模块。在生成阶段,一个 6 层的 USEMamba 作为生成器。为适应不同频带间差异化的特征模式,作者提出了自适应多频带判别器。该判别器使用 5 层二维卷积网络在对应于输入采样率的特定子频带内进行局部特征提取,随后进行拼接并通过进一步的卷积层产生最终输出。所有组件均使用 AdamW 优化器进行训练。
实验
评估使用了一系列基于参考和非侵入式指标、主观听力测试,以及下游 ASR 和 TTS 评估。使用 0.65 的 VQScore 阈值过滤训练数据、采用时间偏移的无回声干净语音作为去混响目标,并在回归输出上施加 GAN 修正,这些操作持续提升了感知质量和保真度,同时避免了纯生成模型中常见的幻觉,显著优于早期反射目标和其他开源系统。主观评分结果与这些客观增益一致,且模型保持语言无关性,在最干净数据上的微调进一步提升了在未见语言上的性能。此外,使用该方法清理多语言 TTS 训练数据可大幅提高合成准确度和说话人相似度,展示了其释放带噪大规模语音资源价值的能力。
作者比较了使用时间偏移的无回声干净语音作为学习目标的语音增强模型与使用早期反射语音作为基线模型的性能,两者均结合了 GAN 修正。结果表明,在各项感知、可懂度和相似度指标上,偏移无回声方法始终优于早期反射基线。这说明使用无回声目标可以避免早期反射目标带来的输出质量下降。带 GAN 修正的偏移无回声目标在感知质量和可懂度得分上均优于早期反射基线。与早期反射方法相比,使用偏移无回声目标改善了语音表征和音素序列相似度。该方法在提升其他质量指标的同时,能够保持或略微提高说话人相似度。

作者将提出的语音增强模型与其他开源模型在不同采样率上进行比较,以评估相对优势。结果表明,在非侵入式、侵入式和任务相关指标上,所提方法始终优于基线。纯生成模型虽然能提高感知质量,但会带来幻觉,而所提方法则保持了高保真度和下游任务性能。与带噪输入和其他开源模型相比,所提方法在所有非侵入式质量指标上均获得最高得分。与出现字符准确率显著下降(表明存在幻觉)的生成式基线不同,所提模型提升了 ASR 性能。在 48 kHz 下,所提方法在所有评估指标上始终优于基于回归的基线,展现出卓越的整体增强质量。
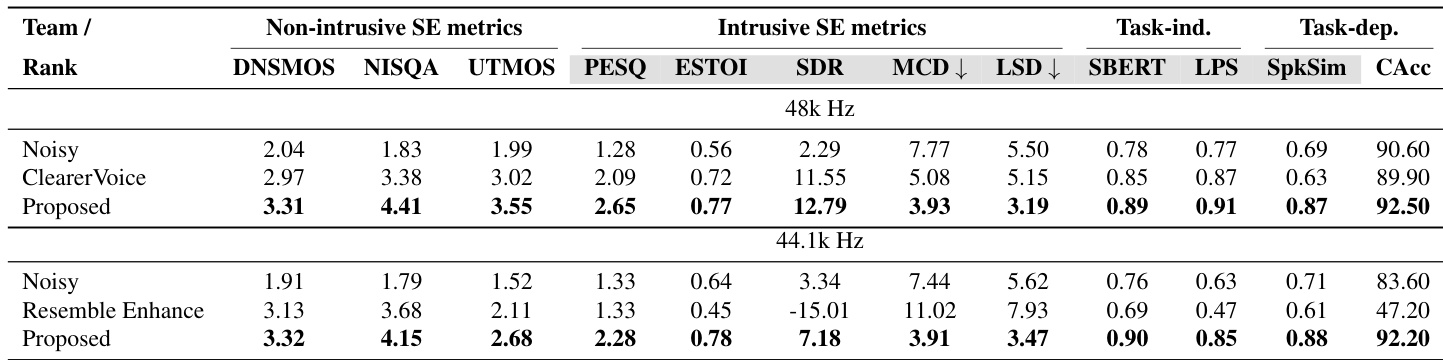
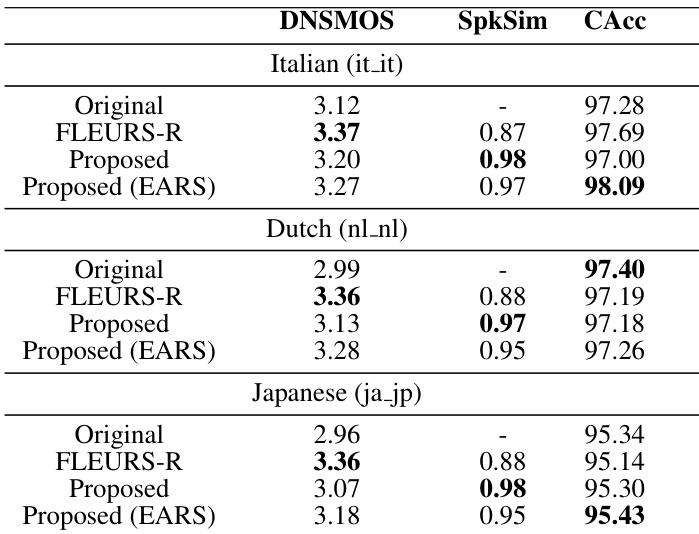
作者在 FLEURS 数据集的未见语言上评估其语音增强模型,以展示语言无关性。结果表明,尽管一种基线生成式恢复方法获得了最高的感知质量得分,但它显著损害了说话人身份的保持。相比之下,作者提出的方法,尤其是在高质量数据上微调后,保持了较高的说话人相似度,并且普遍提高了自动语音识别的准确率。基线恢复方法在所有语言上获得了最高的感知质量得分,但说话人相似度最低。所提方法在保持说话人身份方面远优于基线,取得了最高的说话人相似度得分。与原始音频相比,在高质量子集上微调模型可提升意大利语和日语的字符准确率。
作者将其语音增强模型应用于清理未见语言的零样本文本到语音系统的训练数据。结果表明,同时增强上下文提示和训练音频,相较于使用原始音频,可显著降低字符和词错误率。同时增强上下文和训练音频在所评估语言上获得了最低的字符和词错误率。与基线条件相比,仅增强训练音频即可显著降低错误率。增强上下文音频可以持续提升说话人相似度指标,并且往往能改善编解码距离得分。
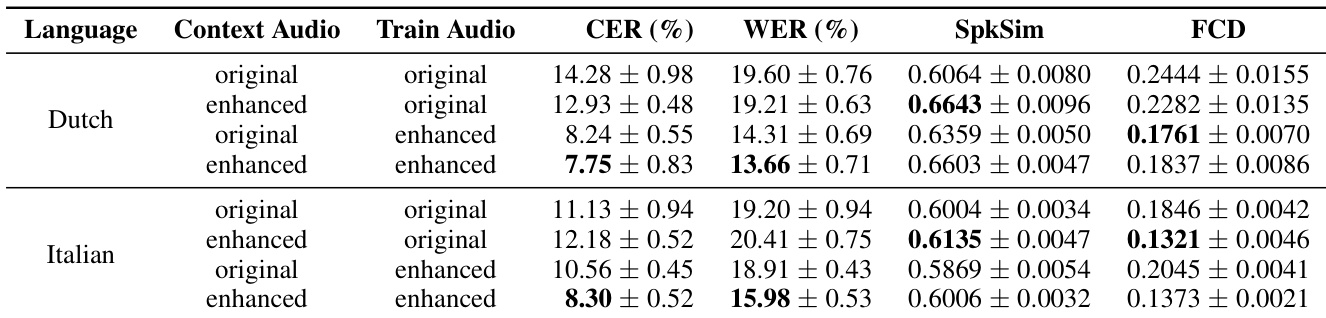
作者研究了其语音增强模型在未见语言的零样本文本到语音任务中清理训练数据的应用。结果表明,同时增强上下文和训练音频可显著提升下游 TTS 性能。具体而言,该方法降低了错误率和声学距离指标,同时保持了说话人相似度。同时增强上下文和训练音频可显著降低荷兰语和意大利语文本到语音模型的字符和词错误率。当模型对上下文和训练均使用增强音频输入时,Fréchet 编解码距离显著改善。说话人相似度得以保持或略有提升,表明增强过程有效维护了说话人身份。

评估首先证明,结合 GAN 修正的偏移无回声干净目标在感知质量和可懂度上始终优于早期反射目标。与开源模型相比,并在未见语言上进行测试时,所提出的增强器在无幻觉的情况下取得了顶级感知得分,在保持说话人身份方面远优于生成式恢复方法,并提升了下游 ASR 性能。使用该模型清理用于零样本 TTS 的上下文和训练音频,可显著降低词错误率和声学距离,同时保持说话人相似度。