Command Palette
Search for a command to run...
记忆缓存:具有增长式记忆能力的 RNN
记忆缓存:具有增长式记忆能力的 RNN
Ali Behrouz Zeman Li Yuan Deng Peilin Zhong Meisam Razaviyayn Vahab Mirrokni
摘要
Transformer 已成为近期大多数序列建模进展事实上的骨干网络,这主要归因于其随上下文长度扩展而增强的记忆能力。这种特性虽然在检索任务中显得合理,但也导致了二次方的时间复杂度,从而激发了近期研究对可行的次二次方循环替代方案的探索。尽管此类循环架构在不同领域展现了极具前景的初步结果,但在对召回率要求较高的任务中,它们的表现仍逊于 Transformer,这通常归因于其固定大小的记忆机制。在本文中,我们引入了“记忆缓存”(Memory Caching,简称 MC)技术,这是一种简单且有效的方法,通过缓存记忆状态(即隐藏状态)的检查点来增强循环模型的能力。MC 允许循环神经网络(RNN)的有效记忆容量随序列长度增长,提供了一种灵活的权衡机制,能够在线性 RNN 的固定记忆(即 O(L) 复杂度)与 Transformer 的增长式记忆(即 O(L2) 复杂度)之间进行插值。我们提出了 MC 的四种变体,包括门控聚合和稀疏选择性机制,并探讨了它们对线性记忆模块和深度记忆模块的影响。我们在语言建模和长上下文理解任务上的实验结果表明,MC 显著提升了循环模型的性能,验证了其有效性。
一句话总结
本文介绍了 Memory Caching (MC),它通过缓存记忆状态的检查点来增强循环模型,从而实现增长的内存容量,在 RNN 的 O(L) 复杂度和 Transformers 的 O(L2) 复杂度之间进行插值,证明了在语言建模和长上下文理解任务上的性能提升。
核心贡献
- 这项工作介绍了 Memory Caching (MC),一种通过缓存循环模型记忆状态的检查点来增强循环模型的技术,允许有效内存容量随序列长度增长。该方法提供了一种灵活的权衡,在 RNN 的固定内存复杂度和 Transformers 的增长内存复杂度之间进行插值。
- 提出了四种 MC 变体,包括门控聚合和稀疏选择机制,并讨论了其对线性和深度记忆模块的影响。这些设计扩展了框架在不同记忆模块结构上的适用性。
- 语言建模和长上下文理解任务的实验结果表明,MC 增强了循环模型的性能。这些发现支持了所提技术在解决高召回任务性能差距方面的有效性。
引言
Transformers 因其关联记忆能力而在序列建模中占据主导地位,但其二次复杂度限制了长上下文的扩展性。循环替代方案提供线性效率,但由于固定大小的状态迫使信息随时间丢失,难以应对高召回任务。作者引入了 Memory Caching 来增强循环模型,通过在输入序列中存储隐藏状态的检查点。该技术允许有效内存容量随序列长度增长,在 RNN 的效率和 Transformers 的性能之间提供了灵活的权衡。他们提出了四种变体,包括门控聚合和稀疏选择机制,以优化这些缓存记忆的使用方式,结果表明该方法在长上下文任务上缩小了与 Transformers 的准确率差距,同时保持了优越的推理效率。
方法
作者引入 Memory Caching (MC) 作为一种在递归神经网络 (RNN) 的效率和 Transformers 的检索能力之间进行插值的技术。核心框架将序列模型视为在前向传播过程中优化的关联记忆。为了在不产生二次计算成本的情况下管理长序列,模型将输入划分为段 S(1),…,S(N)。对于每个段,模型维护一个记忆状态并递归更新。一旦处理完一个段,其最终记忆状态就被保存为检查点。这确立了当前“在线记忆”和历史“缓存记忆”之间的区别。
如框架图所示,该架构聚合来自这些多个记忆状态的信息以计算当前查询的输出。系统维护来自先前段的一组缓存记忆以及当前在线记忆,允许模型访问任意距离的信息。
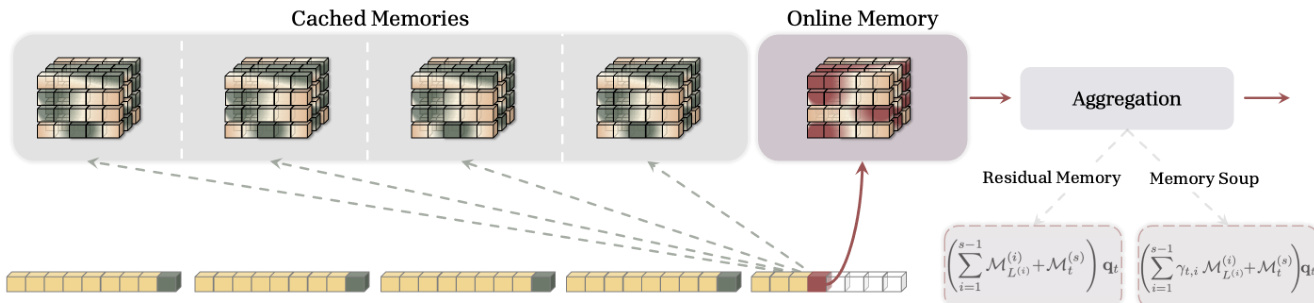
提出了几种聚合策略以有效地组合这些记忆。残差记忆变体简单求和来自在线和缓存记忆的输出。为了实现输入依赖的选择,门控残差记忆 (GRM) 引入了门控参数,根据当前输入上下文调节每个段的贡献。另一种方法 Memory Soup 通过插值缓存记忆的参数构建单个数据依赖记忆模块,有效地为每个 token 创建专门的检索函数。
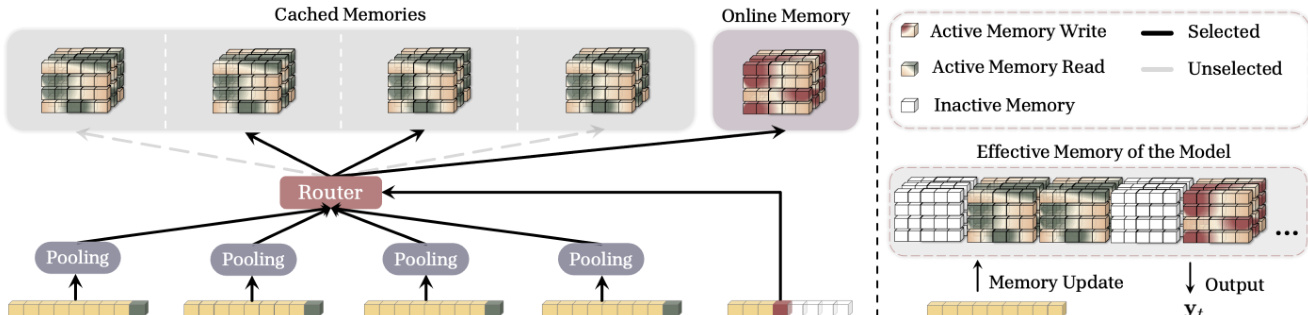
为了提高极长序列的效率,作者引入了稀疏选择缓存 (SSC)。该方法使用路由器测量当前 token 与过去段之间的上下文相似度,仅选择最相关的缓存记忆子集进行检索。这种方法通过避免为每个 token 处理所有缓存状态来减少计算开销。
参考说明路由器机制的图表,该图表突出了模型如何激活特定记忆块进行读写,同时保持其他块不活动。路由器确保仅访问必要的记忆组件,优化内存消耗和推理速度。
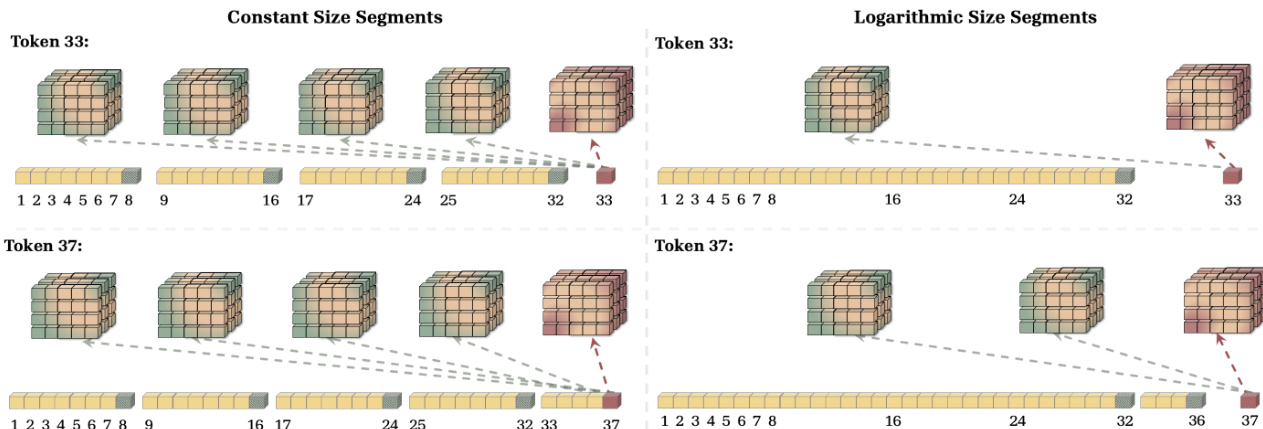
分割策略显著影响内存容量和计算复杂度之间的平衡。恒定大小段在序列上提供均匀分辨率,而对数大小段将缓存状态的数量减少到 O(logL)。这种分割选择允许模型在压缩水平和检索计算成本之间进行权衡。
这些分割方法的视觉比较展示了对数分割如何将 tokens 分组为指数增加的段大小,与恒定大小段相比,为处理长上下文提供了更高效的替代方案。
实验
该研究使用 LongBench 和 Needle-in-a-Haystack 等基准评估了语言建模、长上下文检索和理解任务中的内存缓存变体。结果表明,这些增强模型始终优于基线循环模型,并通过有效分配压缩负载和增加有效内存容量缩小了与 Transformers 的性能差距。此外,消融研究验证了特定设计选择对鲁棒性的贡献,而效率分析证实,这些变体在循环模型和 Transformers 之间提供了可扩展的中间地带,且开销最小。
提供的配置细节概述了研究中评估的两种模型规模的超参数。较大的模型变体具有更宽的隐藏维度,并在显著更大的 token 预算上训练,而较小的变体更深,具有更多的注意力头。这些设置为评估不同模型容量下的内存缓存和长上下文能力建立了基线。与较小的变体相比,较大的模型变体在显著更大的 token 预算上训练。较小的模型架构采用更多的块和注意力头,但使用较小的隐藏维度。峰值学习率与模型规模成反比缩放,较小的模型使用更高的速率。

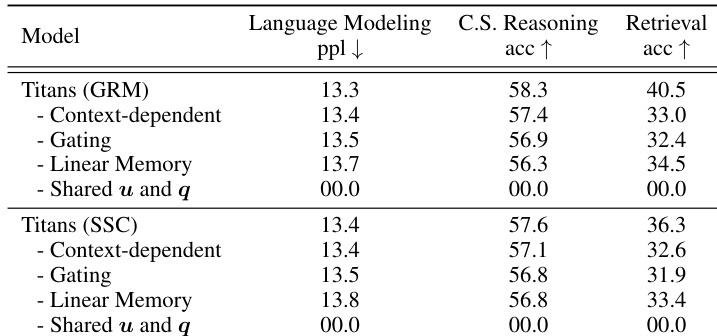
作者对 Titans 模型进行了消融研究,以评估上下文依赖性、门控和记忆线性等特定设计选择的贡献。结果表明,移除这些组件会在语言建模、推理和检索任务上始终降低性能。此外,共享特定参数的配置会导致模型完全失败,突出了所提架构的必要性。移除上下文依赖机制或门控会导致推理和检索任务的准确率降低。用线性版本替换记忆模块会增加困惑度并降低准确率,与基线相比。共享特定参数会导致模型完全失败,突出了所提架构的必要性。
下表比较了 Transformer、DLA 和 Titans 模型在各种内存缓存策略增强下的性能,涵盖单文档 QA、多文档 QA、摘要、少样本学习和代码生成任务。结果表明,内存缓存变体,特别是 GRM 和 SSC,通常比基线循环模型和 Log-Linear++ 方法提供一致的提升,特别是在多文档和少样本场景中。虽然 Transformers 作为强大的基线,但增强的循环模型表现出竞争性性能,通常在特定的少样本和检索基准上超越 Transformer。像 GRM 和 SSC 这样的内存缓存策略在大多数任务类别中始终产生更好的结果 than the Log-Linear++ approach。增强的循环模型在多文档 QA 和少样本任务中相比其基线版本显示出显著的性能提升。带有 GRM 的 Titans 模型在少样本 TQA 中实现了显著的高性能,超越了标准 Transformer 基线。
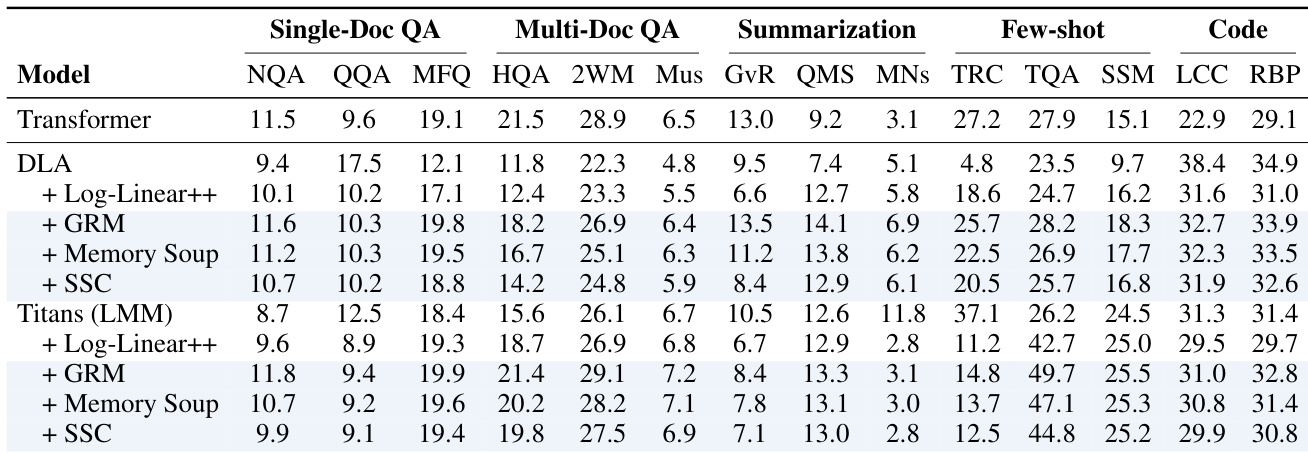
作者评估了内存缓存增强模型在上下文检索任务上的表现,将其与标准 Transformers 和基线循环模型进行比较。结果表明,内存缓存变体始终优于其基线模型,并提供与 Transformers 竞争的性能,特别是在使用 GRM 或 SSC 分割方法时。作者将这些增益归因于随序列长度扩展的增加的有效内存容量。内存缓存变体在多样化的数据集和上下文长度上为基线循环模型提供了一致的改进。GRM 和 SSC 方法相比其他内存缓存策略(如 Log-Linear++)实现了更优的结果。增强的循环模型缩小了与 Transformers 的性能差距,某些变体在特定任务上超越了 Transformer 基线。
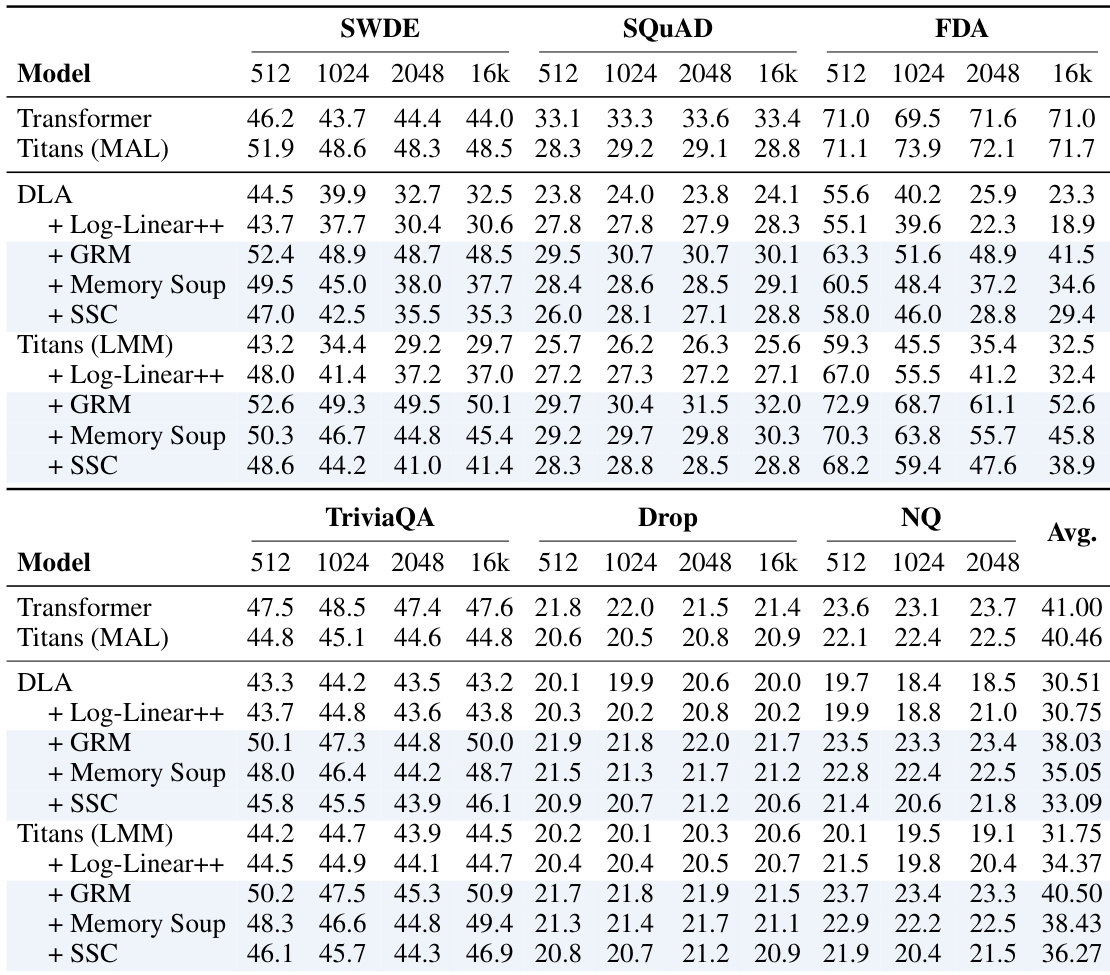
作者评估了内存缓存变体与基线模型在具有不同上下文长度的 Needle-in-a-Haystack 检索任务上的表现。结果表明,内存缓存始终提高检索准确率,特别是对于基线模型难以应对的较长序列。基于 Titans 的模型通过内存缓存增强实现了优越的性能,通常在不同检索类型和上下文长度上达到近乎完美的准确率。内存缓存变体显著提升了检索性能,优于基线 DLA 和 Transformer 模型,特别是随着上下文长度增加。Titans 模型与 SSC 和 GRM 等内存缓存方法结合实现了最高准确率,无论序列长度如何,在 pass-key 检索任务上保持完美得分。SSC 和 GRM 通常优于 Log-Linear++ 方法,展示了从长上下文中检索特定信息的更好鲁棒性。
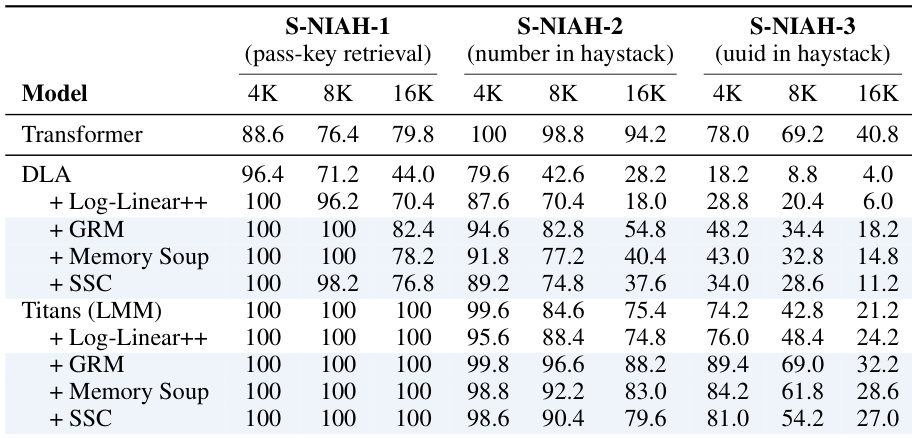
评估利用两种模型规模来建立评估内存缓存和长上下文能力的基线。消融分析确认了上下文依赖和门控等特定架构组件是必要的,因为移除它们会降低推理和检索任务的性能。比较实验表明,内存缓存策略,特别是 GRM 和 SSC,始终优于基线循环模型和 Log-Linear++ 方法,同时在 Transformers 上实现竞争性结果,特别是在长上下文检索场景中。